1 宽依赖和窄依赖
RDD从具体的依赖的角度讲,有窄依赖和宽依赖2种情况。
窄依赖:指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter等都会产生窄依赖;
宽依赖:指一个父RDD的Partition会被多个子RDD的一个Partition所使用,如groupByKey,reduceByKey等操作都会产生宽依赖。
总结:如果父RDD的一个Partition被一个子RDD的Partition使用就是窄依赖,否则就是宽依赖。如果子RDD的Partition对父RDD的Partition依赖的数量不会随着RDD数据规模的改变而改变就是窄依赖,否则就是宽依赖。
特别说明:对join操作有两种情况,如果说join操作的时候每个partition仅仅和已知的Partition进行join,这次是join操作就是窄依赖;其它情况(input not co-partitioned 会产生shuffle操作,而co-partitioned是哪几个固定的Partition进行join)的join操作就是宽依赖;
因为是确定的partition数量的依赖关系,所有就是窄依赖,得出一个推论,窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变)

2 RDD根据依赖关系构成Stage

RDD基于不同的依赖关系构成了Stage,我们到底能不能把所有的RDD放在一个任务中运行:
假设一:Spark一开始是将所有相关联的RDD构成一个Stage,上图中的ABCDEFG 这些RDD都放在一个Stage中,groupByKey,join等操作,其中的严重问题是,需要挨个执行,产生了大量的中间数据(中间数据需要被存储起来,下一步才会执行,导致内存无法释放)。
从执行逻辑图的角度来看在每个RDD中不同的Partition是独立的,这个是数据分片的一个基本特征,也就是在RDD内部每个Partition数据彼此之间不会干扰。假设G是最后一个RDD,为最后一个RDD每个Partition分配一个具体的任务。最后一个RDD有3个Partition,为每个Partition分配一个task。这个时候第一个数据分片来自B和F,B的数据来自A的3个分片,这样做的话有很大的问题:①耗性能,重复计算:task太大,而且遇到shuffle级别操作的时候就必须计算依赖的RDD的所有Partition,而且都发送在一个task中计算。而且第2,3个Partition还要重复计算②存储浪费;从后往前的依赖关系,看哪些RDD进行cache,如果从G的角度看,3个分片各自算各自的,这也是数据存储的浪费。
上述假设,核心问题都是在遇到shuffle依赖(宽依赖)的时候,无法进行pipeline。则采取在有shuffle依赖的时候断开处理,原因是浪费内存、重复计算、任务太大、不方便管理。所以要采用现在从后往前推理,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到该Stage中的方式。
回溯,血统从计算的角度说到底都是pipeline,每个Stage里面的Task数量是由该Stage中最后一个RDD的Partition的数量所决定的。最后一个Stage里面的任务的类型是ResultTask,前面其它所有的Stage里面的任务的类型多是ShuffleMapTask。
我们的计算表面上看是数据在流动,实质上是算子在流动:有两层含义①集群计算角度:数据不动代码动②在一个Stage内部算子为何会流动(pipeline)?首先是算子合并也就是,也就是所谓的函数式编程,执行的时候会最终进行函数的展开从而把一个Stage内部的多个算子合并成为一个大算子(其内部包含当前Stage所有算子对数据的计算逻辑);其次是由于Tranformation操作的lazy特征!!!在具体算子交给集群的executor计算之前首先会通过DAGScheduler进行算子的优化(基于数据本地性的pipeline)那就不会产生中间结果。
注意:shuffle依赖一般是k-v的形式,并且k不可以是数组
3 RDD依赖源码
spark的宽依赖(narrow dependency)和窄依赖(wide dependency)继承于Dependency。Dependency是个抽象类,只包含一个rdd,是它依赖的parentRDD.

Dependency一个很重要的要求是,子RDD可以为其每个partition根据dependency找到它所对应的父RDD的partition,或者是找到计算的数据来源,所以每个实现的Dependency都要提供根据partitionID获取parentRDD的partition的方法。
3.1 窄依赖
NarrowDependency中子RDD的每个分区依赖少量(一个或多个)parent RDD分区,即parent RDD的partition至多被子RDD的某个partition使用一次。

窄依赖继承于Dependency并定义了一个获取parent rdd的方法,下面看窄依赖的子类: OneToOneDependency和RangeDependency。
OneToOneDependency
OneToOneDependency是一对一依赖关系,子RDD的每个partition依赖单个parentRdd的一个partition。常见的OneToOneDependency有map, filter, join等。源码如下:

实现了getParents方法:子RDD以及父RDD之间,每个partition是对应(如果子RDD中存在的话)的,所以两个RDD中的对应的partition应该具有相同的partitionId。
此类的Dependency中parent中的partitionId与childRDD中的partitionId是一对一的关系,也就是partition本身范围不会改变,一个parition经过transform还是一个partition,虽然内容发生了变化,所以可以在local完成,此类场景通常像mapreduce中只有map的场景。
RangeDependency
rangeDependency是子rdd的每个partition依赖多个父parentRdd的一个partition。常见的RangeDependency有union。

