8 进程管理
有了系统调用,就可以开始创建进程了
8.1 通过写代码使用系统调用创建一个进程
在 Linux 上写程序和编译程序,也需要一系列的开发套件,就像 IDEA 一样;
运行下面的命令,就可以在 centOS 7 操作系统上安装开发套件:
yum -y groupinstall "Development Tools"
在 Windows 上写的程序,都会被保存成.h 或者.c 文件,容易让人感觉这是某种有特殊格式的文件,但其实这些文件只是普普通通的文本文件。
因而在 Linux上,用 Vim 来创建并编辑一个文件就行了。
接下来开始写创建一个进程的程序:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
extern int create_process (char* program, char** arg_list);
int create_process (char* program, char** arg_list)
{
pid_t child_pid;
child_pid = fork ();//创建
if (child_pid != 0)
return child_pid;
else {
execvp (program, arg_list);//运行
abort ();
}
接下来创建第二个文件,调用上面这个函数:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
extern int create_process (char* program, char** arg_list);
int main ()
{
char* arg_list[] = {"ls","-l","/etc/yum.repos.d/",NULL};
create_process ("ls", arg_list);
return 0;
}
8,2 进行编译:程序的二进制格式
程序写完了,但是这两个文件只是文本文件,CPU 是不能执行文本文件里面的指令的,这些指令只有人能看懂;
CPU 能够执行的命令是二进制的,比如“0101”这种,所以这些指令还需要翻译一下,这个翻译的过程就是编译(Compile)。
编译好的二进制文件才是我们的程序。
在 Linux 下面,二进制的程序要有严格的格式,这个格式我们称为ELF(Executeable and Linkable Format,可执行与可链接格式);
这个格式可以根据编译的结果不同,分为不同的格式;
这样才能保证无论分配给程序的资源是怎么样的,都能以固定的流程执行;按照里面的指令来,程序也能达到预期的效果。
如何从文本文件编译成二进制格式呢?
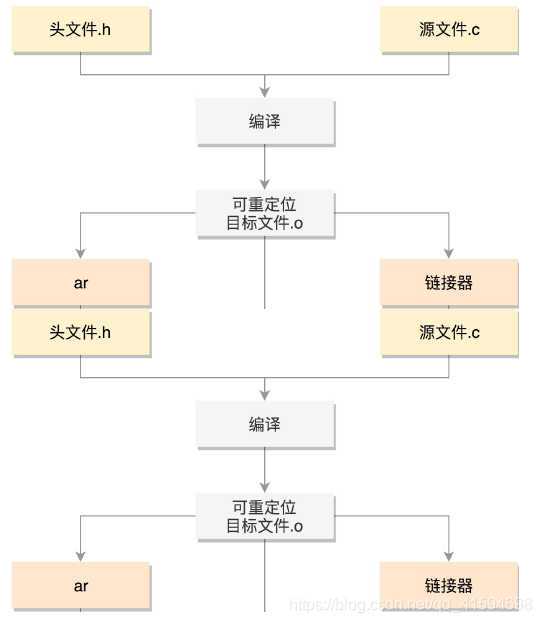
编译这两个程序:
gcc -c -fPIC process.c
gcc -c -fPIC createprocess.c
在编译的时候,先做预处理工作,例如将头文件嵌入到正文中,将定义的宏展开;
然后就是真正的编译过程,最终编译成为.o 文件,这就是 ELF 的第一种类型:可重定位文件(RelocatableFile):
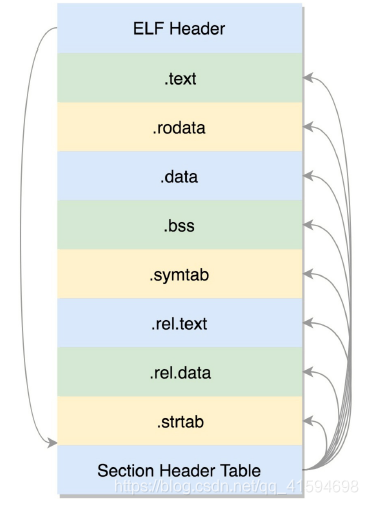
.text:放编译好的二进制可执行代码
.data:已经初始化好的全局变量
.rodata:只读数据,例如字符串常量、const 的变量
.bss:未初始化全局变量,运行时会置 0
.symtab:符号表,记录的则是函数和变量
.strtab:字符串表、字符串常量和变量名
接下来的每一段被称为一个一个的 section,也叫节。
这里只有全局变量,因为局部变量是放在栈里面的,是程序运行过程中随时分配空间,随时释放的,现在讨论的是二进制文件,还没启动,所以只需要讨论在哪里保存全局变量。
这些节的元数据信息也需要有一个地方保存,就是最后的节头部表(Section Header Table);
在这个表里面,每一个 section 都有一项,在代码里面也有定义 struct elf32_shdr 和 structelf64_shdr;
在 ELF 的头里面,有描述这个文件的节头部表的位置,有多少个表项等等信息。
要想让 create_process 这个函数作为库文件被重用,不能以.o 的形式存在,而是要形成库文件;
最简单的类型是静态链接库.a 文件(Archives),仅仅将一系列对象文件(.o)归档为一个文件,使用命令 ar 创建。
ar cr libstaticprocess.a process.o
这样,当有程序要使用这个静态连接库的时候,会将.o 文件提取出来,链接到程序中:
gcc -o staticcreateprocess createprocess.o -L. -lstaticprocess
在这个命令里,-L 表示在当前目录下找.a 文件,-lstaticprocess 会自动补全文件名,比如加前缀lib,后缀.a,变成 libstaticprocess.a;
找到这个.a 文件后,将里面的 process.o 取出来,和createprocess.o 做一个链接,形成二进制执行文件 staticcreateprocess;
这个链接的过程,重定位就起作用了;
原来 createprocess.o 里面调用了 create_process 函数,但是不能确定位置,现在将 process.o 合并了进来,就知道位置了。
形成的二进制文件叫可执行文件,是 ELF 的第二种格式,格式如下:
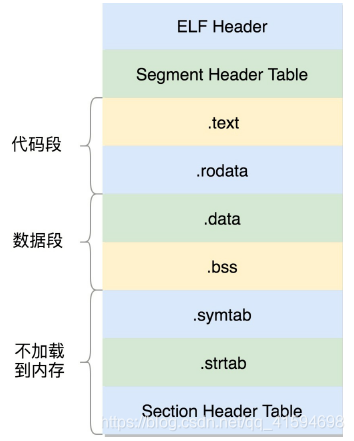
这个格式和.o 文件大致相似,还是分成一个个的 section,并且被节头表描述;
在 ELF 头里面,有一项 e_entry,也是个虚拟地址,是这个程序运行的入口;
只不过这些section 是多个.o 文件合并过的;
但是这个时候,这个文件已经是马上就可以加载到内存里面执行的文件了;
因而这些 section 被分成了需要加载到内存里面的代码段、数据段和不需要加载到内存里面的部分;
将小的 section 合成了大的段 segment,并且在最前面加一个段头表(Segment Header Table);
在代码里面的定义为 struct elf32_phdr 和 struct elf64_phdr,这里面除了有对于段的描述之外,最重要的是 p_vaddr,这个是这个段加载到内存的虚拟地址。
静态链接库一旦链接进去,代码和变量的 section 都合并了,因而程序运行的时候,就不依赖于这个库是否存在;
但是这样有一个缺点,就是相同的代码段,如果被多个程序使用的话,在内存里面就有多份,而且一旦静态链接库更新了,如果二进制执行文件不重新编译,也不随着更新;
因而就出现了动态链接库(Shared Libraries),不仅仅是一组对象文件的简单归档,而是多个对象文件的重新组合,可被多个程序共享。
当一个动态链接库被链接到一个程序文件中的时候,最后的程序文件并不包括动态链接库中的代码,而仅仅包括对动态链接库的引用,并且不保存动态链接库的全路径,仅仅保存动态链接库的名称。
动态链接库,就是 ELF 的第三种类型,共享对象文件(Shared Object)。
8.3 运行程序为进程
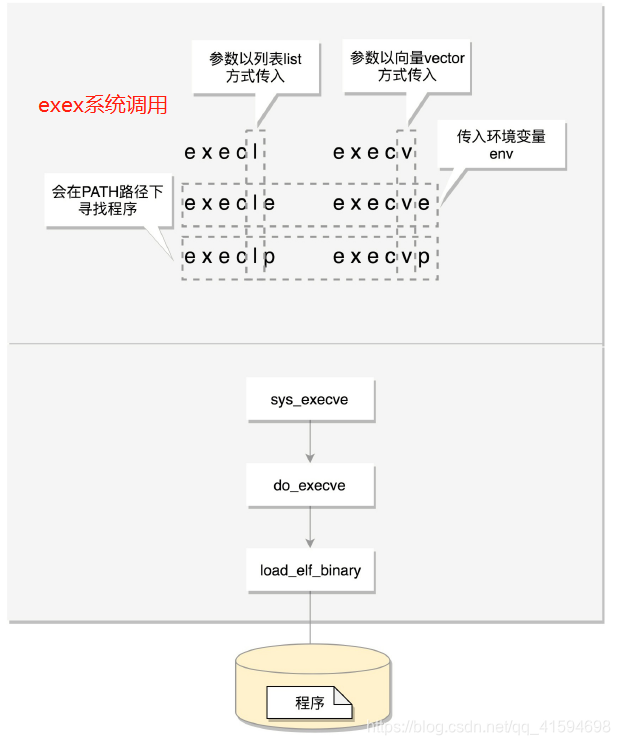
这个时候它还是个程序,那怎么把这个文件加载到内存里面呢?
