39 容器
容器有一定的隔离,但是隔离性没有虚拟化那么好,仅仅做简单的封装。
当然封装也带来了好处,一个是打包,二是标准;
容器实现封闭的环境主要靠两种技术:
一种是看起来是隔离的技术,称为namespace(命名空间);
在每个 namespace 中的应用看到的,都是不同的 IP 地址、用户空间、进程 ID 等。
一种是用起来是隔离的技术,称为cgroup(网络资源限制);
即整台机器有很多的 CPU、内存,但是一个应用只能用其中的一部分。
容器做好之后,就可以使用镜像把容器保存下来:
将代码连同运行环境打包成一个容器镜像,无论是在开发环境、测试环境,还是生产环境运行代码,都
可以使用相同的镜像,就好像集装箱在开发、测试、生产这三个码头非常顺利地整体迁移,这样产品的发布和上线速度就加快了。
Docker是一种主流的实现方式,其好处为:持续集成、弹性伸缩、跨云迁移
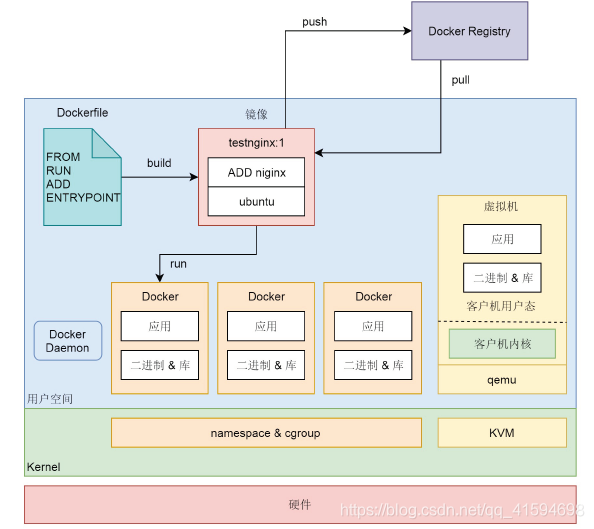
无论是容器,还是虚拟机,都依赖于内核中的技术,虚拟机依赖的是 KVM,容器依赖的是 namespace 和 cgroup 对进程进行隔离。
为了运行 Docker,有一个 daemon 进程 Docker Daemon 用于接收命令行。
为了描述 Docker 里面运行的环境和应用,有一个 Dockerfile,通过 build 命令称为容器镜像。容器镜像可以上传到镜像仓库,也可以通过 pull 命令从镜像仓库中下载现成的容器镜像。
通过 Docker run 命令将容器镜像运行为容器,通过 namespace 和 cgroup 进行隔离,容器里面不包含内核,是共享宿主机的内核的。
对比虚拟机,虚拟机在 qemu 进程里面是有客户机内核的,应用运行在客户机的用户态。
40 Namespace
一个容器需要什么?用户管理、进程管理、文件管理、对外通信
Linux 内核里面实现了以下六项资源隔离:
UTS,对应的宏为 CLONE_NEWUTS,表示不同的 namespace 可以配置不同的hostname。
User,对应的宏为 CLONE_NEWUSER,表示不同的 namespace 可以配置不同的用户和组。
Mount,对应的宏为 CLONE_NEWNS,表示不同的 namespace 的文件系统挂载点是隔离的
PID,对应的宏为 CLONE_NEWPID,表示不同的 namespace 有完全独立的 pid,也即一个 namespace 的进程和另一个 namespace 的进程,pid 可以是一样的,但是代表不同的进程。
Network,对应的宏为 CLONE_NEWNET,表示不同的 namespace 有独立的网络协议栈。
