之前朋友圈无意刷到比较关注的人发了一条什么找人帮忙追女孩子也不能找李子维,作为程序猿(舔狗)看了一脸懵逼,从来不怎么看剧的我然后就去百度了一下,原来是想见你。然后就去腾讯视频看了一下,额不是我喜欢看的类型,不过还是想做点什么,那就分析一下弹幕吧。
以后真的要改掉拖延症,其实两天前我就应该写这个博客的,拖了两天。。。结果现在去翻朋友圈,三天可见,无朋友圈截图
爬取弹幕
由于不是VIP,第一件事就是打开一集然后等着45s的广告。。。
然后找到了弹幕的链接网址
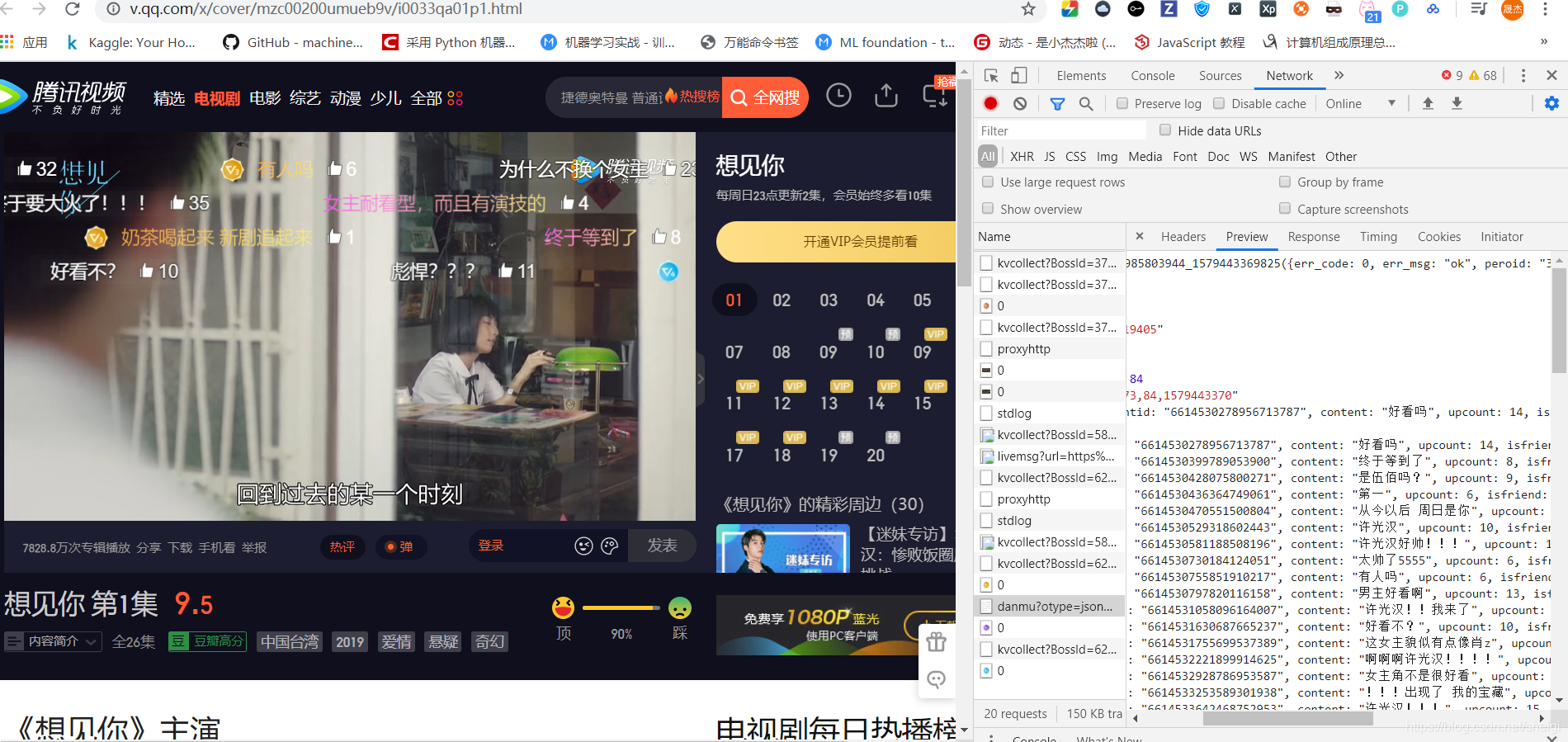
https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910014051953985803944_1579443369825&target_id=4576819405%26vid%3Di0033qa01p1&session_key=23873%2C84%2C1579443370×tamp=75&_=1579443369830
然后多看几集多找几个弹幕链接,发现主要改变的就是target_id和timestamp,然后简化链接,最终实验出了只要target_id和timestamp的url。
# 'https://mfm.video.qq.com/danmu?otype=json×tamp=2385&target_id=4576819404%26vid%3Du0033tu6jy5&count=80'#无数据
# #最后一页1995=133*15
# '2385'
#最后就是
#https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id={}%26vid%3D{}&count=400&second_count=5
下面这是我找的一段记录
# #第一集
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087666001&target_id=4576819405%26vid%3Di0033qa01p1&session_key=19564%2C70%2C1579087668×tamp=135&_=1579087666006'
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087666001&target_id=4576819405%26vid%3Di0033qa01p1&session_key=19564%2C70%2C1579087668×tamp=165&_=1579087666007'
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087666001&target_id=4576819405%26vid%3Di0033qa01p1&session_key=19564%2C70%2C1579087668×tamp=195&_=1579087666008'
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087666001&target_id=4576819405%26vid%3Di0033qa01p1&session_key=19564%2C70%2C1579087668×tamp=225&_=1579087666009'
