
Autor | La piedra que flota como un sueño
guía
Con la amplia aplicación de la tecnología informática en tiempo real en big data, la puntualidad de los datos ha mejorado mucho, pero en los escenarios de aplicación reales, además de la puntualidad, también enfrenta mayores requisitos técnicos.
Este documento combina la exploración y la práctica de la tecnología de cálculo del nivel del agua en tiempo real en el almacén de datos integrado por lotes de flujo, centrándose en el concepto de tecnología del nivel del agua y las prácticas teóricas relacionadas, especialmente las características, la definición de límites y la aplicación del nivel del agua en la realidad. -sistemas de cómputo de tiempo, y finalmente se enfoca en la descripción Se presenta un diseño e implementación mejorados de nivel de agua preciso. La arquitectura técnica actualmente es madura y estable en los escenarios comerciales reales de Baidu, y me gustaría compartirla con usted, con la esperanza de que sea de valor de referencia para todos.
El texto completo tiene 7118 palabras y el tiempo de lectura previsto es de 18 minutos.
01 Antecedentes comerciales
Para mejorar la eficiencia del desarrollo de productos, la iteración de estrategias, el análisis de datos y la toma de decisiones operativas, las empresas tienen requisitos cada vez más altos para la puntualidad de los datos.
Aunque nos dimos cuenta muy temprano de la construcción de un almacén de datos en tiempo real basado en la computación en tiempo real, todavía no puede reemplazar el almacén de datos fuera de línea.El costo de desarrollo y mantenimiento de un conjunto de almacenes de datos en tiempo real y fuera de línea es alto, y lo más importante es que el calibre del negocio no puede estar alineado al 100%. Por lo tanto, nos hemos comprometido a construir un almacén de datos integrado de transmisión por lotes, que no solo puede acelerar la eficiencia general del procesamiento de datos, sino también garantizar que los datos sean tan confiables como los datos fuera de línea y que puedan admitir escenarios comerciales al 100 %. para lograr una reducción general de costos y una mejora de la eficiencia.
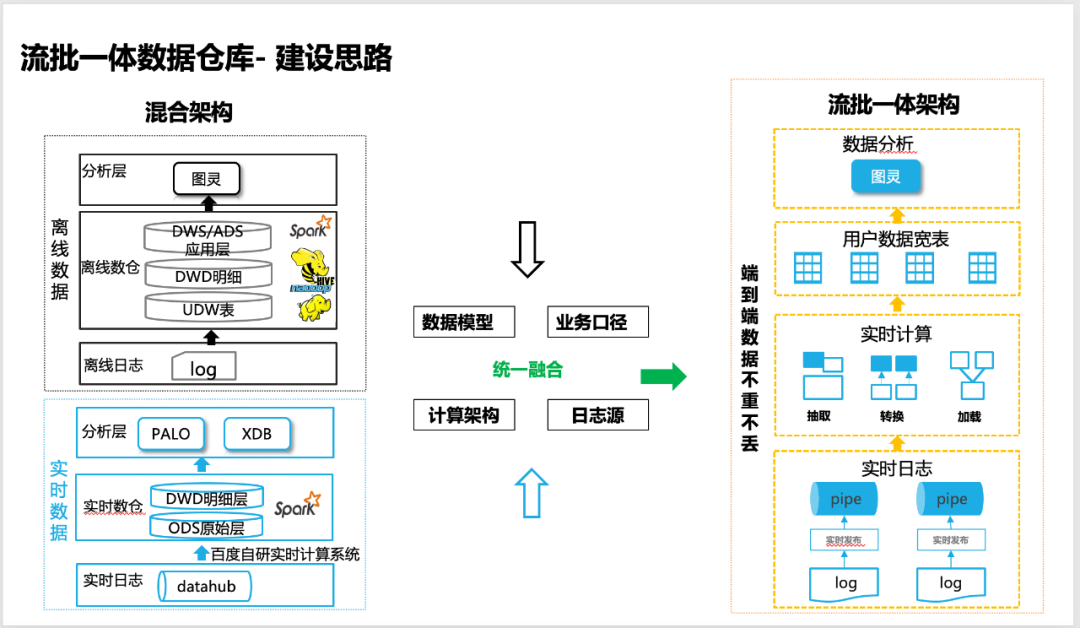
△La idea de construir un almacén de datos integrado de flujo por lotes
02 Dificultades técnicas del almacén de datos integrado Stream-Batch
Con el fin de realizar el almacenamiento de datos por lotes y transmisión integrado de extremo a extremo, como el sistema informático en tiempo real de la arquitectura técnica subyacente, se enfrenta a muchas dificultades y desafíos técnicos:
1. Los datos de extremo a extremo no se repiten ni se pierden estrictamente para garantizar la integridad de los datos;
2. La ventana de datos en tiempo real y la ventana de datos sin conexión, incluidos los datos, están alineados (99,9 % ~ 99,99 %) ;
3. El cálculo en tiempo real debe admitir un cálculo de ventana preciso para garantizar el efecto preciso de la estrategia anti-trampas en tiempo real;
4. El sistema informático en tiempo real está integrado con la ecología interna de big data de Baidu, y existe una práctica real de operación estable en línea a gran escala.
Los 2 y 3 puntos anteriores requieren un mecanismo de nivel de agua altamente confiable para garantizar el conocimiento del progreso y la segmentación precisa de los datos en tiempo real.
Por lo tanto, este artículo comparte con usted la exploración y la experiencia práctica del nivel de agua preciso en el almacén de datos integrado de lotes de flujo.