IPC
对应到容器:

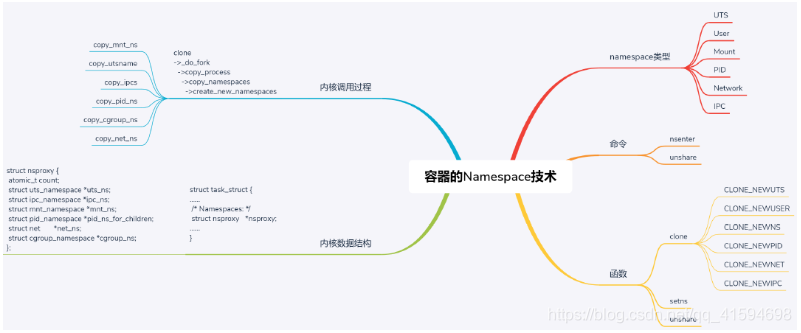
在每一个进程的 task_struct 里面,有一个指向namespace 结构体的指针 nsproxy。
namespace 有六种类型,分别是 UTS、User、Mount、Pid、Network 和 IPC。
还有两个常用的命令 nsenter 和 unshare,主要用于操作 Namespace,有三个常用的函数 clone、setns 和 unshare。
在内核里面,对于任何一个进程 task_struct 来讲,里面都会有一个成员 struct nsproxy,用于保存 namespace 相关信息,里面有 struct uts_namespace、struct ipc_namespace、struct mnt_namespace、struct pid_namespace、struct net *net_ns和 struct cgroup_namespace *cgroup_ns。
创建 namespace 的时候,我们在内核中会调用 copy_namespaces,调用顺序依次是copy_mnt_ns、copy_utsname、copy_ipcs、copy_pid_ns、copy_cgroup_ns 和copy_net_ns,来复制 namespace。
41 CGroup:Control Group
用来控制资源的使用
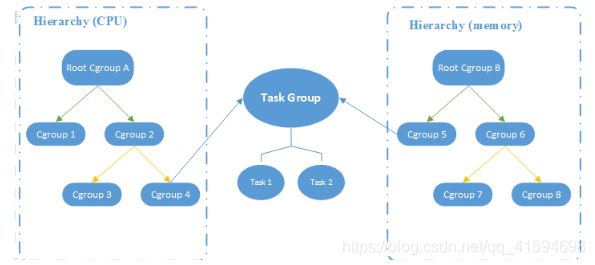
- task :一个任务就是一个进程
- control group :就是一个进程集合,可以把它理解成一个房间,每个房间都是相互隔离的。
- hierachy(层级) :control group存在父子的概念,父组可以使用子组里的资源
- subsystem :如果组内的进程需要工作,就必须要有cpu内存之类的资源,这就需要涉及到资源控制器,这个资源控制器就是subsystem。比如一个cpu控制器就是一个subsystem
cgroups 定义了下面的一系列子系统,每个子系统用于控制某一类资源:
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory 子系统,可以限制进程的 memory 使用量。
blkio 子系统,可以限制进程的块设备 io。
devices 子系统,可以控制进程能够访问某些设备。
net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