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087666001&target_id=4576819405%26vid%3Di0033qa01p1&session_key=19564%2C70%2C1579087668×tamp=255&_=1579087666010'
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087666001&target_id=4576819405%26vid%3Di0033qa01p1&session_key=19572%2C70%2C1579088455×tamp=2115&_=1579087666018'
#
# #第二集
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087665999&target_id=4576819403%26vid%3Dw0033mb4upm&session_key=17967%2C94%2C1579088496×tamp=105&_=1579087666034'
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910975216511090891_1579087665999&target_id=4576819403%26vid%3Dw0033mb4upm&session_key=17967%2C94%2C1579088496×tamp=135&_=1579087666035'
# '''callback: jQuery1910975216511090891_1579087665999
# target_id: 4576819403&vid=w0033mb4upm
# session_key: 17967,94,1579088496'''
#
#
# '''Request URL: https://tunnel.video.qq.com/fcgi/danmu_read_count?ddwTargetId=4576819404%26vid%3Du0033tu6jy5&ddwUin=0&dwGetTotal=1&wOnlyTotalCount=0&strSessionKey=&dwGetPubCount=1&raw=1&vappid=29188582&vsecret=37ae5f4003c9a2332e566d8c53bf32b0d4ddfa4ac6717cd1'''
# '''ddwTargetId: 4576819404&vid=u0033tu6jy5
# ddwUin: 0
# dwGetTotal: 1
# wOnlyTotalCount: 0
# strSessionKey:
# dwGetPubCount: 1
# raw: 1
# vappid: 29188582
# vsecret: 37ae5f4003c9a2332e566d8c53bf32b0d4ddfa4ac6717cd1'''
#
#
# '''ddwTargetId: 4576819404
# ddwUin: 0
# dwUpCount: 1
# ddwUpUin: 0
# dwTotalCount: 16924
# stLastComment: {ddwTargetId: 0, ddwUin: 0, dwIsFriend: 0, dwIsOp: 0, dwIsSelf: 0, dwTimePoint: 