一、摘要
在本文中,我们介绍了一种基于几何推理的检测和过滤异常值的技术。我们测试由三个点组成的三角形的有效性,如果不满足三角形不等式,则将三角形标记为断开。
1 I
NTRODUCTION
多维比例缩放(MDS)是数据分析和信息可视化中的一个基本问题.MDS将包含元素xi之间的所有
 对距离的距离矩阵D作为输入,并将元素嵌入到d维空间中,以成对的距离 Dij 由 ||xi-xj|| 尽可能地保留在嵌入式空间中。 当距离数据没有异常值时,最新的方法(例如SMACOF)可提供令人满意的解决方案。 这些解决方案基于所谓的压力函数的优化,压力函数是相异度Dij及其对应的嵌入矢量间距离之间的平方误差之和:
对距离的距离矩阵D作为输入,并将元素嵌入到d维空间中,以成对的距离 Dij 由 ||xi-xj|| 尽可能地保留在嵌入式空间中。 当距离数据没有异常值时,最新的方法(例如SMACOF)可提供令人满意的解决方案。 这些解决方案基于所谓的压力函数的优化,压力函数是相异度Dij及其对应的嵌入矢量间距离之间的平方误差之和:

在许多实际情况下,由于恶意行为,系统故障或错误措施,输入距离可能很嘈杂或包含异常值。 许多MDS技术处理嘈杂的数据,但很少关注异常值。
我们称离群值与噪声相反,是指距离与其对应的真实值明显不同。 由于即使一小部分离群值也会导致重大错误,因此开发强大的MDS具有挑战性。 MDS对异常值的敏感性在图1中得到了证明,其中只有两个成对的距离(435个对中的)是错误的(在(a)中以红色显示),导致嵌入中的强烈变形(b)。 为了突出显示嵌入错误,我们绘制了在地面真实位置和嵌入位置之间连接的线。

图1:两个离群值距离(在左侧用虚线标记)导致嵌入中的明显变形,如地面和嵌入位置之间的大偏移量所反映的那样(如右图所示)。
在本文中,我们介绍了一种强大的MDS技术,该技术可以检测并从数据中删除异常值,从而提供更好的嵌入效果。
我们的方法
基于几何推理,可通过分析给定的输入距离来识别异常值。 这种方法遵循众所周知的成语“预防胜于治疗”。 也就是说,我们没有从异常值对MDS优化造成的损害中恢复过来,而是通过检测并过滤掉它们来首先防止它们。
我们将距离视为
 条边的完整图。
条边的完整图。
每个边都与其对应的距离相关联,并且与其余N-2个节点一起形成N-2个三角形。 我们工作的前提是,异常距离往往会打破许多三角形。 如果三角形的不等式不成立,我们将其称为断开的三角形。 正如我们将要展示的,虽然
内线边参与了相当少的断三角形,但离群边参与了许多。 这使我们设置保守的阈值并将边缘及其相关距离分类为内群值和离群值(请参见图2)

图2:(a):两个扭曲距离的效果,用红色虚线标记。 (b):绿线表示违反三角形不等式的边。 (c):更强的变形会导致更多的断三角形
一般而言,MDS是一个无法确定的问题,因为距离矩阵包含的距离远多于正确解决该问题所需的距离。 因此,该想法是在应用MDS之前检测怀疑离群的距离并删除它们。 在下文中,我们表示并引用了带有TMDS的健壮MDS方法。 就像我们将要展示的那样,我们的技术成功地检测并去除了大多数没有任何参数的离群值,同时产生较少数量的误报,以促进更准确的嵌入。 我们在大量具有不同分布的异常值部分的数据集上测试,分析和评估了我们的方法。
2 B
ACKGROUND
MDS最初是在心理学领域使用和开发的,作为可视化对象之间的知觉关系的一种手段[8],[9]。 如今,MDS被广泛用于各种领域,例如市场营销[10]和图形嵌入[11]。 最值得注意的是,MDS在数据探索[12],[13],[14]和计算机图形应用(例如纹理映射[15],形状分类和检索[16],[17],[18]和[ 更多。
建议了几种方法来处理数据中的异常值(例如[5],[7])。 使用Sammon加权[19]会产生以下应力函数:

