0、摘要
卷积神经网络建立在卷积运算的基础上,通过融合局部感受野内的空间信息和通道信息来提取信息特征。为了提高网络的表示能力,许多现有的工作已经显示出增强空间编码的好处。在这项工作中,我们专注于通道,并提出了一种新颖的架构单元,我们称之为“Squeeze-and-Excitation”(SE)块,通过显式地建模通道之间的相互依赖关系,自适应地重新校准通道式的特征响应。通过将这些块堆叠在一起,我们证明了我们可以构建SENet架构,在具有挑战性的数据集中可以进行泛化地非常好。关键的是,我们发现SE块以微小的计算成本为现有的最先进的深层架构产生了显著的性能改进。SENets是我们ILSVRC 2017分类提交的基础,它赢得了第一名,并将top-5错误率显著减少到 2.251 % 2.251 \% 2.251%,相对于2016年的获胜成绩取得了 ∼ 25 % \sim25\% ∼25%的相对改进。
1、概要
论文的动机是从特征通道之间的关系入手,希望显式地建模特征通道之间的相互依赖关系。另外,没有引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的“特征重标定”策略。
SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去增强有用的特征并抑制对当前任务用处不大的特征,通俗来讲,就是让网络利用全局信息有选择的增强有益feature通道并抑制无用feature通道,从而能实现feature通道自适应校准。
也许通过给某一层特征配备权重的想法很多人都有,那为什么只有SENet成功了?个人认为主要原因在于权重具体怎么训练得到。就像有些是直接根据feature map的数值分布来判断;有些可能也利用了loss来指导权重的训练,不过全局信息该怎么获取和利用也是因人而异。
当然,SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的。
Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。
作者在文中将SENet block插入到现有的多种分类网络中,都取得了不错的效果。作者采用SENet block和ResNeXt结合在ILSVRC 2017的分类项目中拿到第一,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。
2、方法概述
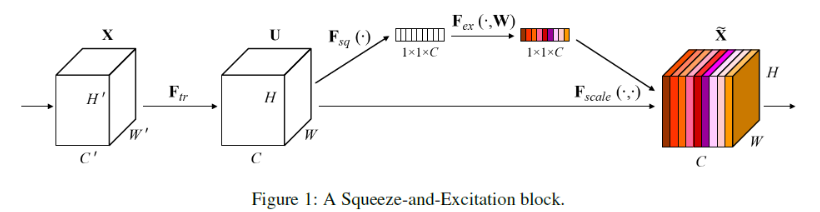
图1是SENet的Block单元,
F t r F_{tr} Ftr操作
图中的 F t r F_{tr} Ftr是传统的卷积结构, X X X和 U U U是 F t r F_{tr} Ftr的输入 ( C ′ × H ′ × W ′ ) (C'\times H'\times W') (C′×H′×W′)和输出 ( C × H × W ) (C\times H\times W) (C×H×W),这些都是以往结构中已存在的。
u c = v c ∗ X = ∑ s = 1 C ′ v c s ∗ x s \mathbf{u}_{c}=\mathbf{v}_{c} * \mathbf{X}=\sum_{s=1}^{C^{\prime}} \mathbf{v}_{c}^{s} * \mathbf{x}^{s} uc=vc∗X=s=1∑C′vcs∗xs