在内核中,有一个数据结构linux_binfmt,用来定义加载二进制文件的方法。
对于 ELF 文件格式,有对应的实现,使用load_elf_binary来加载,原理是使用exec:
8.4 进程树
所有的进程都是从父进程 fork 过来的,而祖宗进程则是系统启动的 init进程。
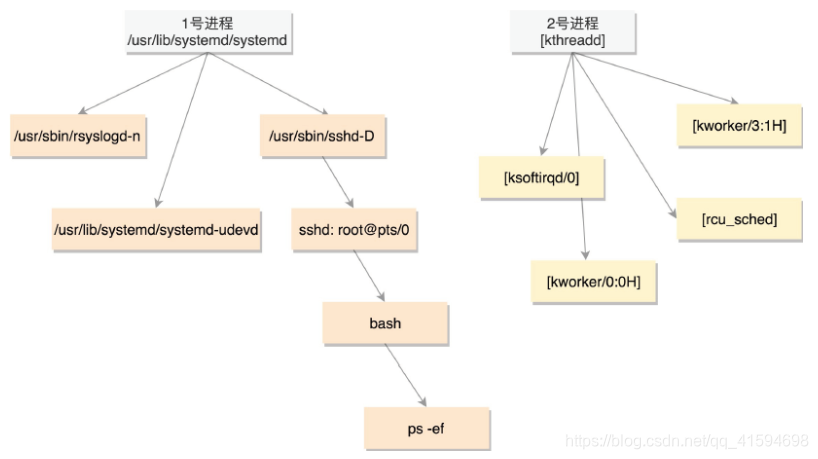
1号进程是用户态进程的祖先,2号进程则为内核态进程的祖先
8.5 总结
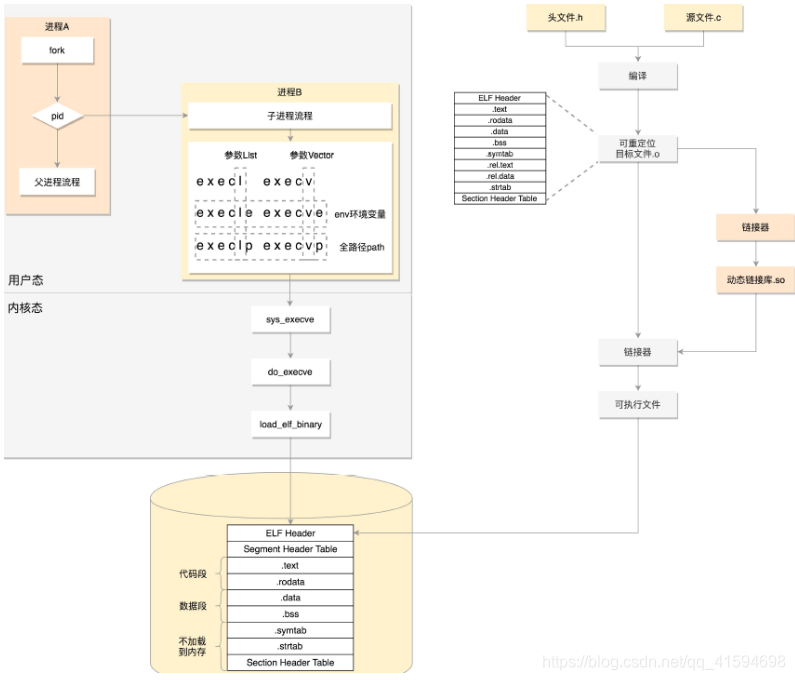
一个进程从代码到二进制到运行时的一个过程:
首先通过图右边的文件编译过程,生成 so 文件和可执行文件,放在硬盘上;
下图左边的用户态的进程 A 执行 fork,创建进程 B,在进程 B 的处理逻辑中,执行 exec 系列系统调用;
这个系统调用会通过 load_elf_binary 方法,将刚才生成的可执行文件,加载到进程 B 的内存中执行
9 线程:让进程并行执行
9.1 为什么要有线程
进程相当于一个项目,而线程就是为了完成项目需求,而建立的一个个开发任务;
1.有时候,任务是可以拆解的,如果相关性没有非常大前后关联关系,就可以并行执行,加快速度;
2.进程要管控意外。例如,主线程正在一行一行执行二进制命令,突然收到一个通知,要做一点小事情,应该停下主线程来做么?太耽误事情了,应该创建一个单独的线程,单独处理这些事件;
3.在 Linux 中,有时候我们希望将前台的任务和后台的任务分开;
因为有些任务是需要马上返回结果的,例如你输入了一个字符,不可能五分钟再显示出来;
而有些任务是可以默默执行的,例如将本机的数据同步到服务器上去,这个就没刚才那么着急;
因此这样两个任务就应该在不同的线程处理,以保证互不耽误。
而使用进程实现并行执行的问题有两个:
第一,创建进程占用资源太多;
第二,进程之间的通信需要数据在不同的内存空间传来传去,无法共享。
9.2 如何创建线程
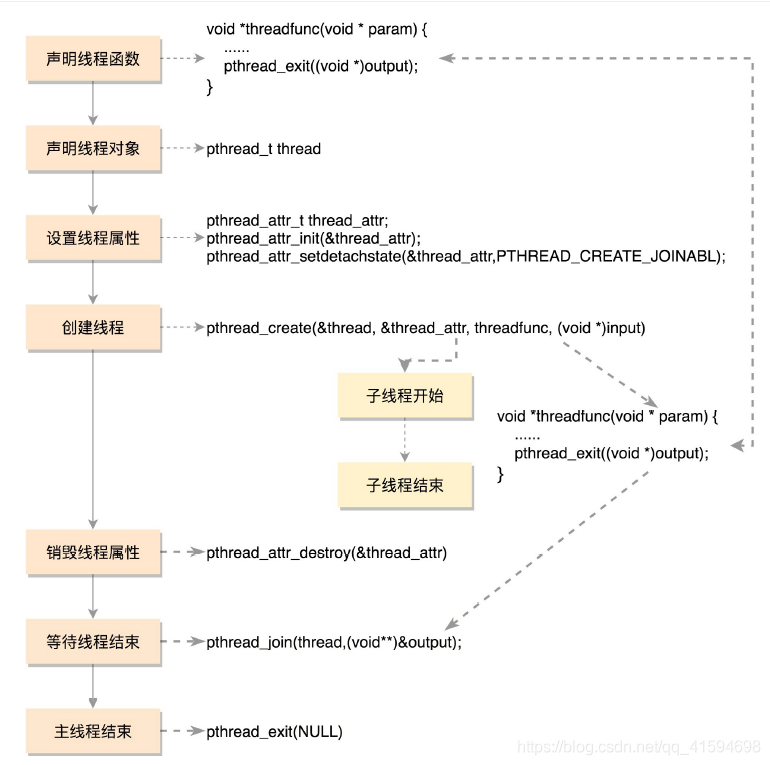
9.3 线程的数据
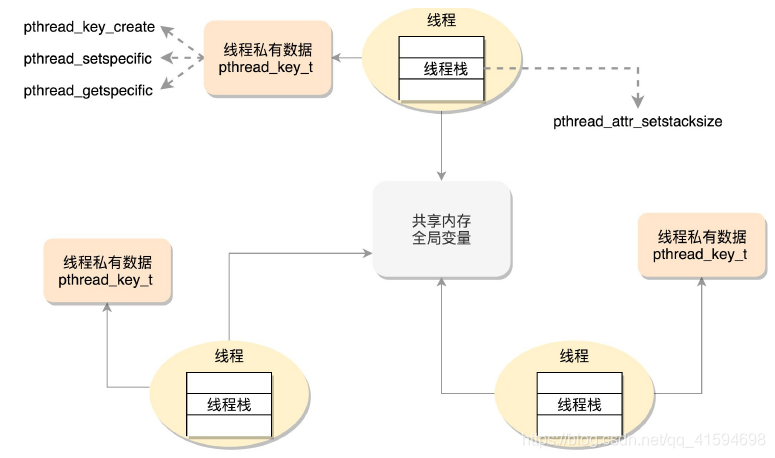
把线程访问的数据细分成三类:线程栈上的本地数据、在整个进程里共享的全局数据、线程私有数据
第一类是线程栈上的本地数据,比如函数执行过程中的局部变量;
