Long Short-Term Memory networks(长-短期记忆网络),简称 LSTMs,可用于时间序列预测。有许多类型的LSTM模型可用于每种特定类型的时间序列预测问题。本文介绍了如何为一系列标准时间序列预测问题开发一套LSTM模型。本文旨在为每种类型的时间序列问题提供所对应模型的示例,你可以依此为模板,针对自己的业务需求进行修改。本文的主要内容为:
- 如何开发适用于单变量时间序列预测的LSTM模型。
- 如何开发适用于多变量时间序列预测的LSTM模型。
- 如何开发适用于多步时间序列预测的LSTM模型。
代码环境:
- python 3.7.6
- tensorflow 2.1.0
- keras 2.3.1
日期:2020/4/7
文章目录
滑动窗口是处理时间序列数据通用的方法,之前的时间序列预测的文章中,示例代码其实是简单的滑动窗口。先通过两张相关图片来直观理解滑动窗口是如何建模的。
-
滑动窗口在时间序列预测任务上的建模方法:
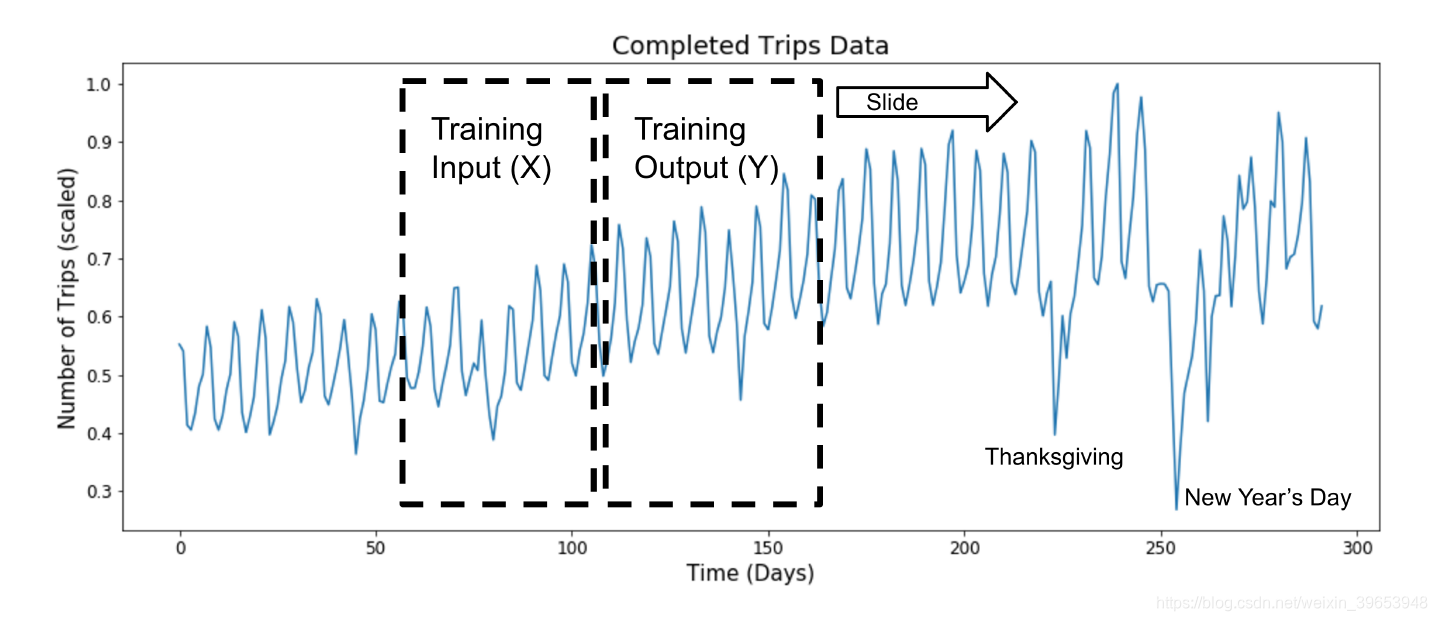
对于时间序列预测任务来讲,以一定滑动窗口大小和滑动步长在原始时间序列上截取数据,以之前的滑动窗口内的数据作为训练样本X,以需要预测的之后的某一时间步长内的的数据作为样本标签y,即从历史数据中学习映射关系来预测未来数据。 -
滑动窗口在时间序列分类任务上的建模方法:
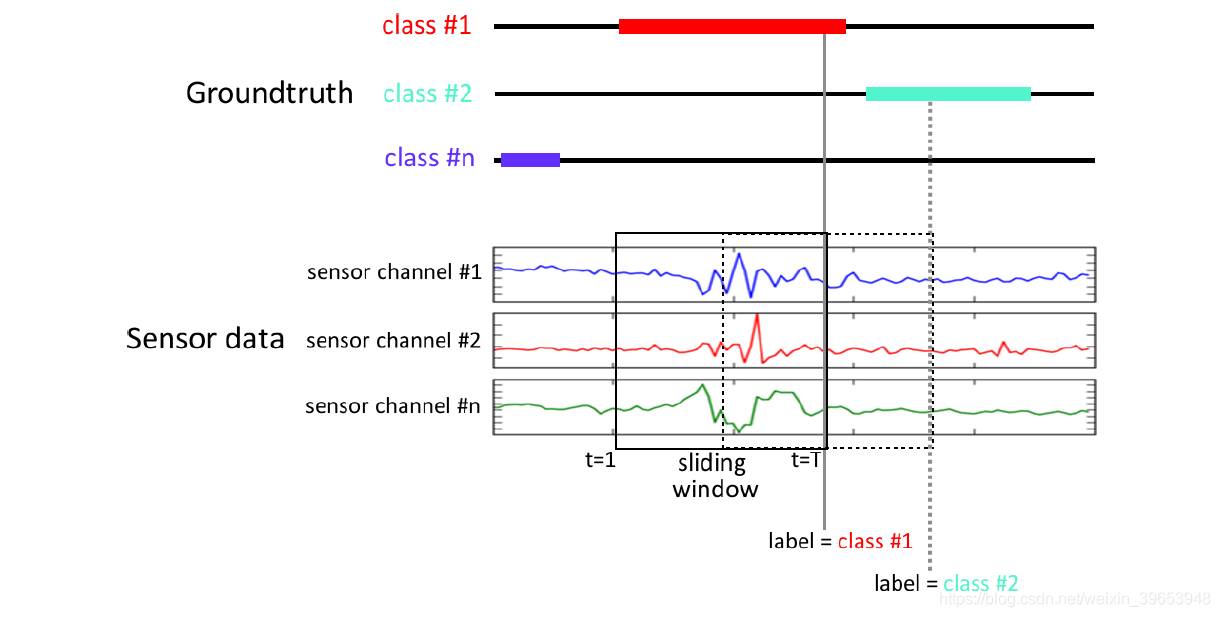
在时间序列分类任务中,使用滑动窗口分割数据并获取标签的过程如上图所示。传感器信号称为特征(features),传感器信号的通道数就是特征的尺寸;传感器信号被一个个滑动窗口按照指定的滑动步长(time steps)截取数据,一个窗口内截取的采样点的数据称为样本。滑动窗口所截取的最后一个采样点的数据标签作为样本标签。
