Manacher算法-马拉车(麻雀)
字符串回文
这个算法。和原先学习的KMP都是处理字符串的。只不过麻雀是专门针对回文串的。我是最近CF补题的时候碰到这个算法的。特此记录一下。说实话。原先学数据结构的时候学的KMP。现在应该完全忘光了把。。啊哈哈。明天再补补。
举个例子:
回文串分为奇回文和偶回文。奇回文的中心是中间的字符。偶回文的中心是两个字符中间的位置。不好同一处理。
所以我们加如下操作。比如aabbaa
增加为#a#a#b#b#a#a#
这样不管是奇回文还是偶回文都是字符啦。偶回文是#。奇回文还是原来的。
我们用数组p[]保存当前下标index作为中心时的回文序列长度半径。
所以我们以当前下标index为中心的回文串的最长长度就是p[i] - 1(这个地方不证明了。自己随便举几个例子就明白了)
mx记录当前已操作序列的最右的回文边界。就是最长的回文序列的最右边的地方。
id记录最长回文序列的中心位置。
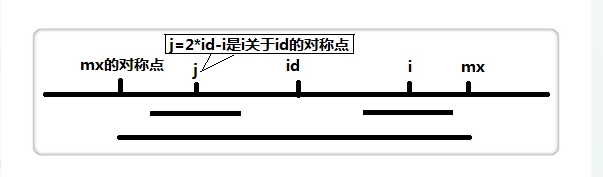
当我们遍历到i时。求p[i]
我们找到i的对称点j。这个地方的下标很简单求出来。(id - (i - id))即可
如图所示mx的对称点也标出来了。上面解释了。mx是最优边界。id是最长回文串的中心。
p[j]我们已经求出来了。
本算法的核心代码:

上面的p[2*id - i]就是p[j];
我们讨论一下p[j]的大小。
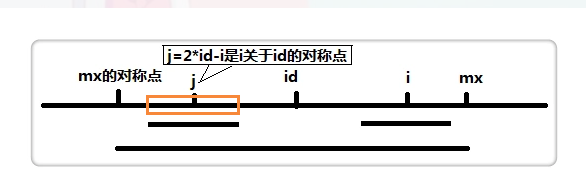
如果p[j]的回文串只有这么长。
也就是没有大于mx - i的长度
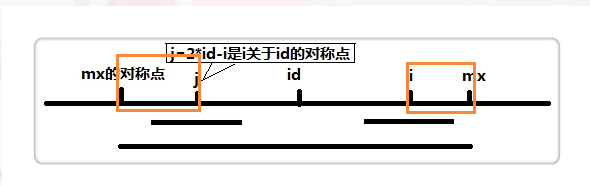
图中标记的橙色部分相等。。这个简单。
也就是以j为中心得回文串没有超过这个长度。
因为对称。所以此时我们赋值p[i] = p[j];这个是此时p[i]的最小长度。就在这个地方节约时间的。
至于p[i]的值有没有可能更长。我们后面暴力跑一遍就行。
如果p[j]的回文串大于了这个长度。
也就是这样:
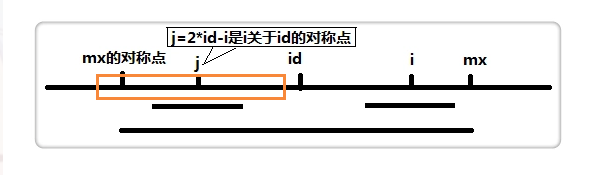
已经超过了mx的对称点的长度。
那我们只能将p[i]赋值为mx - i
因为这个mx - i是我们现在已知的最小长度。
因为mx对称点左边的字符和mx右边的字符不等呀。不然mx肯定不在当前位置了。。
之后我们暴力跑一遍判断即可。
我当时在想为啥这两部分的p[]是一一对称的。

傻坐在那想了半天。。
后来举了个例子画了个图就知道了。
因为mx和mx对称点范围内就是我们求得最长回文呀。id左边和id右边肯定是一一对称的呀。。。害~
上面解释完了就应该很好理解了。
然后我们在制作新的字符串的时候注意边界位置。
第一个字符初始化为$
最后一个字符就是结束标志’\0’就行。避免溢出。
时间复杂度控制在O(N)范围
棒~
模板代码:
我最后输出的是最长的回文串的长度。
#include <bits/stdc++.h>
using namespace std;
const int N = 2e7 + 10;
string s;
char ss[N];
int p[N];
int Init()//形成新的字符串
{
int n = s.size();
ss[0] = '$';//边界处理
ss[1] = '#';
int i = 2;
for (int j = 0; j < n; j++)
{
ss[i++] = s[j];
ss[i++] = '#';
}
ss[i] = '\0';
return i;
}
int Manacher()
{
int len = Init();
int maxx = -1;//最长回文串长度
int id = 1;
int mx = 0;
for (int i = 1; i <= len; i++)
{
if (i < mx)
{
p[i] = min(p[2 * id - i], mx - i);
}
else
{
p[i] = 1;
}
while (ss[i - p[i]] == ss[i + p[i]])
{
p[i]++;
}
if (mx < i + p[i])
{
id = i;
mx = i + p[i];
}
maxx = max(maxx, p[i] - 1);
}
return maxx;
}
int main()
{
cin >> s;
cout << Manacher() << endl;
return 0;
}