函数的调用会使用栈的模型,这在线程里面是一样的。只不过每个线程都有自己的栈空间;
为了避免线程之间的栈空间踩踏,线程栈之间还会有小块区域,用来隔离保护各自的栈空间;
一旦另一个线程踏入到这个隔离区,就会引发段错误。
第二类数据是在整个进程里共享的全局数据。例如全局变量,虽然在不同进程中是隔离的,但
是在一个进程中是共享的;
如果同一个全局变量,两个线程一起修改,那肯定会有问题,有可能把数据改的面目全非;
这就需要有一种机制来保护他们,比如谁先用谁后用;
第三类数据是线程私有数据(Thread Specific Data),使得线程像进程一样,也有自己的私有数据;
9.4 数据的保护
- 第一种方式:Mutex,全称 Mutual Exclusion,中文叫互斥。
顾名思义,有你没我,有我没你;
它的模式就是在共享数据访问的时候,去申请加把锁,谁先拿到锁,谁就拿到了访问权限,其他人就只好在门外等着,等这个人访问结束,把锁打开,其他人再去争夺,还是遵循谁先拿到谁访问
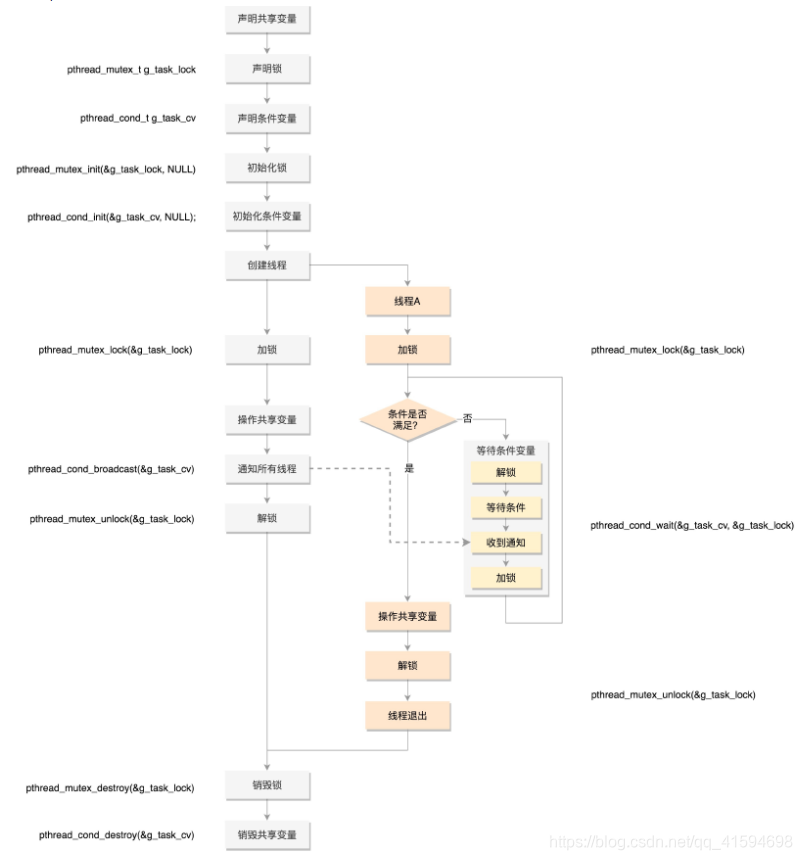
使用流程:
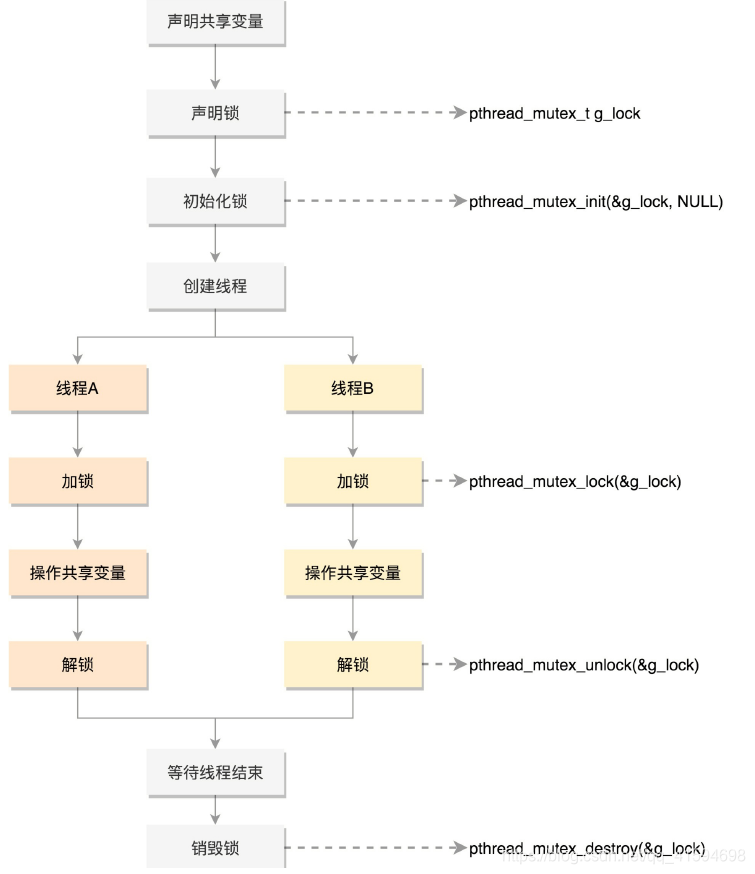
如果使用 pthread_mutex_lock(),那就需要一直在那里等着;
如果是 pthread_mutex_trylock(),就可以不用等着,去干点儿别的,但是我怎么知道什么时候回
来再试一下,是不是轮到我了呢?能不能在轮到我的时候,通知我一下呢?
这其实就是条件变量,也就是说如果没事儿,就让大家歇着,有事儿了就去通知,别让人家没事儿就来问问,浪费大家的时间。
但是当它接到了通知,来操作共享资源的时候,还是需要抢互斥锁,因为可能很多人都受到了通知,都来访问了,所以条件变量和互斥锁是配合使用的。
使用流程:
10 进程数据结构
10.1 task_struct解析1
内核如何管理进程/线程体系?
即有的进程只有一个线程,有的进程有多个线程,它们都需要由内核分配CPU来干活。可是CPU总共就这么几
个,应该怎么管理,怎么调度?
在Linux里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构task_struct进行管理
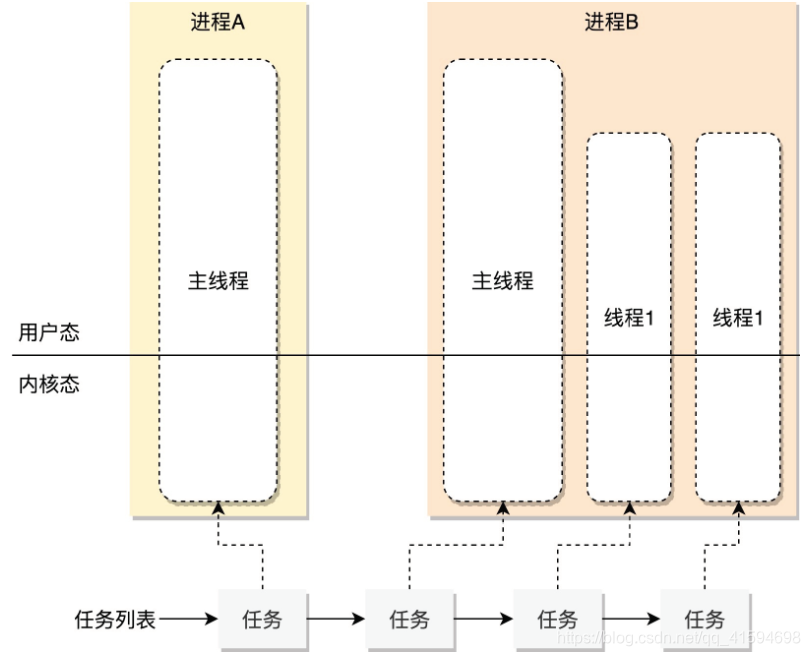
Linux的任务管理都应该干些什么?