0, dwUpCount: 0,…}
# ddwTargetId: 0
# ddwUin: 0
# dwIsFriend: 0
# dwIsOp: 0
# dwIsSelf: 0
# dwTimePoint: 0
# dwUpCount: 0
# ddwPostTime: 0
# dwHlwLevel: 0
# dwRichType: 0
# dwDanmuContentType: 0
# dwTimeInterval: 59
# strSessionKey: "59,16924,1579088736"
# dwMaxUpNum: 133
# dwPubCount: 13190'''
#
# 'https://mfm.video.qq.com/danmu?otype=json×tamp=45&target_id=4576819404%26vid%3Du0033tu6jy5&count=80'
#
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109959296720329007_1579088733741&target_id=4576819404%26vid%3Du0033tu6jy5&session_key=0%2C0%2C0×tamp=15&_=1579088733743'
# 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109959296720329007_1579088733741&target_id=4576819404%26vid%3Du0033tu6jy5&_=1579088733743'
#
# 'https://mfm.video.qq.com/danmu?otype=json×tamp=2385&target_id=4576819404%26vid%3Du0033tu6jy5&count=80'#无数据
# #最后一页1995=133*15
# '2385'
#
#
# 'https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1'
# 'https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1'
# '''{wRegistType: 2, vecIdList: ["h00336e2bmu"], wSpeSource: 0, bIsGetUserCfg: 1,…}
# wRegistType: 2
# vecIdList: ["h00336e2bmu"]
# 0: "h00336e2bmu"
# wSpeSource: 0
# bIsGetUserCfg: 1
# mapExtData: {h00336e2bmu: {strCid: "mzc00200umueb9v", strLid: ""}}
# h00336e2bmu: {strCid: "mzc00200umueb9v", strLid: ""}
# strCid: "mzc00200umueb9v"
# strLid: ""'''
然后就是要找到每一集对应的target_id和v_id才能得到每一集的弹幕,所以再去找找哪里有那些target_id和v_id。
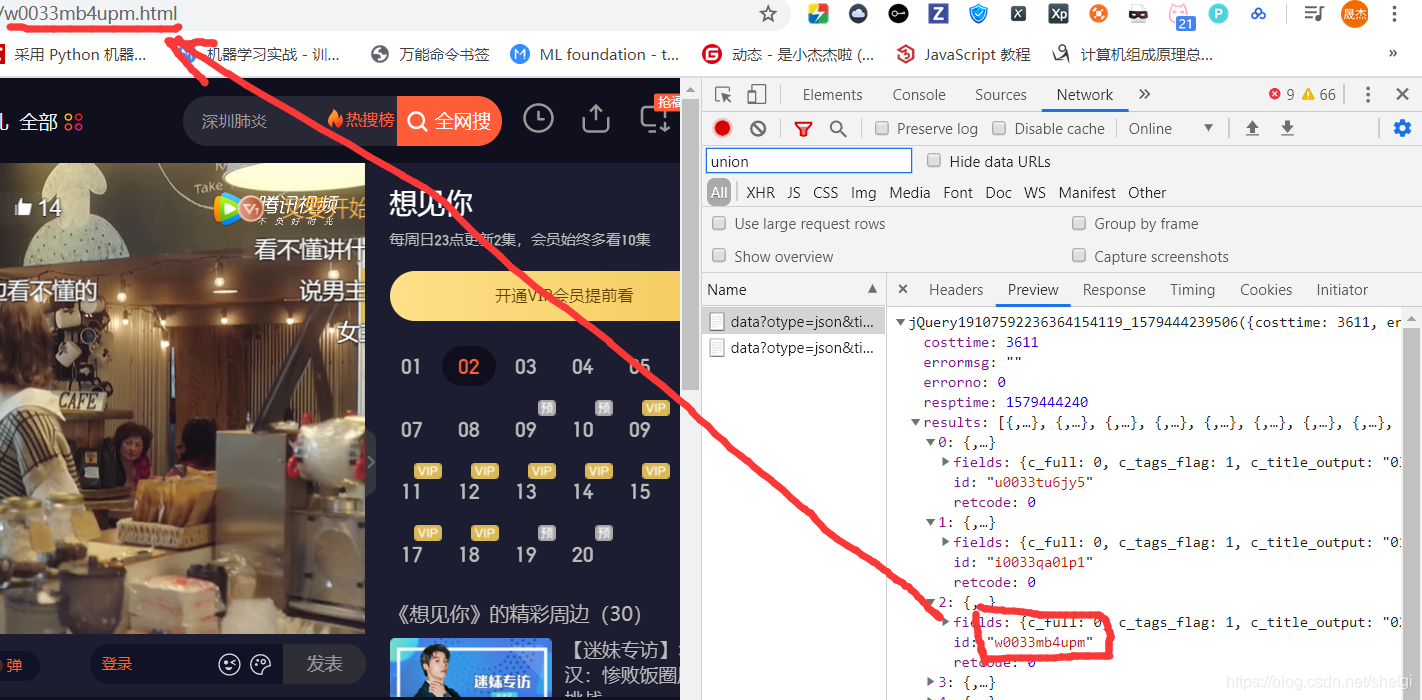
这里就得到了v_id,然后再去通过v_id,post得到target_id