该目标函数可以有效地视为对长距离具有鲁棒性,因为它
减少了长距离的权重。 我们区分两种类型的异常值:较大和较短的异常值(在图3和4中分别用蓝色和红色表示),因为它们的特征和效果不同,因此可能需要不同的处理方法。 在(a)中,我们显示2D数据元素,其中离群值标记为红色和蓝色。 在(b)中,我们通过应用最新的MDS(即SMACOF)显示了他们的头寸;在(c)中,是Sammon方法的结果[19]。 可以看出,通过给它们分配低权重,Sammon方法可以很好地处理拉长的距离。但是,缩短的距离不能很好地处理,因为它们被分配了较大的权重,从而导致嵌入变形。

图3:(a)蓝线表示放大的距离。(b)嵌入SMACOF。 (c)Sammon嵌入。

图4:(a)蓝线表示缩短的距离。(b)嵌入SMACOF。 (c)Sammon嵌入。
与我们最相关的工作是Forero和Giannakis [6]提出的方法,以下简称为FG12。他们使用目标函数F(X; O)来寻找嵌入X和离群矩阵O,以最小化以下:

其中lambda调节O中表示异常值的非零值的数目。
设置lambda的大小来控制Oij的稀疏性并不容易。 如果lambda太大,则检测到异常值太少;反之, 如果太小,则将太多的边缘视为离群值。 正如我们将显示的,λ的接近值可能导致不同的结果。 这种现象示于图5(a-c)。 因此,需要仔细调整lambda以获得良好的结果。 这也将是一个过于复杂的过程,因为也将显示,该算法对初始猜测也很敏感。
请注意,X具有d x N个未知变量,O具有
 个变量。 这导致参数数量的显着增加,因此与SMACOF相比,优化FG12困难得多。 在图5中可以明显看出这一点,我们在图(d-f)中显示了将相同lambda应用于相同的数据集,但初始猜测不同的情况。 如图所示,三个初始猜测产生了不同数量的边缘,这些边缘被视为离群值。 在图6中也可以观察到FG12方法的这种行为。对于黄色曲线,lambda = 1.8是检测正确数目的异常值的值。 但是,对于相同的lambda值,蓝色图会将大多数边缘检测为离群值。 这突出显示了FG12方法的灵敏度,并强调,即使我们对系统中的异常值数量有了很好的估计,我们也无法设置lambda的值。
个变量。 这导致参数数量的显着增加,因此与SMACOF相比,优化FG12困难得多。 在图5中可以明显看出这一点,我们在图(d-f)中显示了将相同lambda应用于相同的数据集,但初始猜测不同的情况。 如图所示,三个初始猜测产生了不同数量的边缘,这些边缘被视为离群值。 在图6中也可以观察到FG12方法的这种行为。对于黄色曲线,lambda = 1.8是检测正确数目的异常值的值。 但是,对于相同的lambda值,蓝色图会将大多数边缘检测为离群值。 这突出显示了FG12方法的灵敏度,并强调,即使我们对系统中的异常值数量有了很好的估计,我们也无法设置lambda的值。

图5:(a-c)将不同的lambda应用于相同的数据集相同的初始猜测会导致不同的嵌入质量。(d-f)将相同的lambda应用于具有不同初始猜测的相同数据集会产生不同的嵌入质量。

图6:此图显示了非零元素的数量,在O(代表离群值)中作为lambda的函数。 这三个图是使用统一采样的不同初始猜测生成的。 这表明FG12方法对初始猜测过于敏感。 在本实验中,我们使用N = 50(1225个边)和100个离群值
3 D
ETECTING OUTLIERS
我们的技术估计每个距离为离群值的可能性。 我们将
 个距离视为连接N个顶点的
个距离视为连接N个顶点的
 条边的完整图。 每个边缘都与其对应的距离相关联,并且与其余N-2个元素一起形成N-2个三角形。关键的想法是,
内部的边参与了一个相当少的破碎三角形,而离群的边参与了许多。 我们将看到,通过分析三角形的直方图,我们可以设置一个保守的阈值并将边缘及其相关距离分类为离群值和离群值。 参见图2。
条边的完整图。 每个边缘都与其对应的距离相关联,并且与其余N-2个元素一起形成N-2个三角形。关键的想法是,
内部的边参与了一个相当少的破碎三角形,而离群的边参与了许多。 我们将看到,通过分析三角形的直方图,我们可以设置一个保守的阈值并将边缘及其相关距离分类为离群值和离群值。 参见图2。
令D代表图顶点之间的成对距离。 在存在异常值的情况下,某些边缘不能表示正确的欧几里得关系。 尤其是,
错误的边长会破坏由边及其两个端点顶点和其余N-2个顶点中的第三个顶点形成的三角形。
回想一下,在这里,断开的三角形是不适用三角形不等式的三角形。
通过遍历图中的所有三角形,我们可以轻松地识别所有断开的三角形。 对于任何边长为(d1, d2, d3)的三角形,其中d1 <d2 <d3,我们测试:d1 + d2 <d3,然后对图中的每个边进行计数,计算其参与的破三角形的数量生成直方图H,
其中H(b)表示参与b个破三角形的边的数量。 图7描绘了这种典型的直方图。 可以看出,大多数边缘都参与了少量的断三角形。 直方图的长尾与离群值相关。
应该注意的是,
离群边缘不一定会破坏其所有三角形,但是在数量上它会脱颖而出,并且正如我们将看到的那样,很可能会被检测到。