1.应该先弄一个链表,将所有的task_struct串起来。
2.每一个任务task_struct的字段如下:
任务ID:作为这个任务的唯一标识;
涉及的字段有:
pid_t pid;
pid_t tgid;
struct task_struct *group_leader;
为什么需要三个?因为上面的进程和线程到了内核这里,统一变成了任务,这就带来两个问题:任务展示、给任务下发指令
任务展示中:使用ps命令可以展示出所有的进程。
但是如果你是这个命令的实现者,到了内核,按照上面的任务列表把这些命令都显示出来,把所有的线程全都平摊开来显示给用户,用户肯定觉得既复杂又困惑;
复杂在于,列表这么长;困惑在于,里面出现了很多并不是自己创建的线程。
给任务下发指令中:使用kill命令来给进程发信号,通知进程退出。
如果发给了其中一个线程,我们就不能只退出这个线程,而是应该退出整个进程;
当然,有时候,我们希望只给某个线程发信号。
总的来说,即发信号的时候,需要区分进程和线程。
所以在内核中,它们虽然都是任务,但是应该加以区分。其中,pid是process id,tgid是thread group ID;
任何一个进程,如果只有主线程,那pid是自己,tgid是自己,group_leader指向的还是自己;
如果创建了其他线程,那么线程有自己的pid,tgid就是进程的主线程的pid,group_leader指向的就是进程的主线程;
有了tgid,就知道tast_struct代表的是一个进程还是代表一个线程了。
信号处理
/* Signal handlers: */
//定义了哪些信号被阻塞暂不处理(blocked),哪些信号尚等待处理(pending),哪些信号正在通过信号处理函数进行处理(sighand)。
//处理的结果可以是忽略,可以是结束进程等等
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
sigset_t saved_sigmask;
struct sigpending pending;
//信号处理函数默认使用用户态的函数栈,当然也可以开辟新的栈专门用于信号处理,这就是sas_ss_xxx这三个变量的作用。
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
task_struct里面有一个struct sigpending pending;
struct signal_struct *signal里面有一个struct sigpending shared_pending;
它们一个是本任务的,一个是线程组共享的。
任务状态
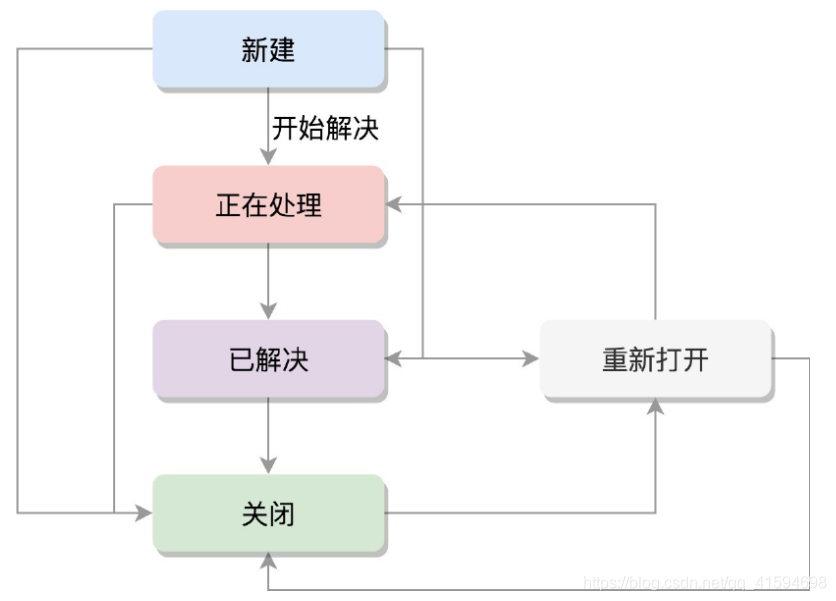
相关变量:
/* -1 unrunnable, 0 runnable, >0 stopped
state(状态)可以取的值定义在include/linux/sched.h头文件中*/
volatile long state;
int exit_state;
//flags是通过bitset的方式设置的。也就是说,当前是什么状态,哪一位就置一
unsigned int flags;
进程状态:
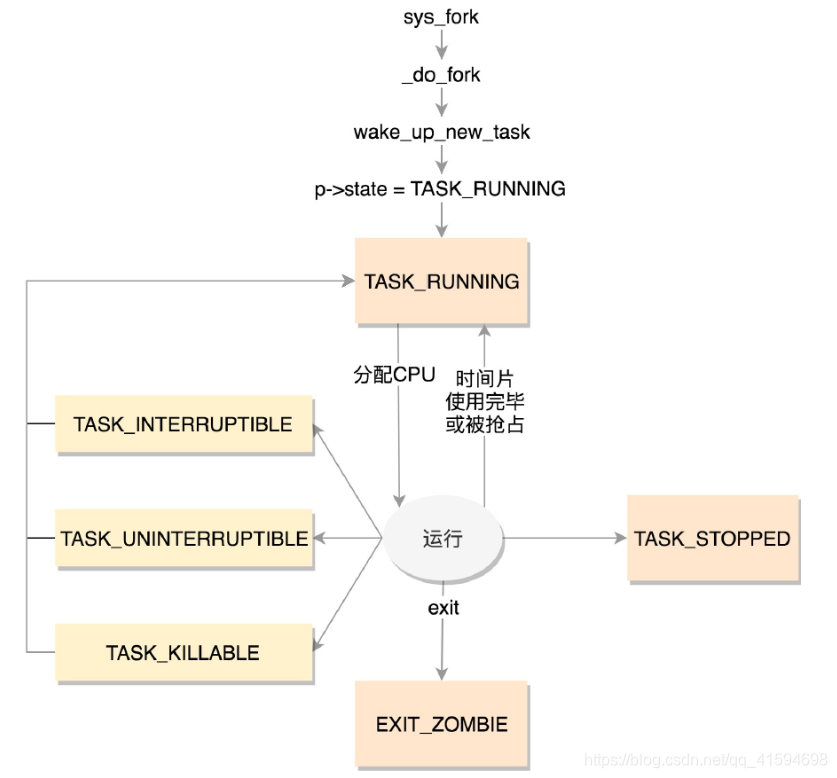
进程状态解析:
TASK_RUNNING并不是说进程正在运行,而是表示进程在时刻准备运行的状态;
当处于这个状态的进程获得时间片的时候,就是在运行中;
如果没有获得时间片,就说明它被其他进程抢占了,在等待再次分配时间片。
在运行中的进程,一旦要进行一些I/O操作,需要等待I/O完毕,这个时候会释放CPU,进入睡眠状态。
在Linux中,有两种睡眠状态:
一种是TASK_INTERRUPTIBLE:可中断的睡眠状态;
这是一种浅睡眠的状态,也就是说,虽然在睡眠,等待I/O完成,但是这个时候一个信号来的时候,进程还是要被唤醒;
只不过唤醒后,不是继续刚才的操作,而是进行信号处理;
当然程序员可以根据自己的意愿,来写信号处理函数,例如收到某些信号,就放弃等待这个I/O操作完成,直接退出,也可也收到某些信息,继续等待。
另一种睡眠是TASK_UNINTERRUPTIBLE,不可中断的睡眠状态;
这是一种深度睡眠状态,不可被信号唤醒,只能死等I/O操作完成;
一旦I/O操作因为特殊原因不能完成,这个时候,谁也叫不醒这个进程了;
而kill本身也是一个信号,既然这个状态不可被信号唤醒,kill信号也被忽略了。除非重启电脑,没有其他办法;
因此,这其实是一个比较危险的事情,除非极其有把握,不然还是不要设置成TASK_UNINTERRUPTIBLE。
于是,我们就有了一种新的进程睡眠状态:TASK_KILLABLE,可以终止的新睡眠状态;
进程处于这种状态中,它的运行原理类似TASK_UNINTERRUPTIBLE,只不过可以响应致命信号:
//TASK_WAKEKILL用于在接收到致命信号时唤醒进程
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
TASK_STOPPED是在进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后进入该状态。
TASK_TRACED表示进程被debugger等进程监视,进程执行被调试程序所停止;
当一个进程被另外的进程所监视,每一个信号都会让进程进入该状态。
一旦一个进程要结束,先进入的是EXIT_ZOMBIE状态,但是这个时候它的父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程就成了僵尸进程;
EXIT_DEAD是进程的最终状态。
EXIT_ZOMBIE和EXIT_DEAD也可以用于exit_state。
上面的进程状态和进程的运行、调度有关系,还有其他的一些状态,我们称为标志,放在flags字段中,这些字段都被定义为宏,以PF开头,例子:
//表示正在退出。当有这个flag的时候,在函数find_alive_thread中,找活着的线程,遇到有这个flag的,就直接跳过。
#define PF_EXITING 0x00000004
//表示进程运行在虚拟CPU上。在函数account_system_time中,统计进程的系统运行时间,如果有这个flag,就调用account_guest_time,按照客户机的时间进行统计。
#define PF_VCPU 0x00000010
//表示fork完了,还没有exec。在_do_fork函数里面调用copy_process,这个时候把flag设置为PF_FORKNOEXEC。当exec中调用了load_elf_binary的时候,又把这个flag去掉。
