29 进程间通信
29.1 管道模型
上一个阶段完全做完,才将输出结果交给下一个阶段
“|”就是一个管道。它会将前一个命令的输出,作为后一个命令的输入。
管道是一种单向传输数据的机制,它其实是一段缓存,里面的数据只能从一端写入,从另一端读出。
如果想互相通信,需要创建两个管道才行。
管道分为两种类型:
“|” 表示的管道称为
匿名管道,意思就是这个类型的管道没有名字,用完了就销毁了。
竖线代表的管道随着命令的执行自动创建、自动销毁。用户甚至都不知道自己在用管道这种技术,就已经解决了问题另外一种类型是
命名管道。这个类型的管道需要通过mkfifo命令显式地创建。
管道以文件的形式存在,符合Linux里面一切皆文件的原则。
创建了一个命名管道后,如果向里面写入东西,这个时候,如果管道里面的内容没有被读出,这个命令就是停在这里的,需要重新连接一个终端读取管道里面的内容,这时候写入东西的终端才能正常退出
小结:管道模型的效率比较低下,因为两个进程之间无法频繁地沟通,此模型不适合进程间频繁的交换数据
29.2 消息队列模型
和管道将信息全部从一个进程倒给另一个进程不同,此模型在发送数据时,会分成一个一个独立的数据单元,也就是消息体,每个消息体都是固定大小的存储块,在字节流上不连续
消息结构的定义如下:类型type和正文mtext没有强制规定,只要消息的发送方和接收方约定好即可。
struct msg_buffer {
long mtype;
char mtext[1024];
};
接下来需要使用msgget函数创建一个消息队列。
这个函数需要有一个参数key,这是消息队列的唯一标识,应该是唯一的。
如何保持唯一性呢?
可以指定一个文件,ftok会根据这个文件的inode,生成一个近乎唯一的key,只要在这个消息队列的生命周期内,这个文件不要被删除就可以了。
只要不删除,无论什么时刻,再调用ftok,也会得到同样的key。
这种key的使用方式在进程间通信会经常遇到,这是因为它们都属于System V IPC进程间通信机制体系中。
System V IPC体系有一个统一的命令行工具:ipcmk,ipcs和ipcrm用于创建、查看和删除IPC对象。
如,ipcs -q就能看到创建的消息队列对象。
如何发送消息?
发送消息主要调用msgsnd函数。
第一个参数是message queue的id;
第二个参数是消息的结构体;
第三个参数是消息的长度;
最后一个参数是flag,IPC_NOWAIT表示发送的时候不阻塞,直接返回。
如何接收消息?
接收消息主要调用msgrcv函数。
第一个参数是message queue的id;
第二个参数是消息的结构体;
第三个参数是可接受的最大长度;
第四个参数是消息类型,最后一个参数是flag,IPC_NOWAIT表示接收的时候不阻塞,直接返回。
小结:有了消息这种模型,两个进程之间的通信可以频繁沟通了,不会被阻塞
29.3 共享内存模型
有时候,进程之间的沟通需要特别紧密,而且要分享一些比较大的数据。
如果使用消息队列,就发现一方面消息的来去不及时;另外一方面,消息的大小也有限制
因此可以在两个进程需要通信的期间,使它们共享内存,直接交流
本来:每个进程都有自己独立的虚拟内存空间,不同的进程的虚拟内存空间映射到不同的物理内存中去。
这个进程访问A地址和另一个进程访问A地址,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
使用此模式后:拿出一块虚拟地址空间来,映射到相同的物理内存中。
这样这个进程写入的东西,另外一个进程马上就能看到了,不需要拷贝来拷贝去,传来传去。
共享内存也是System V IPC进程间通信机制体系中的,所以从它的使用流程可以看到熟悉的面孔
如何创建共享内存:
调用shmget创建一个共享内存:
在这个体系中,创建一个IPC对象都是xxxge;
这里面第一个参数是key,和msgget里面的key一样,都是唯一定位一个共享内存对象,也可以通过关联文件的方式实现唯一性;
第二个参数是共享内存的大小;
第三个参数如果是IPC_CREAT,同样表示创建一个新的
创建完毕之后,我们可以通过ipcs命令查看这个共享内存
接下来,如果一个进程想要访问这一段共享内存,需要通过shmat函数将这个内存加载到自己的虚拟地址空间的某个位置,就是attach的意思。
其中addr就是要指定attach到这个地方。但是这个地址的设定难度比较大,除非对于内存布局非常熟悉,否则可能会attach到一个非法地址。所以,通常的做法是将addr设为NULL,让内核选一个合适的地址。返回值就是真正被attach的地方。
如果共享内存使用完毕,可以通过shmdt解除绑定,然后通过shmctl,将cmd设置为IPC_RMID,从而删除这个共享内存对象。
29.3.1 信号量
如果两个进程attach同一个共享内存,都往里面写东西,很有可能就冲突了。
例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。
所以,这里就需要一种保护机制,使得同一个共享的资源,同时只能被一个进程访问。