03 Estado actual del concepto de nivel de agua e implementación general
3.1 Necesidad de nivel de agua
Antes de introducir el concepto de marca de agua, es necesario insertar dos conceptos:
-
Hora del evento, la hora en que ocurrió el evento. En general, lo entendemos como el momento en que se produjo el comportamiento real del usuario, y específicamente corresponde a la marca de tiempo en que se produjo el comportamiento del usuario en el registro.
-
Tiempo de procesamiento, tiempo de procesamiento de datos. Generalmente lo entendemos como el tiempo que tarda el sistema en procesar los datos.
¿Cuál es el uso específico de la marca de agua?
En el proceso real de procesamiento de datos en tiempo real, los datos son ilimitados (Ilimitados), por lo que la computación de ventanas basada en Windows u otros escenarios similares enfrentan un problema práctico:
¿Cómo sabes que los datos en una determinada ventana están completos? ¿Cuándo se puede activar el cálculo de ventana ()?
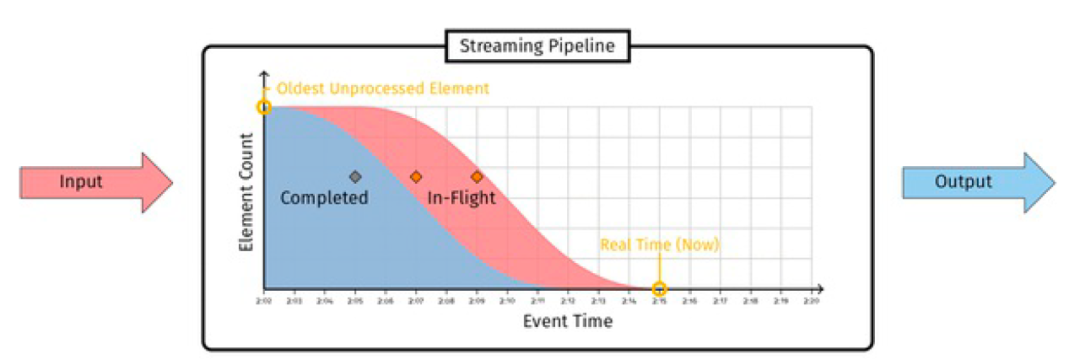
En la mayoría de los casos, usamos Event Time para desencadenar cálculos de ventana (o división de partición de datos y alineación fuera de línea). Sin embargo, la situación real es que los registros en tiempo real siempre tienen diferentes grados de retraso (en las etapas de recopilación de registros, transmisión de registros y procesamiento de registros), es decir, como se muestra en la figura a continuación, el sesgo de la marca de agua en realidad (es decir, los datos aparecerán desordenados). En este caso, el mecanismo de marca de agua es necesario para garantizar la integridad de los datos.
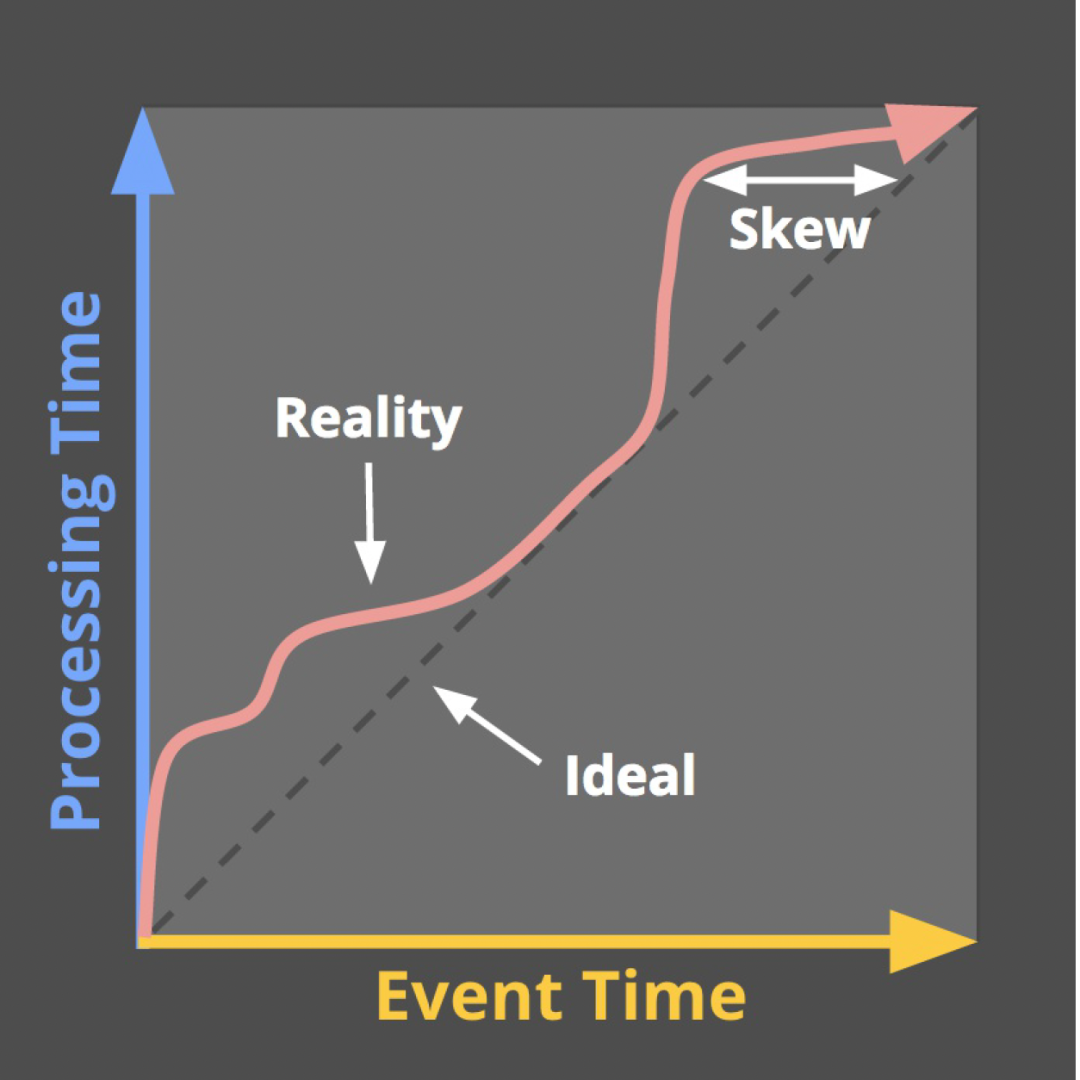 △Fenómeno de inclinación del nivel del agua
△Fenómeno de inclinación del nivel del agua
3.2 Definición y características del nivel del agua
La definición de marca de agua (watermark) actualmente no es uniforme en la industria. Combinada con la definición en el libro ** Streaming Systems ** (el autor es el equipo de I+D de Google Dataflow), personalmente creo que es más precisa:
La marca de agua es una marca de tiempo que aumenta monótonamente del trabajo más antiguo que aún no se ha completado.