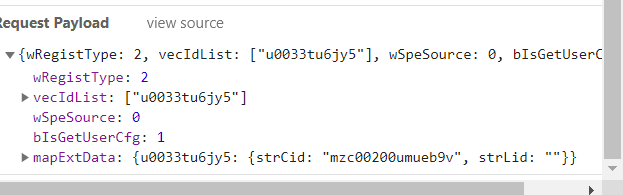
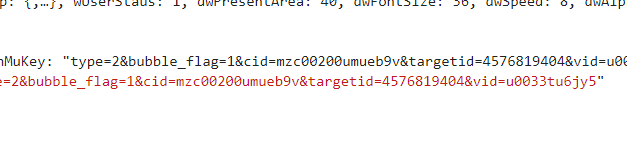
大概思路就是这样,到处找我们想要的最后得到就行。
之前也看到了别人写的爬取腾讯视频弹幕的代码,不过链接忘了,我在这个基础上改成了我需要的,上爬虫代码:
import requests
import json
import pandas as pd
import time
import random
# 页面基本信息解析,获取构成弹幕网址所需的后缀ID、播放量、集数等信息。
def parse_base_info(url, headers):
df = pd.DataFrame()
html = requests.get(url, headers=headers)
bs = json.loads(html.text[html.text.find('{'):-1])
for i in bs['results']:
v_id = i['id']
title = i['fields']['title']
view_count = i['fields']['view_all_count']
episode = int(i['fields']['episode'])
if episode == 0:
pass
else:
cache = pd.DataFrame({'id': [v_id], 'title': [title], '播放量': [view_count], '第几集': [episode]})
df = pd.concat([df, cache])
return df
# 传入后缀ID,获取该集的target_id并返回
def get_episode_danmu(v_id, headers):
base_url = 'https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1'
pay = {"wRegistType": 2, "vecIdList": [v_id],
"wSpeSource": 0, "bIsGetUserCfg": 1,
"mapExtData": {v_id: {"strCid": "mzc00200umueb9v", "strLid": ""}}}
html = requests.post(base_url, data=json.dumps(pay), headers=headers)
bs = json.loads(html.text)
danmu_key = bs['data']['stMap'][v_id]['strDanMuKey']
target_id = danmu_key[danmu_key.find('targetid') + 9: danmu_key.find('vid') - 1]
return [v_id, target_id]
# 解析单个弹幕页面,需传入target_id,v_id(后缀ID)和集数(方便匹配),返回具体的弹幕信息
def parse_danmu(url, target_id, v_id, headers, period):
html = requests.get(url, headers=headers)
bs = json.loads(html.text, strict=False)
df = pd.DataFrame()
try:
for i in bs['comments']:
content = i['content']
name = i['opername']
upcount = i['upcount']
user_degree = i['uservip_degree']
timepoint = i['timepoint']
comment_id = i['commentid']
cache = pd.DataFrame({'用户名': [name], '内容': [content], '会员等级': [user_degree],
'弹幕时间点': [timepoint], '弹幕点赞': [upcount], '弹幕id': [comment_id], '集数': [period]})
df = pd.concat([df, cache])
except:
pass
return df
# 构造单集弹幕的循环网页,传入target_id和后缀ID(v_id),通过设置爬取页数来改变timestamp的值完成翻页操作
def format_url(target_id, v_id, page=85):
urls = []
base_url = 'https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id={}%26vid%3D{}&count=400&second_count=5'
for num in range(15, page * 30 + 15, 30):
url = base_url.format(num, target_id, v_id)
urls.append(url)
#print(urls)
return urls
def get_all_ids(part1_url,part2_url, headers):
part_1 = parse_base_info(part1_url, headers)
part_2 = parse_base_info(part2_url, headers)
df = pd.concat([part_1, part_2])
df.sort_values('第几集', ascending=True, inplace=True)
count = 1
# 创建一个列表存储target_id
info_lst = []
for i in df['id']:
info = get_episode_danmu(i, headers)
info_lst.append(info)
print('正在努力爬取第 %d 集的target_id' % count)
count += 1
time.sleep(2 + random.random())
print('是不是发现多了一集?别担心,会去重的')
# 根据后缀ID,将target_id和后缀ID所在的表合并
info_lst = pd.DataFrame(info_lst)
info_lst.columns = ['v_id', 'target_id']
combine = pd.merge(df, info_lst, left_on='id', right_on='v_id', how='inner')
# 去重复值
combine = combine.loc[combine.duplicated('id') == False, :]
return combine
# 输入包含v_id,target_id的表,并传入想要爬取多少集
def crawl_all(combine, num, page, headers):