图7:直方图H(b)计算出打破“ b”三角形的边的数量。 可以看出,大多数边缘仅破坏了几个三角形。 直方图的尾部与离群值相关。 y轴是对数的,可以更好地感知方差。
我们希望确定阈值Phi来对离群值进行分类,即将参与超过Phi断三角形的边分类为离群值。
无法设置阈值Phi来准确地对内部/外部边缘进行分类。 相反,我们提出了一种
通过分析直方图H来确定此阈值的简单方法。将其设置为满足以下两个要求的最小值:

第一项要求确保大多数边缘不被视为离群值。 在大多数情况下,此假设成立,但可以根据问题设置进行调整。
第二个要求对应于观察,离群边缘倾向于沿直方图H的尾部形成一个高的bin(图7)。这种简单的启发式方法在经验上表现良好(见第4节)。
选择阈值后,我们可以从数据中删除关联的距离,然后使用剩余的距离通过MDS计算嵌入。 算法1中描述了TMDS的高级伪代码。


4 A
NALYSIS
4.1 Algorithm complexity
测试所有三角形以识别损坏的三角形,时间复杂度为O(N3),比SMACOF(O(N2))大一个数量级。为了避免增加MDS方法的总时间复杂度,我们
可以对O(N2)个三角形进行二次采样并仅基于它们构建直方图。我们可以使用统一采样,其中对于每个边Dij,我们采样恒定数量的点以形成恒定数量的三角形。如图8所示,测试三角形太少可能会降低检测率。可以看到每个边缘有45个三角形足以检测大多数离群值,并且可以与N很好地缩放。根据经验,我们观察到有效的经验法则是,采样比预期的异常值数量多两倍的三角形。在实践中,对于N = 100的TMDS,使用Matlab中的非优化实现仅需2秒钟,而无需任何子采样,而使用SMACOF计算嵌入本身仅需1.9秒钟。这表明过滤步骤不会产生很大的开销。参见表1。
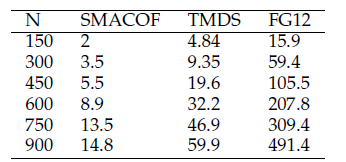
表1:从具有多个(N)个对象的二维单位超立方体中均匀采样的三种数据嵌入算法的CPU时间(以秒为单位)。 距离矩阵被10%的异常值污染。 所有方法均在Matlab中实现,并在i3-6200U处理器的单核上进行了测试。 对于TMDS,我们每个边缘采样了100个三角形,对于FG12,我们使用了lambda =2。TMDS比FG12快,并且与SMACOF相比,正如预期的那样,其乘积开销几乎恒定。

图8:检测到的离群值数量是二次采样的每个边缘三角形的数量的函数。 数据包含15个离群值。
4.2 Evaluation
为了评估TMDS,我们使用了各种幅度的综合数据,尺寸和异常值部分。 我们测量检测离群值的精确召回性能,以及使用和不使用离群值过滤的嵌入质量。 更精确地说,我们通过在d维超立方体中随机采样N个点来合成地面数据,并计算它们之间的成对距离D.我们随机选择M个元素并将其替换为距离矩阵中的随机元素。
定性评估。 我们使用Shepard图以可视方式将数据元素的分类显示为离群值或离群值。 在图9的图中,每个点代表一个距离。 X轴表示输入距离,Y轴表示嵌入结果中的距离。 主对角线上的点是表示在嵌入中正确保留的距离的内点。 红色圆圈表示TMDS检测为异常值的距离,斜对角外的蓝色点是假负,对角线上的红点是假正距离。

