最近关注到了这篇论文,发现这篇论文挺有意思的。因此在这里按我的理解说说这篇论文。这里不做论文完整的翻译。
GCNet 网络结构结构了non-local network和Squeeze-excitation networks.我们知道non-local network(NLNet)可以捕获长距离依赖关系。可以发现NLnet的网络结构采用的是自注意力机制来建模像素对关系。在这篇文章中non-local network的全局上下文在不同位置几乎是相同的,这表明学习到了无位置依赖的全局上下文,因此这样导致了大量的计算量的浪费。作者在这里提出了一种简化版的模型去获得全局上下文信息。使用的是query-independent(可以理解为无query依赖)的建模方式。同时更可以共享这个简化的结构和SENet网络结构。因此作者在这里联合了这三种方法产生了一个global context(GC) block

在这里我们可以可以看到一个个简化版的NL block 和完整的NLblock
NL block 可以表述为
为位置的索引,
枚举所有可能的位置。
表示位置
和
的关系,
为归一化因子。
和
表示线性转换矩阵(例如1x1卷积)。为了简单起见,定义
为位置
和
的归一化关系。本文中将
表示为Embedded Gaussian的形式,定义为

作者从COCO数据集中随机选择6幅图,分别可视化3个不同位置和它们的attention maps。作者发现对于不同位置来说,它们的attention maps几乎是相同的。作者通过分析不同位置全局上下文的距离,进一步证明了这一点。换句话说,虽然non-local block想要计算出每一个位置特定的全局上下文,但是经过训练之后,全局上下文是不受位置依赖的。
同时作者也利用了SENet网络
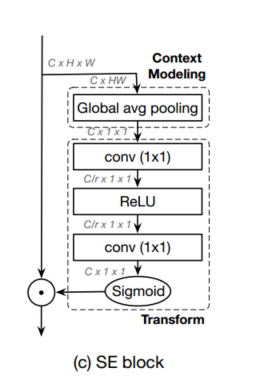
最后得到了一个全新的GCnet 模块

最后这个新的block 可以更好的分析模型的上下文信息。
最近我在进行语义分割时 准备把non-lock 网络也加入到分割中,发现我两个12G的显卡都爆了。由于我进行分割的图片大小为512*512.当进行分割时最后一步按照non-lock的操作。最后得到的矩阵大小是512*512 * 512*512 还要加上batchsize 最后导致内存爆了。当时我就对non_lock 网络进行了简单的更改。最后得到的分割结果也是比较理想的。当时我就想着对于non_lock 网络进行一些简化操作。没想到看到这个论文,发现作者比我更狠,简化了这么多。这样也同时给我了一个思路。又重新对于网络进行了更改。