#define PF_FORKNOEXEC 0x00000040
进程调度
进程的状态切换往往涉及调度,下面这些字段都是用于调度的:
//是否在运⾏队列上
int on_rq;
//优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
//调度器类
const struct sched_class *sched_class;
//调度实体
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
//调度策略
unsigned int policy;
//可以使⽤哪些CPU
int nr_cpus_allowed;
cpumask_t cpus_allowed;
struct sched_info sched_info;
运行统计信息:
u64 utime;//⽤⼾态消耗的CPU时间
u64 stime;//内核态消耗的CPU时间
unsigned long nvcsw;//⾃愿(voluntary)上下⽂切换计数
unsigned long nivcsw;//⾮⾃愿(involuntary)上下⽂切换计数
u64 start_time;//进程启动时间,不包含睡眠时间
u64 real_start_time;//进程启动时间,包含睡眠时间
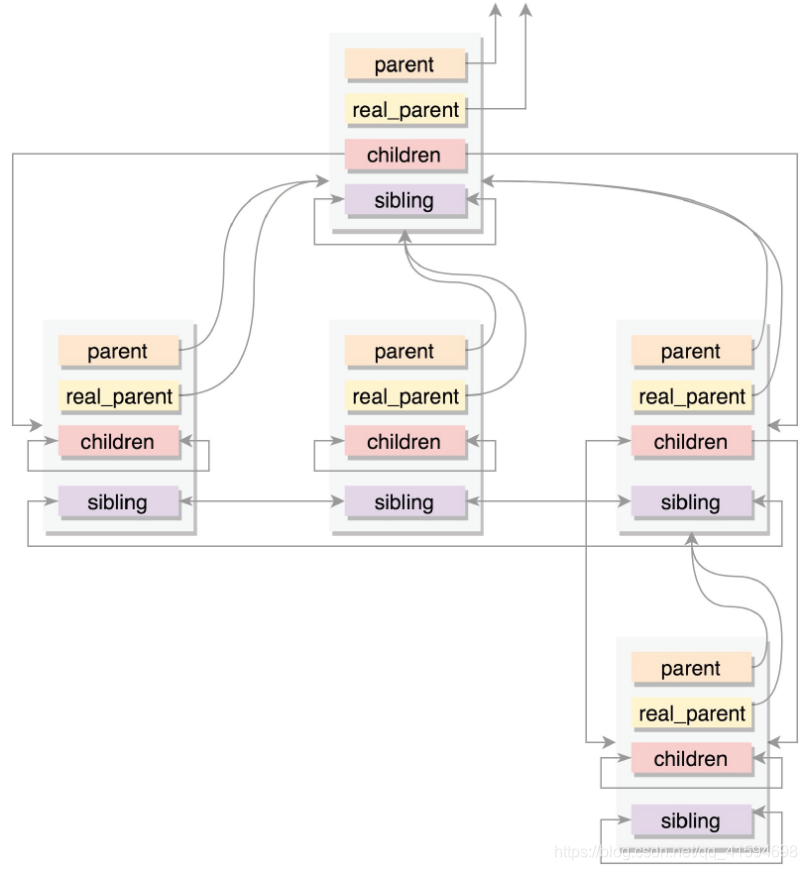
进程亲缘关系:
任何一个进程都有父进程,所以,整个进程其实就是一棵进程树,而拥有同一父进程的所有进程都具有兄弟关系:
//通常情况下,real_parent和parent是一样的,但是也会有另外的情况存在。
//例如,bash创建一个进程,那进程的parent和real_parent就都是bash。如果在bash上使用GDB来debug一个进程,这个时候GDB是real_parent,bash是这个进程的parent。
struct task_struct __rcu *real_parent;
struct task_struct __rcu *parent;//指向其父进程。当它终止时,必须向它的父进程发送信号。
struct list_head children;//表示链表的头部。链表中的所有元素都是它的子进程。
struct list_head sibling;//用于把当前进程插入到兄弟链表中。
进程间关系如图:
进程权限:我能操纵谁,谁能操纵我。
//Objective
const struct cred __rcu *real_cred;//谁能操作这个进程
//Subjective
const struct cred __rcu *cred;//这个进程能够操作谁。
cred结构大部分是关于用户和用户所属的用户组信息,即以用户和用户组控制权限
面试:setuid原理
问题:
比如,用户A想玩一个游戏,这个游戏的程序是用户B安装的。游戏这个程序文件的权限为rwxr–r–。A是没有权限运行这个程序的,因而用户B要给用户A权限才行;
于是用户B就给这个程序设定了所有的用户都能执行的权限rwxr-xr-x,用户A就获得了运行这个游戏的权限;
当游戏运行起来之后,游戏进程的uid、euid、fsuid都是用户A;
后来,想保存通关数据的时候,发现这个游戏的玩家数据是保存在另一个文件里面的;
这个文件权限rw-------,只给用户B开了写入权限,而游戏进程的euid和fsuid都是用户A,A是写不进去的。
解决:
可以通过chmod u+s program命令,给这个游戏程序设置set-user-ID的标识位,把游戏的权限变成rwsr-xr-x;
这个时候,用户A再启动这个游戏的时候,创建的进程uid当然还是用户A,但是euid和fsuid就不是用户A了,因为看到了set-user-id标识,就改为文件的所有者的ID,也就是说,euid和fsuid都改成用户B了,这样就能够将通关结果保存下来;
在Linux里面,一个进程可以随时通过setuid设置用户ID,所以,游戏程序的用户B的ID还会保存在一个地方,这就是suid和sgid,也就是saved uid和save gid;
这样就可以很方便地使用setuid,通过设置uid或者suid来改变权限。
还有另一个权限机制就是capabilities:用位图表示权限,对于普通用户运行的进程,当有这个权限的时候,就能做这些操作;没有的时候,就不能做,这样粒度要比“只有普通用户和root用户”小很多。
内存管理:每个进程都有自己独立的虚拟内存空间,用一个数据结构来表示,为mm_struct。
struct mm_struct *mm;
struct mm_struct *active_mm;
文件与文件系统:每个进程有一个文件系统的数据结构,还有一个打开文件的数据结构。
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
总结:下图为task_struct的组织和字段:

10.2 用户态的执行和内核态的执行
在程序执行过程中,一旦调用到系统调用,就需要进入内核继续执行;
那如何将用户态的执行和内核态的执行串起来呢?
需要以下两个成员变量:
struct thread_info thread_info;//用户栈
void *stack;//内核栈
10.2.1 用户态函数栈
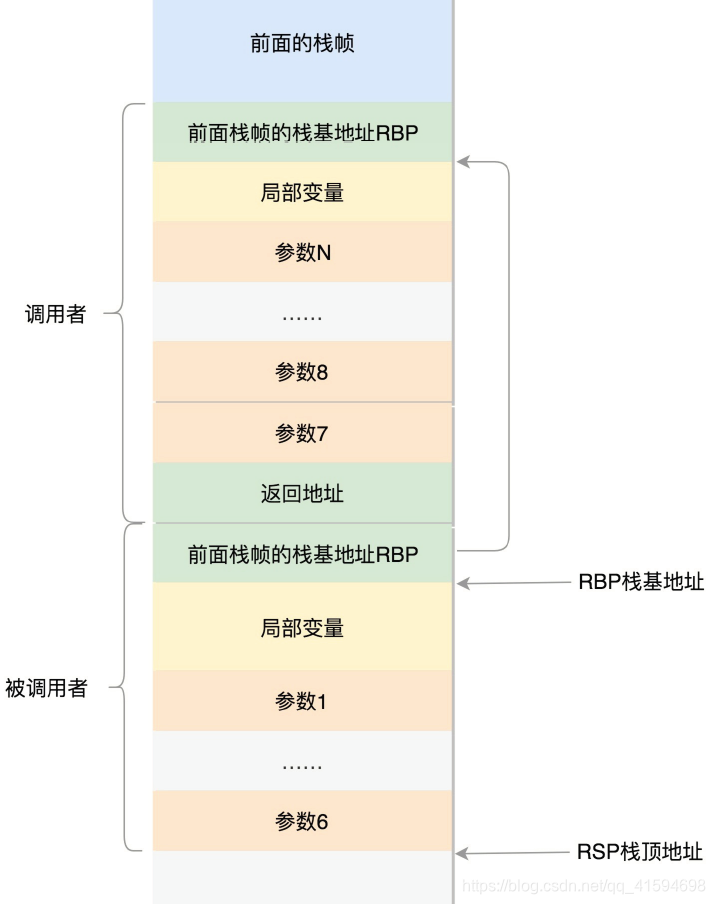
在进程的内存空间里面,栈是一个从高地址到低地址,往下增长的结构;
即上面是栈底,下面是栈顶,入栈和出栈的操作都是从下面的栈顶开始的。
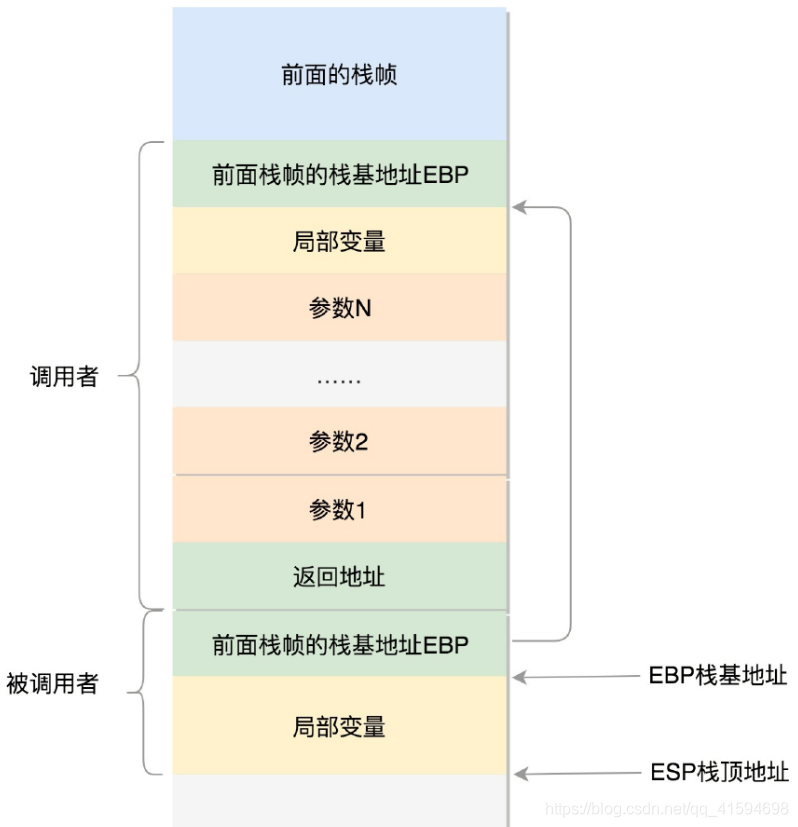
- 32位的情况
在CPU里,ESP(Extended Stack Pointer)是栈顶指针寄存器,入栈操作Push和出栈操作Pop指令,会自动调整ESP的值;
另外有一个寄存器EBP(Extended Base Pointer),是栈基地址指针寄存器,指向当前栈帧的最底部。
例如,A调用B,A的栈里面包含A函数的局部变量,然后是调用B的时候要传给它的参数,然后返回A的地址,这个地址也应该入栈,这就形成了A的栈帧。
接下来就是B的栈帧部分了,先保存的是A栈帧的栈底位置,也就是EBP;
因为在B函数里面获取A传进来的参数,就是通过这个指针获取的;
接下来保存的是B的局部变量等等;
当B返回的时候,返回值会保存在EAX寄存器中,从栈中弹出返回地址,将指令跳转回去,参数也从栈中弹出,然后继续执行A。
- 64位的情况
因为64位操作系统的寄存器数目比较多,所以会更多地利用寄存器;
