22 文件系统
可以永久保存文件
22.1 功能规划
需要考虑的问题:
1 文件系统要有严格的组织形式,使得文件能够以块为单位进行存储
2 文件系统中也要有索引区,用来方便查找一个文件分成的多个块都存放在了什么位置
3 如果文件系统中有的文件是热点文件,近期经常被读取和写入,文件系统应该有缓存层
4 文件应该用文件夹的形式组织起来,方便管理和查询,即分门别类,形成树形结构,也可以减少命名冲突,因为不同节点下的节点文件可以重名
5 Linux内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用
22.2 文件系统相关命令行
fdisk -l:查看格式化和没有格式化的分区
mkfs.ex4 盘:对指定分区盘建立分区,格式化为ext4格式
fdisk 盘:启动一个交互式程序,可以用来格式化为多个分区而不是一个
mount 盘 /根⽬录/⽤⼾A⽬录/⽬录1:格式化后的硬盘,需要挂在到某个目录下面,才能作为普通的文件系统进行访问

umount /根⽬录/⽤⼾A⽬录/⽬录1:卸载
Linux里面一切都是文件,那从哪里看出是什么文件呢?要从ls -l的结果的第一位标识位看出来:
-表示普通文件;
d表示文件夹;
c表示字符设备文件;
b表示块设备文件;
s表示套接字socket文件;
l表示符号链接,也即软链接,就是通过名字指向另外一个文件;
22.3 文件系统相关系统调用
open:打开一个文件。操作系统会创建一些数据结构来表示这个被打开的文件;
为了能够找到这些数据结构,在进程中会为这个打开的文件分配一个文件描述符fd(File Descriptor),用来区分一个进程打开的多个文件。
write:写入数据
lseek:重新定位读写的位置
read:读取数据
close:关闭一个文件
stat、fstat、lstat:返回与打开的文件描述符相关的文件状态信息;
这个信息将会写到类型为struct stat的buf结构中;
函数stat和lstat返回的是通过文件名查到的状态信息:stat没有处理符号链接(软链接)的能力。如果一个文件是符号链接,stat会直接返回它所指向的文件的属性;
而lstat返回的就是这个符号链接的内容;
fstat则是通过文件描述符获取文件对应的属性。
opendir函数:打开一个目录名所对应的DIR目录流。
readdir函数:从DIR目录流中读取一个项目
closedir函数:关闭参数dir所指的目录流
22.4 总结
文件系统的主要功能:
在文件系统上,需要维护文件的严格的格式,要通过mkfs.ext4命令来格式化为严格的格式。
每一个硬盘上保存的文件都要有一个索引,来维护这个文件上的数据块都保存在哪里。
文件通过文件夹组织起来,可以方便用户使用。
为了能够更快读取文件,内存里会分配一块空间作为缓存,让一些数据块放在缓存里面。
在内核中,要有一整套的数据结构来表示打开的文件。
在用户态,每个打开的文件都有一个文件描述符,可以通过各种文件相关的系统调用,操作这个文件描述
符。
23 硬盘文件系统
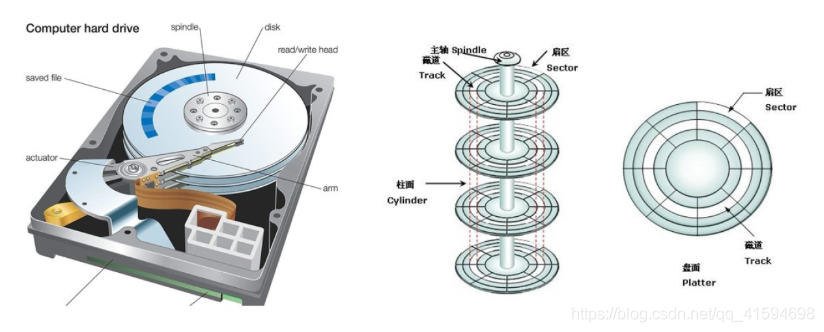
如图左边是最常见的硬盘,中间是磁盘的盘片,右边是盘片抽象出来的图;
每一层里分多个磁道,每个磁道分多个扇区,每个扇区是512个字节。
文件系统就是安装在这样的硬盘之上。
这一节重点分析目前Linux下最主流的文件系统格式——ext系列的文件系统的格式。
23.1 inode与块的存储
硬盘分成相同大小的单元,称为块(Block);
一块的大小是扇区大小的整数倍,默认是4K(大概8个扇区)。
一大块硬盘被分成了一个个小的块,用来存放文件的数据部分;
这样一来,如果我们存放一个文件,就不用给他分配一块连续的空间了;
我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。
这也带来一个新的问题,那就是文件的数据存放得太散,找起来就比较困难,可以使用一个索引结构来维护“某个文件分成几块、每一块在哪里“等等这些基本信息;
另外,文件还有元数据部分,例如名字、权限等也需要存储;
这就需要一个结构inode(index node)来存放
每个文件都会对应一个inode;
一个文件夹就是一个文件,也对应一个inode。
inode结构的信息:文件的读写权限i_mode,属于哪个用户i_uid,哪个组i_gid,大小是多少i_size_io,占用多少个块i_blocks_io;
i_atim最近一次访问文件的时间,i_ctime最近一次更改inode的时间,i_mtime最近一次更改文件的时间;
i_block保存文件具体分隔成块的块信息,如“某个文件分成几块、每一块在哪里”
ls命令列出来的权限、用户、大小这些信息,就是从文件对应的inode取出来的,这也是其原理
struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
......
