《Squeeze-and-Excitation Networks(SENet)》
其他
2018-11-24 12:44:28
阅读次数: 0
卷积神经网络已被证明是解决各种视觉任务的有效模型。对于每个卷积层,沿着输入通道学习一组滤波器来表达局部空间连接模式。
换句话说,期望卷积滤波器通过融合空间信息和信道信息进行信息组合,而受限于局部感受野。通过叠加一系列非线性和下采样交织的卷积层,CNN能够捕获具有全局感受野的分层模式作为强大的图像描述。
最近的工作已经证明,网络的性能可以通过显式地嵌入学习机制来改善,这种学习机制有助于捕捉空间相关性而不需要额外的监督。Inception架构推广了一种这样的方法,这表明网络可以通过在其模块中嵌入多尺度处理来取得有竞争力的准确度。最近的工作在寻找更好地模型空间依赖,结合空间注意力。
与这些方法相反,通过引入新的架构单元,我们称之为*“Squeeze-and-Excitation”* (SE)块,我们研究了架构设计的一个不同方向——通道关系。我们的目标是通过显式地建模卷积特征通道之间的相互依赖性来提高网络的表示能力。为了达到这个目的,我们提出了一种机制,使网络能够执行特征重新校准 ,通过这种机制可以学习使用全局信息来选择性地强调信息特征并抑制不太有用的特征;
Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡。
SENets是我们ILSVRC 2017分类提交的基础,它赢得了第一名,并将top-5错误率显著减少到2.251%2.251%,相对于2016年的获胜成绩取得了∼25%∼25%的相对改进
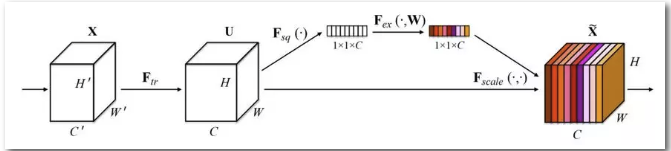
SENet是基于特征通道之间的关系提出的,下图是SENet的Block单元,图中的Ftr是传统的卷积结构,X和U是Ftr的输入和输出,这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(称为Squeeze过程),输出是一个1x1xC的数据,再经过两级全连接(称为Excitation过程),最后用sigmoid把输出限制到[0,1]的范围,把这个值作为scale再乘到U的C个通道上,作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
下图是把SENet模型分别用于Inception网络和ResNet网络,下图左边部分是原始网络,右边部分是加了SENet之后的网络,分别变成SE-Inception和SE-ResNet。网络中的r是压缩参数,先通过第一个全连接层把1x1xC的数据压缩为1x1xC/r,再通过第二个全连接层把数据扩展到1x1xC。
转载自 blog.csdn.net/u010067397/article/details/84427614