【Spark & Hadoop 的分区】
- Spark 的分区是切片的个数,每个 RDD 都有自己的分区数。
- Hadoop 的分区指的是 Reduce 的个数,是 Map 过程中对 Key 进行分发的目的地。
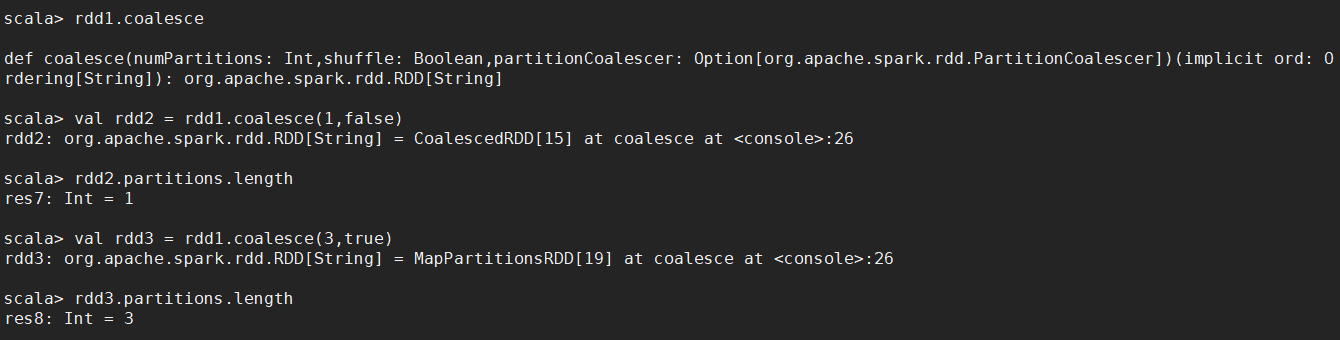
【指定分区 repartition 和 coalesce】
rdd.repartition() 调用的就是 coalesce,始终进行 shuffle 操作。
如果是减少分区,推荐使用 coalesce,可以指定是否进行 shuffle 操作。
通过 coalesce 增加分区时,必须指定 shuffle 为 true,否则分区数不变。