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl_lo; /* File ACL */
__le32 i_size_high;
......
};
- “某个文件分成几块、每一块在哪里”这些信息具体是如何保存在i_block中的呢?
EXT4_N_BLOCKS一共有15项
ex2/ex3中前12项直接保存了块的位置,也就是说可以通过i_block[0-11],直接得到保存文件内容的块;
但是,如果一个文件比较大,12块放不下,当我们用到i_block[12]的时候,就不能直接放数据块的位置了,
要不然i_block很快就会用完了。
我们可以让i_block[12]指向一个块,这个块里面不放数据块,而是放数据块的位置,这个块我们称为间接块。也就是说,我们在i_block[12]里面放间接块的位置,通过i_block[12]找到间接块后,间接块里面放数据块的位置,通过间接块可以找到数据块。
如果文件再大一些,i_block[13]会指向一个块,我们可以用二次间接块。二次间接块里面存放了间接块的位置,间接块里面存放了数据块的位置,数据块里面存放的是真正的数据。如果文件再大一些,i_block[14]会指向三次间接块。原理和上面都是一样的,就像一层套一层的俄罗斯套娃,一层一层打开,才能拿到最中心的数据块:

出现的问题:对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
于是ex4做了一定的改变,使用了Extents。
比方说,一个文件大小为128M,如果使用4k大小的块进行存储,需要32k个块。
如果按照ext2或者ext3那样散着放,那分出来的数量就太大了。
但是Extents可以用于存放连续的块,也就是说,我们可以把128M放在一个Extents里面;
这样的话,对大文件的读写性能提高了,文件碎片也减少了。
Extends会保存成一棵树,树有一个个的节点,有叶子节点,也有分支节点。每个节点都有一个头,ext4_extent_header可以用来描述某个节点:
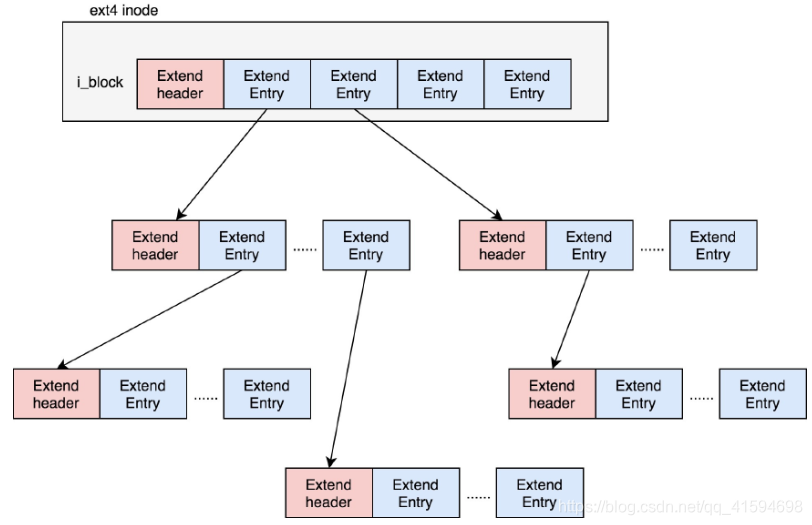
ext4_extent_header:
struct ext4_extent_header {
__le16 eh_magic; /* probably will support different formats */
__le16 eh_entries; /* number of valid entries */
__le16 eh_max; /* capacity of store in entries */
__le16 eh_depth; /* has tree real underlying blocks? */
__le32 eh_generation; /* generation of the tree */
};
eh_entries表示这个节点里面有多少项。
这里的项分两种:
如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点ext4_extent;
如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点ext4_extent_idx。
这两种类型的项的大小都是12个byte。
如果文件不大,inode里面的i_block中可以放得下一个ext4_extent_header和4项ext4_extent;
所以这个时候eh_depth为0,inode里面的就是叶子节点,树高度为0。
如果文件比较大,4个extent放不下,就要分裂成为一棵树,eh_depth>0的节点就是索引节点,其中根节点
深度最大,在inode中。
最底层eh_depth=0的是叶子节点。
除了根节点,其他的节点都保存在一个块4k里面,4k减掉ext4_extent_header的12个byte,剩下的能够放340项,每个extent最大能表示128MB的数据,340个extent会使你的表示的文件达到42.5GB;
如果还需要再大,可以增加树的深度。
23.2 inode位图和块位图
此时我们知道,硬盘上有一系列的inode和一系列的块排列起来。
接下来的问题是,如果要保存一个数据块,或者要保存一个inode,应该放在硬盘上的哪个位置呢?难
道需要将所有的inode列表和块列表扫描一遍,找个空的地方随便放吗?
这样效率太低了。所以文件系统里面专门弄了一个块来保存inode的位图。
在这4k里面,每一位对应一个inode。
如果是1,表示这个inode已经被用了;
如果是0,则表示没被用。
同样,文件系统也弄了一个块保存block的位图。
那么位图是如何起作用的呢?如调用open的时候,如果需要创建新文件,则从文件系统里面读取inode位图,然后找到下一个为0的inode,就是空闲的inode;block位图同理
23.3 文件系统的格式
数据块的位图是放在一个块里面的,共4k;
每位表示一个数据块,共可以表示
个数据块。
如果每个数据块也是按默认的4K,最大可以表示的空间为
个byte,也就是128M。
也就是说按照上面的格式,如果采用“一个块的位图+一系列的块”,外加“一个块的inode的位图+一系列
的inode的结构”,最多能够表示128M。太小了
我们把这个结构称为一个块组。那么只要有多个块组,就能表示更多的文件了
对于块组,我们也需要一个数据结构来表示为ext4_group_desc。
这里面对于一个块组里的inode位图bg_inode_bitmap_lo、块位图bg_block_bitmap_lo、inode列表bg_inode_table_lo,都有相应的成员变量。
这样一个个块组,就基本构成了整个文件系统的结构。
因为块组有多个,块组描述符也同样组成一个列表,我们把这些称为块组描述符表。
还需要有一个数据结构,对整个文件系统的情况进行描述,这个就是超级块ext4_super_block。
这里面有表示整个文件系统一共有多少inode的s_inodes_count;
表示一共有多少块的s_blocks_count_lo,
表示每个块组有多少inode的s_inodes_per_group,
表示每个块组有多少块的s_blocks_per_group等全局信息
对于整个文件系统,如果是一个启动盘,我们需要预留一块区域作为引导区,所以第一个块组的前面要留1K,用于启动引导区。
最终整个文件系统格如图所示:
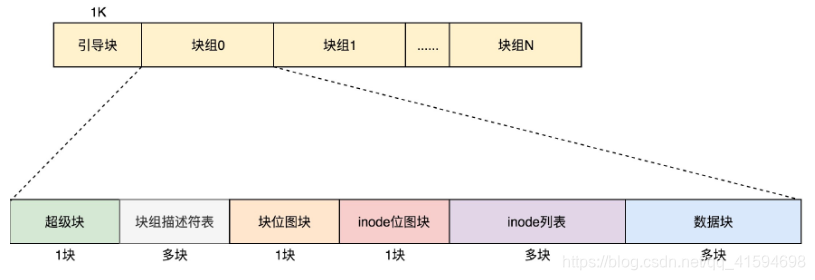
超级块和块组描述符表都是全局信息,而且这些数据很重要。
如果这些数据丢失了,整个文件系统都打不开了,这比一个文件的一个块损坏更严重。
所以,这两部分我们都需要备份,但是采取不同的策略。
- 策略
默认情况下,超级块和块组描述符表都有副本保存在每一个块组里面。
如果开启了sparse_super特性,超级块和块组描述符表的副本则只会保存在块组索引为0、3、5、7的整数幂里。
对于超级块来讲,由于超级块不是很大,所以就算我们备份多了也没有太多问题。
但是,对于块组描述符表来讲,如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大128M,而块组描述符表里面有多少项,这就限制了有多少个块组,128M * 块组的总数目是整个文件系统的大小,就被限制住了。
改进思路:Meta Block Groups
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,称为元块组(Meta Block
Group)。
每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含64个块组,这样一个元块组中
的块组描述符表最多64项。
假设一共有256个块组,原来是一个整的块组描述符表,里面有256项,要备份就全备份;
现在分成4个元块组,每一个元块组包含64个块组,每个元块组里面的块组描述符表就只有64项了,这就小多了,而且四个元块组自己备份自己的块组描述符表。
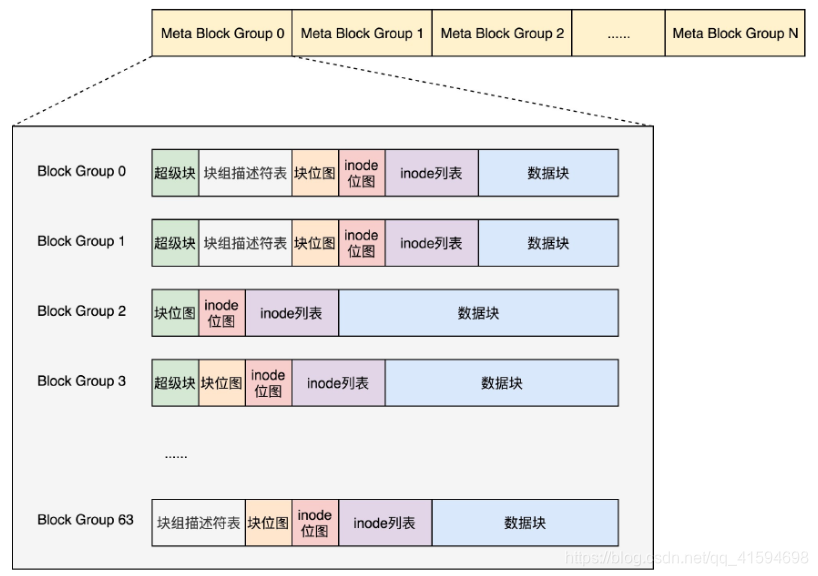
如图,每一个元块组包含64个块组,块组描述符表也是64项,备份三份,在元块组的第一个,第二个
和最后一个块组的开始处。
这样化整为零,我们就可以发挥出ext4的48位块寻址的优势了,在超级块ext4_super_block的定义中,我们
可以看到块寻址的分为高位和地位,均为32位,其中有用的是48位,2^48个块是1EB,足够用了。
23.4 目录的存储格式
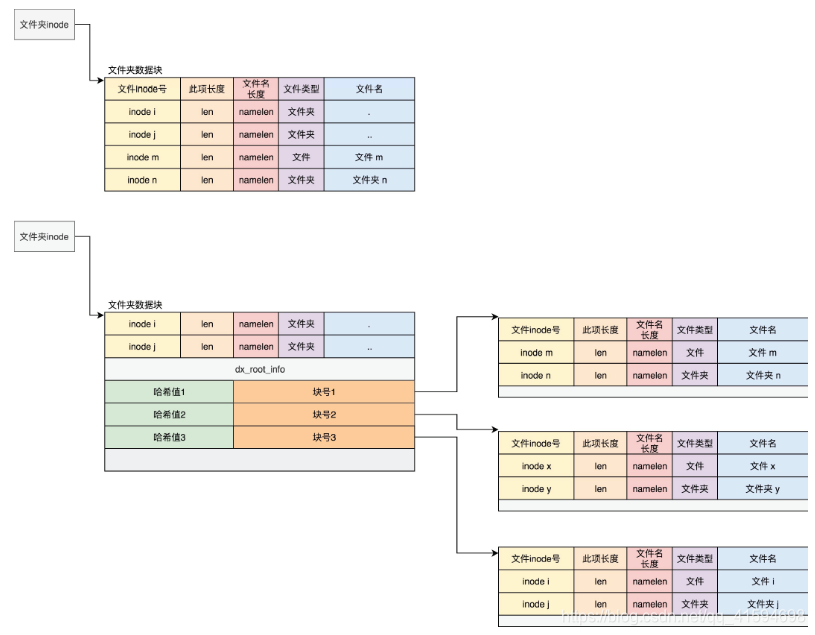
知道了一个普通的文件是如何存储的,那么文件夹(目录)是如何存储的?
其实目录本身也是个文件,也有inode,inode里面也是指向一些块。
和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息,这些信息称为ext4_dir_entry。
在目录文件的块中,最简单的保存格式是列表;
每一项都会保存这个目录的下一级的文件的文件名和对应的inode,通过这个inode,就能找到真正的文
件。
第一项是“.”,表示当前目录,第二项是“…”,表示上一级目录,接下来就是一项一项的文件名和inode。
有时候,如果一个目录下面的文件太多的时候,想在这个目录下找一个文件,按照列表一个个去找,太
慢了,于是我们就添加了索引的模式。
索引项dx_entry其实就是文件名的哈希值和数据块的一个映射关系;
如果我们要查找一个目录下面的文件名,可以通过名称取哈希。
如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是ext4_dir_entry_2的列表,我们只要一项一项找文件名就行;
通过索引树,我们可以将一个目录下面的N多的文件分散到很多的块里面,可以很快地进行查找。
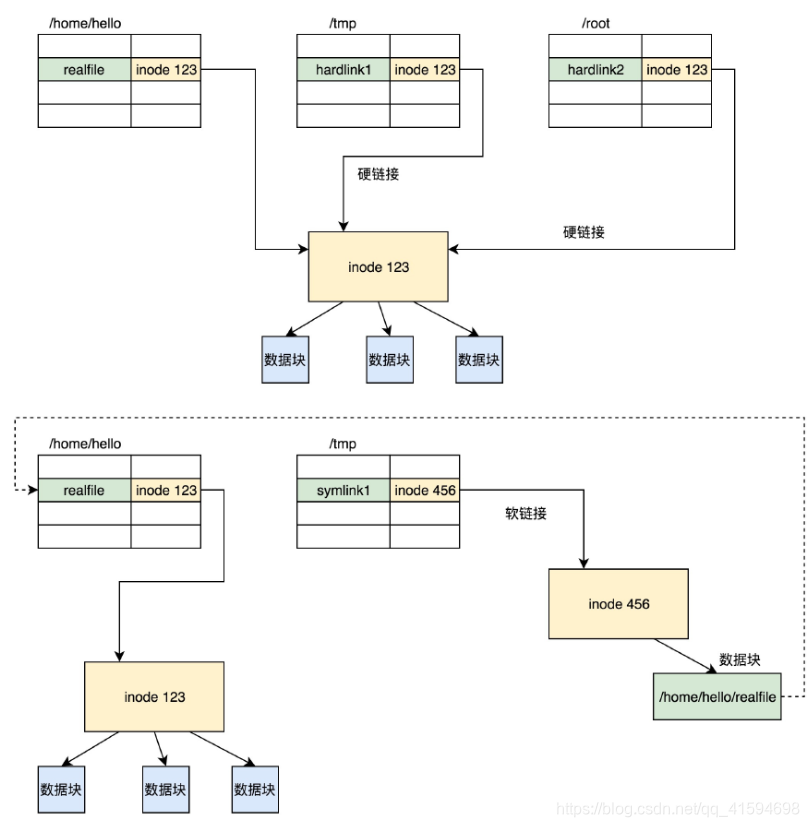
23.5 软链接和硬链接的存储格式
链接(Link)可以认为是文件的别名,而链接又可分为两种,硬链接与软链接。
ln -s创建的是软链接,不带-s创建的是硬链接。
它们有什么区别呢?在文件系统里面是怎么保存的呢?
如图所示,硬链接与原始文件共用一个inode的,但是inode是不跨文件系统的,每个文件系统都有自己的inode列表,因而硬链接是没有办法跨文件系统的。
而软链接不同,软链接相当于重新创建了一个文件。这个文件也有独立的inode,只不过打开这个文件看里面内容的时候,内容指向另外的一个文件。这就很灵活了。我们可以跨文件系统,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
23.6 总结
inode和数据块在文件系统上的关联关系:
无论是文件夹还是文件,都有一个inode。
inode里面会指向数据块;
对于文件夹的数据块,里面是一个表,是下一层的文件名和inode的对应关系;
文件的数据块里面存放的才是真正的数据。

24 虚拟文件系统
硬盘上的文件系统格式搭建好了,现在需要一个文件管理模块来管理文件
进程要想往文件系统里面读写数据,需要很多层的组件一起合作:
在应用层,进程在进行文件读写操作时,可通过系统调用如sys_open、sys_read、sys_write等。
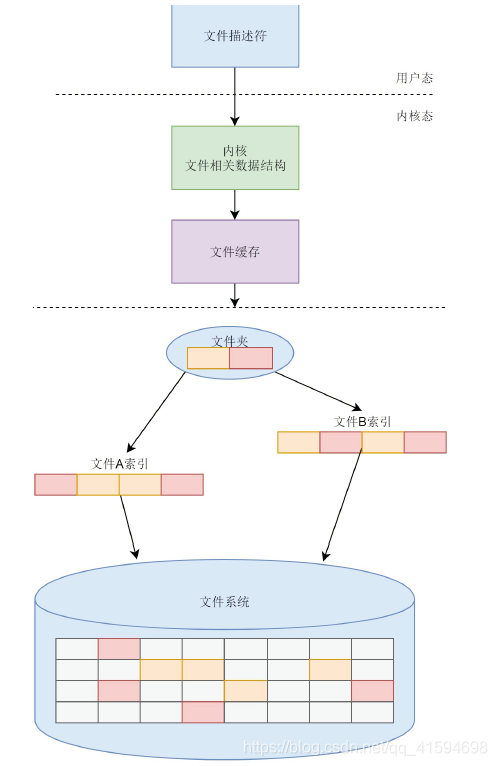
在内核,每个进程都需要为打开的文件,维护一定的数据结构。
在内核,整个系统打开的文件,也需要维护一定的数据结构。
Linux可以支持多达数十种不同的文件系统。它们的实现各不相同,因此Linux内核向用户空间提供了虚拟文件系统这个统一的接口,来对文件系统进行操作。
它提供了常见的文件系统对象模型,例如inode、directory entry、mount等,以及操作这些对象的方法,例如inode operations、directory operations、file operations等。然后就是对接的是真正的文件系统,如ext4文件系统。
为了读写ext4文件系统,要通过块设备I/O层,也即BIO层。这是文件系统层和块设备驱动的接口。
为了加快块设备的读写效率,我们还有一个缓存层。
最下层是块设备驱动程序。
接下来从几个最重要的系统调用逐层解析:
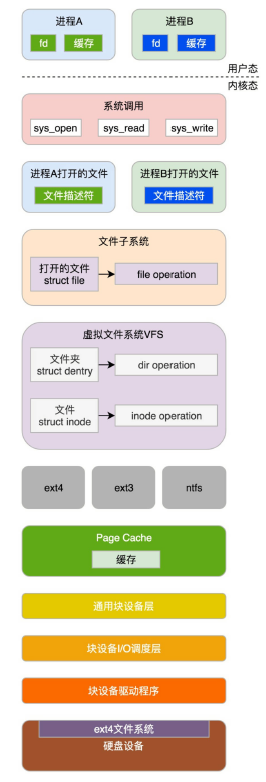
mount系统调用用于挂载文件系统;
open系统调用用于打开或者创建文件,创建要在flags中设置O_CREAT,对于读写要设置flags为O_RDWR;
read系统调用用于读取文件内容;
write系统调用用于写入文件内容。
24.1 挂载文件系统
想要操作文件系统,第一件事情就是挂载文件系统。
内核是不是支持某种类型的文件系统,需要我们进行注册才能知道,如ext4的register_filesystem;
如果一种文件系统的类型曾经在内核注册过,这就说明允许你挂载并且使用这个文件系统。
每个挂载的文件系统都对应一个struct mount结构,创建了此结构后,就开始挂载文件系统。
当所有的数据结构都读到内存里面,内核就可以通过操作这些数据结构,来操作文件系统了。
假设根文件系统下面有一个目录home,有另外一个文件系统A挂载在这个目录home下面,在文件系统A的根目录下面有另外一个文件夹hello。
由于文件系统A已经挂载到了目录home下面,所以我们就有了目录/home/hello,然后有另外一个文件系统B挂在在/home/hello下面。在文件系统B的根目录下面有另外一个文件夹world,在world下面有个文件夹data。由于文件系统B已经挂载到了/home/hello下面,所以我们就有了目录/home/hello/world/data。
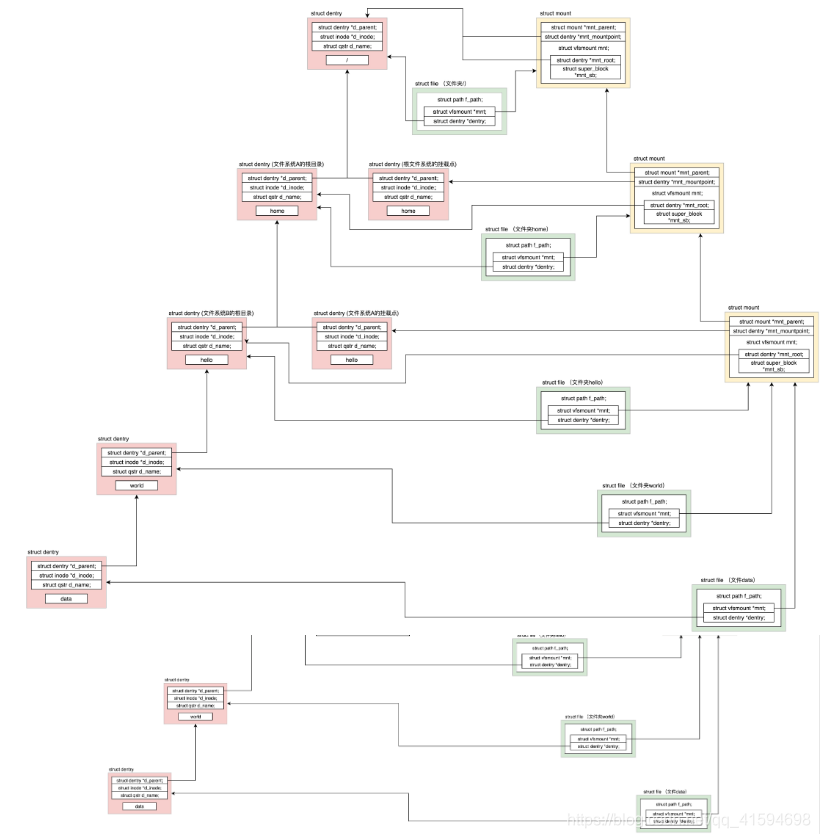
24.2 打开文件Open
在进程里面通过open系统调用打开文件,最终会调用到内核的系统调用实现sys_open
要打开一个文件,首先要通过get_unused_fd_flags从文件描述符列表里得到一个没有用的文件描述符。
Linux为了提高目录项对象的处理效率,设计与实现了目录项高速缓存dentry cache,简称dcache。它主要
由两个数据结构组成:
哈希表dentry_hashtable:dcache中的所有dentry对象都通过d_hash指针链到相应的dentry哈希链表中;
未使用的dentry对象链表s_dentry_lru:dentry对象通过其d_lru指针链入LRU链表中。LRU的意思是最近
最少使用,我们已经好几次看到它了。只要有它,就说明长时间不使用,就应该释放了:
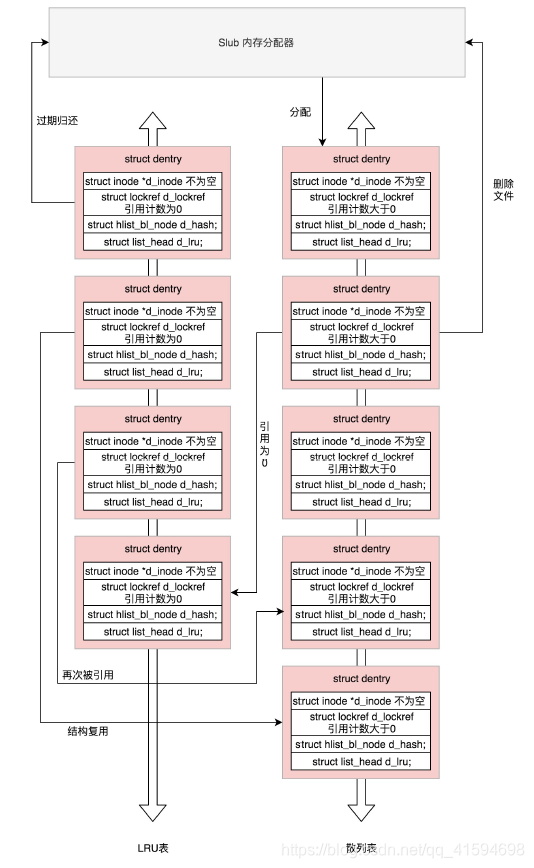
24.3 总结
有关文件的数据结构:
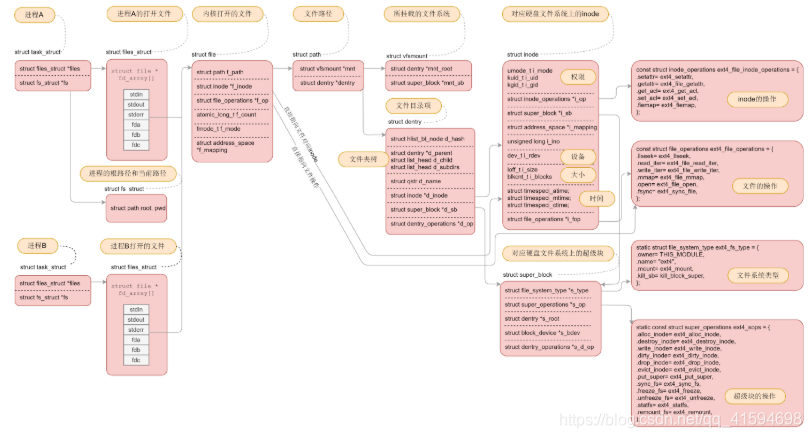
对于每一个进程,打开的文件都有一个文件描述符,在files_struct里面会有文件描述符数组,每一个文件描述符是这个数组的下标;
里面的内容指向一个file结构,表示打开的文件;
这个结构里面有这个文件对应的inode,最重要的是这个文件对应的操作file_operation。
如果操作这个文件,就是看这个file_operation里面的定义。
对于每一个打开的文件,都有一个dentry对应,虽然叫作directory entry,但是不仅仅表示文件夹,也表示文件;
它最重要的作用就是指向这个文件对应的inode。
如果说file结构是一个文件打开以后才创建的,dentry则是放在一个dentry cache里面的(dcache);
文件关闭了,dentry依然存在,因此他可以更长期的维护内存中的文件的表示和硬盘上文件的表示之间的关系。
inode结构就表示硬盘上的inode,包括块设备号等。