前言
本文分为四个部分,将按照如下行文顺序进行介绍:
- Univariate LSTM Models
- Multivariate LSTM Models
- Multi-step LSTM Models
- Multivariate Multi-step LSTM Models
1. 单变量 LSTM 模型(Univariate LSTM Models)
LSTMs可用于单变量时间序列预测问题的建模。这些问题由单个观测序列组成,需要一个模型从过去的观测序列中学习,以预测序列中的下一个值。下文将演示一元时间序列预测的LSTM模型。本节分为六个部分:
- Data Preparation
- Vanilla LSTM
- Stacked LSTM
- Bidirectional LSTM
- CNN-LSTM
- ConvLSTM
上边的5种LSTM模型都可用于单时间步单变量时间序列预测,也可用于其他类型时间序列预测问题。
1.1 数据准备
在对单变量序列建模之前,必须做好准备。LSTM模型学习一个映射规则,该规则以过去的序列观测值作为输入,然后输出预测值。因此,观测序列必须转换成LSTM可以学习的多个样本(由多个观测值组成)。考虑一个单变量序列:
[10, 20, 30, 40, 50, 60, 70, 80, 90]
我们可以将序列分成多个输入/输出模式,称为样本,其中三个时间步(的观测值)作为输入,一个时间步(的观测值)作为输出:
X, y
10, 20, 30, 40
20, 30, 40, 50
30, 40, 50, 60
...