A partir de la definición, podemos resumir las dos características básicas del nivel del agua:
-
El nivel del agua está aumentando continuamente (no retornable)
-
El nivel del agua es una marca de tiempo
Sin embargo, en el sistema de producción real, ¿cómo calcular el nivel del agua y cuál es el efecto real? Combinado con diferentes sistemas de cómputo en tiempo real en la industria, el soporte para los niveles de agua sigue siendo diferente.
3.3 Estado actual del nivel del agua y desafíos
En los sistemas informáticos en tiempo real actuales en la industria, como Apache Flink (una implementación de código abierto de Google Dataflow) y Apache Spark (solo limitado al marco de transmisión estructurada), todos admiten niveles de agua. El siguiente es el más popular Apache Flink en la comunidad Enumere el mecanismo de implementación del nivel del agua:

Sin embargo, el mecanismo de implementación y el efecto del nivel de agua anterior, en el caso de una gran área de transmisión de registro retrasada en la fuente de registro, el nivel de agua aún se actualizará (los datos nuevos y antiguos se transmiten desordenados) y adelantado, lo que dará lugar a datos incompletos en la ventana correspondiente y cálculo de ventana inexacto. Por lo tanto, dentro de Baidu, hemos explorado un mecanismo de nivel de agua mejorado y relativamente preciso basado en el sistema de recopilación y transmisión de registros y el sistema informático en tiempo real para garantizar que los datos en tiempo real se calculen en la ventana y el aterrizaje de datos (sumidero a AFS /Hive) y otros escenarios de aplicación A continuación, el problema de la integridad de los datos de la ventana es cumplir con los requisitos para realizar el almacén de datos integrado de flujo por lotes.
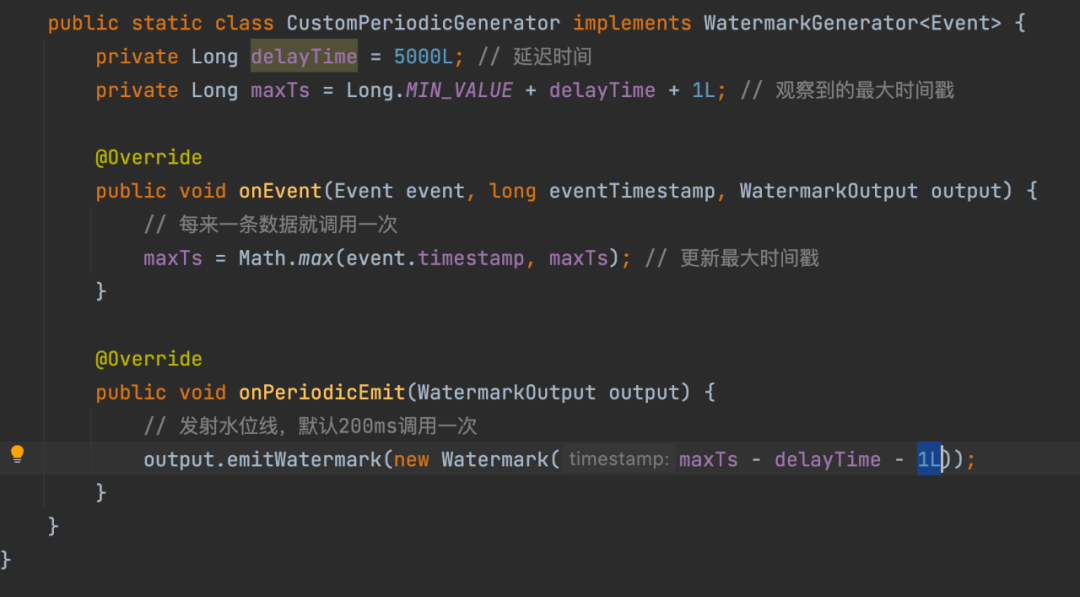
△Flink estrategia de generación de nivel de agua
CHARLA FRIKI
04 Diseño y aplicación del nivel global del agua
4.1 Diseño de la gestión centralizada del nivel del agua
Para que el nivel del agua sea más preciso en el cálculo en tiempo real, diseñamos una idea centralizada de gestión del nivel del agua, es decir, cada nodo de cálculo en tiempo real, incluida la fuente, el operador, el hundidor, etc., informará el nivel del agua. información calculada por sí mismo al servidor de marca de agua global, el servidor de marca de agua lleva a cabo la gestión unificada de la información del nivel del agua.
