大数据:pyspark模块
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
大数据:pyspark模块
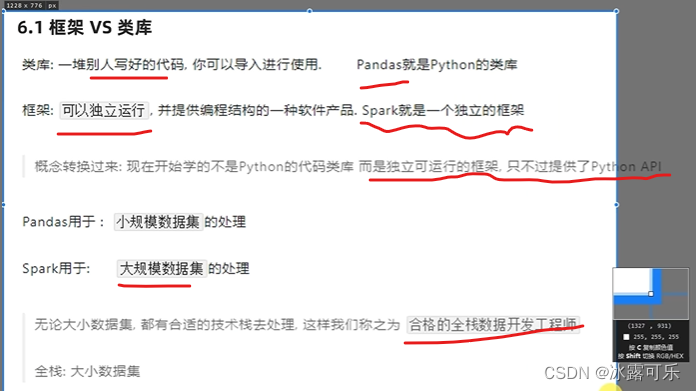
这波pyspark是一个框架API
而不是第三方库,不是第三方代码
而是一个客户端
pyspark是交互式的客户端,可以写独立的程序


spark core的RDD



RDD就是一个抽象的数据对象
目的就是为了在分布式计算框架中统一调度
海量数据,在spark中均衡分布
RDD是spark中最核心的抽象对象
非常非常重要

弹性分布式数据集
不可变、分布式存储,可并行计算
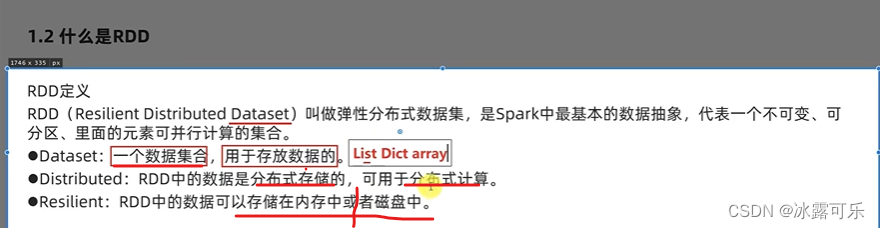
普通的字典、列表,数组,都是在同一个进程内的数据集合
而RDD是分布式存储的,跨进程,跨机器存储的
RDD是弹性的,数据在内存和硬盘中,分区可以动态的增减
