现代开源操作系统的基本组成:
| 功能 | 链接地址 |
|---|---|
| 文件管理和设备管理 | 虚拟文件系统(无持久存储的文件系统),以proc和sysfs为例 |
| 内存管理 | 现代操作系统的内存管理原理:以Linux2.6.x.x为例 |
| 系统启动原理 | Linux 2.6.4.30 Arm Architecture源码深度剖析—基于《ARM Linux内核源码剖析》 |
| 虚拟地址空间 | 什么是虚拟地址空间?从架构视角来解释 |
| 动态链接 | 一篇长文带你深析Linux动态链接的全过程 |
从上篇:Intel® 64 and IA-32 Architectures Software Developer’s Manual 读后感可以看到Intel对于虚拟化技术还是很看重的,因此此篇借助Linux平台来总结一下虚拟化技术。
虚拟化技术与容器技术的差别:KVM内核虚拟化技术以及Docker容器技术的原理浅谈?
下一篇:多核系统原理与解决方案
虚拟化主要分为以下几个部分:CPU虚拟化,内存虚拟化,中断虚拟化和设备虚拟化。其中内存虚拟化和中断虚拟化属于软件虚拟技术,而CPU虚拟化和设备虚拟化属于硬件虚拟化技术,特别是设备虚拟化,和真实存在的设备差别不是太大。
VT-d技术
CPU虚拟化
结合
Intel手册中的虚拟化技术来看
陷入和模拟模型(Trap and Emulate):虚拟机的用户程序和内核都运行在用户模式(一般情况下是用户程序运行在用户模式,内核运行在系统模式),这称为特权级压缩(Ring Compression),在这种方式下,虚拟机的非特权级治疗直接运行在处理器上,当运行特权级指令时,将触发处理器异常,陷入VMM中,由VMM代理虚拟机完成系统资源的访问。
随后Intel开发了VT技术支持虚拟化,为CPU增加了VMX,即Virtual-Machine Extension。此时CPU提供了两种运行模式:VMX Root Mode和VMX non-Root Mode,每一种都支持ring0-ring3。VMM运行在VMX Root Mode,除了支持VMX,VMX Root Mode和普通的模式并无本质区别。VM运行在VMX non-Root Mode,Guest kernel运行在VMX non-Root Mode的ring0中 。
VT技术上处理器上的作用,不必关心其细节。
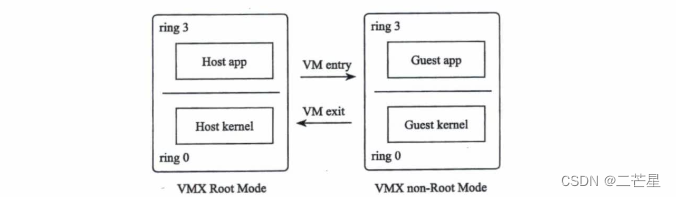
处于VMX Root Mode的VMM可以通过执行CPU提供的虚拟化指令VMLaunch切换到VMX non-Root Mode,因为这个过程相当于进入Guest,所以通常也被称为VM entry。当Guest内部执行力敏感指令,比如某些I/O操作后,将触发CPU发生陷入的动作,这个过程相当于退出VM,因此被称为VM exit。然后VMM对Guest的操作进行模拟。
如同一个CPU可以分时运行多个任务一样,每个人物有自己的上下文,由调度器质调度时切换上下文,从而实现同一个CPU同时运行多个任务,在虚拟化场景下,同一个物理CPU分时运行着Host和Guest,在不同的模式间按需切换,因此,不同的模式也需要保存自己的上下文。每个Guest都有自己的一个VMCS实例,当物理CPU加载了不同的VMCS时,将运行不同的Guest。
当运行Guest模式时,Guest用户空间的系统调用直接陷入Guest模式的内核空间,而不是陷入Host模式的内核空间