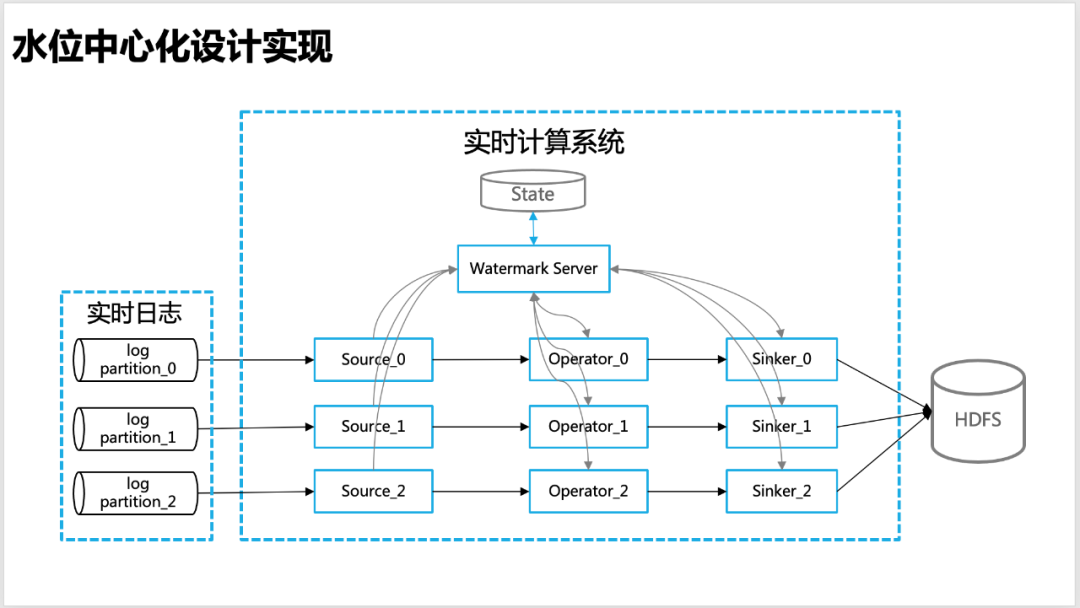
△Diseño de nivel de agua centralizado
Servidor Watermark : mantenga una tabla de información de nivel de agua (hash_table), que contiene la información de nivel de agua correspondiente a cada nivel de la información de topología general (Fuente, Operador, Sumidero, etc.) del programa de cálculo en tiempo real (APP), por lo que para facilitar el cálculo del nivel global del agua (como la marca de agua baja), el servidor de marca de agua interactúa con el estado regularmente para garantizar que la información del nivel del agua no se pierda.
Cliente de marca de agua : el cliente de actualización del nivel del agua, en tiempo real, operadores como fuente, trabajador y hundidor, es responsable de informar y solicitar información sobre el nivel del agua (como el nivel de agua global o aguas arriba) al servidor de marca de agua y solicitar la devolución de llamada a través de baidu-rpc servicio.
Marca de agua baja (nivel de agua bajo) : La marca de agua baja es una marca de tiempo que se utiliza para marcar la hora de los datos no procesados más antiguos (más antiguos) en el proceso de procesamiento de datos en tiempo real (marca de agua baja, que de forma pesimista intenta capturar la hora del evento de los datos sin procesar más antiguos). registro del que el sistema es consciente ). Promete que ningún dato futuro llegará antes de esa marca de tiempo. El cálculo del tiempo aquí generalmente se basa en el tiempo del evento, es decir, el momento en que ocurre el evento, como el momento en que ocurre el comportamiento del usuario en el registro, y el tiempo de procesamiento de datos (tiempo de procesamiento, que también se puede usar en algunos escenarios ) se usa menos. La fórmula para el cálculo de la marca de agua es (de Google MillWheel Thesis ):
Marca de agua baja de A = min (trabajo más antiguo de A, marca de agua baja de C: salidas C a A)
Sin embargo, en el diseño del sistema real, la marca de agua baja se puede distinguir según el límite del procesamiento del operador de la siguiente manera:
-
Marca de agua baja de entrada : el trabajo más antiguo aún no se ha enviado a esta etapa de transmisión.
InputLowWatermark(Etapa) = min { OutputLowWatermark(Etapa') | Stage' está aguas arriba de Stage}
Ingrese el nivel de agua más bajo, que puede entenderse como la marca de agua que se ingresará al operador actual, es decir, los datos procesados por el operador aguas arriba.
-
Marca de agua baja de salida : el trabajo más antiguo aún no completado en esta etapa de transmisión.
OutputLowWatermark(Stage) = min { InputLowWatermark(Stage), OldestWork(Stage) }
Muestra el nivel de agua más bajo, que el operador actual puede entender como el nivel de agua más temprano (más antiguo) de los datos sin procesar, es decir, el nivel de agua de los datos procesados.
Como se muestra en la figura a continuación, la comprensión será más vívida.