图9:谢泼德图。 每个点代表一个距离,X轴代表输入距离,Y轴代表嵌入结果中的距离。Y轴代表嵌入结果中的距离。 红色圆圈代表被视为离群值的边缘。 (a)离群值2%。 (b)10%的异常值。
定量评估。 我们采用两种模型进行定量评估TMDS。 在第一种方法中,我们随机选择离群值,而在第二种方法中,所有边均因对数正态分布而失真。
首先,我们使用精确调用来测量异常值检测的准确性。 每个距离都可以分类为离群值或离群值,因此可以将检测视为一个检索过程,其中精度是检索到的离群值是真实正数的比例,召回率是被检测到的真实正值的比例。 如图10所示,
我们的精度和召回率很高,其中前者随着离群值的数量而适度降低,而后者则增加。精度大于75%,这意味着滤波距离的不可忽略部分为假阳性。 但是,过多的过滤不会造成破坏性的影响,因为MDS是一个过分确定的问题。 但是,在某些时候,过滤太多距离会损害嵌入效果,如下面的单独实验所示。

检测概率。 图11显示了检测到异常值的概率与其误差幅度的函数关系,该误差幅度由实际距离dout与真实距离dGT之间的比值来衡量。 可以观察到,很可能检测到严重变形(挤压或或扩大)的边缘。 这也适用于更高的尺寸。

图11:离群率与收缩率的关系,离群值相对于真实值的扩大。 可能会检测到严重变形(挤压或扩大)的边缘。 请注意,X轴是对数的:log2(dout = dGT)。
嵌入评估。 获得有关嵌入的见解,X1,...,XN点的性能,我们使用以下得分:

然后,我们将Sij的平均值作为嵌入的分数。 该评分将缩小和扩大平均对待,低分意味着更好的嵌入。 评估结果显示在图12中。该图显示,当异常值的部分小于22%时,我们的预过滤要比直接应用SMACOF MDS更好。 大量的离群值会导致TMDS过滤掉太多的离群值,并削弱嵌入效果。

图12:SMACOF和TMDS之间的比较,作为离群率的函数。 高达22%的TMDS具有更好的性能
对数正态分布。 通过在d维超立方体中均匀采样N个数据点并形成相应的距离矩阵D,我们生成了模拟现实数据特征的合成数据。我们使用对数正态分布的因素使距离失真。 即,每个距离Dij乘以从对数正态分布采样的因子,其中对数正态均值是1。请注意,这些失真的距离包括噪声和离群值。 这些具有不同对数标准偏差sigma的模拟结果如图13所示。请注意,对于较大的sigma值(表示更大的误差),TMDS的有效性更为显着。

图13:在SMACOF和TMDS之间针对各种分布的比较,这些分布被定义为sigma的函数。
非均匀分布。我们进一步评估了非均匀结构数据的tmd。具有清晰结构的数据集的嵌入如图14所示。正如我们将在下面讨论的,tmd的一个限制是处理直线。
这在图14中很明显,我们的嵌入是不完美的(b),尽管比没有过滤要好(a)。在(c-d)中,结构化数据在数值上更易于过滤。结果表明,15%异常值数据的嵌入精度较高。

图14:嵌入了形状为“ PLUS”的数据集(上排),其具有10%的离群值,并且嵌入了形状为“ SPIRAL”的数据集(下排),其具有15%的离群值。 每个嵌入点都连接到其地面真点
4.3 Limitations
如前所述,我们的算法由两部分组成-建立残破三角形的直方图和设置阈值。 每个部分都有其自身的局限性。 直方图的分析假设离群点边缘打破了许多三角形,而离群点则没有。 当大量三角形也被内在距离打破时,这种假设可能不成立。当Dij = Dik + Dkj时可能会发生这种情况,但由于数值问题Dij> Dik + Dkj,例如当许多点沿直线存在时 。 设置阈值Phi只是一种启发式方法,当异常值太多时,或者只有很少的具有特殊分布的启发式方法会混淆启发式方法,并导致一半的数据被视为异常值时,启发式方法可能会失败。
5 E
XPERIMENTS
在前面的部分中,我们已经使用了具有地面真实距离的合成数据来测试和评估了我们的方法(TMDS)。 我们已经证明,Forero和Giannakis [6]的MDS技术对初始猜测很敏感,其性能取决于用户选择的参数。
在下文中,我们将根据无法获得基本事实的数据评估我们的方法。 为了评估性能,我们比较了TMDS和使用MDS的SMACOF实现的MDS
带有地面真相标签而不是距离的常见度量。 标签仅用于评估。
首先,我们在网络上可用的两个真实数据集上测试TMDS,对于这些数据集,地面真实距离是可用的。 接下来,我们在三个数据集上评估TMDS,这三个数据集的地面真实距离不可用,但是存在类标签。
SGB128数据集该数据集由北美128个城市的位置组成[20]。 我们计算城市之间的距离,并引入15%的离群值。 图15显示了实际位置,通过SMACOF在异常数据上的嵌入以及应用我们的滤波技术后的SMACOF结果。 可以看出,在计算嵌入之前应用过滤会产生巨大的进步。