rax用于保存函数调用的返回结果;
栈顶指针寄存器变成了rsp,指向栈顶位置,堆栈的Pop和Push操作会自动调整rsp;
栈基指针寄存器变成了rbp,指向当前栈帧的起始位置。
改变比较多的是参数传递:rdi、rsi、rdx、rcx、r8、r9这6个寄存器,用于传递存储函数调用时的6个参数。如果超过6的时候,还是需要放到栈里面。
然而,前6个参数有时候需要进行寻址,但是如果在寄存器里面,是没有地址的,因而还是会放到栈里面,只不过放到栈里面的操作是被调用函数做的。
10.2.2 内核态函数栈
通过系统调用,从进程的内存空间到内核中了;
内核中也有各种各样的函数调用来调用去的,也需要这样一个机制,此时,stack属性就派上了用场
Linux给每个task都分配了内核栈:
32位:
#define THREAD_SIZE_ORDER 1
//一个PAGE_SIZE是4K,左移一位就是乘以2,也就是8K。
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
64位:
#ifdef CONFIG_KASAN
#define KASAN_STACK_ORDER 1
#else
#define KASAN_STACK_ORDER 0
#endif
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
//在PAGE_SIZE的基础上左移两位,也即16K,并且要求起始地址必须是8192的整数倍。
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
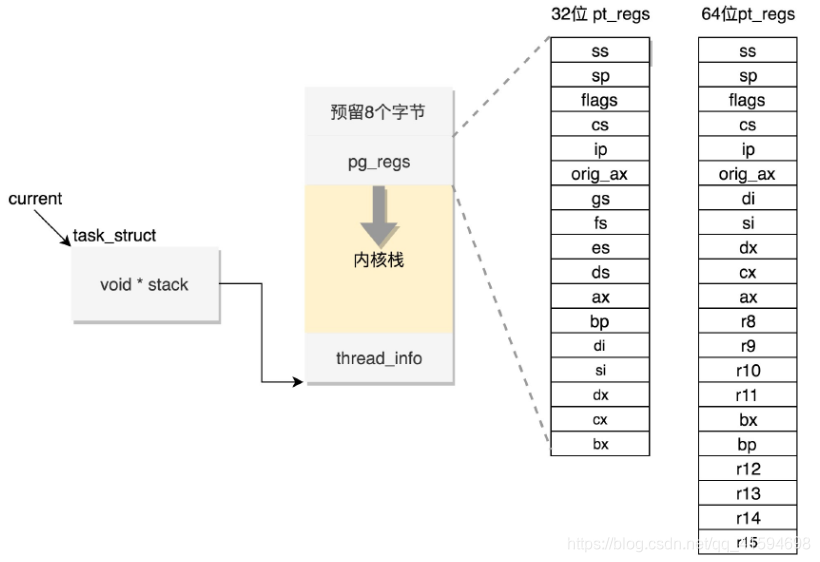
这段空间的最低位置,是一个thread_info结构,这个结构是对task_struct结构的补充;
因为task_struct结构庞大但是通用,不同的体系结构就需要保存不同的东西,所以往往与体系结构有关的,都放在thread_info里面。
在内核栈的最高地址端,存放的是另一个结构pt_regs;
当系统调用从用户态到内核态的时候,首先要做的第一件事情,就是将用户态运行过程中的CPU上下文保存起来;
其实主要就是保存在这个结构的寄存器变量里;
这样当从内核系统调用返回的时候,才能让进程在刚才的地方接着运行下去。
预留的8个字节是32位机器使用的,因为压栈pt_regs有两种情况:
CPU用ring来区分权限,从而Linux可以区分内核态和用户态;
因此,第一种情况,拿涉及从用户态到内核态的变化的系统调用来说;
因为涉及权限的改变,会压栈保存SS、ESP寄存器的,这两个寄存器共占用8个byte。
另一种情况是,不涉及权限的变化,就不会压栈这8个byte;
这样就会使得两种情况不兼容。如果没有压栈还访问,就会报错,所以就预留在这里,保证安全;
在64位上,修改了这个问题,变成了定长的。
10.2.2.1 通过task_struct找内核栈
通过函数task_stack_page,使用个task_struct的stack指针来找到对应的线程内核栈
如何找到相应的pt_regs?先从task_struct找到内核栈的开始位置,然后这个位置加上THREAD_SIZE就到了最后的位置,然后转换为struct pt_regs,再减一,就相当于减少了一个pt_regs的位置,就到了这个结构的首地址。
10.2.2.2 通过内核栈找task_struct
一个当前在某个CPU上执行的进程,想知道自己的task_struct在哪里,则需要通过给thread_info这个结构.
32位实现.它里面有个成员变量task指向task_struct,通过此结构来找到task_struct
64位实现.每个CPU运行的task_struct不通过thread_info获取了,而是直接放在Per CPU 变量里面了;
因为多核情况下,CPU是同时运行的,但是它们会共同使用其他的硬件资源的时候,所以我们需要解决多个CPU之间的同步问题;
而Per CPU变量就是内核中一种重要的同步机制:顾名思义,Per CPU变量就是为每个CPU构造一个变量的副
本,这样多个CPU各自操作自己的副本,互不干涉。
- 总结
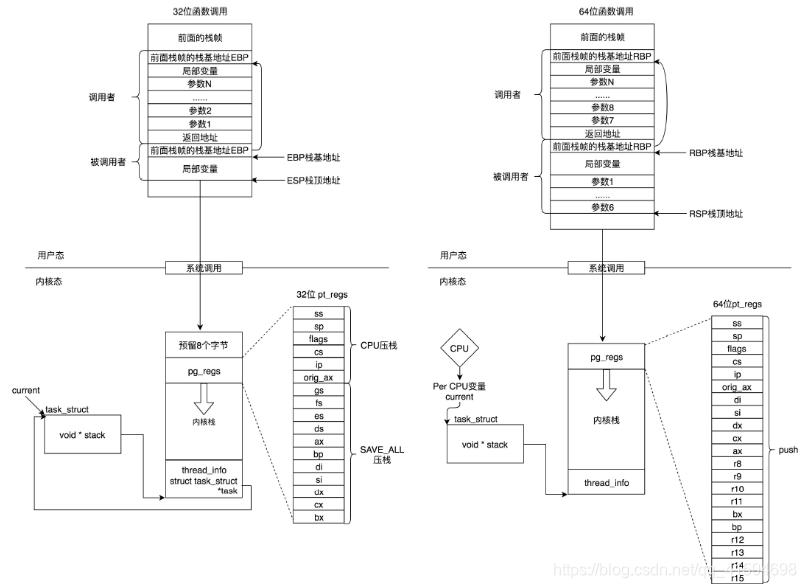
如果说task_struct的其他成员变量都是和进程管理有关的,那么内核栈是和进程运行有关系的。
在用户态,应用程序进行了至少一次函数调用;3
2位和64的传递参数的方式稍有不同,32位的就是用函数栈,64位的前6个参数用寄存器,其他的用函数栈。
在内核态,32位和64位都使用内核栈,格式也稍有不同,主要集中在pt_regs结构上。
在内核态,32位和64位的内核栈和task_struct的关联关系不同;
32位主要靠thread_info,64位主要靠Per-CPU变量。
11 调度(一):如何制定进程管理体系
task_struct解决了“看到”的问题,接下来解决“做到”的问题。
11.1 调度策略与调度类
一种称为实时进程,也就是需要尽快执行返回结果的那种;
另一种是普通进程,大部分进程都是这种
两种不同的进程,调度策略也不同,在task_struct中,有一个成员变量,就是叫调度策略:
unsigned int policy;
配合调度策略的,还有优先级,也在task_struct中:
int prio, static_prio, normal_prio;
unsigned int rt_priority;
11.2 实时调度策略
policy有以下取值:
#define SCHED_NORMAL 0
//高优先级的进程可以抢占低优先级的进程,而相同优先级的进程遵循先来先得
#define SCHED_FIFO 1
//时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性
//而高优先级的任务也是可以抢占低优先级的任务。
#define SCHED_RR 2
#define SCHED_BATCH 3
#define SCHED_IDLE 5
//按照任务的deadline进行调度
//当产生一个调度点的时候,DL调度器总是选择其deadline距离当前时间点最近的那个任务,并调度它执行。
#define SCHED_DEADLINE 6
11.3 普通调度策略
SCHED_NORMAL:普通的进程
SCHED_BATCH:后台进程,这类进程可以默默执行,不要影响需要交互的进程,可以降低他的优先级。
SCHED_IDLE:特别空闲的时候才跑的进程
11.4 具体执行者
policy和priority都设置了一个变量,表示了应该怎么干,那么交给谁干呢?