我们可以通过写一个函数来实现上述功能,为了增加文章可读性,减少重复,此处先不贴出代码,会在完整代码中贴出。先看下划分结果,使用该函数对整个数据集进行划分,将单变量序列拆分为6个样本(sample),其中每个样本有3个输入时间步(的观测值)和1个输出时间步(的观测值)。
[10 20 30] 40
[20 30 40] 50
[30 40 50] 60
[40 50 60] 70
[50 60 70] 80
[60 70 80] 90
数据集构建好之后,接下来定义网络模型,进行训练。
1.2 Vanilla LSTM
刚开始接触LSTM的时候,碰到“Vanilla”还以为是“香草”的意思,心想作者也太文艺了,后来才知道是自己才疏学浅,“Vanilla”是“普通的,简单的”意思…
Vanilla LSTM是一个LSTM模型,它有一个单隐层的LSTM单元和一个用于预测的输出层。LSTM可以很好的完成序列预测任务。与CNN读取整个输入向量不同,LSTM模型一次读取序列的一个时间步(的观测值),并建立一个内部状态表示,来学习上下文信息,从而进行预测。以下为单变量时间序列预测任务定义了一个简单的LSTM模型:
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(n_steps, n_features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
该模型中,定义了一个有50个LSTM 单元的单隐层和一个预测单个数值的输出层。该模型利用有效的随机梯度下降Adam模型进行拟合,并利用均方误差(mse)损失函数进行优化。
模型定义中的关键是 input_shape 参数,当初花了很长时间来理解,现在算是稍有眉目吧。如果不好理解,可以用 jupyter notebook 一步一步地看,看每个变量的shape,也可以使用IDE debug,再结合API的官方文档,帮助理解。这里有一点需要注意,如果查LSTM官方文档的话,这个API中是没有input_shape这个参数的,那为什么要指定?这其实是用于构建顺序模型的 Sequential() API所要求提供的的输入数据格式,只需要在第一层输入数据尺寸,后面层Keras会自动计算。我们的示例中使用的是一个单变量序列,因此特征数(features)为1。相信很多人跟我一样,对 n_steps 这个参数也有疑惑,其实就是 滑动窗口的宽度,也可以理解为一个样本中包含观测值的数量。这个参数在 split_sequence() 函数中已经定义了,还不明白的,可以结合这个函数再理解理解,在我们的示例中,这个参数为3。
这里贴一下所用API的官方文档:
模型定义完成之后,需要考虑Keras中模型拟合API fit() 的数据输入维度要求,每个样本的输入形状在单隐层的LSTM层中的 input_shape 参数中指定。因为有多个训练样本,所以模型拟合API fit() 要求输入数据的形状为 [样本,时间步,特征]([samples, timesteps, features])。上一节中的 split_sequence() 函数输出 X 的形状为 [samples,timesteps],因此我们可以通过 reshape() 方法来为训练数据集添加特征维度。代码实现:
n_features = 1
X = X.reshape((X.shape[0], X.shape[1], n_features))
完整代码在该小节结束后贴出,此处只放出结果:
[10 20 30] 40
[20 30 40] 50
[30 40 50] 60
[40 50 60] 70
[50 60 70] 80
[60 70 80] 90
X:
[[[10]
[20]
[30]]
[[20]
[30]
[40]]
[[30]
[40]
[50]]
[[40]
[50]
[60]]
[[50]
[60]
[70]]
[[60]
[70]
[80]]]
y:
[40 50 60 70 80 90]
X.shape:(6, 3, 1), y.shape:(6,)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 50) 10400
_________________________________________________________________
dense (Dense) (None, 1) 51
=================================================================
Total params: 10,451
Trainable params: 10,451
Non-trainable params: 0
_________________________________________________________________
None
[[[70]
[80]
[90]]]
yhat: [[102.01498]]
1.3 Stacked LSTM
Stacked LSTM意即堆叠LSTM,可以将多个LSTM层堆叠在一起。LSTM层需要三维输入,LSTM的默认输出为二维,可以通过设置 return_sequences=True 参数使得LSTM的输出形状为三维。这样就可以作为下一层的输入。代码实现:
model = Sequential()
model.add(LSTM(50, activation='relu', return_sequences=True, input_shape=(n_steps,
n_features)))
model.add(LSTM(50, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
1.4 Bidirectional LSTM
在一些序列预测问题上,允许LSTM模型向前和向后学习输入序列,并将两种解释连接起来是有益的。这称为双向LSTM。我们可以通过将第一个隐藏层包装在一个称为双向的包装层中来实现用于单变量时间序列预测的双向LSTM。代码实现:
# define model
model = Sequential()
model.add(Bidirectional(LSTM(50, activation='relu'), input_shape=(n_steps, n_features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
1.5 CNN-LSTM
卷积神经网络,简称CNN,是为处理二维图像数据而开发的一种神经网络。CNN可以非常有效地从一维序列数据(如单变量时间序列数据)中自动提取和学习特征。CNN模型可用于具有LSTM后端的混合模型中,其中CNN用于解释输入的子序列,这些子序列作为一个序列提供给LSTM模型来解释。这种混合模型称为CNN-LSTM。
第一步是将输入序列分割成可以由CNN模型处理的子序列。例如,我们可以首先将单变量时间序列数据分成输入/输出样本,其中四个步骤作为输入,一个步骤作为输出。然后,每个样本可以分成两个子样本,每个子样本有两个时间步。CNN可以解释两个时间步的每个子序列,并将子序列的时间序列解释提供给LSTM模型作为输入进行处理。我们可以将其参数化,并将子序列的数量定义为 n_seq,将每个子序列的时间步数定义为n_steps。然后可以对输入数据进行整形,使其具有所需的结构:[示例、子序列、时间步、功能]([samples, subsequences, timesteps, features])。例如:
