Este artículo es un discurso pronunciado por el equipo del kit de desarrollo de la plataforma de datos de ByteDance en Flink Forward Asia 2021: Flink Forward Summit, que se centra en compartir el pensamiento de selección y la práctica de exploración de la tecnología de lago de datos de ByteDance.
Texto | Gary Li Ingeniero sénior de I+D del equipo del kit de desarrollo de la plataforma de datos ByteDance, Apache Hudi PMC Miembro del proyecto de código abierto Data Lake
Con el desarrollo continuo de la comunidad Flink, cada vez más empresas utilizan Flink como su motor informático de big data preferido. ByteDance también continúa explorando Flink. Como uno de los muchos usuarios de Flink, su inversión en Flink también aumenta año tras año.
El status quo de la integración de datos de ByteDance
En 2018, construimos un canal de sincronización por lotes entre fuentes de datos heterogéneas basado en Flink, que se utiliza principalmente para importar bases de datos en línea a almacenes de datos fuera de línea y transmisión por lotes entre diferentes fuentes de datos.
En 2020, construimos un canal de integración de datos en tiempo real de MQ-Hive basado en Flink, que se usa principalmente para escribir los datos en la cola de mensajes en Hive y HDFS en tiempo real, y lograr la unificación de secuencias por lotes en el motor informático. .
Para 2021, construiremos un canal de integración de lago de datos en tiempo real basado en Flink, completando así la construcción de un sistema integrado de integración de datos de lago y almacén.
El sistema de integración de datos de ByteDance actualmente admite docenas de diferentes canales de transmisión de datos, que cubren bases de datos en línea, como Mysql Oracle y MangoDB; colas de mensajes, como Kafka RocketMQ; varios componentes del ecosistema de big data, como HDFS, HIVE y ClickHouse.
Dentro de ByteDance, el sistema de integración de datos sirve a casi todas las líneas de negocio, incluidas aplicaciones conocidas como Douyin y Toutiao.
Todo el sistema se divide principalmente en 3 modos: integración por lotes, integración de transmisión e integración incremental.
- El modo de integración por lotes se basa en el modo Flink Batch, que transmite datos por lotes en diferentes sistemas y actualmente admite más de 20 tipos de fuentes de datos diferentes.
- El modo de integración de transmisión principalmente importa datos de MQ a Hive y HDFS, y los usuarios reconocen ampliamente la estabilidad y el rendimiento en tiempo real de las tareas.
- El modo incremental es el modo CDC, que se utiliza para admitir la sincronización de cambios de datos en la base de datos de componentes externos a través del registro de cambios de la base de datos Binlog.
Este modo actualmente admite fuentes de datos 5. Aunque no hay muchas fuentes de datos, la cantidad de tareas es muy grande, incluidos muchos enlaces principales, como la facturación y liquidación de cada línea comercial, lo que requiere una precisión de datos muy alta.
El enlace general en el enlace CDC es relativamente largo. En primer lugar, la primera importación es una importación por lotes. Conectamos directamente la biblioteca Mysql a través del modo Flink Batch para extraer la cantidad total de datos y escribirlos en Hive, y los datos incrementales de Binlog se importan a HDFS a través de tareas de transmisión.
Dado que Hive no admite operaciones de actualización, todavía usamos un enlace por lotes basado en Spark para combinar la tabla de Hive del día anterior y el Binlog recién agregado mediante la combinación incremental T-1 para producir la tabla de Hive del día actual.
Con el rápido desarrollo de los negocios, este enlace expone cada vez más problemas.
En primer lugar, este enlace fuera de línea basado en Spark consume muchos recursos. Cada vez que se generan nuevos datos, implica una mezcla completa de datos y un disco de datos completo. Los recursos informáticos y de almacenamiento que se consumen en el medio son relativamente serios.
Al mismo tiempo, con el rápido desarrollo del negocio de ByteDance, también está aumentando la demanda de análisis casi en tiempo real.
Finalmente, todo el proceso de enlace es demasiado largo, involucra dos motores de cómputo, Spark y Flink, y tres tipos de tareas diferentes. El costo de uso y aprendizaje para los usuarios es relativamente alto, y trae muchos costos de operación y mantenimiento.
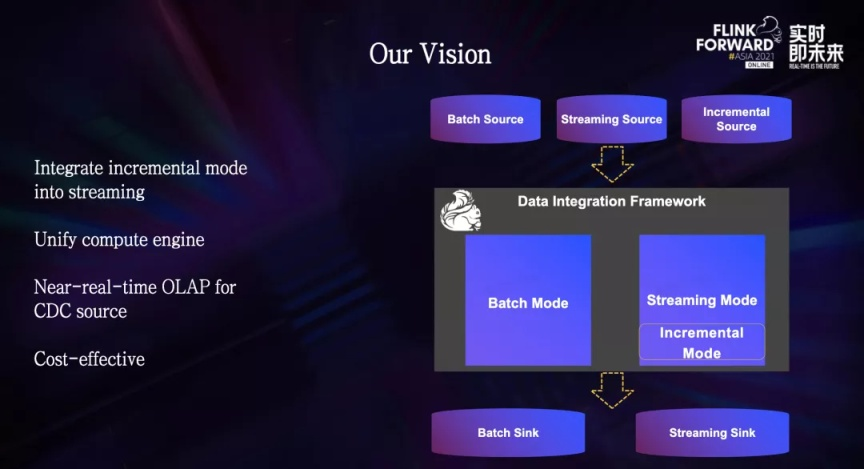
Para resolver estos problemas, esperamos realizar una actualización completa de la arquitectura al modo incremental y fusionar el modo incremental en la integración de transmisión, para eliminar la dependencia de Spark y lograr la unidad a nivel del motor informático.
Una vez completada la transformación, el motor de integración de datos basado en Flink puede admitir modos por lotes, de transmisión e incrementales al mismo tiempo, cubriendo casi todos los escenarios de integración de datos.
Al mismo tiempo, en el modo incremental, proporciona una latencia de datos equivalente al canal de transmisión, brindando a los usuarios capacidades de análisis casi en tiempo real. Mientras logra estos objetivos, puede reducir aún más los costos computacionales y mejorar la eficiencia.
Después de un poco de exploración, notamos la tecnología emergente del lago de datos.
Reflexiones sobre la selección de tecnología de lago de datos
Nuestro enfoque está en Iceberg y Hudi, dos marcos de lago de datos de código abierto bajo la Apache Software Foundation.
Los marcos de lago de datos Iceberg y Hudi son excelentes. Pero los dos proyectos fueron creados para resolver problemas diferentes, por lo que tienen diferentes enfoques funcionales:
- Iceberg: la abstracción central es relativamente económica para interactuar con los nuevos motores informáticos y proporciona capacidades avanzadas de optimización de consultas y cambios de esquema completos.
- Hudi: se enfoca más en Upserts eficientes y actualizaciones casi en tiempo real, proporcionando el formato de archivo Merge On Read y funciones de consulta incrementales que facilitan la creación de canalizaciones ETL incrementales.
Después de algunas comparaciones, los dos marcos tienen sus propias ventajas y desventajas, y están lejos de la forma final del lago de datos que imaginamos, por lo que nuestros problemas centrales se concentran en los siguientes dos problemas:
¿Qué marco puede soportar mejor las demandas centrales de nuestro procesamiento de datos de CDC?
¿Qué marco puede complementar rápidamente las funciones de otro marco y convertirse en un marco de lago de datos general y maduro?
Después de muchas discusiones internas, creemos que Hudi es más maduro en el procesamiento de datos de CDC, y la velocidad de iteración de la comunidad es muy rápida, especialmente en el último año, se han completado muchas funciones importantes y la integración con Flink se ha vuelto más madura. eligió Hudi como nuestra base de datos del lago.
01 - Sistema de indexación
Elegimos Hudi, y lo más importante es el sistema de indexación de Hudi.
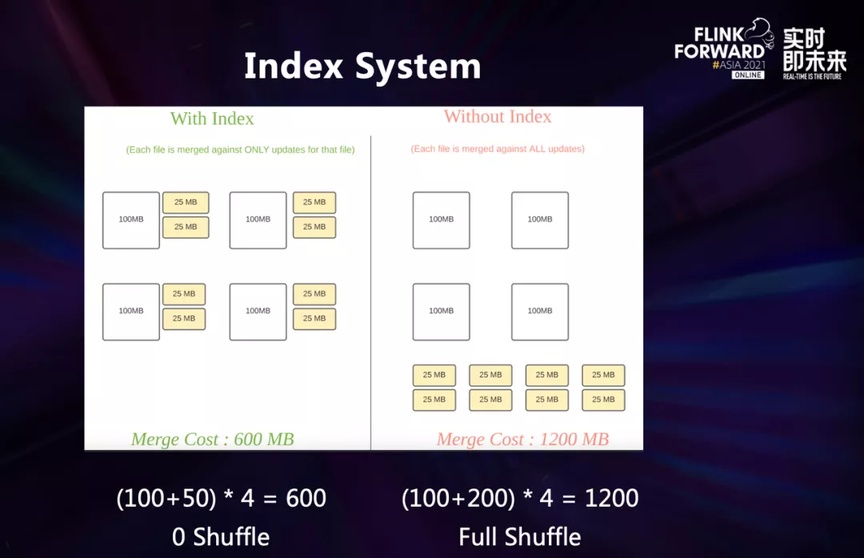
Este gráfico es una comparación con y sin indexación.
En el proceso de escritura de datos de CDC, para que los datos de actualización recién agregados actúen en la tabla inferior, necesitamos saber claramente si estos datos han aparecido y dónde han aparecido, para escribir los datos en el lugar correcto. Al fusionar, solo podemos fusionar un solo archivo sin tener que lidiar con datos globales.
Si no hay índice, la operación de combinación solo se puede realizar mediante la combinación de datos globales, lo que genera una mezcla global.
En el ejemplo de la figura, el costo de combinación sin un índice es el doble que con un índice, y si aumenta la cantidad de datos en la tabla base, esta brecha de rendimiento aumenta exponencialmente.
Por lo tanto, a nivel de datos comerciales que superan los bytes, los beneficios de rendimiento que brinda la indexación son enormes.
Hudi proporciona una variedad de índices para adaptarse a diferentes escenarios. Cada índice tiene diferentes ventajas y desventajas. La selección del índice debe basarse en la distribución específica de datos, para lograr la solución óptima para escribir y consultar.
A continuación se muestran ejemplos de dos escenarios diferentes.
1. Escenario de deduplicación de datos de registro
En el escenario de deduplicación de datos de registro, los datos suelen tener una marca de tiempo de create_time, y la distribución de la tabla inferior también se particiona de acuerdo con esta marca de tiempo. Los datos de las últimas horas o días se actualizarán con más frecuencia, pero cuanto mayor sea la los datos no cambiarán mucho.
Los escenarios de partición caliente y fría son más adecuados para índices Bloom, índices de estado con TTL e índices hash.
2. Escena de los CDC
El segundo ejemplo es un ejemplo de exportación de base de datos, que es el escenario de CDC. En este escenario, los datos actualizados se distribuirán aleatoriamente, no hay ninguna regla en absoluto, y la cantidad de datos en la tabla inferior será relativamente grande, y la cantidad de datos recién agregados generalmente será menor que la de la tabla inferior. mesa.
En este escenario, podemos elegir el índice hash, el índice estatal y el índice Hbase para lograr una indexación global eficiente.
Estos dos ejemplos ilustran que, en diferentes escenarios, la elección del índice también determina el rendimiento de lectura y escritura de toda la tabla. Hudi proporciona una variedad de índices listos para usar, que han cubierto la mayoría de los escenarios, y el costo para el usuario es muy bajo.
02 - Combinar en formato de tabla de lectura
Además del sistema de indexación, el formato de tabla Merge On Read de Hudi también es una de las características principales que valoramos. Este formato tabular permite escrituras en tiempo real y consultas casi en tiempo real.
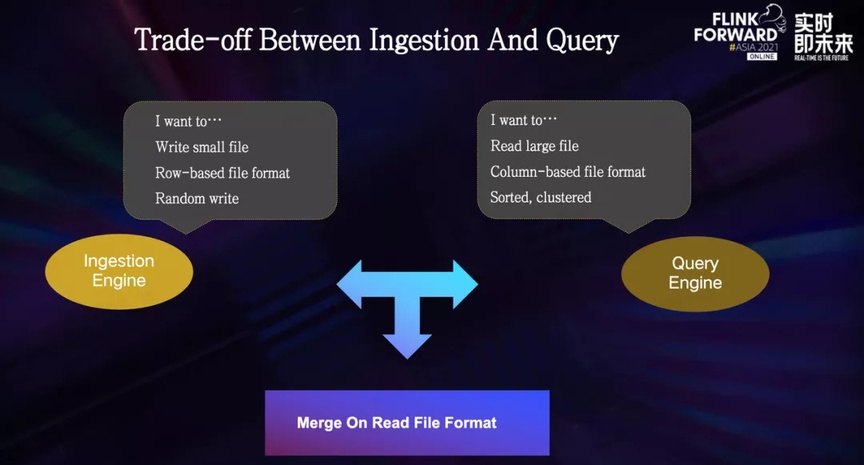
En la construcción del sistema de big data, existe un conflicto natural entre el motor de escritura y el motor de consulta:
El motor de escritura está más inclinado a escribir archivos pequeños y escribirlos en un formato de datos almacenados en filas para evitar, en la medida de lo posible, demasiada carga computacional durante el proceso de escritura. Lo mejor es escribir uno por uno.
El motor de consulta tiende más a leer archivos grandes y almacenar datos en formatos de archivo en columnas, como parquet y orc, y los datos se distribuyen estrictamente de acuerdo con ciertas reglas, como clasificarlos según un campo común, para que puedan usarse. al consultar. , omita el escaneo de datos inútiles para reducir la sobrecarga computacional.
Para encontrar la mejor compensación en este conflicto natural, Hudi admite el formato de archivo Merge On Read.
El formato MOR contiene dos tipos de archivos: uno es el archivo de registro basado en el formato Avro basado en filas y el otro es el archivo base basado en el formato basado en columnas, incluidos Parquet u ORC.
El archivo de registro suele ser pequeño y contiene datos actualizados recientemente. El archivo base es grande y contiene todos los datos históricos.
El motor de escritura puede escribir datos actualizados en el archivo de registro con baja latencia.
El motor de consulta fusiona el archivo de registro con el archivo base durante la lectura, de modo que se pueda leer la vista más reciente; la tarea de compactación activa periódicamente la fusión del archivo base y el archivo de registro para evitar la expansión continua del archivo de registro. Bajo este mecanismo, el formato de archivo Merge On Read logra escritura en tiempo real y consultas casi en tiempo real.
03 - Cálculo Incremental
El sistema de indexación y el formato Merge On Read sientan una base muy sólida para el lago de datos en tiempo real, y la computación incremental es otra característica deslumbrante de Hudi basada en esta base:
La computación incremental le da a Hudi una capacidad similar a la de una cola de mensajes. Los usuarios pueden extraer nuevos datos dentro de un período de tiempo en la línea de tiempo de Hudi a través de una marca de tiempo similar a la compensación.
En algunos escenarios en los que la tolerancia al retraso de datos está en el nivel de un minuto, Hudi puede unificar la arquitectura Lambda, atender escenarios tanto en tiempo real como fuera de línea, y lograr la integración de flujo por lotes en el almacenamiento.
Pensamiento práctico en el escenario interno de ByteDance
Después de elegir el marco del lago de datos basado en Hudi, creamos un plan de implementación personalizado basado en la escena interna de ByteDance. Nuestro objetivo es admitir todos los enlaces de datos con la actualización a través de Hudi:
Necesita upserts eficientes y de bajo costo
Soporta alto rendimiento
Visibilidad de datos de extremo a extremo en 5-10 minutos
Con el objetivo claro, empezamos a probar la Hudi Flink Writer. Este diagrama es la arquitectura de Hudi en Flink Writer: después de que ingresa una nueva pieza de datos, primero pasará por una capa de índice para encontrar a dónde debe ir.