在task_struct里面,还有这样的成员变量,调度策略的执行逻辑,就封装在这里面,它是真正干活的那个:
const struct sched_class *sched_class;
其实现为:
stop_sched_class优先级最高的任务会使用这种策略,会中断所有其他线程,且不会被其他任务打断;
dl_sched_class就对应上面的deadline调度策略;
rt_sched_class就对应RR算法或者FIFO算法的调度策略,具体调度策略由进程的task_struct->policy指定;
fair_sched_class就是普通进程的调度策略;
idle_sched_class就是空闲进程的调度策略。
11.5 完全公平调度算法
普通进程使用的调度策略是fair_sched_class,顾名思义,对于普通进程来讲,公平是最重要的。
在Linux里面,实现了一个基于CFS的调度算法。CFS全称Completely Fair Scheduling,叫完全公平调度。
首先,你需要记录下进程的运行时间。
CPU会提供一个时钟,过一段时间就触发一个时钟中断,叫Tick。
CFS会为每一个进程安排一个虚拟运行时间vruntime。
如果一个进程在运行,随着时间的增长,也就是一个个tick的到来,进程的vruntime将不断增大。
没有得到执行的进程vruntime不变。
显然,那些vruntime少的,就说明受到了不公平的对待,需要给它补上,所以会优先运行这样的进程。
如果加上优先级,这就相当于N个口袋,优先级高的袋子大,优先级低的袋子小。这样球就不能按照个数分配了,要按照比例来,大口袋的放了一半和小口袋放了一半,里面的球数目虽然差很多,也认为是公平的。
综合起来就是:
得到当前的时间,以及这次的时间片开始的时间,两者相减就是这次运行的时间delta_exec ;
但是得到的这个时间其实是实际运行的时间,需要做一定的转化才作为虚拟运行时间vruntime。
转化方法如下:
虚拟运行时间vruntime += 实际运行时间delta_exec * NICE_0_LOAD/权重这就是说,同样的实际运行时间,给高权重的算少了,低权重的算多了,但是当选取下一个运行进程的时
候,还是按照最小的vruntime来的,这样高权重的获得的实际运行时间自然就多了
11.6 调度队列与调度实体
可以看出,CFS和其他的调度策略需要一个数据结构来对vruntime进行排序,找出最小的那个。
这个能够排序的数据结构不但需要查询的时候,能够快速找到最小的,更新的时候也需要能够快速的调整排序;
因为vruntime是经常在变的,变了再插入这个数据结构,就需要重新排序。
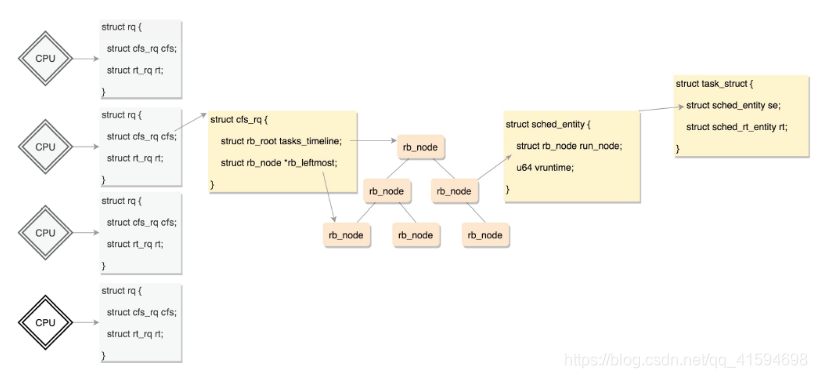
能够平衡查询和更新速度的是树,cfs_rq使用的是红黑树;
红黑树的的节点是应该包括vruntime的,称为调度实体。
task_struct中有如下成员变量:
struct sched_entity se;//完全公平算法调度实体
struct sched_rt_entity rt;//实时调度实体
struct sched_dl_entity dl;//Deadline调度实体
存放普通进程的调度实体的红黑树位置:每个CPU都有自己的 struct rq 结构,其用于描述在此CPU上所运行的所有进程,其包括一个实时进程队列rt_rq和一个CFS运行队列cfs_rq;
在调度时,调度器首先会先去实时进程队列rt_rq找是否有实时进程需要运行,如果没有才会去CFS运行队列cfs_rq找是否有进程需要运行。
普通进程调度相关的数据结构如下:
11.6.1 调度类是如何工作的?
调度类为sched_class,定义了很多种方法,用于在队列上操作任务;
也定义了一个指针,指向下一个调度类:11.4说过有5种调度类,它们其实是放在一个链表上的;
调度的时候是从优先级最高的调度类到优先级低的调度类,依次执行,不同的调度类有自己的实现。
即:当某个CPU需要找下一个任务执行的时候,会按照优先级依次调用调度类,不同的调度类操作不同
的队列。
rt_sched_class先被调用,它会在实时进程队列rt_rq上找下一个任务,只有找不到的时候,才轮到fair_sched_class被调用,它会在CFS运行队列cfs_rq上找下一个任务。
这样保证了实时任务的优先级永远大于普通任务。
11.7 总结
一个CPU上有一个队列;
CFS的队列是一棵红黑树,树的每一个节点都是一个sched_entity,每个sched_entity都属于一个task_struct,task_struct里面有指针指向这个进程属于哪个调度类:
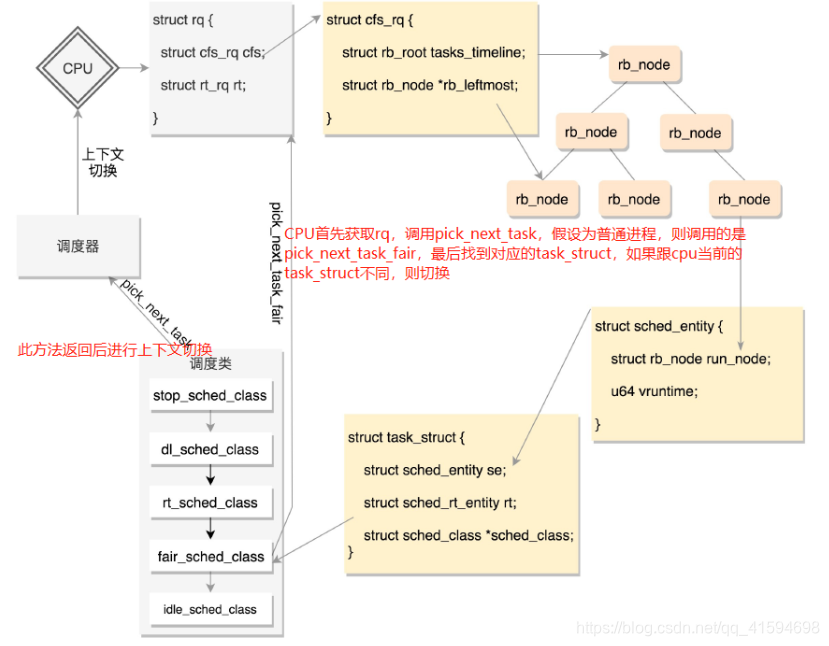
上下文切换的任务:一是切换进程空间,也即虚拟内存;二是切换寄存器和CPU上下文
使用时钟中断处理函数来进行抢占式调度,调用task_struct对应的调度类的task_tick函数来处理时钟事件
12 调度(二):主动调度是如何发生的?
为调度准备好了数据结构之后,调度是如何发生的呢?