对于外部中断,因为需要由VMM控制系统的资源,所以当处于Guest模式的CPU收到外部中断后。则触发CPU从Guest模式退出到Host模式,由Host内核处理外部中断,处理完中断后,再重新切入Guest模式。(此时不必产生VM exit)
对于VCPU,VMM使用一个线程来代表这个VCPU实体
KVM是内核模块。
陷入和模拟:当Guest访问系统资源时,就需要退出到Host模式,由Host作为统一的管理者代为完成资源访问。当虚拟机进行I/O访问时,首先需要陷入Host,VMM中的虚拟磁盘收到I/O请求后,如果虚拟机磁盘镜像存储在本地文件,那么就代为读写本地文件。在访问设备I/O内存映射的地址空间时,将触发页面异常,但是这些地址对应的不是内存,而是模拟设备的I/O空间,因此需要KVM介入,调用相应的模拟设备处理I/O
对于被动性触发的陷入,只需要Guest将CPU资源让给Host即可。
常用外设访问方式包括
PIO和MMIO
内存虚拟化
实质是创建影子页表或者EPT等页表进行与物理内存的映射关系。
中断虚拟化
对于软件虚拟的中断芯片而言,中断信号只是一个变量,从软件模拟的角度就是设置变量的值了。如果KVM发现虚拟中断芯片有中断请求,则向VMCS中VM entry control部分的VM-entry interruption-information filed字段写入中断信息,在切入Guest模式的一刻,CPU将检查这个字段,就如同检查CPU管脚 ,如果有中断,则进入中断执行过程。
其中中断的逻辑为
- 虚拟设备向虚拟中断芯片
PIC发送中断请求,虚拟PIC记录虚拟设备的中断信息,与物理的中断过程不同,此时并不会触发虚拟PIC芯片的中断评估逻辑,而是在VM entry时进行 - 如果虚拟
CPU处于睡眠状态,则唤醒虚拟CPU,即使虚拟CPU对应的线程进入了物理CPU的就绪任务队列 - 当虚拟
CPU开始运行时,在其切入Guest前一刻,KVM模块将检查虚拟PIC芯片,查看是否有 中断需要处理。此时,KVM将触发虚拟PIC芯片的中断评估逻辑 - 一旦经过虚拟中断芯片计算得出一需要
Guest处理的中断,则将中断信息注入VMCS中断字段VM-entry interruption-information - 进入
Guest模式后,CPU检查VMCS中断中断信息 - 如果有中断需要处理
CPU将调用Guest IDT中相应的中断服务处理中断
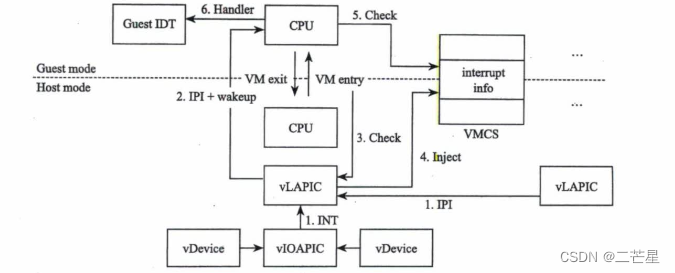
一般对于中断的控制是由中断控制器8259A可编程中断控制器或者APIC可编程高级中断控制器来操作的,因此也要对这两个芯片进行虚拟化。
硬件虚拟化的支持
虚拟中断芯片是在用户空间实现的,但是中断芯片密集地参与了整个计算机系统的运转过程,因此,为了减少内核空间与用户空间之间的上下文切换带来的开销,后来,中断芯片的虚拟是在了内核空间。为了进一步提高效率,Intel从硬件层面对虚拟化的方方面面进行了支持。
virtual-APIC page:Intel在CPU的Guest模式下实现了一个用于存储中断寄存器的virtual-APIC page。在Guest模式下有了此状态,后面Guest模式下还有了中断逻辑,很多中断行为就无需VMM介入了,从而大大减少了VM exit的次数。Guest模式下的中断评估逻辑。Intel在Guest模式中实现了部分中断芯片的逻辑用于中断评估,当有中断发生时,CPU不必再推出到Host模式,而是直接在Guest模式下完成中断评估。posted-interrupt processing:在虚拟中断芯片收到中断请求后,会将信息保存在虚拟中断芯片中,在VM entry时,触发虚拟中断芯片的中断评估逻辑,根据记录在虚拟中断芯片中断信息进行中断评估。但是当CPU支持者Guest模式下的中断评估逻辑后,虚拟中断芯片可以在收到中断请求后,将中断信息直接传递给处于Guest模式下的CPU,由Guest模式下的中断芯片的逻辑中Guest模式中进行中断评估,向Guest模式的CPU直接递交中断。