美滋滋
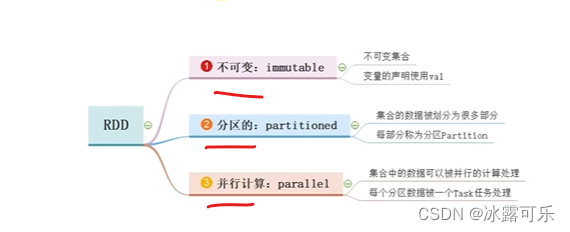
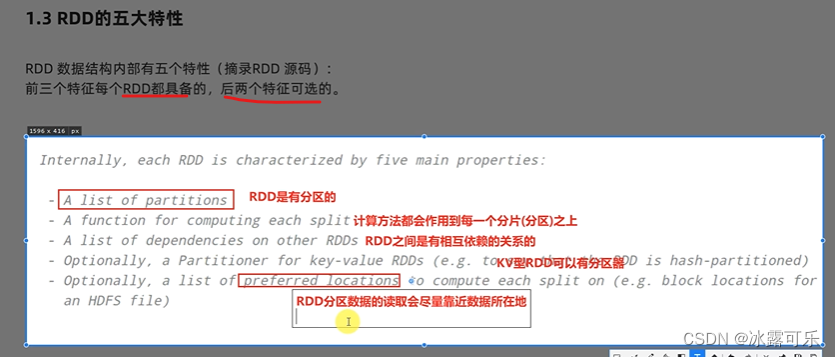
RDD的五大特性
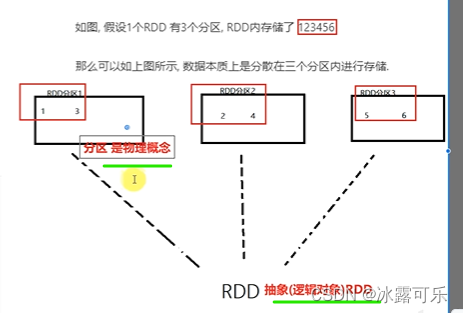
RDD有分区
每个分片有计算方法,作用到每个分片之上
和其他的RDD有依赖关系,相互依赖
kv型RDD可以有分区器
RDD分区数据的读取,尽量靠近数据所在地
尽量少传输
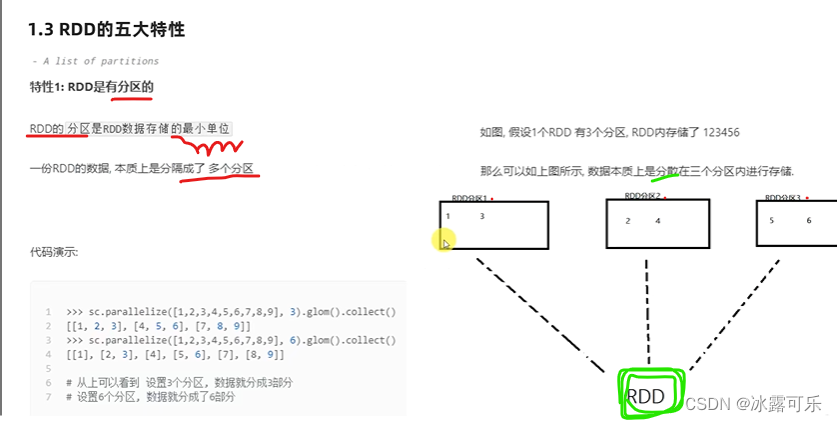
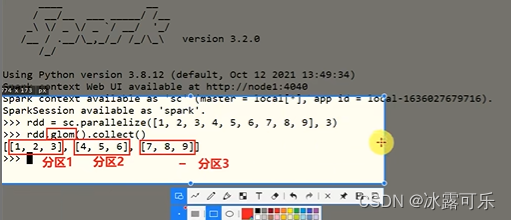
sc是spark core
glom是分区的api
数据RDD本质还是会被分区的哦
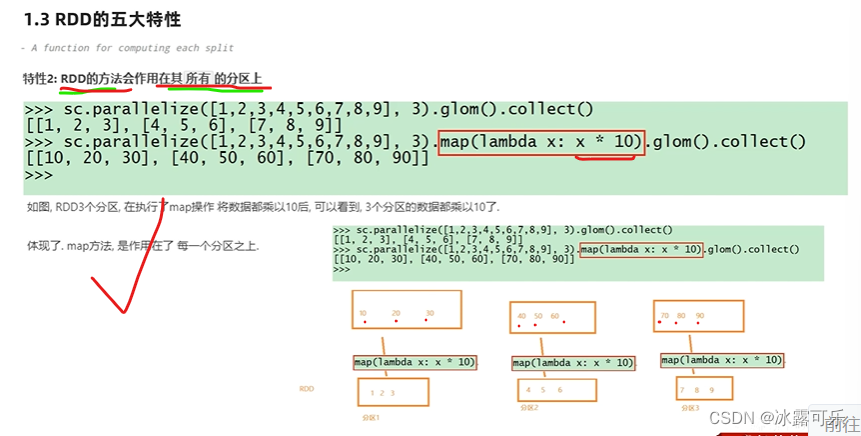
因为你是分开存数据,调用函数时,当然要作用在每个分区上