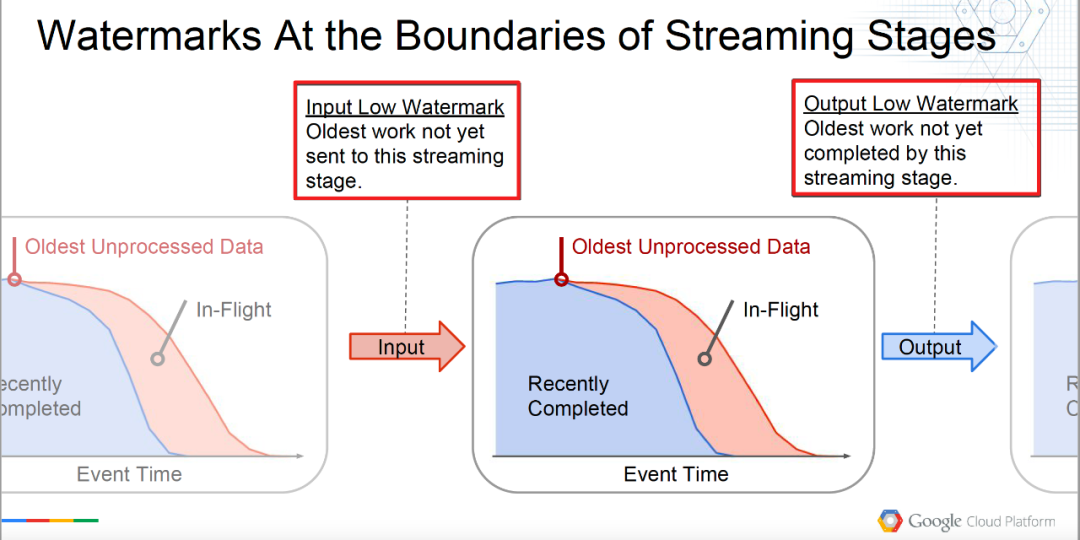 Definición de límite de △Marca de agua baja
Definición de límite de △Marca de agua baja
4.2 Cómo lograr un nivel de agua preciso
4.2.1 Condiciones previas para un nivel de agua exacto
En la actualidad, en los escenarios de aplicación de los sistemas informáticos en tiempo real en los almacenes de datos en tiempo real, todos usamos la marca de agua baja para activar el cálculo de la ventana (porque es más confiable). De la definición de marca de agua baja en 3.1, podemos saber que : la marca de agua baja se calcula por iteración jerárquica, y si el nivel del agua es exacto, depende de la precisión del nivel de agua más arriba (es decir, fuente). Entonces, para mejorar la precisión del cálculo del nivel de agua de la fuente, necesitamos requisitos previos:
-
Los registros se producen secuencialmente según el tiempo (event_time) en un solo servidor en el lado del servidor
-
Cuando se recopila el registro, además del registro de comportamiento real del usuario, también debe contener otra información, como la etiqueta del servidor (nombre de host) y la hora de registro (msg_time), como se muestra en la siguiente figura.

△ Información de empaquetado de registro
-
El registro se publica en la cola de mensajes en tiempo real punto a punto para garantizar que dentro de una única partición de la cola de mensajes, los registros de un único servidor estén estrictamente ordenados.
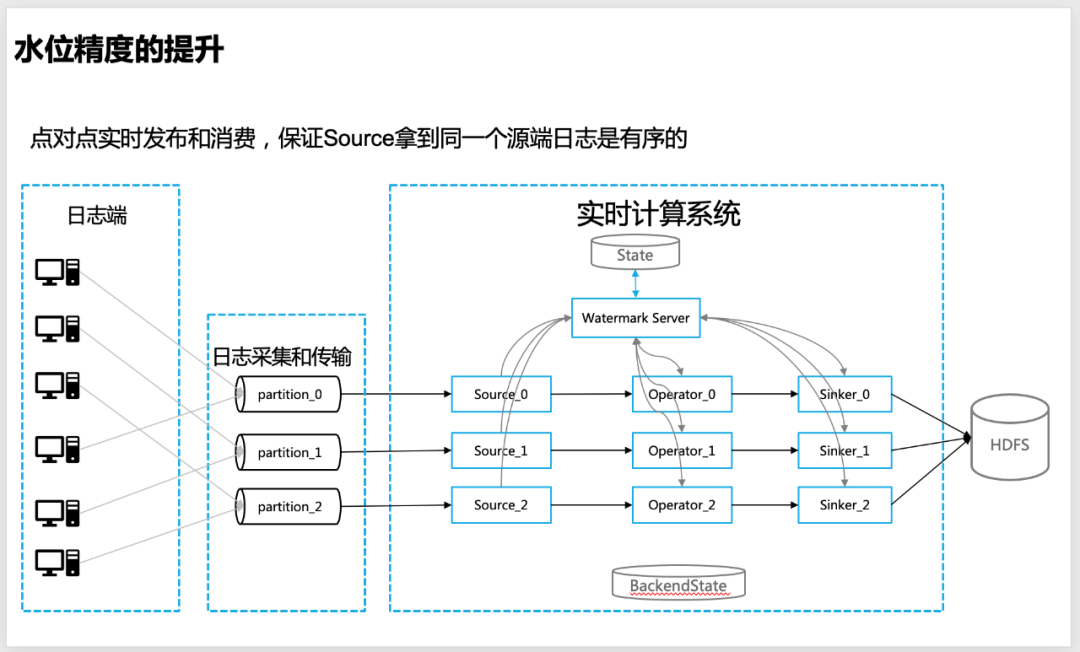
△El registro de origen se publica punto a punto en la cola de mensajes para garantizar que el registro de una sola partición esté ordenado
4.2.2 Método de cálculo del nivel de agua
1, servidor de marca de agua
Inicializar :
Primero comenzó como un hilo separado (hilo). Según el BNS (Baidu Naming Service, servicio de nombres de Baidu, que proporciona una asignación del nombre del servicio a todas las instancias del servidor en ejecución) de la tarea de transmisión de registros configurada, se analiza la lista de servidores (lista de nombres de host) del origen del registro; De acuerdo con la relación de topología de la aplicación configurada, la marca de agua se inicializa en la tabla de información y en la tabla de escritura persistente (motor de almacenamiento kv distribuido de Baidu).