设备虚拟化
设备虚拟化:系统虚拟化软件使用软件的方式呈现给Guest操作系统硬件设备的逻辑。设备虚拟化先后经历了完全虚拟化,半虚拟化,以及后来出现的硬件辅助虚拟化,包括将硬件直接透传给虚拟机,以及将一个硬件从硬件层面虚拟成多个子硬件,每个子硬件分别透传给虚拟机等。
设备透传
设备虚拟化如果采用软件模拟的方式,则需要VMM参与进来。为了避免这个开销,Intel尝试从硬件层面对I/O虚拟化进行支持,即将设备直接透传给Guest,Guest绕过VMM直接访问物理设备,无需VMM参与I/O过程,这种方式提供了最佳的I/O虚拟化性能。
Intel最初采用的方式是Direct Assignment,即将整个设备透传给某一台虚拟机,不支持多台VM共享同一设备。为例使不同设备制造商的设备可以互相兼容,PIC-SIG制定了一个标准:Single Root I/O Virtualzation and Sharing,简称SR-IOV。SR-IOV引入了两个新的Function类型,一个是Physical Function,简称PF;另一个是Virtual Function,简称VF。一个SR-IOV可以支持多个VF,每一个VF可以分别透传给Guest,如此,将从硬件角度实现了多个Guest分享同一物理设备。
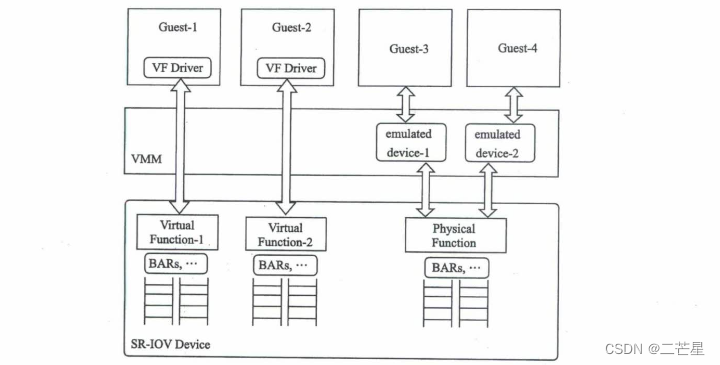
每个VF都有自己独立的用于数据传输的存储空间、队列、中断及命令处理单元等,但是这些VF的管理仍然在VMM的控制下,VMM通过PF管理这些VF。虚拟机可以直接访问这些VF,而无须再通过VMM中的模拟设备访问物理设备。PF除了提供管理VF的途径外,Host 以及其上的应用仍然可以通过PF无差别地访问物理设备。对于那些没有VF驱动的Guest,虚拟机依然可以通过SR-IOV设备的PF接口共享物理设备。
数据传输方式
(1)MMIO:Memory-Mapped I/O:将外设的内存,寄存器映射到CPU的内存地址空间中,CPU访问外设如同访问自己的内存一样。
(2)PIO:Port I/O:使用IN和OUT指令对指定端口进行读取数据。
我不喜欢网络,也没有探究网络虚拟化,跳过了
此处要注意,
VT-d技术实现的是CPU的虚拟化和内存的虚拟化,中断和设备并无安全算上一种虚拟化。
QEMU/KVM技术
概念看多了,略显枯燥,来看实操
QEMU源码下载:qemu源码官网下载
Linux源码下载:Linux内核源码官网下载
概念和历史
虚拟机(Virtual Machine,VM)是进程,进程可以看作是一组资源的集合,有自己独立的进程地址空间以及独立的CPU和寄存器,执行程序员编写的指令,完成一定的任务。系统虚拟化是在云计算的支持下得到了快速的发展,Intel和AMD都相继在CPU硬件层面增加了虚拟化的支持。
随后,Qumranet利用Intel的硬件虚拟化技术在Linux内核上开发了KVM Kernel Virtual Machine,KVM架构精简,与Linux内核天然融合,得以很快进入内核。KVM现在已经是一个非常成功的虚拟化VMM,称为云计算的基石。