逻辑就是代码
物理就是要作用于每一个分区之上
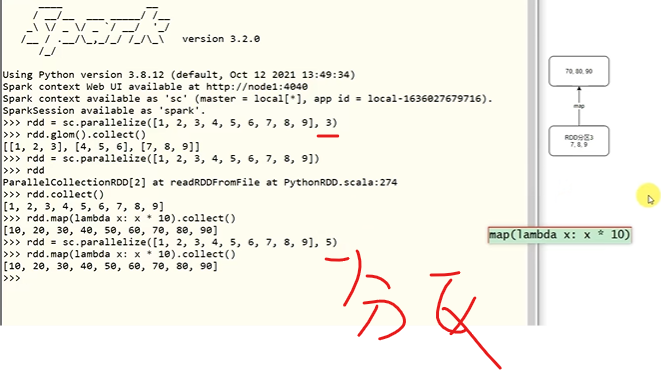

这本身就是程序处理过程中的依赖链条
相当于流水线处理
反正大家并行干活
但是每个过程都是依赖往下走的
最终成品车辆就是一步步搞出来的

key-value二元元组
就是字典


之前讲过,数据均衡
RDD可能不见得都是key-value型的
我们可以拿key来分区,但是非kv型没法分区
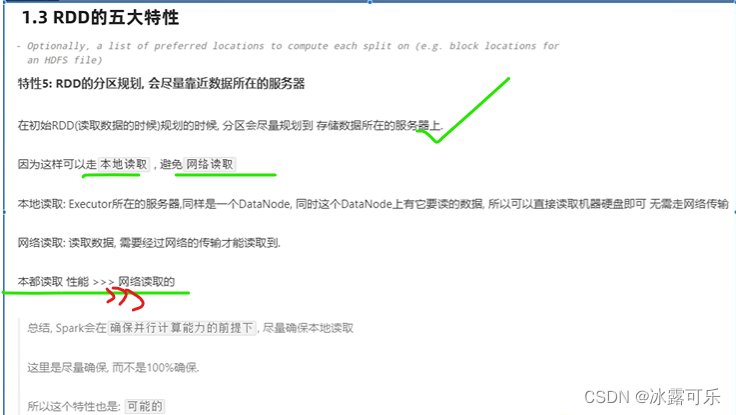
本地读取速度快
不要走网络,传输好麻烦
并行计算的能力为核心
wordcount案例分析
看看是怎么计算出来的
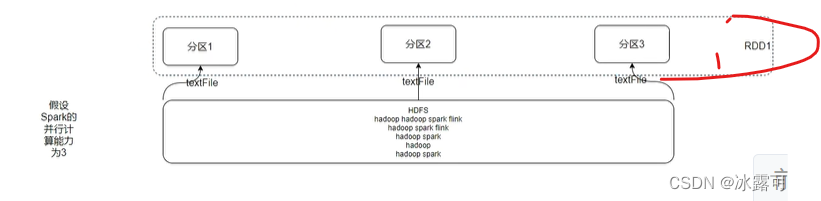
干活,三条路线分区走起