最常用的是对于 CPU和内存的控制
用户态中,cgroup 对于 Docker 资源的控制表现如图:

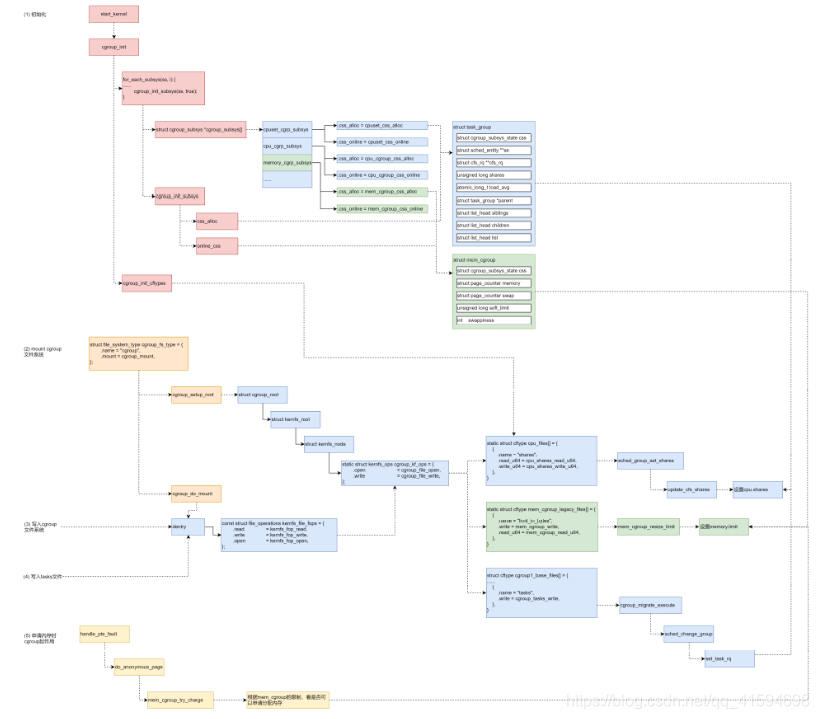
内核中,cgroup 的工作机制如下:
第一步,系统初始化的时候,初始化 cgroup 的各个子系统的操作函数,分配各个子系统的数据结构。
第二步,mount cgroup 文件系统,创建文件系统的树形结构,以及操作函数。
第三步,写入 cgroup 文件,设置 cpu 或者 memory 的相关参数,这个时候文件系统的操作函数会调用到 cgroup 子系统的操作函数,从而将参数设置到 cgroup 子系统的数据结构中。
第四步,写入 tasks 文件,将进程交给某个 cgroup 进行管理,因为 tasks 文件也是一个cgroup 文件,统一会调用文件系统的操作函数进而调用 cgroup 子系统的操作函数,将cgroup 子系统的数据结构和进程关联起来。
第五步,对于 cpu 来讲,会修改 scheduled entity,放入相应的队列里面去,从而下次调度的时候就起作用了。对于内存的 cgroup 设定,只有在申请内存的时候才起作用。
Namespace:隔离技术的第一层,确保 Docker 容器内的进程看不到也影响不到 Docker 外部的进程。
Control Groups:用于进行运行时的资源限制。
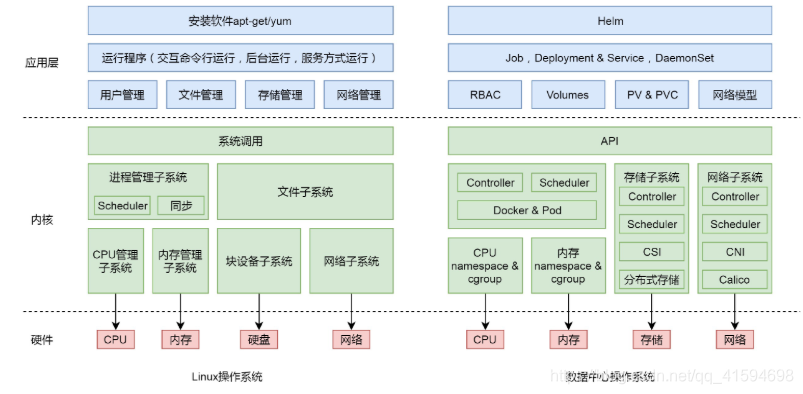
42 数据中心操作系统:Kubernetes
Kubernetes是一个调度器,可以管理多个机器,即数据中心
主要管理数据中心里面的四种硬件资源:CPU、内存、存储、网络。
对于 CPU 和内存这两种计算资源的管理可以通过 Docker 技术完成。
在服务器之间迁移,那数据应该怎么办呢?如果数据放在每一台服务器上,其实就像散落在汪洋大海里面,用的时候根本找不到,所以必须要有统一的存储。正像一台操作系统上多个进程之间,要通过文件系统保存持久化的数据并且实现共享,在数据中心里面也需要一个这样的基础设施;
统一的存储常常有三种形式:对象存储、分布式文件系统、分布式块存储
不同的服务器上的 Docker 需要互相通信:
IP-per-Pod,每个 Pod 都拥有一个独立 IP 地址,Pod 内所有容器共享一个网络命名空间。
集群内所有 Pod 都在一个直接连通的扁平网络中,可通过 IP 直接访问。
所有容器之间无需 NAT 就可以直接互相访问。
所有 Node 和所有容器之间无需 NAT 就可以直接互相访问。
容器自己看到的 IP 跟其它容器看到的一样。
功能总结: