容器网络总览
Linux 容器“网络栈”实际上是被隔离 在它自己的 Network Namespace 当中的,其包括了:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则;
对于一个进程来说,这些要素构成了它发起和响应网络请求的基本环境
容器可以声明直接使用宿主机的网络栈,但是会引入共享网络资源的问题,比如端口冲突,所以一般希望容器进程能使用自己 Network Namespace 里的网络栈,即拥有属于自己的 IP 地址和端口
容器之间如何进行交互
Docker 会默认在宿主机上创建一个名叫 docker0 的网桥,凡是连接在 docker0 网桥上的容器,就可以通过它来进行通信
使用Veth Pair虚拟设备来连接容器,Veth Pair被创建出来后,以两张虚拟网卡(Veth Peer)的形式成对出现,从其中一个网卡发出的数据包,可以直接出现在与它对应的另一张网卡上,即便这两个网卡在不同的 Network Namespace 里
使用相关命令,可以看到容器里有一张叫作 eth0 的网卡,它正是一个 Veth Pair 设备在容器里的这一 端, Veth Pair 设备的另一端则在宿主机上,被插在了docker0 上
容器之间的通信如下图:
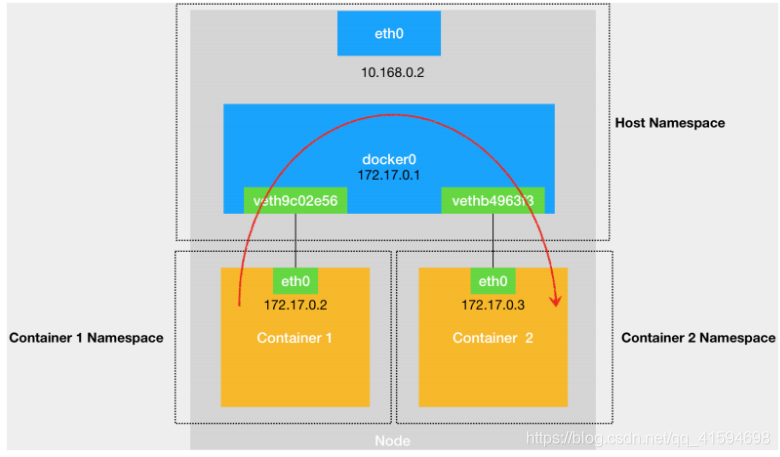
外部访问该宿主机上的容器的 IP 地址时,这个请求的数据包, 也是先根据路由规则到达 docker0 网桥,然后被转发到对应的 Veth Pair 设备,最后出现在容器里:
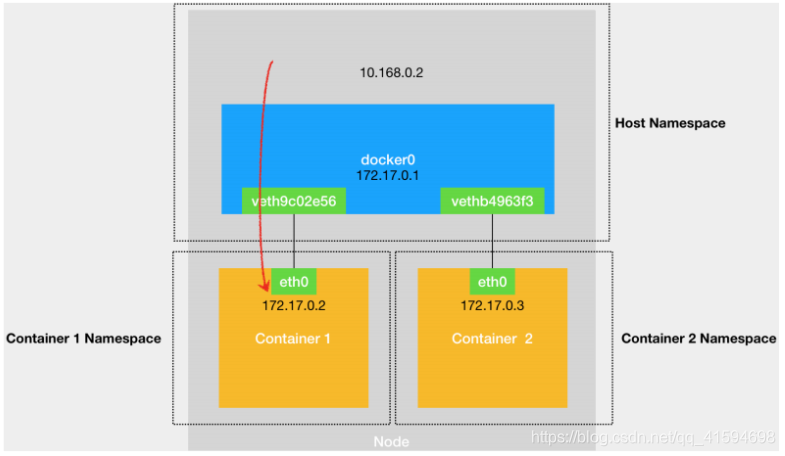
当一个容器连接到另外一个宿主机时,它发出的请求数 据包,首先经过 docker0 网桥出现在宿主机上,然后根据宿主机的路由表里的直连路由规则 (10.168.0.0/24 via eth0)),访问请求会交给宿主机的 eth0 处理:
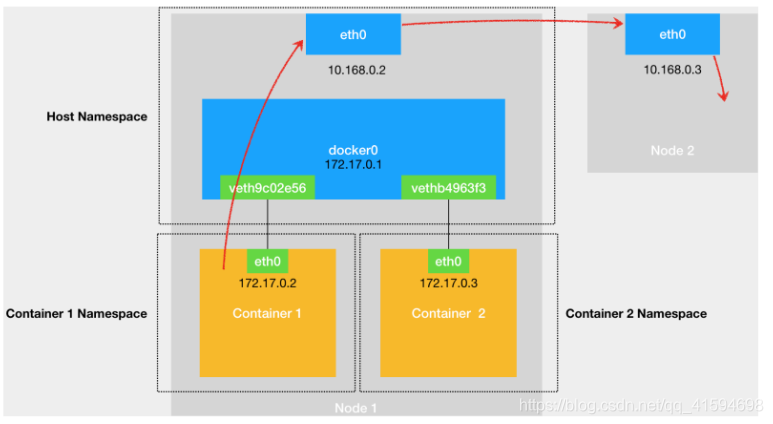
不同宿主机的容器互联,则使用Ovberlay NetWork(覆盖网络),即创建一个整个集群“公用”的网桥,然后把集群里的所有容器都连接到这个网桥上,就可以相互通信了:
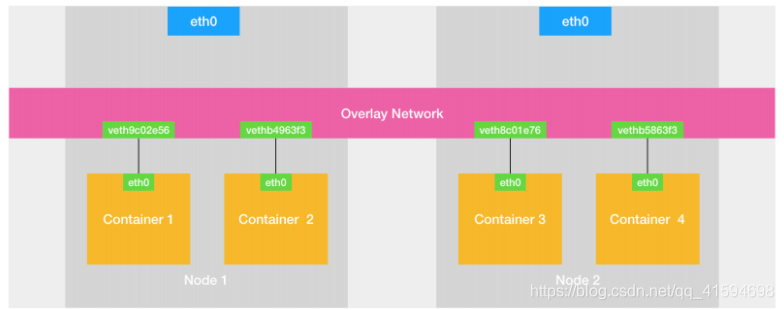
容器跨主机网络
使用Flannel,其有三种模式:VXLAN、host-gw、UDP
flanneld进程会保存中介设备的信息在路由规则里,如UDP的flannel0,VXLAN的VTEP
基于 Flannel UDP 模式的原理图:
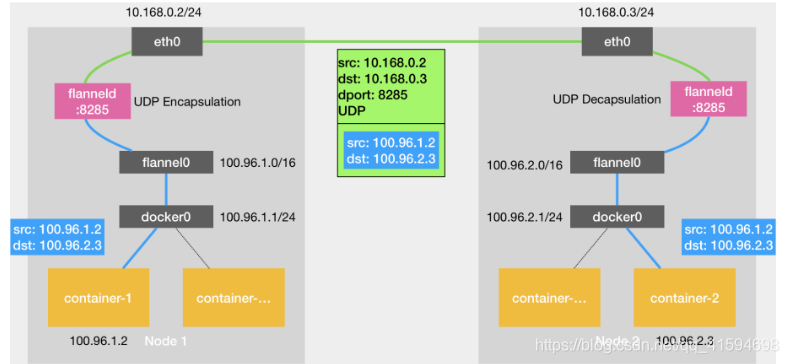
flannel0 是一个 TUN 设备(Tunnel 设备),是一个工作在三层(Network Layer)的虚拟网络设备,其功能为:在操作系统内核和用户应用程序之间传递 IP 包
flanneld 通过保存在Etcd中的子网与宿主机的对应关系,通过ip找到对应的子网,子网匹配对应的宿主机
Flannel UDP 模式提供的是一个三层的 Overlay 网络,即:
首先对发出端的 IP 包进行 UDP 封装,然后在接收端进行解封装拿到原始的 IP 包,进而把这个 IP 包转发给目标容 器;
这就好比,Flannel 在不同宿主机上的两个容器之间打通了一条“隧道”,使得这两个容器可以直接使用 IP 地址进行通信,而无需关心容器和宿主机的分布情况
该模式的性能相对比较差,因为相比于两台宿主机之间的直接通信,基于 Flannel UDP 模式的容器通信多了一个额外的步骤,即 flannel0 的处理过程;
而这个过程,由于使用到了 flannel0 这个 TUN 设备,仅在发出 IP 包的过程中,就需要经过三次用户态与内核态之间的数据拷贝:
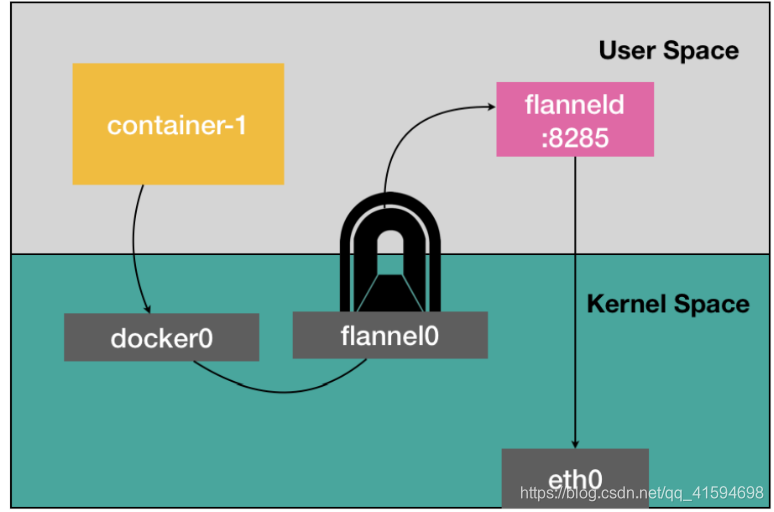
进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态 的切换次数,并且把核心的处理逻辑都放在内核态进行;
因此Flannel 后来支持的 VXLAN 模式((虚拟可扩展局域网),逐渐成为了主流的容器网络方案
VXLAN是 Linux 内核本身就支持的一种网络 虚似化技术。所以VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
设计思想:
在现有的三层网络之上,“覆盖”一层虚拟的、由内核 VXLAN 模块负责维护的二层网络,使得连接在这个 VXLAN 二层网络上的“主机”(虚拟机或者容器)之间,可以像在同一个局域网(LAN)里那样自由通信
而这些“主机”可能分布在不同的宿主机上,甚至是分布在不同的物理机房里,为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧 道”的两端,这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)
VTEP 设备的作用,其实跟前面的 flanneld 进程非常相似,只不过,它进行封装和解封装的对 象,是二层数据帧(Ethernet frame),而且这个工作的执行流程,全部是在内核里完成的(因为VXLAN 本身就是 Linux 内核中的一个模块)
其原理图如下:
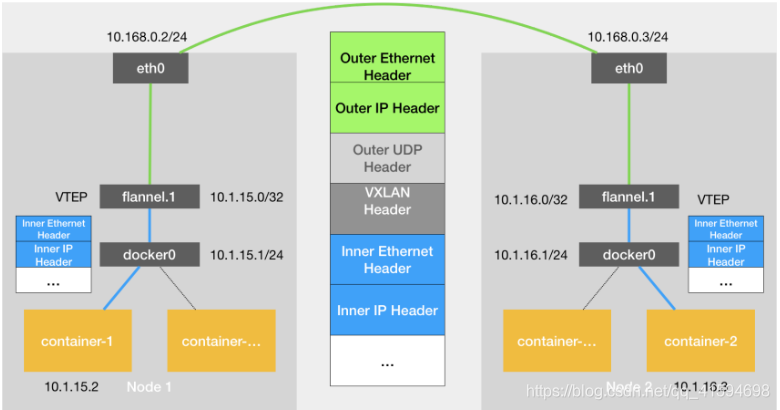
flannel.1就是VTEP设备,有IP有MAC,进行转发的数据就不是保存在Etcd里了,而是存在于一个叫作 FDB(Forwarding Database)的转发数据库里
flanneld 进程在 Node 2 节点启动时,自动在 Node 1 上 添加ARP记录,方便得到mac地址,封装数据包
总结一下,用户的容器都连接在 docker0 网桥上。而网络插件则在宿主机上创建了一个特殊的设备(UDP 模式创建的是 TUN 设备,VXLAN 模式创建的则是 VTEP 设备),docker0 与这个设备之间,通过 IP 转发(路由表)进行协作;
网络插件真正要做的事情,则是通过某种方法,把不同宿主机上的特殊设备连通,从而达到容器跨主机通信的目的
flannel 的 host-gw 模式则是一种纯三层的网络方案:

host-gw 模式的工作原理是将每个 Flannel 子网(Flannel Subnet,比 如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。
Kubernetes网络模型
网络模型为:
1 所有容器都可以直接使用 IP 地址与其他容器通信,而无需使用 NAT
2 所有宿主机都可以直接使用 IP 地址与所有容器通信,而无需使用 NAT。反之亦然
3 容器自己“看到”的自己的 IP 地址,和别人(宿主机或者容器)看到的地址是完全一样 的。
Kubernetes 对容器网络的主要处理方法也是同上文,不过是通过一个叫作 CNI 的接口,维护了一个单独的网桥来代替 docker0;
这个网桥的名字就叫作:CNI 网桥,它在宿主机上的设备名称默认是:cni0
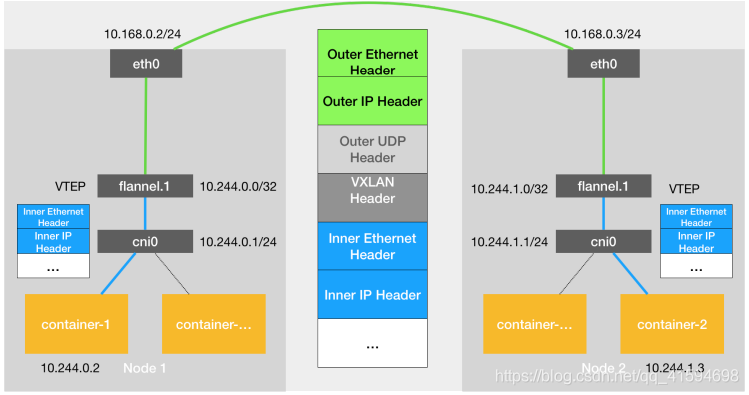
Kubernetes 之所以要设置这样一个与 docker0 网桥功能几乎一样的 CNI 网桥,主要原因包括两个方面:
1 Kubernetes 项目并没有使用 Docker 的网络模型(CNM),所以它并不希望、也 不具备配置 docker0 网桥的能力;
2与 Kubernetes 如何配置 Pod,也就是 Infra 容器的 Network Namespace 密切相关
CNI 的设计思想:Kubernetes 在启动 Infra 容器之后,就可以直接调用 CNI 网络 插件,为这个 Infra 容器的 Network Namespace,配置符合预期的网络栈。
(CNI原理todo)
soft multi-tenancy
NetworkPolicy 实际上只是宿主机上的一系列 iptables 规则,这跟传统 IaaS 里面 的安全组(Security Group)其实是非常类似的。
服务发现
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
Service 一旦被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加,而作为对这个事件的响应,它就会在宿主机上创建一条 iptables 规则,比如:凡是目的地址是 10.0.1.175、目的端口是 80 的 IP 包,都应该跳转到另外一条名叫 KUBE-SVC-NWV5X2332I4OT4T3的 iptables 链进行处理,链指向的最终目的地,其实就是这个 Service 代理的三个 Pod。
IPVS 模式的 Service,可以解决这样一个问题:当宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大 量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中(所以基于 iptables 的 Service 实现,都是制约 Kubernetes 承载更多量级的 Pod 的主要障碍)
IPVS 模式的工作原理,其实跟 iptables 模式类似,相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这 一层上,理论上 IPVS 并没有显著的性能提升。但是,IPVS 并不需要在宿主机上为每个 Pod 设 置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。
那么如何从外部 (Kubernetes 集群之外),访问到 Kubernetes 里创建的 Service?最常用的方式就是NodePort
NodePort 模式中,kube-proxy 要做的就是在每台宿主机上生成 iptables 规则:KUBE-SVC-67RL4FN6JRUPOJYM ,其实就是一组随机模式的 iptables 规则
还有LoadBalancer 和 External Name
这三种方式中,每个 Service 都要有一个负载均衡服务,既浪费成本又高;
作为用户,更希望看到 Kubernetes 内置一个全局的负载均 器,然后通过访问的 URL把请求转发给不同的后端 Service。
这种全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的 Ingress 服务,可以使用 Kubernetes 的 Ingress 来创建一个统一的负载均衡器,从而实现当用户访问不同的域名时,能够访问到不同的 Deployment