经过flatmap,仨分区都要作用函数,拉平
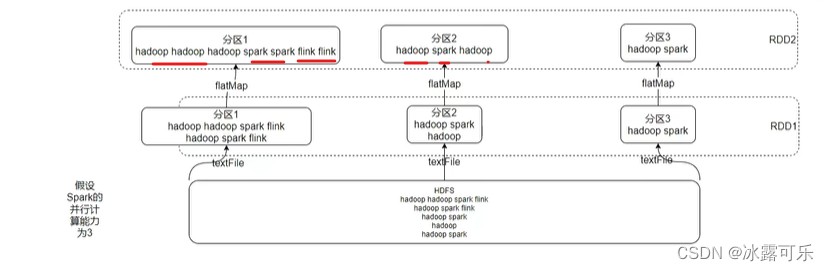
然后统计单词的个数
map
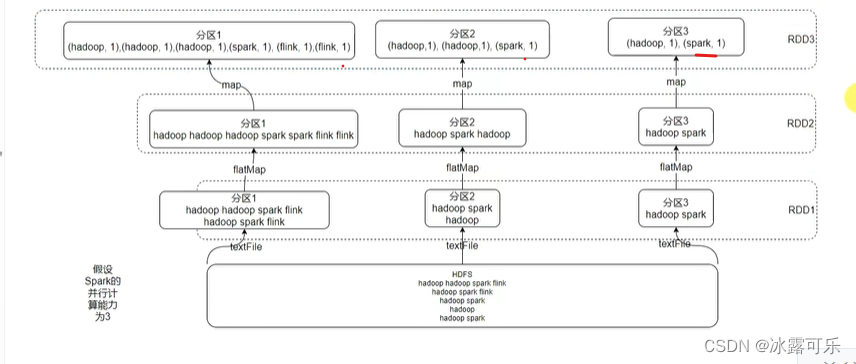
最后就是reduce了聚合
相同的放一起统计
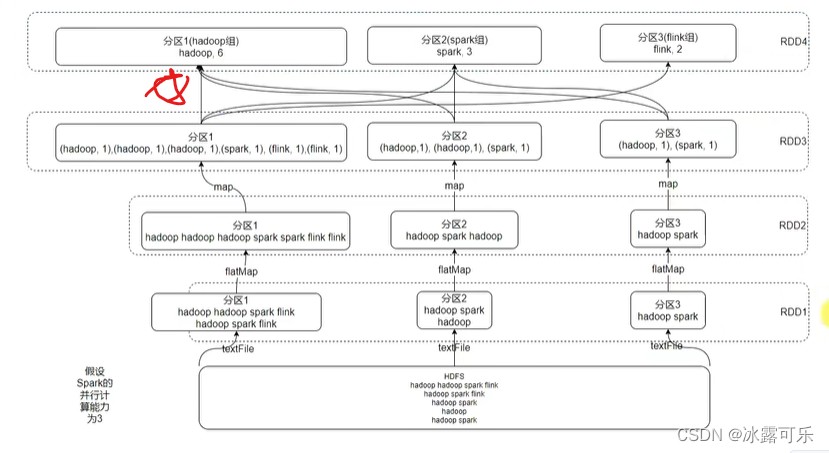
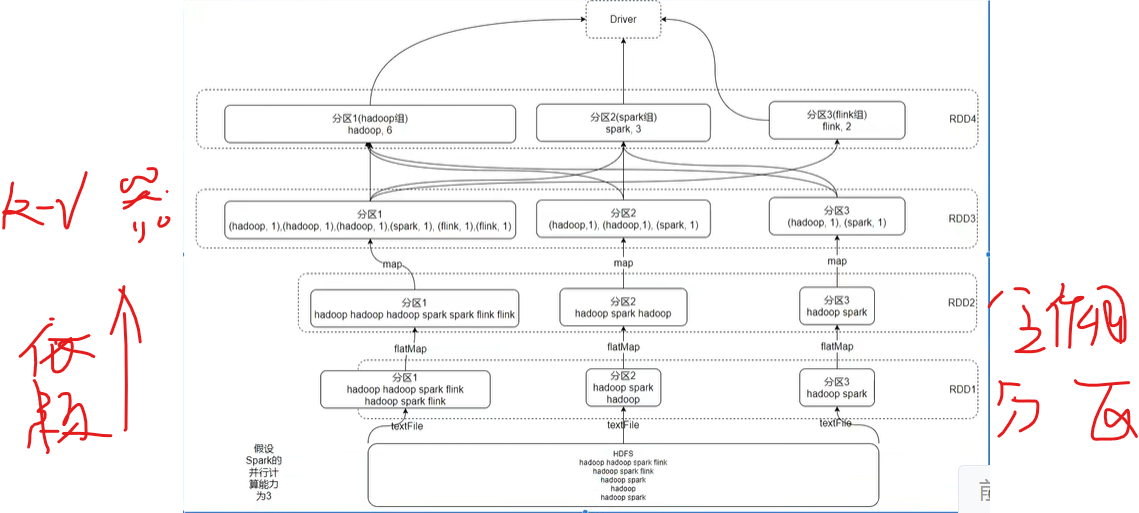
然后收集数据
哈希规则分区器
默认分组
在计算过程中,就近读取
这就是RDD五大特性!!!
RDD:弹性分布式数据集(是一个数据抽象)
分区,并行

总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。