这里这篇文章提出一个说法:因为卷积后的结果是输入矩阵不同通道计算结果的加和,通道间的相关性会被嵌入在卷积核 V c V_c Vc的训练之后的结果中,但是同时呢,通道间的这些依赖性与滤波器捕获的空间相关性纠缠在一起。本文的目标就是:确保网络能够提高其对信息特征的敏感性,以便后续的转换可以利用这些特征,并抑制不太有用的特征。所以通过显式地建模通道相关性来实现这一点。


Squeeze(挤压/ F s q F_{sq} Fsq操作)
SENet增加的部分是 U U U后的结构:对 U U U先做一个Global Average Pooling(图中的 F s q ( ⋅ ) F_{sq}(\cdot) Fsq(⋅),作者称为Squeeze即为压缩过程)
公式
z c = F s q ( u c ) = 1 W × H ∑ i = 1 W ∑ j = 1 H u c ( i , j ) (1) z_{c}=\mathbf{F}_{s q}\left(\mathbf{u}_{c}\right)=\frac{1}{W \times H} \sum_{i=1}^{W} \sum_{j=1}^{H} u_{c}(i, j) \tag{1} zc=Fsq(uc)=W×H1i=1∑Wj=1∑Huc(i,j)(1)
Excitation(激励/ F e x F_{ex} Fex操作)
输出的 1 × 1 × C 1 \times 1 \times C 1×1×C 数据再经过两级全连接(图中的 F e x ( ⋅ ) F_{ex}(\cdot) Fex(⋅),作者称为Excitation,即为激发过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围
s = F e x ( z , W ) = σ ( g ( z , W ) ) = σ ( W 2 δ ( W 1 z ) ) \mathrm{s}=\mathrm{F}_{e x}(\mathrm{z}, \mathrm{W})=\sigma(g(\mathrm{z}, \mathrm{W}))=\sigma\left(\mathrm{W}_{2} \delta\left(\mathrm{W}_{1} \mathrm{z}\right)\right) s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))

Fscale
把这个值作为scale乘到 U U U的 C C C个通道上, 作为下一级的输入数据。
x ~ c = F scale ( u c , s c ) = s c ⋅ u c \widetilde{\mathbf{x}}_{c}=\mathbf{F}_{\text {scale}}\left(\mathbf{u}_{c}, s_{c}\right)=s_{c} \cdot \mathbf{u}_{c} x
c=Fscale(uc,sc)=sc⋅uc

这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
3、实际使用
SE-Inception网络
通过将变换 F t r F_{tr} Ftr看作一个整体的Inception模块(参见图2),为Inception网络构建SE块。通过对架构中的每个模块进行更改,构建了一个SE-Inception网络。