图15:具有10%离群值的SGB128距离的二维嵌入。 绿点是地面位置,品红色点代表嵌入点??
蛋白质数据集该数据集由一个邻近矩阵组成,该邻近矩阵来自213个蛋白质序列的结构比较[21],[22]。这些相异度值不构成度量。 这些蛋白质中的每一种都与以下四类之一相关:血红蛋白(HA),血红蛋白(HB),肌红蛋白(M)和异质球蛋白(G)。 我们在使用SMACOF的情况下使用和不使用过滤器来嵌入差异,然后执行k-均值聚类并根据地面真实性类评估聚类。 结果如
图16所示。聚类结果使用四种常用度量进行评估:ARI,RI和MOC。 可以看出,通过所有措施,TMDS优于直接应用SMACOF。

图16:10次执行的平均簇索引值。 嵌入尺寸设置为6,因为对于较小的尺寸,SMACOF由于位于同一位置而失败。
6 G
RAPHICAL
D
ATASETS
在下面的,我们进行实验以显示强大的MDS对于图形元素可视化的有效性。具体来说,我们使用三个数据集,一种是从MPEG7数据集[23]和1070db [24]形状数据集中获取的2D形状之一,一种是运动数据(CMU运动捕获数据库
mocap.cs.cmu.edu),另一种是3D形状[ 25]。对于每个集合,我们使用适当的距离度量来生成所有对距离矩阵,然后通过使用SMACOF MDS和鲁棒的MDS嵌入元素来创建地图。更具体地说,我们使用内部距离测量2D形状之间的距离,使用LMA功能[26]测量序列之间的距离,使用SHED [27]测量3D形状之间的距离。
我们对定性进行了定性和定量评估。由于无法获得基本事实,因此我们使用已知的类进行评估。我们期望有一个很好的嵌入方式,将类划分为紧密的簇,尤其要避免它们之间的交叉。定性地,这可以在图17、18、20、22和21的SMACOF和TMDS嵌入的三个并排比较中观察到。要定量地测量它,我们使用两个常见的测度,即Silhouette Index [28]和Calinski Harabasz [29],它们分析了不同类别之间的分离程度。我们还使用通用措施来分析聚类技术对数据进行聚类的成功程度。我们应用K-means并使用AMI [30],NMI [31]以及完整性和同质性度量[32]来衡量其成功。如表2所示,在所有这些方面,我们的TMDS方法均优于SMACOF措施。

我们在所有实验中使用的差异性度量标准都不是度量标准,因此应该相应地理解异常值的含义。 在这种情况下,离群值的去除仅增加了距离以更好地符合度量。 但是,可以清楚地看到,在所有情况下,TMDS都会增强地图并更好地区分类别。 仍然可以从图20、21和22中观察到,在某些元素的嵌入程度与它们各自类别中的其余元素距离不够近的意义上,嵌入的结果不一定是完美的。 请注意,为完整起见,我们添加了使用Forero和Giannakis [6]方法获得的结果,为此我们将lambda设置为2。

图17:使用(a)SMACOF MDS和我们的稳健MDS(b)嵌入形状。 可以看出,使用我们的方法可以更好地分离四类形状。 正如我们将在第5节中详细说明的那样,轮廓度量在质量上也支持这一点。

图18:3D形状不相似矩阵的嵌入。 可以看出,使用TMDS可以更好地分离六种形状。表2也对此进行了定性支持。

图19:将三类运动数据嵌入到2D空间中。 请注意,蓝色数据点与左侧的绿色数据点(SMACOF)混合在一起,而右侧的分离度更好(TMDS)。
图20:从MPEG7数据集中嵌入六个类。 可以看出,TMDS修复了嵌入(注意绿色类),但是仍然不完善(注意蓝色公鸡)

图21:从1070db数据集中的10个类别(每个类别10个形状)中选择的100个随机形状的嵌入。 与SMACOF(注意橄榄色)和FG12(注意红色和黄色类)相比,TMDS改进了嵌入。 轮廓得分从0.14(SMACOF)和0.19(FG12)提高到0.27(TMDS)SMACOF