c = 1
final_result = pd.DataFrame()
for v_id, target_id in zip(combine['v_id'][:num], combine['target_id'][:num]):
count = 1
urls = format_url(target_id, v_id, page)
for url in urls:
result = parse_danmu(url, target_id, v_id, headers, c)
final_result = pd.concat([final_result, result])
time.sleep(2 + random.random())
print('这是 %d 集的第 %d 页爬取..' % (c, count))
count += 1
print('-------------------------------------')
c += 1
return final_result
if __name__ == '__main__':
part1_url = 'https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=x00335pmni4,u0033s6w87l,a0033ocq64d,z0033hacdb0,k30411thjyx,x00330kt2my,o0033xvtciz,r0033i8nwq5,q0033f4fhz2,a3033heyf4t,p0033giby5x,g0033iiwrkz,m0033hmbk3e,a0033m43iq4,o003381p611,c00339y0zzt,w0033ij5l6r,d0033mc7glb,k003314qjhw,x0033adrr32,h0033oqojcq,a00335xx2ud,t0033osrtb7&callback=jQuery191022356914493548485_1579090019078&_=1579090019082'
part2_url = 'https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=t00332is4j6,i0033qa01p1,w0033mb4upm,u0033tu6jy5,v0033x5trub,h00336e2bmu,t00332is4j6,v0033l43n4x,s0033vhz5f6,u003325xf5p,n0033a2n6sl,s00339e7vqp,p0033je4tzi,y0033a6tibn,x00333vph31,v0033d7uaui,g0033a8ii9x,e0033hhaljd,g00331f53yk,m00330w5o8v,o00336lt4vb,l0033sko92l,g00337s3skh,j30495nlv60,m3047vci34u,j3048fxjevm,q0033a3kldj,y0033k978fd,a0033xrwikg,q0033d9y0jt&callback=jQuery191022356914493548485_1579090019080&_=1579090019081'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 得到所有的后缀ID,基于后缀ID爬取target_id