几乎每一种结构都有自己对应的operation结构,里面都是一些方法;
因此当后面遇到对于某种结构进行处理的时候,如果不容易找到相应的处理函数,就先找这个operation结构,就清楚了。
25 文件缓存
之前还没有对文件进行读写,还属于对于元数据的操作,本节开始讲解文件读写,即调用系统函数read和write
25.1 系统调用层和虚拟文件系统层
read:会调用相应文件系统的file_operations里面的read操作,
write:会调用相应文件系统file_operations里的write操作。
25.2 ext4文件系统层
对于ext4文件系统来讲,内核定义了一个ext4_file_operations。
读写的逻辑中,要区分是否使用缓存;
缓存其实是内存中的一块空间;
因为内存比硬盘快的多,Linux为了改进性能,有时候会选择不直接操作硬盘,而是将读写都在内存中,然后批量读取或者写入硬盘。一旦能够命中内存,读写效率就会大幅度提高。
因此,根据是否使用内存做缓存,我们可以把文件的I/O操作分为两种类型:
第一种类型是缓存I/O。
大多数文件系统的默认I/O操作都是缓存I/O。
对于读操作来讲,操作系统会先检查,内核的缓冲区有没有需要的数据;
如果已经缓存了,那就直接从缓存中返回;
否则从磁盘中读取,然后缓存在操作系统的缓存中。
对于写操作来讲,操作系统会先将数据从用户空间复制到内核空间的缓存中;
这时对用户程序来说,写操作就已经完成;
至于什么时候再写到磁盘中由操作系统决定,除非显式地调用了sync同步命令。第二种类型是直接IO,就是应用程序直接访问磁盘数据,而不经过内核缓冲区,从而减少了在内核缓存和
用户程序之间数据复制。
对于缓存来讲,需要文件和内存页进行关联,需要使用到address_space
25.2.1 带缓存的写
带缓存写入的函数generic_perform_write里是一个while循环。
此函数需要找出这次写入影响的所有的页,然后依次写入。对于每一个循环,主要做四件事情:
对于每一页,先调用address_space的write_begin做一些准备;
调用iov_iter_copy_from_user_atomic,将写入的内容从用户态拷贝到内核态的页中;
调用address_space的write_end完成写操作;
调用balance_dirty_pages_ratelimited,看脏页是否太多,需要写回硬盘。所谓脏页,就是写入到缓存,
但是还没有写入到硬盘的页面。
第一步会做日志相关的操作:Journal、order、writeback三个模式;
和得到应该写入的缓存页
第四步使用了回写机制(启动一个后台线程开始回写,回写的任务使用队列来保存),因为第三步并没有真正写入硬盘,仅仅是写入缓存后,标记为脏页,此时数据很危险,一旦宕机就没有了,所以需要一种机制,将写入的页面真正写到硬盘中
