Spark中的RDD以及分区
RDD
在spark中,最重要的概念就是RDD,它本质上是一个数据的引用,可以把它理解为C语言中的指针,即RDD本身是不存储数据的,但是通过操作RDD,我们就可以直接操作保存在分布式系统中的数据。所以RDD是存储在系统中数据的一个代理。
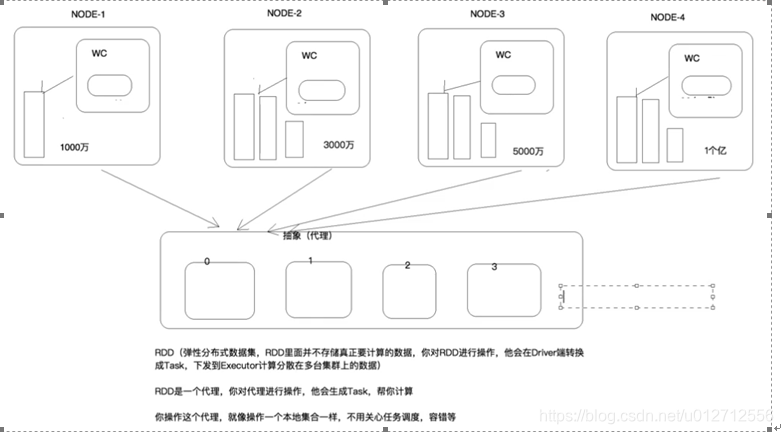
在上面的图片中,我们可以看到系统中的一份文件实际是由多个分布在多台设备上的文件块构成的。如果我们每次都只能获取某台设备上的文件,那要操作这个完整的文件就会非常麻烦。所以在Spark中就引入了RDD的概念。RDD就代表了这些小文件块。在使用时,可以把一个RDD就看成那个完成的文件,虽然它是文件的引用。
RDD中的分区
接下来我们再来分析RDD内部的结构。如果要将RDD再往下细分,那就是分区了,以为一个RDD中包含了多个分区。通过上面的学习我们了解到,RDD中的数据可能是分布在多台设备的,也就是是RDD所指向的数据是由多个文件块构成了。所以可以理解成 每个逻辑上的分区就指向了一个一个物理上的数据块。
那分区是怎么产生的呢?
1 从HDFS中读取文件
如果最初的RDD是从HDFS中读取数据而得到了,那数据再HDFS中也是分块保存的。假如这个文件在HDFS中有三个块,那spark就会启动三个task去从HDFS中读取数据,然后每个task产生一个分区,最终产生了三个分区,这三个分区就构成了一个RDD。
2 在reduce后产生新的分区
在spark在获取了数据后,通常会经过map和reduce,这些过程都会时RDD的内容发生改变,也就是使分区发生了改变。一下介绍几种分区产生的方式。
2.1 HashPartitioner
也就是根据RDD中数据的key的hash值来确定这个数据该放入的分区的索引值。
scala> val counts = sc.parallelize(List((1,'a'),(1,'aa'),(2,'b'),(2,'bb'),(3,'c')), 3)
.partitionBy(new RangePartitioner(3,counts))
HashPartitioner确定分区的方式:partition = key.hashCode () % numPartitions
2.2 RangePartitioner
scala> val counts = sc.parallelize(List((1,'a'),(1,'aa'),(2,'b'),(2,'bb'),(3,'c')), 3)
.partitionBy(new RangePartitioner(3,counts))
RangePartitioner会对key值进行排序,然后将key值被划分成3份key值集合。
2.3 CustomPartitioner
自定义分区器,比如分区中数据格式为((学科名称,教师名称), 点击次数),如果使用默认分区器,会根据key,也就是(学科名称,教师名称)来计算hash值来确定所属分区的索引值。但是如果我们想学科名称相同的数据在同一个分区中,那就可以使用自定义分区器。在这个分区器中,使用key中的学科名称来计算hash值即可。
···
class CustomPartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int =
{
if(key1)){
0
} else if (key2){
1} else{
2 }
}
}
scala> val counts = sc.parallelize(List((1,‘a’),(1,‘aa’),(2,‘b’),(2,‘bb’),(3,‘c’)), 3).partitionBy(new CustomPartitioner(3))
···
分区数量的影响
如果分区太少,会导致系统中部分设备,即worker上没有分区,也就是说这次计算任务只有部分worker参与了,就没有充分利用集群的资源。如果分区太多,也就意味了需要被调度的任务多,这个过程中也会浪费很多资源。