调度概念:CPU在运行A进程,在某个时刻,换成运行B进程去了,有两种方式:
方式一:A进程运行着的时候,发现里面有一条指令sleep,也就是要休息一下,或者在等待某个I/O事件。那没
办法了,就要主动让出CPU,然后可以开始运行B进程。(主动调度)
方式二:A项目运行着的时候,旷日持久,实在受不了了。CPU介入了,说这个进程A先停停,B进程也要运行一下,要不然B进程该投诉了
12.1 主动调度
计算机主要处理计算、网络、存储三个方面。
计算主要是CPU和内存的合作;
网络和存储则多是和外部设备的合作;
在操作外部设备的时候,往往会等待数据,需要让出CPU,选择调用schedule()函数。
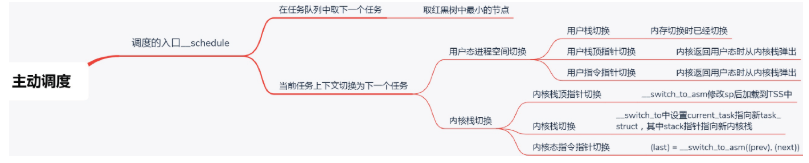
接下来学习schedule函数的调用过程:
首先在当前的CPU上取出任务队列rq;
第二步,获取下一个任务,为11.6.1所说的先获取调度类再获取任务;
第三步,当选出的继任者进程和前任进程不同,就要进行上下文切换,继任者进程正式进入运行。
12.2 进程上下文切换
主要任务:
一是切换进程空间,也即虚拟内存;
二是切换寄存器和CPU上下文。
12.3 总结
一个运行中的进程主动调用__ schedule让出CPU。
在 __schedule里面会做两件事情
第一是选取下一个进程,第二是进行上下文切换。
而上下文切换又分用户态进程空间的切换和内核态的切换。
proc文件系统里面可以看运行时间和切换次数,还可以看自愿切换和非自愿切换次数。
13 调度(三)抢占式调度是如何发生的?
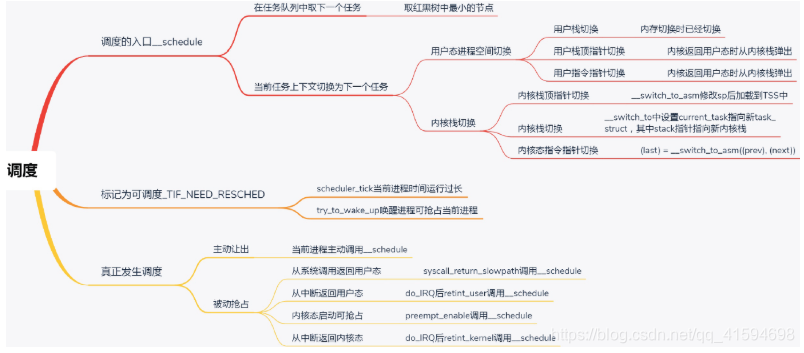
主动调度是第一种方式,第二种方式,就是抢占式调度。
什么情况下会发生抢占呢?
最常见的现象就是一个进程执行时间太长了,是时候切换到另一个进程了。
怎么衡量一个进程的运行时间呢?
在计算机里面有一个时钟,会过一段时间触发一次时钟中断,通知操作系统,时间又过去一个时钟周期,这是个很好的方式,可以查看是否是需要抢占的时间点。
另外一个可能抢占的场景是当一个进程被唤醒的时候。
当一个进程在等待一个I/O的时候,会主动放弃CPU。
但是当I/O到来的时候,进程往往会被唤醒。这个时候是一个时机。
当被唤醒的进程优先级高于CPU上的当前进程,就会触发抢占。
抢占时,首先会标识当前运行中的进程应该被抢占了,然后就需要真正的抢占动作,但是这需要一个让正在运行中的进程有机会调用一下__schedule的时机
13.1 用户态的抢占时机
对于用户态的进程来讲,从系统调用中返回的那个时刻,是一个被抢占的时机。
13.2 内核态的抢占时机
对内核态的执行中,被抢占的时机一般发生在在preempt_enable()中。
在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用preempt_disable()
关闭抢占,当再次打开的时候,就是一次内核态代码被抢占的机会。
在内核态也会遇到中断的情况,当中断返回的时候,返回的仍然是内核态。这个时候也是一个执行抢占的时
机
13.3 总结
整个进程的调度体系如图:
第一条总结了进程调度第一定律的核心函数__schedule的执行过程,为主动调度的流程
第二条总结了标记为可抢占的场景,第三条是所有的抢占发生的时机,这里是真正验证了进程调度第一定律
的。
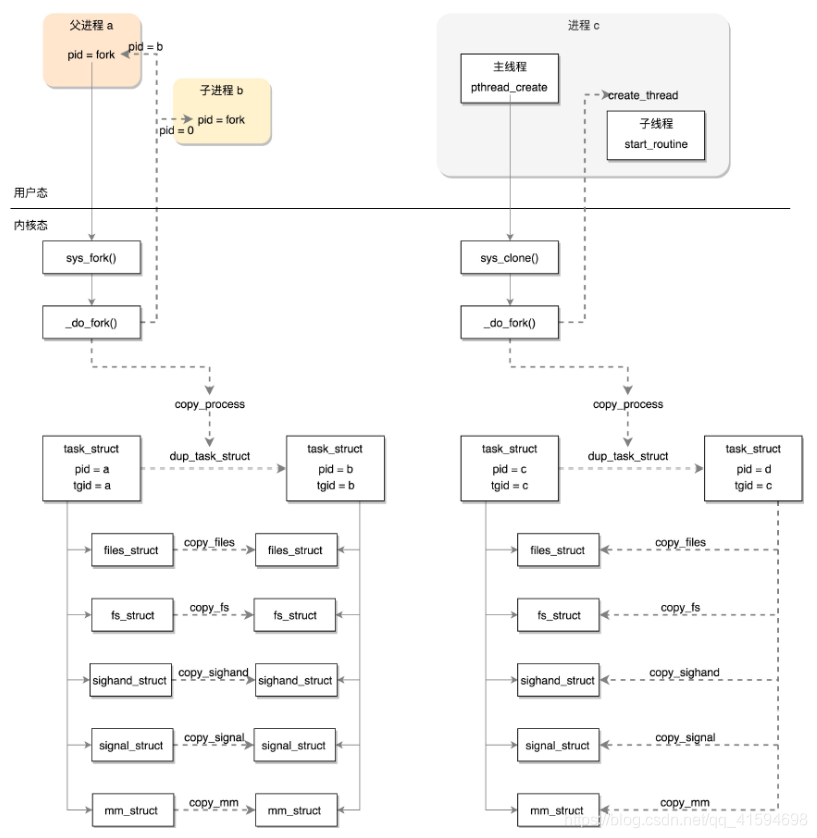
14 进程的创建
问题:创建进程这个动作在内核里都做了什么事情?
fork是一个系统调用,流程的最后会在sys_call_table中找到相应的系统调用sys_fork;
sys_fork会调用_do_fork。
14.1 fork做的第一件事
_do_fork里面做的第一件大事就是copy_process,因为如果所有数据结构都从头创建一份太麻烦了,直接复制就可以了
需要将整个task_struct复制一份,而且内核栈也要创建好。
然后就是权限相关
接下来是调度相关的变量
随后开始初始化文件和文件系统相关的变量
紧接着就是初始化与信号相关的变量
下一步就开始复制进程内存空间
复制完后,就开始分配pid,设置tid,group_leader,并且建立进程之间的亲缘关系
14.2 fork做的第一件事
_do_fork做的第二件大事是wake_up_new_task:唤醒新进程,因为新任务刚刚建立,看看有没有机会抢占别人,获得CPU
首先,需要将进程的状态设置为TASK_RUNNING。
如果是CFS的调度类,则执行相应的enqueue_task_fair,在enqueue_task_fair中取出的队列就是cfs_rq,然后调用enqueue_entity函数
此函数会更新运行的统计量,然后将节点加入到红黑树里面
回到enqueue_task_fair后,将这个队列上运行的进程数目加一,然后会看此进程是否能够抢占当前进程;
如果要,会将父进程标记为TIF_NEED_RESCHED
如果新创建的进程应该抢占父进程,在什么时间抢占呢?
因为fork是一个系统调用,而从系统调用返回的时候,是抢占的一个好时机;
如果父进程判断自己已经被设置为TIF_NEED_RESCHED,就让子进程先跑,抢占自己。
14.3 总结
fork系统调用的过程包含两个重要的事件:
一个是将task_struct结构复制一份并且初始化
另一个是试图唤醒新创建的子进程。
15 线程的创建
创建一个线程调用的是pthread_create
线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的。pthread_create不是一个系统调用,而是Glibc库的一个函数
- 线程的生命周期(pthread_create)
1
处理线程的属性参数
2
就像在内核里一样,每一个进程或者线程都有一个task_struct结构,在用户态也有一个用于维护线程的结构,就是一个pthread结构的变量
每个线程有自己的栈,所以此步就是传入属性参数和pthread结构来创建线程栈
线程栈是在进程的堆里面创建的
3
内核态创建任务:clone
第一步是标志位设定,将五大结构的引用计数加1,表示多了一个线程;
第二步是设置亲缘关系,因为要识别多个线程是不是属于一个进程;
第三部是处理信号,要保证发给进程的信号虽然可以被一个线程处理,但是影响范围应该是整个进程
的
用户态执行任务:
在start_thread入口函数中,真正的调用用户提供的函数
执行完用户的函数后,会释放这个线程相关的数据。
- 总结
创建进程调用的系统调用是fork,在copy_process函数里面,会将五大结构files_struct、fs_struct、
sighand_struct、signal_struct、mm_struct都复制一遍,从此父进程和子进程各用各的数据结构。
创建线程调用的系统调用是clone,在copy_process函数里面, 五大结构仅仅是引用计数加一,也即线程共
享进程的数据结构。