触发回写的时机:
1 当发现缓存的数据太多的时候,会触发回写
2 用户主动调用sync,将缓存刷到硬盘上去,最终会调用wakeup_flusher_threads,同步脏页
3 当内存十分紧张,以至于无法分配页面的时候,会调用free_more_memory,最终会调用wakeup_flusher_threads,释放脏页;
4 脏页已经更新了较长时间,时间上超过了timer,需要及时回写,保持内存和磁盘上数据一致性。
25.2.2 带缓存的读
带缓存读的函数generic_file_buffered_read里主要涉及预读的问题
需要先找到page cache里面是否有缓存页;
如果没有找到,不但读取这一页,还要进行预读(page_cache_sync_readahead函数中实现);
预读完了以后,再试一次查找缓存页,应该就能找到了。
如果第一次找缓存页就找到了,还是要判断是不是应该继续预读;
如果需要,就调用page_cache_async_readahead发起一个异步预读。
最后,copy_page_to_iter会将内容从内核缓存页拷贝到用户内存空间。
预读参考链接:https://www.cnblogs.com/dkblog/archive/2011/11/10/2244631.html
25.3 总结
ext4是一种日志文件系统,是为了防止突然断电的时候的数据丢失,引入了日志**(Journal)**模式。
日志文件系统比非日志文件系统多了一个Journal区域。
文件在ext4中分两部分存储,一部分是文件的元数据,另一部分是数据。元数据和数据的操作日志Journal也是分开管理的。
Journal模式在将数据写入文件系统前,必须等待元数据和数据的日志已经落盘才能发挥作用,这样性能比较差,但是最安全。
另一种模式是order模式。这个模式不记录数据的日志,只记录元数据的日志,但是在写元数据的日志前,必须先确保数据已经落盘。这个折中,是默认模式。
还有一种模式是writeback,不记录数据的日志,仅记录元数据的日志,并且不保证数据比元数据先落盘,这个性能最好,但是最不安全。
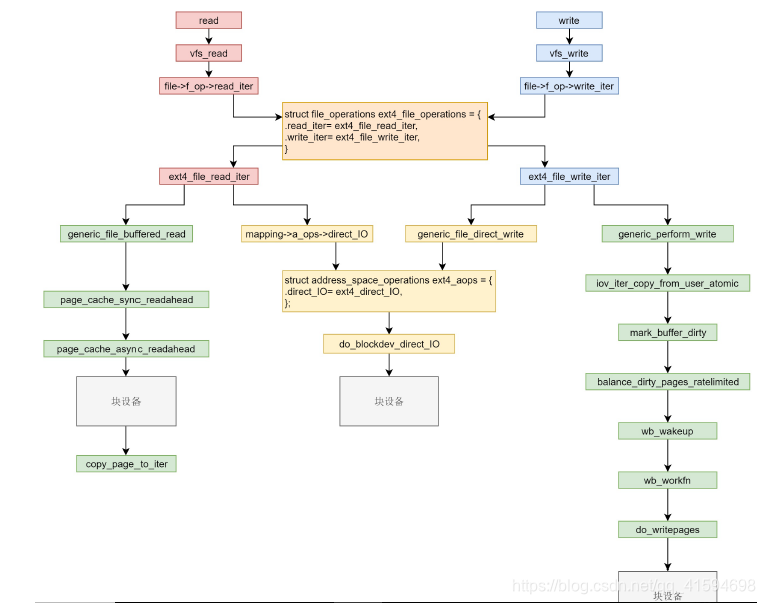
read和write在VFS层调用的是vfs_read和vfs_write并且调用file_operation。在ext4层调用的是ext4_file_read_iter和ext4_file_write_iter。
接下来就是分叉,分为缓存I/O和直接I/O。
直接I/O的读和写是一样的,调用ext4_direct_IO,再往下就调用块设备层了。
缓存I/O读和写则不一样
对于读,从块设备读取到缓存中,然后从缓存中拷贝到用户态;
对于写,从用户态拷贝到缓存,设置缓存页为脏页,然后启动一个线程写入块设备。