Figure2是在Inception中加入SE block的情况,这里的Inception部分就对应Figure1中的 F t r F_{tr} Ftr操作。

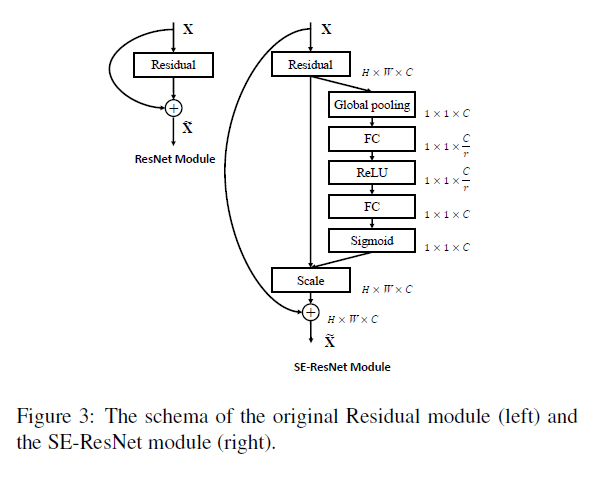
SE-ResNet模块
残留网络及其变种已经证明在学习深度表示方面非常有效。我们开发了一系列的SE块,分别与ResNet,ResNeXt和Inception-ResNet集成。图3描述了SE-ResNet模块的架构。在这里,SE块变换 F t r F_{tr} Ftr被认为是残差模块的非恒等分支。压缩和激励都在恒等分支相加之前起作用。
4、思考
思考一
先是Squeeze部分。Global Average Pooling有很多算法,作者用了最简单的求平均的方法(公式1),将空间上所有点的信息都平均成了一个值。这么做是因为最终的scale是对整个通道作用的,这就得基于通道的整体信息来计算scale。另外作者要利用的是通道间的相关性,而不是空间分布中的相关性,用GAP屏蔽掉空间上的分布信息能让scale的计算更加准确。
思考二:
Excitation部分是用2个全连接来实现 ,第一个全连接把 C C C个通道压缩成了 C / r C/r C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回 C C C个通道(后面跟了Sigmoid), r r r是指压缩的比例。作者尝试了 r r r在各种取值下的性能 ,最后得出结论 r = 16 r=16 r=16时整体性能和计算量最平衡。
思考三:
为什么要加全连接层呢?这是为了利用通道间的相关性来训练出真正的scale。一次mini-batch个样本的squeeze输出并不代表通道真实要调整的scale值,真实的scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加个全连接层来进行训练。
思考四:
为什么是两个全连接层呢
应该是类似bottleneck的设计,增加非线性(model capacity),减少参数和运算量,不压缩的话这块儿的参数量和运算量会多 r 2 r^2 r2倍,比如1024个特征到1024个特征,直接全连接运算量是1024*1024,如果中间插入一个256层,那么它的运算量是1024*256*2,运算量降低了一半。
思考五:
看完结构,再来看添加了SE block后,模型的参数到底增加了多少。其实从前面的介绍可以看出增加的参数主要来自两个全连接层,两个全连接层的维度都是C/r * C,那么这两个全连接层的参数量就是2*C^2/r。以ResNet为例,假设ResNet一共包含S个stage,每个Stage包含N个重复的residual block,那么整个添加了SE block的ResNet增加的参数量就是下面的公式:
2 r ∑ s = 1 S N s ⋅ C s 2 \frac{2}{r} \sum_{s=1}^{S} N_{s} \cdot C_{s}^{2} r2s=1∑SNs⋅Cs2

思考六:
可以拿SE Block和下面3种错误的结构比较来进一步理解:
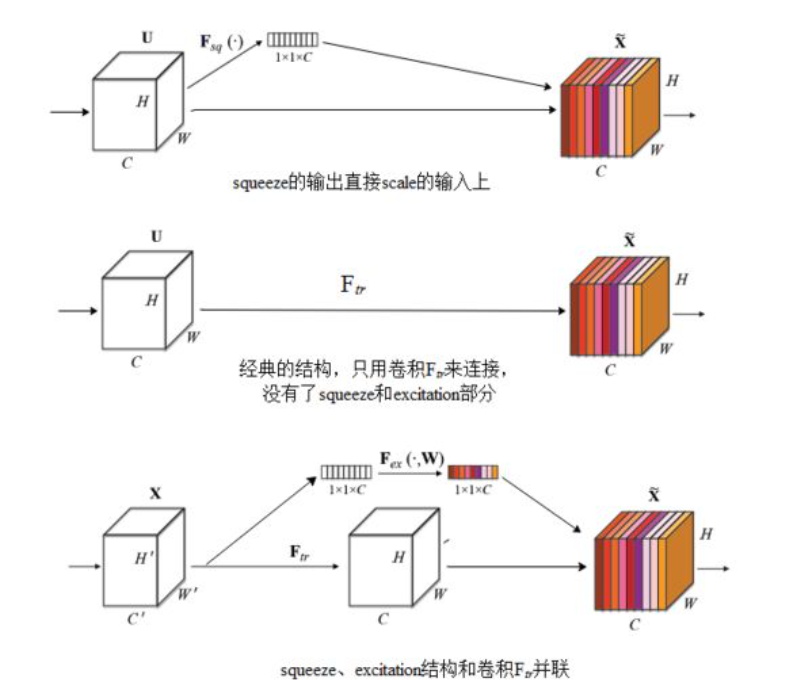
最上方的结构,squeeze的输出直接scale到输入上,没有了全连接层,某个通道的调整值完全基于单个通道GAP的结果,事实上只有GAP的分支是完全没有反向计算、没有训练的过程的,就无法基于全部数据集来训练得出通道增强、减弱的规律。