在System V IPC进程间通信机制体系中使用信号量(Semaphore)来保证。
因此,信号量和共享内存往往要配合使用。
信号量其实是一个计数器,主要用于实现进程间的互斥与同步,而不是用于存储进程间通信数据:
可以将信号量初始化为一个数值,来代表某种资源的总体数量。
对于信号量来讲,会定义两种原子操作;
一个是P操作,称为申请资源操作。这个操作会申请将信号量的数值减去N,表示这些数量被他申请使用了,其他人不能用了。
另一个是V操作,我们称为归还资源操作,这个操作会申请将信号量加上M,表示这些数量已经还给信号量了,其他人可以使用了。
如何创建信号量:
通过semget函数。
第一个参数key也是类似的;
第二个参数num_sems不是指资源的数量,而是表示可以创建多少个信号量,形成一组信号量,也就是说,如果你有多种资源需要管理,可以创建一个信号量组。接下来需要通过semctl函数初始化信号量的总的资源数量
第一个参数semid是这个信号量组的id;
第二个参数semnum是在这个信号量组中某个信号量的id;
第三个参数是命令,如果是初始化,则用SETVAL;
第四个参数是一个union。如果初始化,应该用里面的val设置资源总量。
如何使用信号量:
无论是P操作还是V操作,统一用semop函数
第一个参数还是信号量组的id,一次可以操作多个信号量;
第三个参数numops就是有多少个操作;
第二个参数将这些操作放在一个数组中。数组的每一项是一个struct sembuf
里面的第一个成员是这个操作的对象是哪个信号量;
第二个成员就是要对这个信号量做多少改变;如果sem_op < 0,就请求sem_op的绝对值的资源。如果相应的资源数可以满足请求,则将该信号量的值减去sem_op的绝对值,函数成功返回。当相应的资源数不能满足请求时,就要看sem_flg了。
如果把sem_flg设置为IPC_NOWAIT,也就是没有资源也不等待,则semop函数出错返回EAGAIN。
如果sem_flg 没有指定IPC_NOWAIT,则进程挂起,直到当相应的资源数可以满足请求。
若sem_op > 0,表示进程归还相应的资源数,将 sem_op 的值加到信号量的值上。
如果有进程正在休眠等待此信号量,则唤醒它们。
补充https://blog.csdn.net/cx2479750196/article/details/81150955
信号量可以理解为是一个计数器加上等待队列,它主要侧重了同步于互斥,因为有时候多个进程同时访问临界资源就会产生死锁,那么就需要信号量记录可申请的资源的数量
每申请一次信号量减1,用完释放就加1,等待队列就是资源被申请完了(信号量为0),再申请时发现信号量<0,那么此时就会将进程加入等待队列,一旦有资源释放,就可以立马申请到。
29.4 信号
上面讲的进程间通信的方式,都是常规状态下的工作模式
其实还有一种异常情况下的工作模式,对应到操作系统中,就是信号。
信号就是一个代号一样的数字。
Linux提供了几十种信号,分别代表不同的意义。信号之间依靠它们的值来区分。
信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。
当某个信号发生的时候,就默认执行这个函数就可以了。
29.5 总结
四大模式:
类似瀑布开发模式的管道
类似邮件模式的消息队列
类似会议室联合开发的共享内存加信号量
类似应急预案的信号
管道,请你记住这是命令行中常用的模式
消息队列其实很少使用,因为有太多的用户级别的消息队列,功能更强大。
共享内存加信号量是常用的模式,常见的一些知名的以C语言开发的开源软件都会用到它。
信号更加常用,机制也比较复杂。
30 信号
30.1 (上)信号和信号处理函数
信号的机制:在某些紧急情况下需要给进程发送一个信号,紧急处理一些事情。
首先要考虑到底能产生哪些异常
Linux为了响应各种各样的事件,定义了非常多的信号,可以通过kill -l命令来查看所有的信号
可以通过man 7 signal命令查看这些信号:每个信号都有一个唯一的ID,还有遇到这个信号的时候的默认操作
一旦有信号产生,用户进程就有下面三种对信号的处理方式:
1.执行默认操作。
Linux对每种信号都规定了默认操作,例如,Term就是终止进程的意思; Core的意思是Core Dump,也即终止进程后,通过Core Dump将当前进程的运行状态保存在文件里面,方便程序员事后进行分析问题在哪里。 2.捕捉信号。可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。 3.忽略信号。
当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。
有两个信号是应用进程无法捕捉和忽略的,即SIGKILL和SEGSTOP,它们用于在任何时候中断或结束某一进程。
信号处理最常见的流程:
第一步是注册信号处理函数(sigaction函数,即使用处理方式的第二步)
第二步是发送信号和处理信号。
如何注册一个信号处理函数?