QEMU早期是通过把源架构指令通过TCG Tiny Code Generator引擎转换成目标架构指令。
Intel和AMD都相继在CPU硬件层面增加了虚拟化的支持,即硬件虚拟化,Intel在x86指令集的基础上增加了一套VMX扩展指令VT-x,为CPU增加了新的运行模式,完成了x86虚拟化漏洞的修补。
通过新的硬件虚拟化指令,可以非常方便的构造VMM,并且x86虚拟机中的代码能够原生地运行在物理CPU上
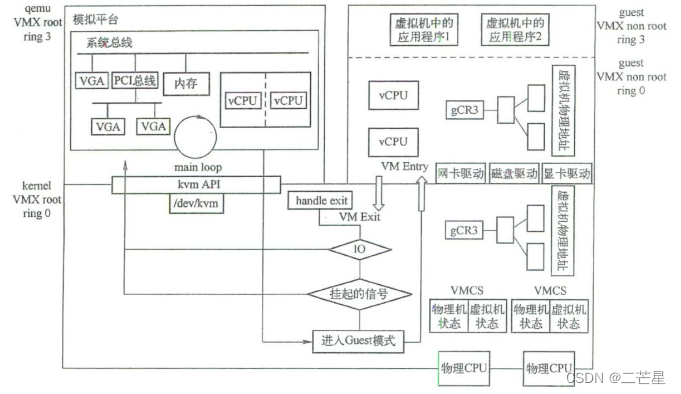
KVM本身是一个内核模块,导出来一系列的接口到用户空间,用户空间可以使用这些接口创建虚拟机。最开始KVM只负责最核心的CPU虚拟化和内存虚拟化部分,使用QEMU作为其用户态组件,负责大量外设的模拟,当时的方案被称为QEMU-KVM。
除此之外,还有VMware和VirtualbBox等虚拟化解决方案。
CPU虚拟化
虚拟机的创建:要创建一台KVM虚拟机,需要用户侧的QEMU发起请求。
QEMU侧虚拟机的创建和KVM虚拟机的创建:QEMU中使用KVMState结构体来表示KVM相关的数据结构,KVM_INIT函数首先打开/dev/kvm设备得到一个fd,调用kvm_ioctl(s, KVM_CREATE_VM)接口中KVM层面创建一个虚拟机,kvm_init也会调用kvm_arch_init完成一些架构相关的初始化。
// qemu
static int accel_init_machine(AccelClass *acc, MachineState *ms)
{
//
ret = acc->init_machine(ms);
if (ret < 0)
{
...
}
return ret;
}
// kvm
static int kvm_init(MachineState *ms)
{
//
MachineClass *mc = MACHINE_GET_CLASS(ms);
ms = KVM_STATE(ms->accelerator);
ms->vmfd = -1;
ms->fd = qemu_open("/dev/kvm", O_RDWR);
do
{
ret = kvm_ioctl(s, KVM_CREATE_VM, type); // 创建一台KVM虚拟机
} while (ret == -EINTR);
}
VCPU的创建
VCPU的类型
struct X86CPUDefinition {
const char *name;
uint32_t level;
uint32_t xlevel;
/* vendor is zero-terminated, 12 character ASCII string */
char vendor[CPUID_VENDOR_SZ + 1];
int family;
int model;
int stepping;
FeatureWordArray features;
char model_id[48];
};
static X86CPUDefinition builtin_x86_defs[] = {
// 各种cpu型号和特性
{
.name = "pentium",
.level = 1,
.vendor = CPUID_VENDOR_INTEL,
.family = 5,
.model = 4,
.stepping = 3,
.features[FEAT_1_EDX] =
PENTIUM_FEATURES,
.xlevel = 0,
},
// ......
}
在调用KVM的创建虚拟CPU会调用一个kvm_vcpu_ioctl函数,此处传入一个参数,用来表示创建cpu的状态,如下
int kvm_cpu_exec(CPUState *cpu)
{
do
{
...
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
} while ()
}
Docker容器技术
传统的虚拟化技术可以通过硬件或者操作系统来实现,如KVM,为了让虚拟的应用程序达到和物理机相近的结果,使用了Hypervisor/VMM,它允许多个操作系统共享一个或多个CPU,但是却带来了很大的开销,由于虚拟机中包括全套的OS,调度和资源占用都非常重。
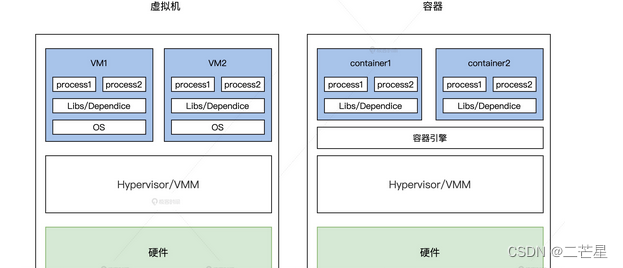
容器(Container)技术是一种更加轻量级的操作系统虚拟化技术,它将应用程序,依赖包,库文件等允许依赖环境打包到标准化的镜像中,通过容器引擎提供进程隔离,资源可限制的允许环境,实现应用与OS平台及底层硬件的解耦。
此处不得不提到一个命令:chroot,即change root,其作用是改变程序执行时所参考的根目录位置,可以增加系统的安全性,限制使用者能做的事。
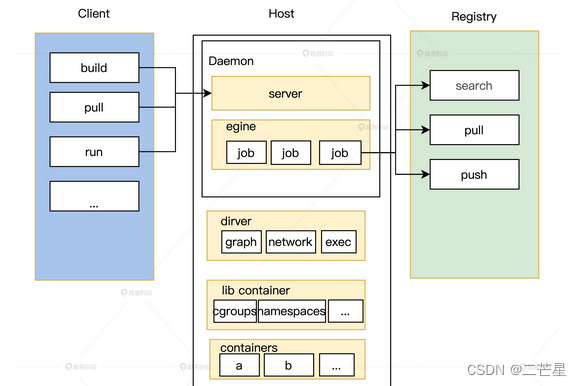
容器管理引擎
主要包括守护进程,镜像,驱动和容器管理者几个模块。
Docker Daemon
该进程是一个常驻后台的守护进程,负责监听客户端请求,然后执行后续的对应逻辑,还能管理Docker对象,主要有三部分:
Server:负责接收客户端发来的请求,接收请求以后Server通过路由与分发调度找到相应的Handler执行请求,然后与容器镜像仓库交互镜像并将结果返回给Docker Client。Engine:运行引擎。该模块扮演了Docker container存储仓库的角色,Engine的每一项工作,都可以拆解成多个最小动作Job,这是其最基本的工作执行单元Job:Docker内部的每一步操作,都可以抽象为一个Job,会使用下层的Driver驱动来完成。
Docker Driver
Docker中的驱动,设计驱动这一层是解耦,将容器管理的镜像,网络和隔离执行逻辑从Docker Daemon的逻辑中剥离。
中期实现中,可以分为以下三类驱动:
graphdriver:负责容器镜像的管理,主要是镜像的存储和获取,当镜像下载时,会将镜像持久化存储到本地的制定目录。networkdriver:负责Docker容器网络环境的配置,如Docker运行时进行IP分配端口映射以及启动时创建网桥和虚拟网卡。execdriver:执行驱动,通过操作Lxc或者libcontainer实现资源隔离。它负责创建管理容器运行命名空间,管理分配资源和容器内部真实进程的运行。
libcontainer
提供了访问内核中和容器相关的API,负责对容器进行具体操作。
主要是利用内核的
namespace和cgroup两个技术。
其中namespace负责进程隔离,cgroup负责资源限制
可见虚拟文件系统(无持久存储的文件系统),以proc和sysfs为例中的Cgroup文件系统。
感兴趣的可以看看这个项目,用bash手写的一百多行简易docker:bocker