中间是经典的卷积结构,有人会说卷积训练出的权值就含有了scale的成分在里面,也利用了通道间的相关性,为啥还要多个SE Block?那是因为这种卷积有空间的成分在里面(也就是之前所说的通道间的这些依赖性与滤波器捕获的空间相关性纠缠在一起),为了排除空间上的干扰就得先用GAP压缩成一个点后再作卷积,压缩后因为没有了Height、Width的成分,这种卷积就是全连接了。
最下面的结构,SE模块和传统的卷积间采用并联而不是串联的方式,这时SE利用的是 F t r F_{tr} Ftr输入 X X X的相关性来计算scale, X X X和 U U U的相关性是不同的,把根据 X X X的相关性计算出的scale应用到 U U U上明显不合适。
5、代码细节
看了下caffe代码(.prototxt文件),和文章的实现还有些不一样。下图是在Inception中添加SENet的可视化结果:SE-BN-Inception,在Inception中是在每个Inception的后面连上一个SENet,下图的上面一半就是一个Inception,下面一半就是一个SENet,然后这个SENet下面又连着一个新的Inception。
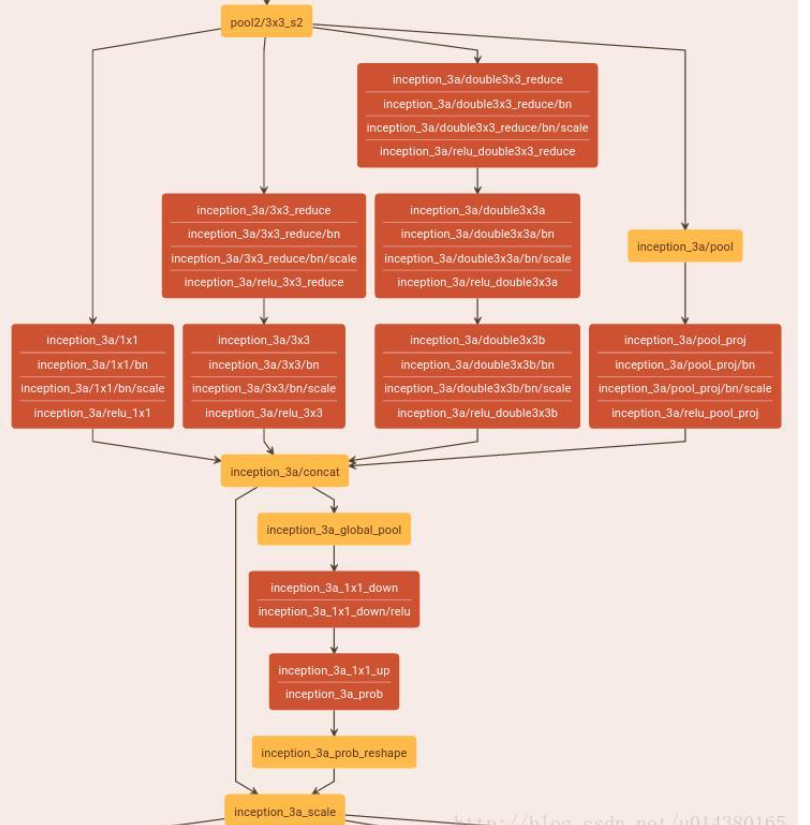
注意看这个SENet的红色部分都是用卷积操作代替文中的全连接层操作实现的
个人理解是为了减少参数(原来一个全连接层是 C ∗ C / r C*C/r C∗C/r个参数,现在变成了 C / r C/r C/r个参数了)。
具体来说,inception_3a_1*1_down是输出channel为16的1*1卷积,其输入channel是256,这也符合文中说的缩减因子为16(256/16=16);而inception_3a_1*1_up是输出channel为256的1*1卷积。其它层都和文中描述一致,比如inception_3a_global_pool是average pooling,inception_3a_prob是sigmoid函数。
SE-ResNet-50的情况也类似,如下图。在ResNet中都是在Residual block中嵌入SENet。下图最左边的长条连线是原来Residual block的skip connection,右下角的conv2_2_global_pool到conv2_2_prob以及左边那条连线都是SENet。不过也是用两个1*1卷积代替文中的两个全连接层。

6、总结
SENet把重要通道的特征强化,非重要通道的特征弱化,得到了很好的效果,这是一种全新的思路,在这个方向上将来可能会有更多的成果。
LAST、参考文献
评论
如何评价 Squeeze-and-Excitation Networks ? - 知乎
解读Squeeze-and-Excitation Networks(SENet)_gaotihong的博客-CSDN博客
解读Squeeze-and-Excitation Networks(SENet) - 知乎
Squeeze-and-Excitation Networks论文翻译——中文版 - 简书
SENet(Squeeze-and-Excitation Networks)算法笔记_AI之路-CSDN博客
Squeeze-and-Excitation Networks论文翻译——中英文对照_SnailTyan-CSDN博客
论文阅读笔记—senet_xys430381_1的专栏-CSDN博客