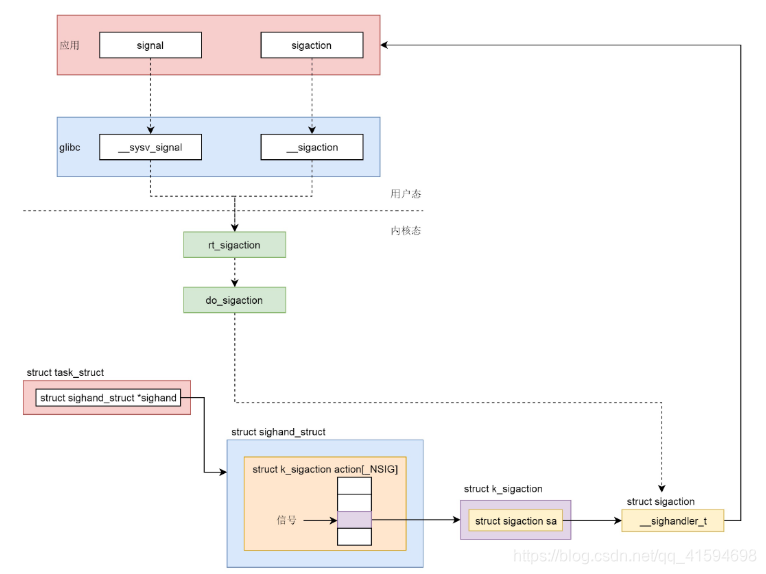
在用户程序里面,有两个函数可以调用,一个是signal,一个是sigaction,推荐使用sigaction,可以根据自己的需要定制参数
用户程序调用的是Glibc里面的函数,signal调用的是
__sysv_signal,里面默认设置了一些参数,使得signal的功能受到了限制,sigaction调用的是__sigaction,参数用户可以任意设定。无论是
__sysv_signal还是__sigaction,调用的都是统一的一个系统调用rt_sigaction。在内核中,rt_sigaction调用的是do_sigaction设置信号处理函数。在每一个进程的task_struct里面,都有
一个sighand指向struct sighand_struct,里面是一个数组,下标是信号,里面的内容是信号处理函数。
sigaction表示一个动作
30.2 (下)会产生信号的情况
信号处理最常见的流程主要是两步,第一步是注册信号处理函数,第二步是发送信号和处理信号。
30.1解析了注册信号处理函数,那一般什么情况下会产生信号呢?
30.2.1 信号的发送
1
在终端输入某些组合键的时候,会给进程发送信号,例如,Ctrl+C产生SIGINT信号,Ctrl+Z产生SIGTSTP信号。
2
硬件异常也会产生信号,比如,执行了除以0的指令,CPU就会产生异常,然后把SIGFPE信号发送给进程;
再如,进程访问了非法内存,内存管理模块就会产生异常,然后把信号SIGSEGV发送给进程。
区分中断和信号:中断要注册中断处理函数,但是中断处理函数是在内核驱动里面的;信号也要注册信号处理函数,信号处理函数是在用户态进程里面的。
对于硬件触发的,无论是中断,还是信号,肯定是先到内核的,然后内核对于中断和信号处理方式不同:
一个是完全在内核里面处理完毕;
一个是将信号放在对应的进程task_struct里信号相关的数据结构里面,然后等待进程在用户态去处理。
当然有些严重的信号,内核会把进程干掉,但是,这也能看出来,中断和信号的严重程度不一样:
信号影响的往往是某一个进程,处理慢了,甚至错了,也不过这个进程被干掉,而中断影响的是整个系统。一旦中断处理中有了bug,可能整个Linux都挂了。
3
内核在某些情况下,也会给进程发送信号。例如,向读端已关闭的管道写数据时产生SIGPIPE信号,当子进程退出时,我们要给父进程发送SIG_CHLD信号等。
4
最直接的发送信号的方法就是,通过命令kill来发送信号了。例如,kill -9 pid可以发送信号给一个进程,杀死它。
5
还可以通过kill或者sigqueue系统调用,发送信号给某个进程,也可以通过tkill或者tgkill发送信号给某个线程。
信号的发送通过 kill/tkill/tgkill/rt_sigqueueinfo 函数执行,最终通过 __send_signal, 将这个信号添加到对应 进程/线程 的信号待处理链表中
- < 32 为不可靠信号, 待处理列表中存在该信号, 则会自动忽略
- 大于等于 32 为可靠信号, 同一个信号会被添加到信号队列中
30.2.2 信号的处理
在从系统调用或者中断返回的时候处理信号
信号的处理会在系统调用或中断处理结束返回用户空间的时机通过 exit_to_usermode_loop 中的 do_signal 执行
修改用户函数栈, 插入我们构建的信号处理函数的栈帧 rt_sigframe, 并且将原来的函数栈信息保存在 uc_mcontext 中
信号处理函数执行结束之后, 会通过系统调用 rt_sigreturn 恢复之前用户态栈
30.3 总结
- 假设我们有一个进程A,main函数里面调用系统调用进入内核。
- 按照系统调用的原理,会将用户态栈的信息保存在pt_regs里面,即记住原来用户态是运行到了line A的
地方。 - 在内核中执行系统调用读取数据。
- 当发现没有什么数据可读取的时候,只好进入睡眠状态,并且调用schedule让出CPU,这是进程调度第一
定律。 - 将进程状态设置为TASK_INTERRUPTIBLE,可中断的睡眠状态,也即如果有信号来的话,是可以唤醒它
的。 - 其他的进程或者shell发送一个信号,有四个函数可以调用:kill、tkill、tgkill、rt_sigqueueinfo。
- 四个发送信号的函数,在内核中最终都是调用do_send_sig_info。
- do_send_sig_info调用send_signal给进程A发送一个信号,其实就是找到进程A的task_struct,或者加入信
号集合,为不可靠信号,或者加入信号链表,为可靠信号。 - do_send_sig_info调用signal_wake_up唤醒进程A。
- 进程A重新进入运行状态TASK_RUNNING,根据进程调度第一定律,一定会接着schedule运行。
- 进程A被唤醒后,检查是否有信号到来,如果没有,重新循环到一开始,尝试再次读取数据,如果还是没
有数据,再次进入TASK_INTERRUPTIBLE,即可中断的睡眠状态。 - 当发现有信号到来的时候,就返回当前正在执行的系统调用,并返回一个错误表示系统调用被中断了。
- 系统调用返回的时候,会调用exit_to_usermode_loop。这是一个处理信号的时机。
- 调用do_signal开始处理信号。
- 根据信号,得到信号处理函数sa_handler,然后修改pt_regs中的用户态栈的信息,让pt_regs指向
sa_handler。同时修改用户态的栈,插入一个栈帧sa_restorer,里面保存了原来的指向line A的pt_regs,
并且设置让sa_handler运行完毕后,跳到sa_restorer运行。 - 返回用户态,由于pt_regs已经设置为sa_handler,则返回用户态执行sa_handler。
- sa_handler执行完毕后,信号处理函数就执行完了,接着根据第15步对于用户态栈帧的修改,会跳到
sa_restorer运行。 - sa_restorer会调用系统调用rt_sigreturn再次进入内核。
- 在内核中,rt_sigreturn恢复原来的pt_regs,重新指向line A。
- 从rt_sigreturn返回用户态,还是调用exit_to_usermode_loop。
- 这次因为pt_regs已经指向line A了,于是就到了进程A中,接着系统调用之后运行,当然这个系统调用返
回的是它被中断了,没有执行完的错误。

31 管道
31.1 匿名管道:|
创建匿名管道的命令及其示意图,返回的两个文件描述符为:f[0]为读取端描述符,f[1]为写入端描述符
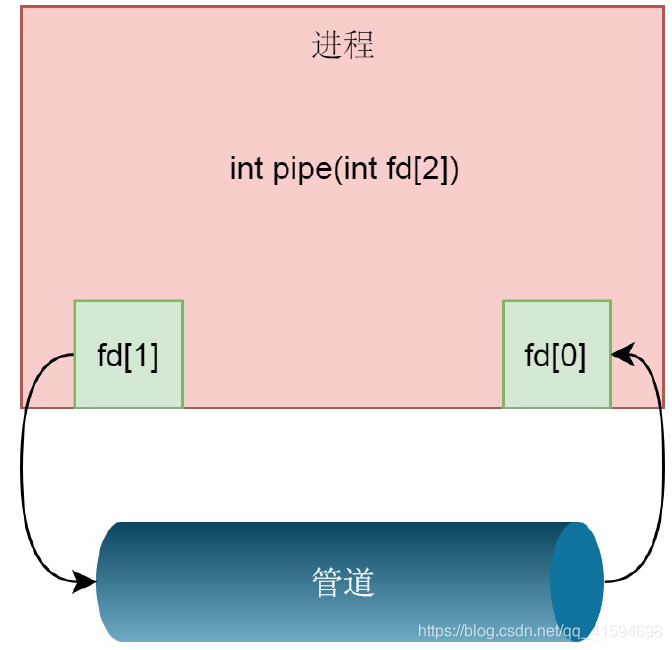
匿名管道其实就是内核里面的一串缓存pipe_buffer:
如果对于fd[1]写入,调用的是pipe_write,向pipe_buffer里面写入数据;
如果对于fd[0]的读入,调用的是pipe_read,从pipe_buffer里面读取数据。
如何跨进程?
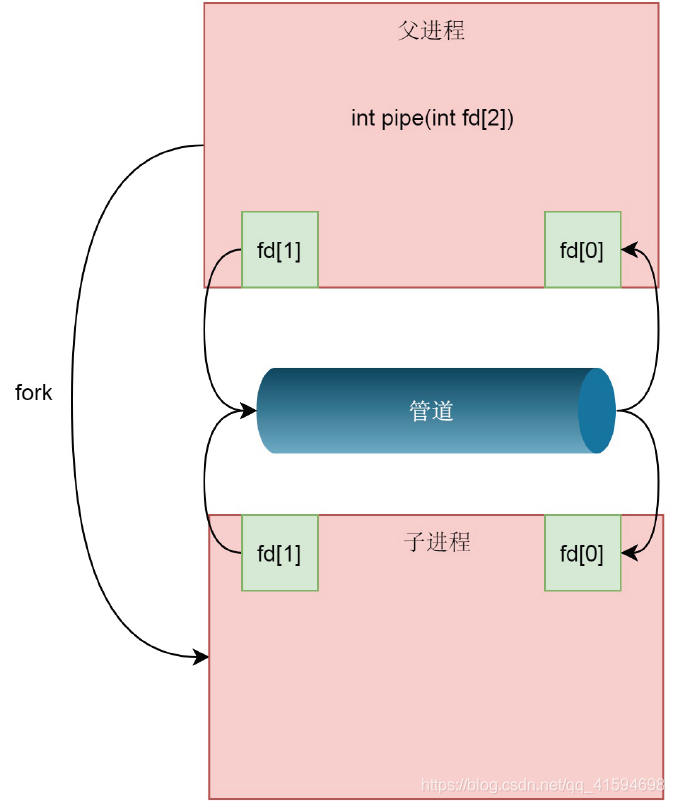
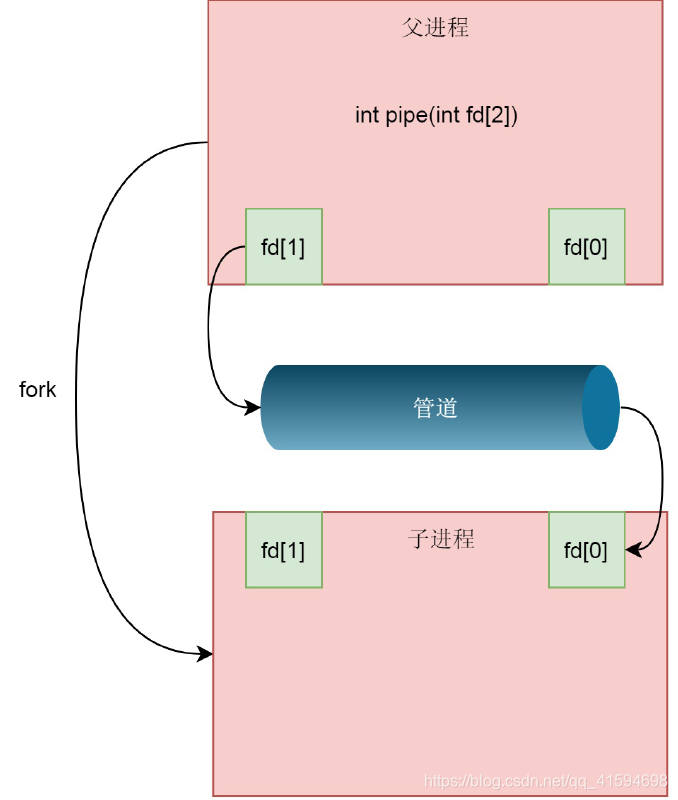
创建进程调用的fork里面,创建的子进程会复制父进程的structfiles_struct,在这里面fd的数组会复制一份,但是fd指向的struct file对于同一个文件还是只有一份;
这样就做到了,两个进程各有两个fd指向同一个struct file的模式,两个进程就可以通过各自的fd写入和读取同一个管道文件实现跨进程通信了:
由于管道只能一端写入,另一端读出,所以上面的这种模式会造成混乱,因为父进程和子进程都可以写入,也都可以读出;
通常的方法是父进程关闭读取的fd,只保留写入的fd,而子进程关闭写入的fd,只保留读取的fd,如果需要双向通行,则应该创建两个管道:
以上可以用代码实现,但是使用hell里面运行A|B的时候,A进程和B进程都是shell创建出来的子进程,A和B之间不存在fork出来的父子关系,无法使用这种方式通信;
可以从1 shell创建子进程A,然后在shell和A之间建立一个管道,其中2 shell保留读取端,A进程保留写入端;
然后3 shell再创建子进程B,这又是一次fork,所以,shell里面保留的读取端的fd也被复制到了子进程B里面。这个时候,相当于shell和B都保留读取端,只要4 shell主动关闭读取端,就变成了一管道,写入端在A进程,读取端在B进程,写入A的东西都传给B保存:
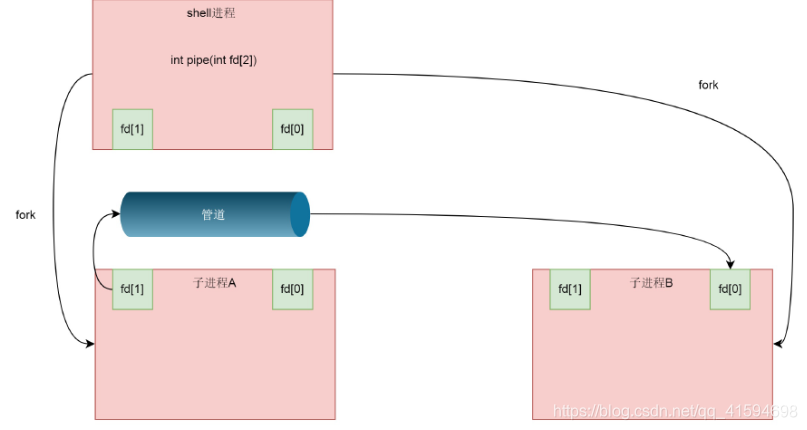
接下来使用dup2系统调用将这个管道的两端和输入输出关联起来:
在A进程中,写入端使用:dup2(fd[1],STDOUT_FILENO),将STDOUT_FILENO不再指向标准输出,而是指向创建的管道文件,那么以后往标准输出写入的任何东西,都会写入管道文件;
在B进程中,读取端使用:dup2(fd[0],STDIN_FILENO),将STDIN_FILENO不再指向标准输入,而是指向创建的管道文件,那么以后从标准输入读取的任何东西,都会从管道文件读取:

31.2 命名管道:Glibc的mkfifo函数
命名管道其实也是内核里面的一串缓存:
对于命名管道的写入,还是会调用pipefifo_fops的pipe_write函数,向pipe_buffer里面写入数据。
对于命名管道的读入,还是会调用pipefifo_fops的pipe_read,从pipe_buffer里面读取数据。
创建:在ext4文件系统上真的创建一个文件,调用init_special_inode,创建一个内存中特殊的inode,inode的i_fop指向管道文件,inode的i_fop指向pipefifo_fops
打开:调用文件系统的open函数,最终在fifo_open里面,创建pipe_inode_info,这个结构里面有个成员是struct
pipe_buffer *bufs,即上述的缓存
31.3 总结
匿名管道和命名管道在内核都是一个文件。
只要是文件就要有一个inode,这里是特殊inode,字符设备、块设备,都是这种特殊的inode。
在这种特殊的inode里面,file_operations指向管道特殊的pipefifo_fops,这个inode对应内存里面的缓存。
使用文件的open函数打开这个管道设备文件时,会调用pipefifo_fops里面的方法创建struct file结构,它的inode指向特殊的inode,也对应内存里面的缓存,file_operations也指向管道特殊的pipefifo_fops。
写入一个pipe就是从struct file结构找到缓存写入,读取一个pipe就是从struct file结构找到缓存读出。

32 IPC
32.1 (上):共享内存和信号量
32.1.1 共享内存
首先,创建共享内存之前,要有一个key来唯一标识这个共享内存。
这个key可以根据文件系统上的一个文件的inode随机生成。
然后,需要创建一个共享内存,就像创建一个消息队列差不多,都是使用xxxget来创建,共享内存使用的是shmget;
对于共享内存,需要指定一个大小size,这个一般要申请多大呢?一个最佳实践是,我们将多个进程需要共享的数据放在一个struct里面(shm_data,两个变量,一个是整型数组,一个是数组中元素的个数。),size赋值为这个struct的大小。这样每一个进程得到这块内存后,只要强制将void类型转换为这个struct类型,就能够访问里面的共享数据了。
接下来,将这个共享内存映射到进程的虚拟地址空间中:shmat函数(此函数返回void,就是在这里进行强转)
最后,当共享内存使用完毕,可以通过shmdt解除它到虚拟内存的映射
32.1.2 信号量
信号量以集合的形式存在的
首先,创建之前,同样需要有一个key来唯一标识这个信号量集合。这个key同样可以根据文件系统上的一个文件的inode随机生成。
然后,需要创建一个信号量集合,同样也是使用xxxget来创建:semget函数,在参数里指定信号量的个数,如果用信号量做互斥,那往往将信号量设置为1。
32.1.3 小结
共享内存和信号量的配合机制:
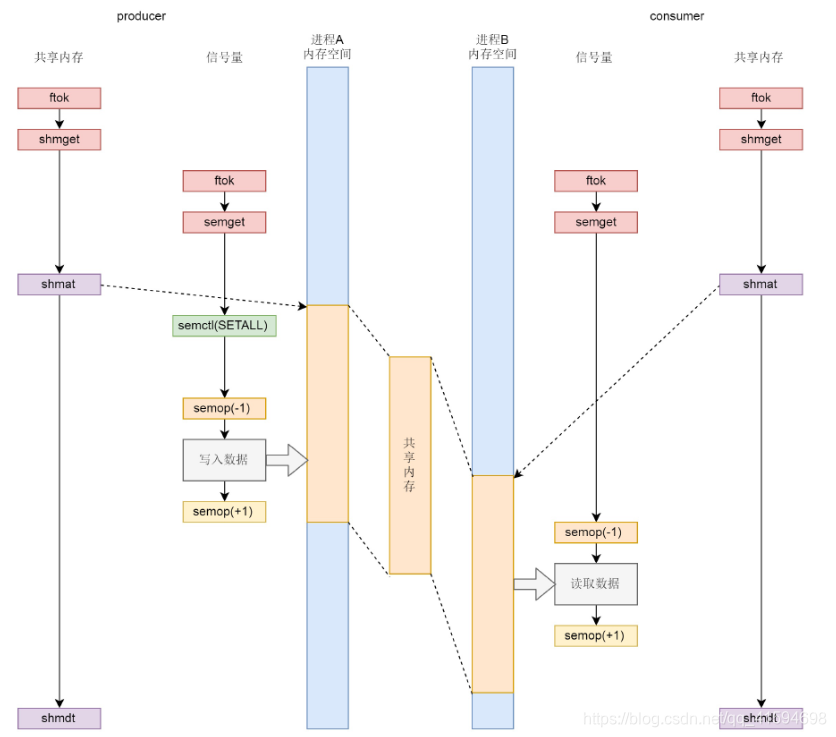
无论是共享内存还是信号量,创建与初始化都遵循同样流程:通过ftok得到key,通过xxxget创建对象并生成id;
生产者和消费者都通过shmat将共享内存映射到各自的内存空间,在不同的进程里面映射的位置不同;
为了访问共享内存,需要信号量进行保护,信号量需要通过semctl初始化为某个值;
接下来生产者和消费者要通过semop(-1)来竞争信号量,如果生产者抢到信号量则写入,然后通过semop(+1)释放信号量,如果消费者抢到信号量则读出,然后通过semop(+1)释放信号量;
共享内存使用完毕,可以通过shmdt来解除映射。
通过程序创建的共享内存和信号量集合,可以通过命令ipcs查看,也可以通过ipcrm进行删除。
32.2 (中)共享内存的内核机制
消息队列、共享内存、信号量的机制的统一规律:在使用之前都要生成key,然后通过key得到唯一的id,并且都是通过xxxget函数来创建对象
在内核里面,这三种进程间通信机制是使用统一的机制管理起来的:ipcxxx。
为了维护这三种进程间通信进制,在内核里面声明了一个有三项的数组ipc_ids:第0项用于信号量,第1项用于消息队列,第2项用于共享内存,分别可以通过sem_ids、msg_ids、shm_ids来访问。
ipc_ids里面保存了一颗基数树,也就是说,对于sem_ids、msg_ids、shm_ids各有一棵基数树进行管理;
ipc_obtain_object_idr函数可以根据id从基数树里找出对应的struct kern_ipc_perm,而信号量、消息队列、共享内存的结构的第一项都是struct kern_ipc_perm,也就是说,可以通过struct kern_ipc_perm的指针,通过进行强制类型转换后,得到整个结构;
通过这种机制,可以将信号量、消息队列、共享内存抽象为ipc类型进行统一处理,C++的抽象类和实现类就是这么实现的(也就是说,根据不同的ipc_obtain_object_idr方法获取不同的基数树节点,然后使用container_of方法就能得到对应的结构,如sem_array、msg_queue或shmid_kernel)

有了抽象类,接下来来看共享内存的创建和映射过程:
- 调用shmget创建共享内存。
- 先通过ipc_findkey在基数树中查找key对应的共享内存对象shmid_kernel是否已经被创建过,如果已经被
创建,就会被查询出来 - 如果共享内存没有被创建过,则调用shm_ops的newseg方法,创建一个共享内存对象shmid_kernel。
- 在shmem文件系统里面创建一个文件,共享内存对象shmid_kernel指向这个文件,这个文件用struct file
表示,我们姑且称它为file1。 - 调用shmat,将共享内存映射到虚拟地址空间。
- shm_obtain_object_check先从基数树里面找到shmid_kernel对象。
- 创建用于内存映射到文件的file和shm_file_data,这里的struct file称为file2。
- 关联内存区域vm_area_struct和用于内存映射到文件的file,也即file2,调用file2的mmap函数。
- file2的mmap函数shm_mmap,会调用file1的mmap函数shmem_mmap,设置shm_file_data和
vm_area_struct的vm_ops。 - 内存映射完毕之后,其实并没有真的分配物理内存,当访问内存的时候,会触发缺页异常do_page_fault。
- vm_area_struct的vm_ops的shm_fault会调用shm_file_data的vm_ops的shmem_fault。
- 在page cache中找一个空闲页,或者创建一个空闲页。

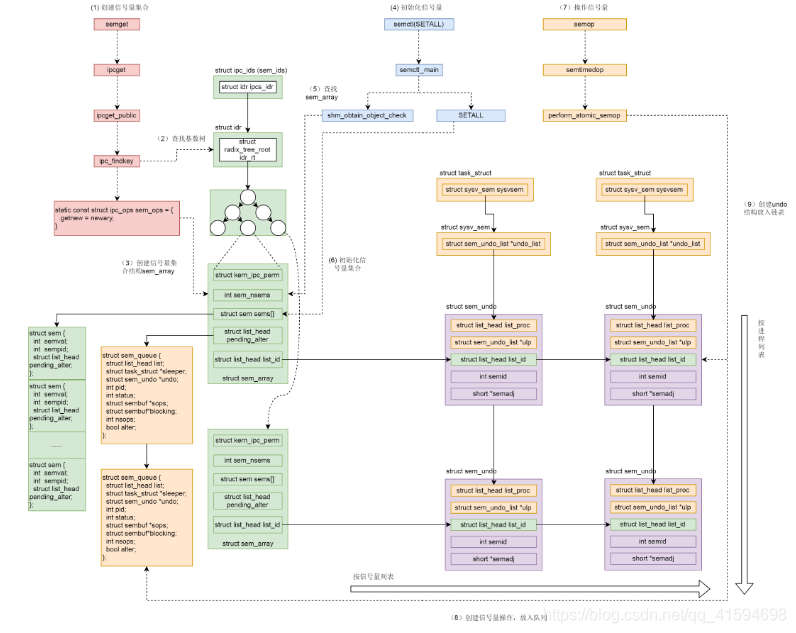
32.3 (下)信号量的内核机制
- 调用semget创建信号量集合。
- ipc_findkey会在基数树中,根据key查找信号量集合sem_array对象。如果已经被创建,就会被查询出
来。 - 如果信号量集合没有被创建过,则调用sem_ops的newary方法,创建一个信号量集合对象sem_array。例
如,在producer中就会新建。 - 调用semctl(SETALL)初始化信号量。
- sem_obtain_object_check先从基数树里面找到sem_array对象。
- 根据用户指定的信号量数组,初始化信号量集合,也即初始化sem_array对象的struct sem sems[]成员。
- 调用semop操作信号量。
- 创建信号量操作结构sem_queue,放入队列。
- 创建undo结构,放入链表。