n_steps = 4
# 划分成样本
X, y = split_sequence(raw_seq, n_steps)
# 重塑形状 [samples, timesteps] 变为 [samples, subsequences, timesteps, features]
n_features = 1
n_seq = 2
n_steps = 2
X = X.reshape((X.shape[0], n_seq, n_steps, n_features)
我们希望在分别读取每个数据子序列时重用相同的CNN模型。这可以通过将整个CNN模型包装在一个 Keras API TimeDistributed 包装器中来实现,该包装器将对每个输入数据子序列应用一次整个模型。定义的CNN模型有一个用于读取子序列的卷积层,该子序列需要指定filter的数目和kernel_size的大小。filter的数目是对输入序列的读取或解释的数目。kernel_size是输入序列的每个读取操作包含的时间步数。卷积层之后是最大池化层,它将filter提取的特征图映射到其大小的1/4,其中包含最显著的特征。然后,这些结构被展平成一个一维向量,用作LSTM层的单个输入时间步。代码实现:
model.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu'), input_shape=(None, n_steps, n_features)))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(50, activation='relu'))
model.add(Dense(1)
1.6 ConvLSTM
与CNN-LSTM相关的一种LSTM是ConvLSTM,它将输入的卷积读取直接构建到每个LSTM单元中。该方法可用于二维时空数据的读取,也可用于单变量时间序列预测。该层期望输入为二维图像序列,因此输入数据的形状必须是:[样本、时间步长、行、列、特征]( [samples, timesteps, rows, columns, features])。
我们可以将每个样本分割成子序列,其中 timesteps 将成为子序列的数量,或 n seq,而列将是每个子序列的时间步长,或 n_steps。对于一维数据,rows 固定为1。分析清楚后,接下来重塑样本。代码实现:
n_steps = 4
# 将序列数据划分成样本
X, y = split_sequence(raw_seq, n_steps)
# 重塑形状 [samples, timesteps] 变为 [samples, timesteps, rows, columns, features]
n_features = 1
n_seq = 2
n_steps = 2
X = X.reshape((X.shape[0], n_seq, 1, n_steps, n_features))
我们可以根据过滤器的数量将ConvLSTM定义为单层,根据 (rows, columns) 将其定义为二维 kernel_size 的大小。对于一维数据,在核函数中,rows 总是固定为1。在解释和预测模型之前,模型的输出必须被展平。
model.add(ConvLSTM2D(filters=64, kernel_size=(1,2), activation='relu', input_shape=(n_seq,
1, n_steps, n_features)))
model.add(Flatten())
以上五个模型的完整代码:
import numpy as np
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, LSTM, Flatten, Bidirectional
from tensorflow.keras.layers import Conv1D, TimeDistributed, MaxPooling1D
from tensorflow.keras.layers import ConvLSTM2D
class UnivariateModels:
'''
单变量时间序列LSTM模型
'''
def __init__(self, sequence, test_seq, n_seq, n_steps, sw_width, features, epochs_num, verbose_set, flag):
self.sequence = sequence
self.test_seq = test_seq
self.sw_width = sw_width
self.features = features
self.epochs_num = epochs_num
self.verbose_set = verbose_set
self.flag = flag
self.X, self.y = [], []
self.n_seq = n_seq
self.n_steps = n_steps
def split_sequence(self):
for i in range(len(self.sequence)):
# 找到最后一个元素的索引
end_index = i + self.sw_width
# 如果最后一个滑动窗口中的最后一个元素的索引大于序列中最后一个元素的索引则丢弃该样本
if end_index > len(self.sequence) - 1:
break
# 实现以滑动步长为1(因为是for循环),窗口宽度为self.sw_width的滑动步长取值
seq_x, seq_y = self.sequence[i:end_index], self.sequence[end_index]
self.X.append(seq_x)
self.y.append(seq_y)
self.X, self.y = np.array(self.X), np.array(self.y)
for i in range(len(self.X)):
print(self.X[i], self.y[i])
if self.flag == 1:
self.X = self.X.reshape((self.X.shape[0], self.n_seq, self.n_steps, self.features))
elif self.flag == 2:
self.X = self.X.reshape((self.X.shape[0], self.n_seq, 1, self.n_steps, self.features))
else:
self.X = self.X.reshape((self.X.shape[0], self.X.shape[1], self.features))
print('X:\n{}\ny:\n{}\n'.format(self.X, self.y))
print('X.shape:{}, y.shape:{}\n'.format(self.X.shape, self.y.shape))
return self.X, self.y
def vanilla_lstm(self):
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(self.sw_width, self.features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
print(model.summary())
history = model.fit(self.X, self.y, epochs=self.epochs_num, verbose=self.verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
print('yhat:%s'%(model.predict(self.test_seq)),'\n-----------------------------')
# model = Sequential()
# model.add(LSTM(50, activation='relu', input_shape=(self.sw_width, self.features),
# # 其它参数配置
# recurrent_activation='sigmoid', use_bias=True, kernel_initializer='glorot_uniform',
# recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None,
# recurrent_regularizer=None, bias_regularizer=None, kernel_constraint=None, recurrent_constraint=None,
# bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, implementation=2))
# model.add(Dense(units=1,
# # 其它参数配置
# activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros',
# kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None))
# model.compile(optimizer='adam', loss='mse',
# # 其它参数配置
# metrics=None, loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None)
# print(model.summary())
# history = model.fit(self.X, self.y, self.epochs_num, self.verbose_set,
# # 其它参数配置
# callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None,
# initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False)
# model.predict(self.test_seq, verbose=self.verbose_set,
# # 其它参数配置
# steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)
def stacked_lstm(self):
model = Sequential()
model.add(LSTM(50, activation='relu', return_sequences=True,
input_shape=(self.sw_width, self.features)))
model.add(LSTM(50, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
history = model.fit(self.X, self.y, epochs=self.epochs_num, verbose=self.verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
print('yhat:%s'%(model.predict(self.test_seq)),'\n-----------------------------')
def bidirectional_lstm(self):
model = Sequential()
model.add(Bidirectional(LSTM(50, activation='relu'),
input_shape=(self.sw_width, self.features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
history = model.fit(self.X, self.y, epochs=self.epochs_num, verbose=self.verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
print('yhat:%s'%(model.predict(self.test_seq)),'\n-----------------------------')
def cnn_lstm(self):
model = Sequential()
model.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu'),
input_shape=(None, self.n_steps, self.features)))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(50, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse',metrics=['accuracy'])
history = model.fit(self.X, self.y, epochs=self.epochs_num, verbose=self.verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
print('yhat:%s'%(model.predict(self.test_seq)),'\n-----------------------------')
def conv_lstm(self):
model = Sequential()
model.add(ConvLSTM2D(filters=64, kernel_size=(1,2), activation='relu',
input_shape=(self.n_seq, 1, self.n_steps, self.features)))
model.add(Flatten())
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
history = model.fit(self.X, self.y, epochs=self.epochs_num, verbose=self.verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
print('yhat:%s'%(model.predict(self.test_seq)),'\n-----------------------------')
前三个模型:
if __name__ == '__main__':
single_seq = [10, 20, 30, 40, 50, 60, 70, 80, 90]
sw_width = 3
features = 1
n_seq = 2
n_steps = 2
epochs = 300
verbose = 0
test_seq = np.array([70, 80, 90])
test_seq = test_seq.reshape((1, sw_width, features))
UnivariateLSTM = UnivariateModels(single_seq, test_seq, n_seq, n_steps, sw_width, features, epochs, verbose, flag=0)
UnivariateLSTM.split_sequence()
UnivariateLSTM.vanilla_lstm()
UnivariateLSTM.stacked_lstm()
UnivariateLSTM.bidirectional_lstm()
输出:
[10 20 30] 40
[20 30 40] 50
[30 40 50] 60
[40 50 60] 70
[50 60 70] 80
[60 70 80] 90
X:
[[[10]
[20]
[30]]
[[20]
[30]
[40]]
[[30]
[40]
[50]]
[[40]
[50]
[60]]
[[50]
[60]
[70]]
[[60]
[70]
[80]]]
y:
[40 50 60 70 80 90]
X.shape:(6, 3, 1), y.shape:(6,)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 50) 10400
_________________________________________________________________
dense (Dense) (None, 1) 51
=================================================================
Total params: 10,451
Trainable params: 10,451
Non-trainable params: 0
_________________________________________________________________
None
train_acc:0.0
train_loss:603.0445827874324
yhat:[[100.85666]]
-----------------------------
train_acc:0.0
train_loss:337.3305027484894
yhat:[[102.78299]]
-----------------------------
train_acc:0.0
train_loss:283.14844233221066
yhat:[[100.81099]]
-----------------------------
后两个模型:
if __name__ == '__main__':
single_seq = [10, 20, 30, 40, 50, 60, 70, 80, 90]
sw_width = 4
features = 1
n_seq = 2
n_steps = 2
epochs = 500
verbose = 0
test_seq = np.array([60, 70, 80, 90])
test_seq = test_seq.reshape((1, n_seq, n_steps, features))
UnivariateLSTM = UnivariateModels(single_seq, test_seq, n_seq, n_steps, sw_width, features, epochs, verbose, flag=1)
UnivariateLSTM.split_sequence()
UnivariateLSTM.cnn_lstm()
test_seq = test_seq.reshape((1, n_seq, 1, n_steps, features))
UnivariateLSTM = UnivariateModels(single_seq, test_seq, n_seq, n_steps, sw_width, features, epochs, verbose, flag=2)
UnivariateLSTM.split_sequence()
UnivariateLSTM.conv_lstm()
输出:
[10 20 30 40] 50
[20 30 40 50] 60
[30 40 50 60] 70
[40 50 60 70] 80
[50 60 70 80] 90
X:
[[[[10]
[20]]
[[30]
[40]]]
[[[20]
[30]]
[[40]
[50]]]
[[[30]
[40]]
[[50]
[60]]]
[[[40]
[50]]
[[60]
[70]]]
[[[50]
[60]]
[[70]
[80]]]]
y:
[50 60 70 80 90]
X.shape:(5, 2, 2, 1), y.shape:(5,)
train_acc:0.0
train_loss:96.9693284504041
yhat:[[100.737885]]
-----------------------------
[10 20 30 40] 50
[20 30 40 50] 60
[30 40 50 60] 70
[40 50 60 70] 80
[50 60 70 80] 90
X:
[[[[[10]
[20]]]
[[[30]
[40]]]]
[[[[20]
[30]]]
[[[40]
[50]]]]
[[[[30]
[40]]]
[[[50]
[60]]]]
[[[[40]
[50]]]
[[[60]
[70]]]]
[[[[50]
[60]]]
[[[70]
[80]]]]]
y:
[50 60 70 80 90]
X.shape:(5, 2, 1, 2, 1), y.shape:(5,)
train_acc:0.0
train_loss:236.70842473191
yhat:[[103.98932]]
-----------------------------
关于多变量的LSTM模型,将在下文介绍。
参考:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