Actualización de información de nivel de agua ordinaria : Reciba la información de nivel de agua del cliente y actualice el nivel de agua de la granularidad correspondiente (granularidad de procesador o granularidad de grupo clave), y actualice el nivel de agua local
Cálculo preciso del nivel de agua :
En realidad, si se requiere que el registro en la fuente llegue con un 100 % de precisión, provocará retrasos frecuentes o retrasos demasiado largos (si se utiliza la lógica global de marca de agua baja para la distribución). La razón es: en el caso de demasiadas instancias de servidor en el lado del registro (por ejemplo, en realidad tenemos 6000-10000 instancias de registros), siempre habrá un retraso en la carga de registros en tiempo real en instancias de servicios en línea por cable. , por lo que esto debe hacerse en Haga un compromiso entre la integridad de los datos y la puntualidad, como controlar con precisión la cantidad de instancias que permiten demoras en forma de porcentajes (por ejemplo, configure 99.9% o 99.99% para establecer la proporción que permite la fuente). registros que se retrasarán ), para controlar con precisión la precisión del nivel del agua en la misma fuente.
El nivel preciso del agua requiere una configuración especial. La marca de agua baja de salida de la fuente se calcula de acuerdo con la relación de mapeo entre el servidor y el progreso del registro informado por la fuente en tiempo real, y la proporción configurada de instancias de retraso permitidas.
Calcule la marca de agua baja global : se calculará un nivel de agua mínimo global y se devolverá a la solicitud del cliente
Persistencia del estado : escriba periódicamente la persistencia de la información del nivel de agua global en el almacenamiento externo para una fácil recuperación del estado
2、Cliente de marca de agua
Origen final : analice el paquete de registro y obtenga información como el nombre de la máquina y el registro original en el paquete de registro. Después de que ETL procese el registro original y se obtenga la marca de tiempo más reciente (event_timestamps) de acuerdo con el registro original, Source informa periódicamente la tabla de relaciones de asignación resuelta al nombre de host y la marca de tiempo más reciente (event_timestamps) a través de la API de Watermark Client (actualmente configurado 1000ms) a Watermark Server.
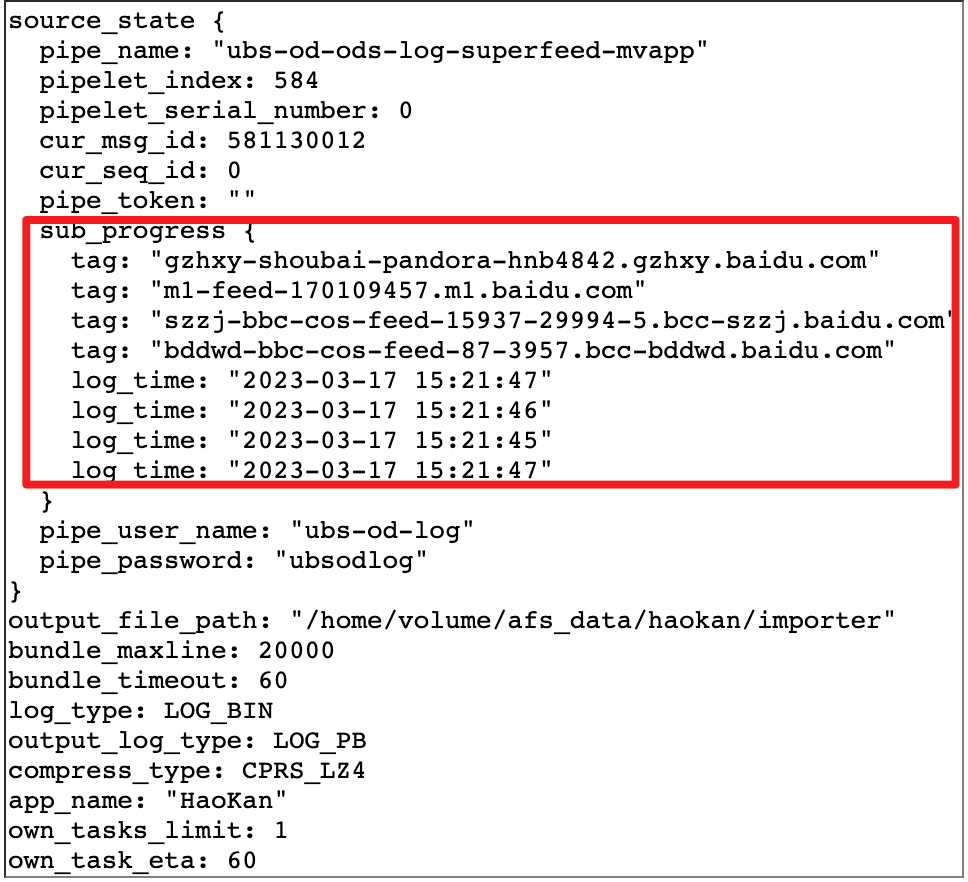
△Fuente La relación de mapeo del progreso del registro y el servidor obtenida al analizar el registro
Lado del operador :
Cálculo de marca de agua baja de entrada: obtenga la marca de agua baja de salida del flujo ascendente (Upstream) como la marca de agua baja de entrada para determinar si se debe activar el cálculo de la ventana y otras operaciones;
Cálculo de marca de agua baja de salida: calcule su propia marca de agua baja de salida en función del registro, el estado (estado) y otros progresos de procesamiento (trabajo más antiguo), e infórmelo al servidor de marca de agua para que lo usen los operadores posteriores (procesador de descarga).