图22:嵌入1070db数据集中的三个类。 灰线表示被TMDS过滤的异常值(1847年为44;即2:3%)。 TMDS改进了品红色和蓝色类的嵌入。 红色圆圈表示的形状显然距离类不够近。 请注意,TMDS不能保证完美的嵌入。
7 D
ISTRIBUTION OF DISTANCES
在本节中,我们假设误差与距离的分布相同,试图分析三角形被错误边缘破坏的可能性。 因此,给定一个由p1,p2; p3形成的三角形;在d维单位超立方体中,我们应该学习三角形边缘距离的分布,以便于估计错误边缘打破三角形不等式的概率。
我们首先分析边缘长度的分布。
 是d维单位超立方体中的两个点,均匀地随机采样.
是d维单位超立方体中的两个点,均匀地随机采样.
距离
 具有正态分布,均值和方差分别为
具有正态分布,均值和方差分别为
 和7/120,并且随着d的增加,近似值会变得更好。 证明在[33]中提供。
和7/120,并且随着d的增加,近似值会变得更好。 证明在[33]中提供。
具有正态分布,均值和方差分别为
我们经验计算了Cov(D(p1,p2); D(p2, p3)),D(p1, p2)与D(p2, p3)之间的协方差,对于多个维度,发现其常数为 0.008。这使我们可以近似得出PD = D(p1, p2)+ D(p2, p3)和MD = D(p1, p2)- D(p2, p3),假设它们的分布是正态的:

这些正态分布显示在图23中的尺寸6,10和30中。可以注意到,对于较大的尺寸,近似值的精度会提高。
给定以上分布,我们现在准备估算三角形错误边缘破坏的可能性。

图23:D(p1,p2),PD和MD的近似正态分布分别显示在(a),(b)和(c)中。 绿色曲线代表近似值,蓝色,红色和橙色曲线分别代表为尺寸6、10和30的测得距离分布。 在(c)中,所有曲线都是相似的,因此我们仅显示6D曲线。
定理1。p1, p2, p3是在d维单位超立方体中均匀随机且独立采样的三个点。 给定上述距离分布,令边缘(p1, p3)为离群距离,即三角形p1,p2 p3被打破的概率是

Phi代表标准正态累积分布函数
假设D(p1,p3)和D(p1,p2)以及D(p1,p3)和D(p2,p3)是独立的,则如果满足以下不等式之一,三角形将断开:

然后,这些独立案例的概率为:

从而,三角形由于离群边缘而破裂的概率就是它们的和:

请注意,离群点的行为类似于常见距离(即相同的分布)的假设使它的检测更加困难。尽管如此,如上所示,离群点会破坏大量三角形。 例如,假设三角形是独立的,且d = 2,则与异常边缘关联的三角形中有24%被破坏。 该数字已通过我们的经验验证以上评估。 另外,请注意,u是d的函数,因此,随着维数d的增加,u也会增加,并且上述概率也随之减小。
8 C
ONCLUSIONS
我们提出了一种在应用MDS之前对距离进行过滤的技术,因此它对于异常值更加健壮。该技术分析了由三个点组成的三角形及其成对的距离,并将距离与断开的三角形相关联。并非每个离群值都与一个断开的三角形相关联,并且与该断开的三角形相关联的边并非一定是一个离群值。因此,期望产生假阳性和假阴性。但是,正如我们所展示的,只要异常边缘的部分是合理的(即20%),则误报是无损的,并且嵌入的质量很高。最值得注意的是,当异常值的数量特别少时(如在合理的实际场景中),我们的技术准确性特别高,并且与直接MDS相比有了明显的改进。我们还表明,即使没有明显的异常值,我们的技术也可以在应用MDS之前先提取数据。
在我们的工作中,我们专注于欧几里得度量,但是,该技术也可以应用于其他度量。例如,在心理学和市场营销中,通常使用Minkowsky距离族[34],[35]:
 其中,p>1
其中,p>1
除了将其推广到其他指标之外,我们的技术还适用于常规嵌入,而不仅限于特定的应力函数或MDS算法。 只要嵌入方法不需要完整的不相似矩阵,我们的方法就是可行的。 我们想强调一下,我们的方法没有参数。 阈值Phi使用 |E|/2 的值,该值不受参数限制。 然而,可以用反映预期的异常值数量的参数来定义Phi,以改进方法的准确性,即产生较少的假阳性。