几个私有变量解释如下:Rdd:父RDD;inStart:父RDDpartition的起始位置;outStart:UnionRDD的起始位置;length:父RDD partition的数量。父RDD中的partition通常是子RDD中,连续的某块partition区间的父partition,所以对应关系应该是parentPartitionId = childPartitionId - childStart + parentStart。
重写了getParents方法:parentRDD在最终的rdd的位置[outStart, outStart + parentRDDLength]
该依赖关系仍然是一一对应,但是parentRDD中的某个区间的partitions对应到childRDD中的某个区间的partitions。典型的操作是union,多个parentRDD合并到一个childRDD,所以将每个parentRDD都对应到childRDD中的一个区间。需要注意的是:union不会把多个partition合并成一个partition,而是的简单的把多个RDD中的partitions放到一个RDD里面,partition不会发生变化。
它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同
3.2 宽依赖
宽依赖,是在shuffle stage的时候的依赖关系,是划分Stage的重要标志,依赖首先要求是PariRdd即k,v的形式才能做shuffle。宽依赖只有ShuffleDependency一个实现。每个Shuffle过程会有一个Id,ShuffleDependency可以根据这个ShuffleId去获得所依赖的partition的数据,所以ShuffleDependency所需要记录的就是要能够通过ShuffleId去获得需要的数据。

ShuffleDependency类有3个泛型参数,K代表键类型,V代表值类型,而C则代表Combiner的类型。因为Shuffle过程对键值型数据才有意义,所以ShuffleDependency对父RDD的泛型类型有限制,必须是Product2[K,V]或者其子类,Product2在Scala中代表两个元素的笛卡尔积。
构造方法参数说明:①partitioner:分区器②serializer:闭包序列化器,SparkEnv中已经创建,为JavaSerializer。③keyOrdering:可选的对键类型K排序的排序规则。④aggregator:可选的Map端数据聚合逻辑。⑤mapSideCombine:指定是否启用Map数据预聚合。
还会调用SparkContext.newShuffleId()方法分配一个新的Shuffle ID,以及调用ShuffleManager的registerShuffle方法注册该Shuffle,返回Shuffle句柄(ShuffleHandle)
4、Partitioner分区器
4.1 Partitioner类
Partitioner是一个抽象类,用于处理key-value类型的RDD,按照key进行元素的划分
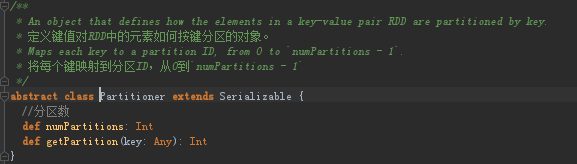
只有两个方法:numPartitions获取分区个数和getPartition(key: Any)根据Key值得到分区ID

在Partitioner的伴生对象中有defaultPartitioner方法,HashPartitioner 是Spark默认的分区器,除非RDD已经指定了一个分区器;对于分区数量,如果设置了配置项spark.default.parallelism,那么使用该配置,否则使用上游分区的最大数目

4.2 HashPartitioner

根据上图源码可知:传入的参数partitions决定总的分区数;重写的numPartitions方法也只是简单返回该值;重写的getPartition实际上是调用了Utils工具类的nonNegativeMod方法,将以key的hashcode和numPartitions作为参数
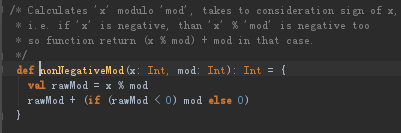
nonNegativeMod方法将对key的hashCode和numPartitions进行取模运算,得到key对应的分区索引。使用哈希和取模的方式,可以方便地计算出下游RDD的各个分区将具体处理哪些key。由于上游RDD所处理的key的哈希值在取模后很可能产生数据倾斜,所以HashPartitioner并不是一个均衡的分区计算器
reduceByKey,aggregateByKey,join内部默认都是使用HashPartitioner
4.3 RangePartitioner
HashPartitioner的实现原理可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据,这是不希望的。而RangePartitioner分区则尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,也就是说一个分区中的元素肯定都是比另一个分区内的元素小或者大;但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
RangePartitioner分区执行原理概述:
1.计算总体的数据抽样大小sampleSize,计算规则是:至少每个分区抽取20个数据或者最多1e6的样本的数据量。
2.根据sampleSize和分区数量计算每个分区的数据抽样样本数量最大值sampleSizePrePartition。
3.根据以上两个值进行水塘抽样,返回RDD的总数据量,分区中总元素的个数和每个分区的采样数据。
4.计算出数据量较大的分区通过RDD.sample进行重新抽样。
5.通过抽样数组 candidates: ArrayBuffer[(K, wiegth)]计算出分区边界的数组BoundsArray
6.在取数据时,如果分区数小于128则直接获取,如果大于128则通过二分法,获取当前Key属于那个区间,返回对应的BoundsArray下标即为partitionsID。
RangePartitioner分区器的主要作用就是:将一定范围内的数映射到某一个分区内,所以它的实现中分界的方法rangeBounds尤为重要