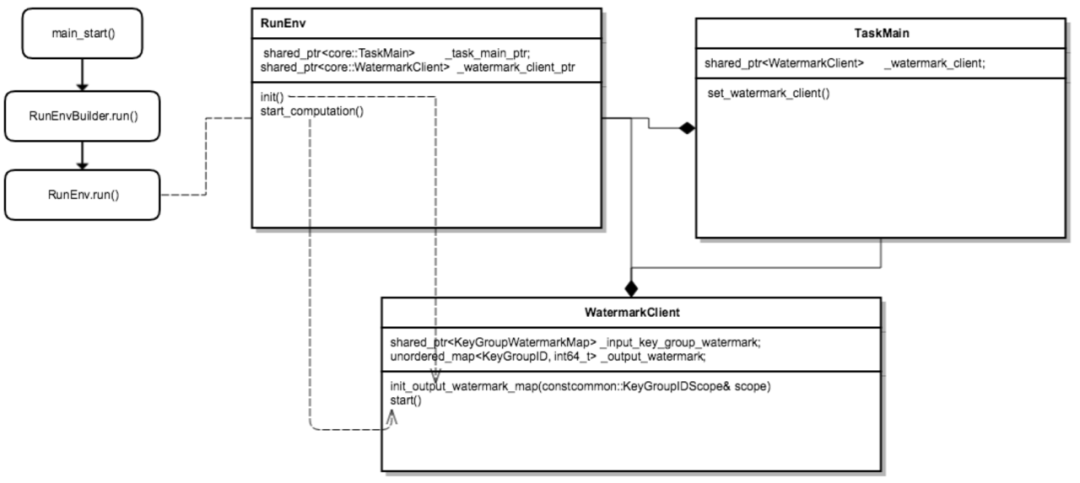
△Flujo de trabajo del cliente de marca de agua
Lado del hundidor :
El lado del hundidor es el mismo que el operador ordinario en tiempo real anterior (Operador), calculará la marca de agua baja de entrada y la marca de agua baja de salida para actualizar su propio nivel de agua,
Además, se debe solicitar una marca de agua baja global para determinar si la ventana de salida de datos está cerrada.
4.3 Transmisión del nivel de agua preciso entre sistemas
La necesidad de transferir el nivel del agua
En muchos casos, los sistemas en tiempo real no están aislados y existe una interacción de datos entre múltiples sistemas informáticos en tiempo real. La forma más común es que dos sistemas de procesamiento de datos en tiempo real estén aguas arriba y aguas abajo.
El rendimiento específico es: dos sistemas de procesamiento de datos en tiempo real implementan la transferencia de datos a través de colas de mensajes (como Apache Kafka en la comunidad), entonces, en este caso, ¿cómo lograr una transferencia precisa del nivel del agua?
Los pasos específicos de implementación son los siguientes :
1. La fuente de registro del sistema informático en tiempo real aguas arriba garantiza que el registro se publique punto a punto, lo que puede garantizar la precisión del nivel global del agua (la relación específica es ajustable);
2. En el extremo de salida del sistema de cómputo en tiempo real aguas arriba (hundidor/exportador al final de la cola de mensajes), es necesario asegurarse de que se emita la marca de agua baja global.Actualmente, utilizamos la información del nivel de agua global para imprimir en cada registro para lograr la entrega;
3. En el extremo de la fuente del sistema de cálculo de datos en tiempo real aguas abajo, es necesario analizar el campo de información del nivel del agua que lleva el registro (del sistema de cálculo en tiempo real aguas arriba) y comenzar a utilizarlo como entrada de el nivel del agua (Input Low Watermark) e inicie el cálculo iterativo del nivel del agua capa por capa y el cálculo del nivel global del agua;
4. En el extremo Operador/Sinker del sistema informático de datos en tiempo real aguas abajo, la hora del evento del registro aún se puede usar para lograr una segmentación de datos específica como entrada del cálculo de la ventana, pero el mecanismo para activar el cálculo de la ventana aún se basa en sobre los datos globales devueltos por Watermark Server Low Watermark prevalecerá para garantizar la integridad de los datos.
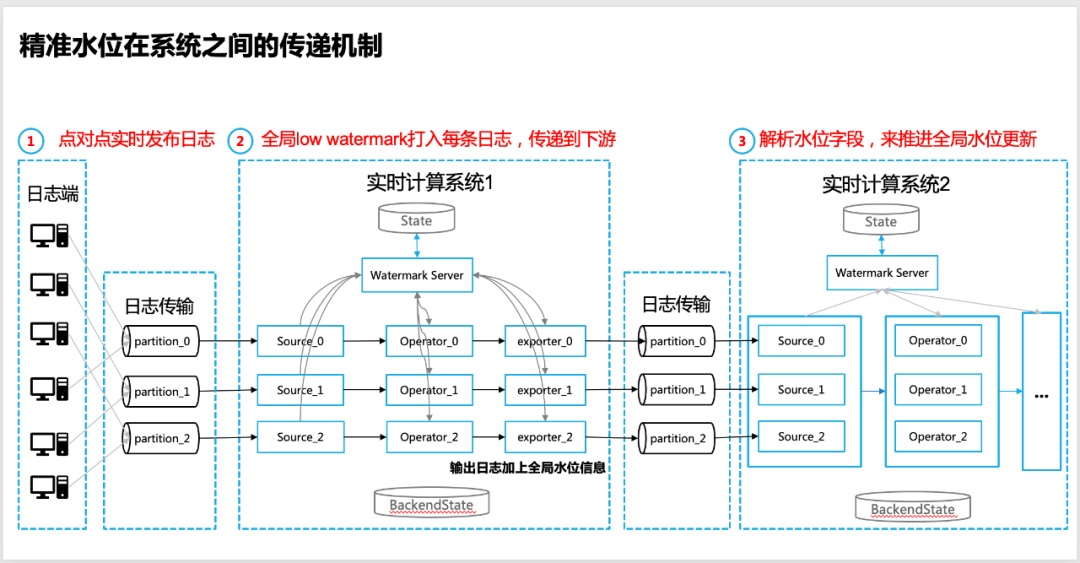
△Mecanismo de transferencia de nivel de agua preciso entre sistemas informáticos en tiempo real
05 Efectos reales y perspectivas de seguimiento
5.1 Efecto real en línea
5.1.1 El efecto medido (integridad) de los datos de aterrizaje
La prueba en línea real adopta un nivel de agua preciso (la precisión del nivel de agua configurado es del 99,9 %, es decir, solo se permite una milésima parte del retraso de la instancia de origen), y cuando no hay retraso en el registro, los datos de aterrizaje en tiempo real y los datos fuera de línea están en la misma ventana de tiempo (Event Time) La comparación de efectos es la siguiente (básicamente todos por debajo de 100,000 puntos):

△El efecto de la integridad de los datos cuando el registro de origen no se retrasa
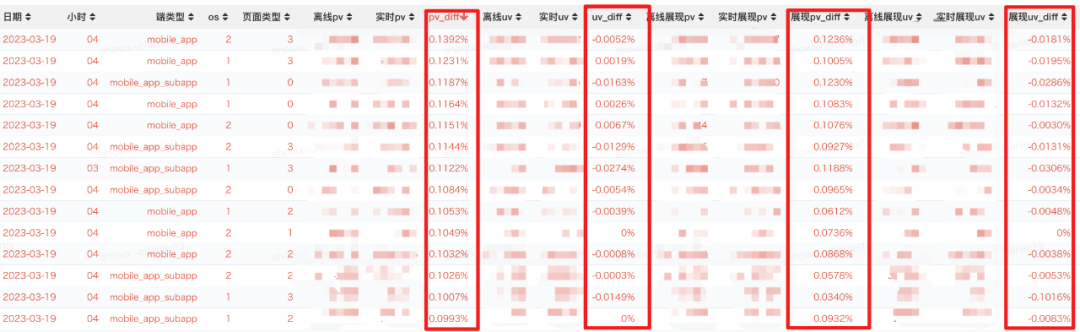