combine = get_all_ids(part1_url,part2_url, headers)
# 设置要爬取多少集(num参数),每一集爬取多少页弹幕(1-85页,page参数)
# 比如想要爬取30集,每一集85页,num = 30,page = 85
final_result = crawl_all(combine, num=5, page=80, headers=headers)
final_result.to_excel('./想见你弹幕.xlsx')
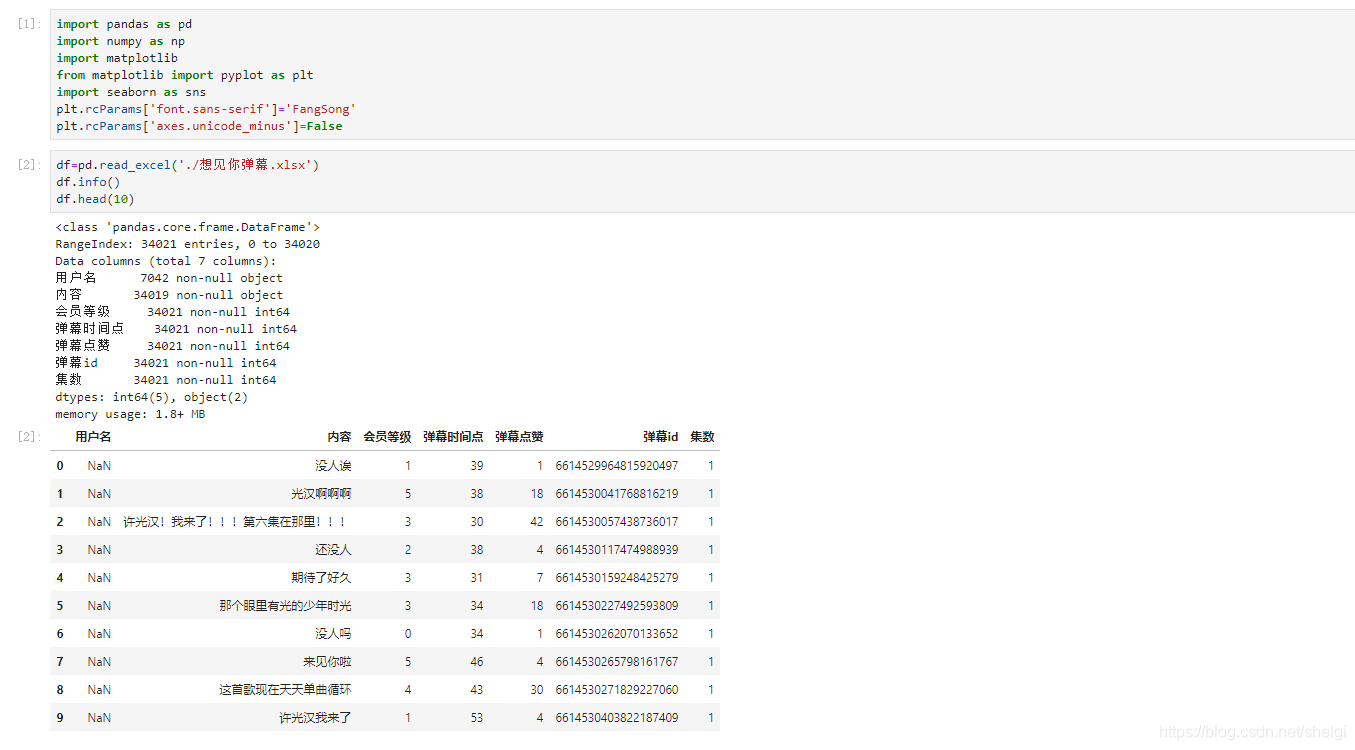
数据分析
爬取之后我们的弹幕是这个样子

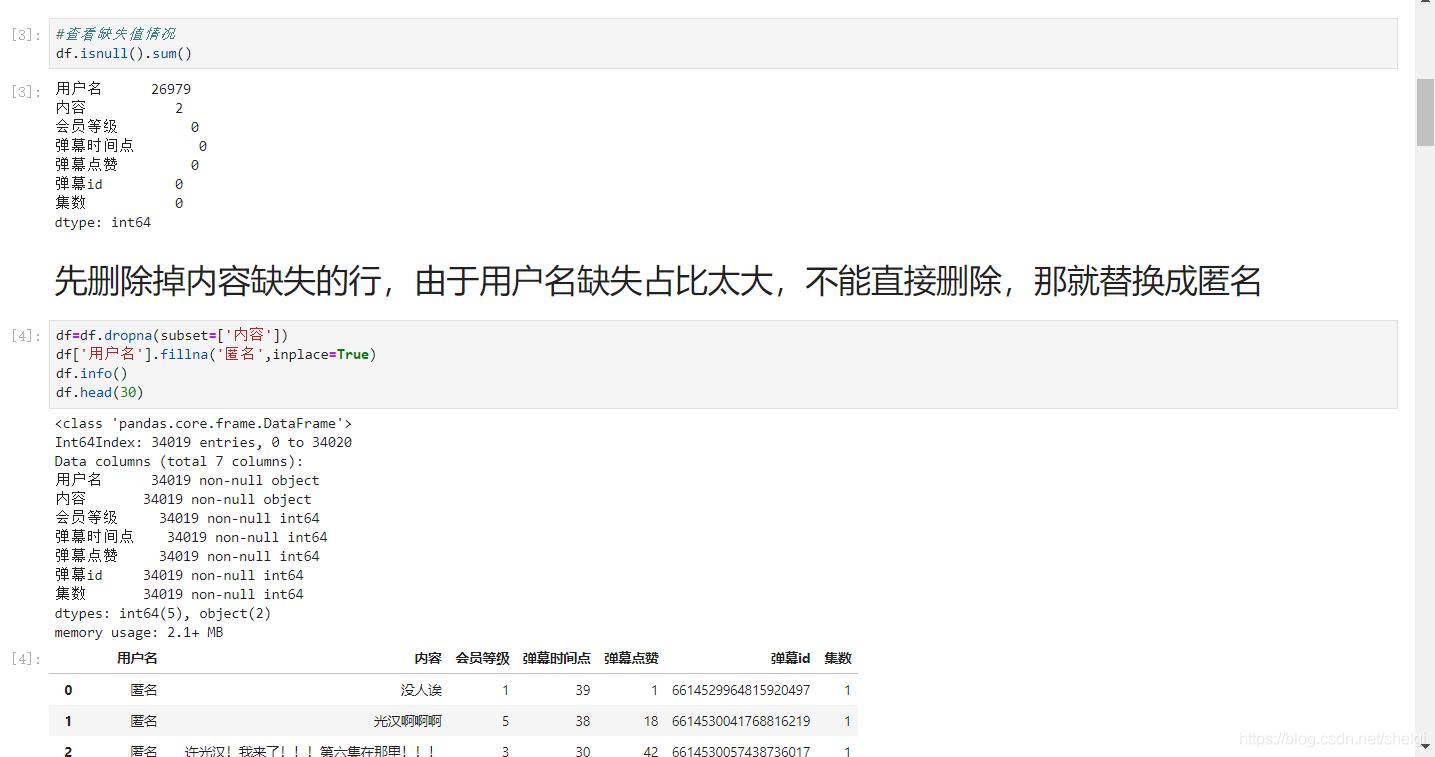
数据分析还是用我们pandas,一开始还是导入和数据清洗
然后看看谁发的弹幕最多(只考虑有用户名的用户)
#同一个人发了多少弹幕
dmby1=df.groupby('用户名')['弹幕id'].count().sort_values(ascending= False).reset_index()
dmby1.columns = ['用户名','累计发送弹幕数']
dmby1.head(20)

然后用一下上次的模板
#除去匿名者不考虑,对发弹幕数多的可视化
import matplotlib.patches as patches
fig, ax = plt.subplots(figsize=(25,16),dpi= 80)
ax.vlines(x=dmby1.index[1:50], ymin=0, ymax=dmby1.累计发送弹幕数[1:50], color='firebrick', alpha=0.7, linewidth=2)
ax.scatter(x=dmby1.index[1:50], y=dmby1.累计发送弹幕数[1:50], s=75, color='firebrick', alpha=0.7)
ax.set_title('每人发送弹幕数', fontdict={'size':22})
ax.set_ylabel('弹幕数')
ax.set_xticks(dmby1[1:50].index)
ax.set_xticklabels(dmby1.用户名[1:50].str.upper(), rotation=60, fontdict={'horizontalalignment': 'right', 'size':12})
ax.set_ylim(0, 200)
for row in dmby1[1:50].itertuples():
ax.text(row.Index, row.累计发送弹幕数+3.5, s=round(row.累计发送弹幕数, 2), horizontalalignment= 'center', verticalalignment='bottom', fontsize=14)
plt.show()
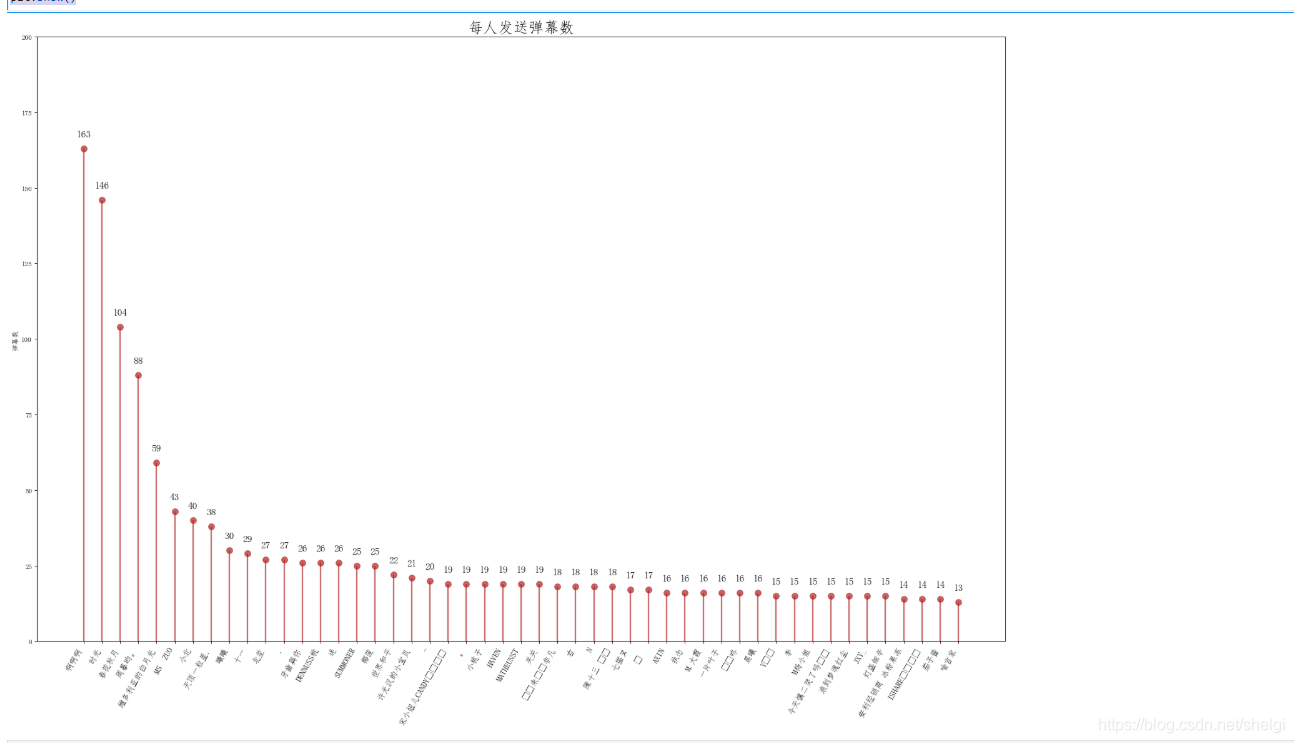
为了截图缩小了网页,原本很清楚的
然后看看每一集的弹幕数
#每一集有多少弹幕
dm=df.groupby('集数')['内容'].count().sort_values(ascending= False).reset_index()
dm.columns = ['集数','本集发送弹幕数']
dm['占比']=dm['本集发送弹幕数']/sum(dm['本集发送弹幕数'])