private var rangeBounds: Array[K] 获取对应分区的边界。每个Range内的数据进入一个分区。首先当Partitioner大于1,那么给定总的数据抽样大小,最多1M的数据量(10^6),最少20倍的RDD分区数量,也就是每个RDD分区至少抽取20条数据,sampleSize是初步的负载均衡;sampleSizePerPartition是由于依赖的父RDD数据时不均匀的,有些Partition数据量会很大,有些Partition数据量会很小。其中乘3的目的是保证数据量特别小的分区能够抽取到足够的数据,同时保证数据量非常大的分区能够进行二次抽样。
然后确定各partition对应的边界,即rangeBounds。首先,利用 RangePartitioner伴生对象的sketch()方法对输入的RDD的每一个 partition进行抽样,抽样方法采取的是水塘抽样(Reservoir Sampling),可以在不知道总size的情况下进行抽样,特别适用于数据在内存存不下的情况。

因为分区只需要对key进行操作,所以RangePartitioner.sketch的第一个参数是rdd.map(_._1)。该函数返回值是val (numItems, sketched) ,其中numItems相当于记录rdd元素的总数;而sketched的类型是Array[(Int, Long, Array[K])],记录的是分区的编号、该分区中总元素的个数以及从父RDD中每个分区采样的数据。
sketch函数对父RDD中的每个分区进行采样,并记录下分区的ID和分区中数据总和。reservoirSampleAndCount函数就是典型的水塘抽样实现,唯一不同的是该算法还记录下i的值,这个就是该分区中元素的总和。
回到RangePartitioner方法中,如果获取的数据分布不均匀,则边界方法rangeBounds会再次抽样,但是只对抽象数少于要求的partition进行sample,其他抽样好的不会
最后获取到每个partition中每个样本和对应的weight( 类似candidates += ((key, weight))),weight为partition中元素数量与抽样数量的比值,对于重新抽样的,则为1。
最后通过RangePartitioner伴生对象的determineBounds()方法进行边界确定,获得边界值组成的数组Array[K]; Array[K]被赋值给rangeBounds,即各partition对应的边界
determineBounds主要对 candidates先按key进行排序,然后获取总抽样元素除以partition大小即为每个partition理论的大小,即代码中的step。
然后再对排序好的ordered进行遍历,当所代表的权重大于step的整数倍时,返回此时的key,作为划分条件。然后依次类推,获得每个partition的边界key。
总结:RangePartitioner是采取抽样的策略,每个partition理论的是抽取20个元素,实际采用水塘抽样(Reservoir Sampling)时为了避免抽样少于期望,会乘以3.然后再用determineBounds对抽样数据进行排序,weight是每个key所代表的抽样数量,再按weight确定每个partition接近理论的边界,并进行返回,即为partitionid(getPartition返回值)。
getPartition查找某个元素应该所属的partitionid时,如果partition数量过大,会采取二分查找。
4.4 水塘抽样算法(Reservoir Sampling)
水塘抽样是一系列的随机算法,其目的在于从包含n个项目的集合S中选取k个样本,其中n为一很大或未知的数量,尤其适用于不能把所有n个项目都存放到主内存的情况。
首先假设要从一个不知道行数的文本中等概率抽取一行,要如何做的?定义取出的行号为num,第一次以第一行作为取出行 num,而后第二次以二分之一概率决定是否用第二行替换 num,第三次以三分之一的概率决定是否以第三行替换 num……,以此类推。得出结论,在取第n个数据的时候,我们生成一个0到1的随机数p,如果p小于1/n,保留第n个数。大于1/n,继续保留前面的数。直到数据流结束,返回此数,算法结束。
将上面的条件变为,k为任意整数的情况,即要求最终返回的元素有k个,这就是水塘抽样(Reservoir Sampling)问题。要求是:取到第n个元素时,前n个元素被留下的几率相等,即k/n。
算法同上面思路类似,将1/n换乘k/n即可。在取第n个数据的时候,我们生成一个0到1的随机数p,如果p小于k/n,替换池中任意一个为第n个数。大于k/n,继续保留前面的数。直到数据流结束,返回此k个数。但是为了保证计算机计算分数额准确性,一般是生成一个0到n的随机数,跟k相比,道理是一样的。
用伪代码表示如下所示:
| 从S中抽取首k项放入「水塘」中 对于每一个S[j]项(j ≥ k): 随机产生一个范围0到j的整数r 若 r < k 则把水塘中的第r项换成S[j]项 |