Cuando el registro de origen se retrasa (<=0,1 % de la instancia de registro de origen se retrasa, el nivel del agua seguirá actualizándose), el efecto de diferencia de datos general es básicamente de 1/1000 (sujeto a la posibilidad de que el punto de origen del registro -to-point log sí mismo Influencia de la falta de homogeneidad de los datos):

En el caso de una gran área de retraso en el registro de origen (>0,1 % del retraso de instancia de registro de origen), debido al uso de un mecanismo de nivel de agua preciso (precisión del nivel de agua 99,9 %), el nivel de agua global no se actualizará, y los datos en tiempo real se escribirán en AFS La ventana no se cerrará, y la ventana se cerrará solo después de esperar la llegada de los datos retrasados y la actualización del nivel global del agua para garantizar la integridad de la datos Los resultados reales de la prueba son los siguientes (entre 1.1-1.2 por mil, sujeto a la fuente de registro La instancia en sí tiene el efecto de la desigualdad):
5.2 Resumen y presentación
Después de la investigación sobre el nivel de agua preciso real y la aplicación en línea real, el almacén de datos en tiempo real basado en el nivel de agua preciso no solo mejora la puntualidad, sino que también tiene un mecanismo de precisión de datos más alto y flexible.Después de la optimización de la estabilidad, en realidad es completamente En lugar de los anteriores sistemas de almacenamiento de datos fuera de línea y en tiempo real, se realiza un verdadero almacenamiento de datos integrado de secuencias por lotes.
Al mismo tiempo, basado en el mecanismo de nivel de agua centralizado, también enfrentará los desafíos de optimización del rendimiento, alta disponibilidad (mejora del mecanismo de recuperación de fallas) y granularidad más fina y nivel de agua preciso (bajo el mecanismo de activación de cálculo de ventana).
--FIN--
referencias:
[1] T. Akidau, A. Balikov, K. Bekiroğlu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom y S. Whittle. Millwheel: Procesamiento de flujo tolerante a fallas a escala de Internet. proc. VLDB Endow., 6(11):1033–1044, agosto de 2013.
[2] T. Akidau, R. Bradshaw, C. Chambers, S. Chernyak, RJ Fernández-Moctezuma, R. Lax, S. McVeety, D. Mills, F. Perry, E. Schmidt, et al. El modelo de flujo de datos: un enfoque práctico para equilibrar la corrección, la latencia y el costo en el procesamiento de datos fuera de orden, sin límites y a gran escala. Actas de la Fundación VLDB, 8(12):1792–1803, 2015.
[3] T. Akidau, S. Chernyak y R. Lax. Sistemas de transmisión. O'Reilly Media, Inc., 1.ª edición, 2018.
[4] "Marcas de agua: medición del tiempo y el progreso en las canalizaciones de transmisión", Slava Chernyak, Google Inc.
[5] P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi y K. Tzoumas. Apache flink: Procesamiento de secuencias y lotes en un solo motor. Boletín del Comité Técnico de Ingeniería de Datos de la IEEE Computer Society, 36(4), 2015.
Lectura recomendada:
Solución técnica de plantilla de texto en el escenario de edición de video
Hablando sobre la aplicación del algoritmo gráfico en la escena de actividad en anti-trampas
Serverless: práctica de escalado flexible basada en retratos de servicio personalizados
Método de descomposición de acciones en la aplicación de animación de imágenes.
Carretera de aceleración de datos de la plataforma de rendimiento
Edición AIGC Proceso de producción de video Práctica de arreglos