dm.head()
# 可视化
plt.pie(x =dm['占比'], labels=dm['集数'],autopct='%1.1f%%')
plt.title('各集弹幕占比')
plt.show()

因为当时爬虫代码设置的count=400,所以可能有遗漏,而且明显第三集爬取弹幕的时候出了问题。
然后做个词云
#词云
from wordcloud import WordCloud
import imageio
import jieba
df['内容']=df['内容'].astype(str)
word_list=" ".join(df['内容'])
word_list=" ".join(jieba.cut(word_list))
#设置词云
wc = WordCloud(
mask = imageio.imread('C:/Users/ysj/Pictures/卑微.jpg'),
max_words = 500,
font_path = 'C:/Windows/Fonts/simhei.ttf',
width=400,
height=860,
)
#生成词云
myword = wc.generate(word_list)
wc.to_file("./想见你词云.png")
#展示词云图
fig = plt.figure(dpi=80)
plt.imshow(myword)
plt.title('想见你词云')
plt.axis('off')
plt.show()

是因为vip发的弹幕前面会带vip吗?居然还会出现这个。。。
最后看看弹幕简单的情感分析
弹幕情感分析
from snownlp import SnowNLP
def sentiment(row):
content = str(row['内容']).strip()
s = SnowNLP(content)
score = float(s.sentiments)
return score
df['score'] = df.apply(sentiment, axis = 1)
df1 = df.groupby(['弹幕时间点'],as_index=False)['score'].mean()
df1.head()
fig = plt.figure(figsize=(10, 4.5))
plt.plot(df1[0:60],lw=2)
plt.title("弹幕情感趋势")
plt.xlabel("时间")
plt.ylabel("分数")
plt.ylim(0,1)
plt.axhline(0.5, color='orange')
plt.show()
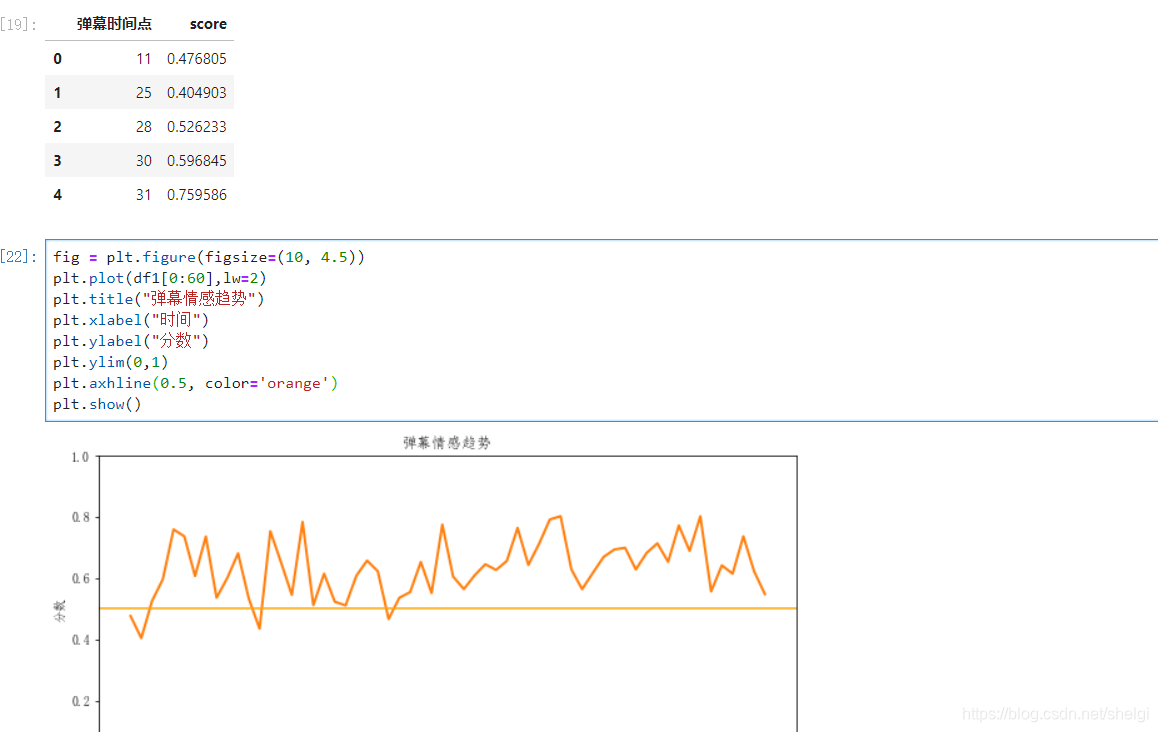
大部分都是比较正面的评价,而且往往评价高的时间点都在15分钟—35分钟之间,可能是这段时间正式进入剧情吧。
最后
其实刚刚在写这篇博客之前我看了爱情公寓5的13集,这一集真的很有意思,弹幕的作用可以让我们看剧的同时发表分享一下自己的想法,但是尽量还是做个文明的看客,看到有的弹幕无脑黑真的很不好,就像很多人喷爱情公寓抄袭之类的,但是好歹也陪伴了我们十年。其实很多剧都是投入了大量的心血的,很多会中途夭折,比如康斯坦丁,我是比较喜欢这类恐怖灵异剧的,很可惜只有一季。还有已经完结的基本演绎法、最后一季的邪恶力量,有的时候这些剧就像朋友陪伴着我们,尽量包容吧被喷的感觉实在不爽。这几天会去研究一下爱奇艺的弹幕,看看爱情公寓5的弹幕会是什么样子的。