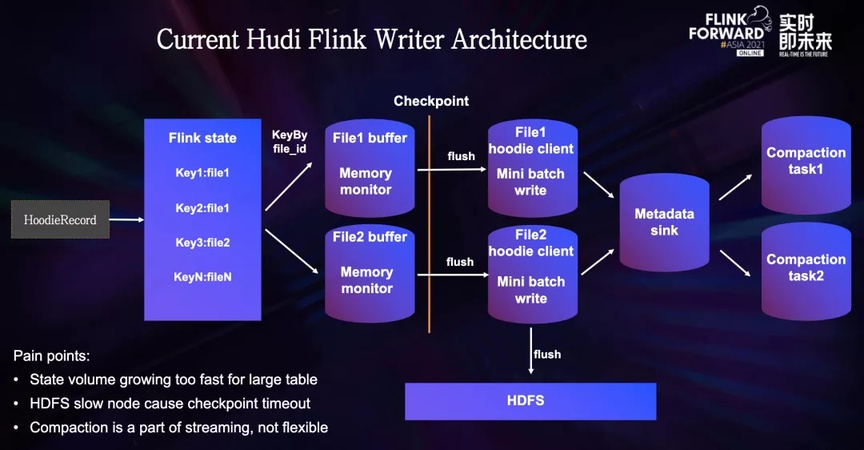
- El índice de estado guarda la relación de mapeo uno a uno entre todas las claves primarias y los ID de archivo. Para Actualizar datos, se encontrará el ID de archivo existente. Para Insertar datos, la capa de índice le asignará un nuevo ID de archivo o un histórico. file ID.small file, y deje que se llene en el archivo pequeño, evitando así el problema del archivo pequeño.
- Después de la capa de índice, cada pieza de datos tendrá una identificación de archivo, y Flink realizará una mezcla basada en la identificación del archivo e importará los datos con la misma identificación de archivo en la misma subtarea, lo que puede evitar el problema de escribir varias tareas. al mismo archivo. .
- Hay un búfer de memoria en la subtarea de escritura, que se usa para almacenar todos los datos del lote actual. Cuando se activa el punto de control, los datos en el búfer de la subtarea se transferirán al Cliente Hudi y el Cliente realizará algunos cálculos. en el modo de micro lotes. Operaciones, como Insertar/Upsert/Insertar sobrescribir, etc., la lógica de cálculo de cada operación es diferente. Por ejemplo, la operación Insert generará un nuevo archivo, y la operación Upsert puede fusionarse con el archivo histórico una vez.
- Una vez que se completa el cálculo, los datos procesados se escriben en HDFS y los metadatos se recopilan al mismo tiempo.
- La tarea de compactación es parte de la tarea de transmisión. Periódicamente entrenará la línea de tiempo de Hudi para verificar si hay un plan de compactación. Si hay un plan de compactación, se ejecutará a través de un operador de compactación adicional.
Durante las pruebas, nos encontramos con los siguientes problemas:
- En un escenario con una gran cantidad de datos, todas las relaciones de asignación entre las claves principales y los ID de archivo existirán en el estado. El volumen del estado se expande muy rápidamente, lo que genera una sobrecarga de almacenamiento adicional y, a veces, provoca el problema del tiempo de espera del punto de control.
- El segundo problema es que durante Checkpoint, Hudi Client tiene operaciones pesadas, como fusionarse con el archivo base subyacente. Esta operación implica leer, deduplicar y escribir nuevos archivos a partir de archivos históricos. El jitter de HDFS es propenso al problema del tiempo de espera de Checkpoint.
- El tercer problema es que la tarea de compactación es parte de la tarea de transmisión y los recursos no se pueden ajustar después de que se inicia la tarea.Si se requiere un ajuste, la tarea completa solo se puede reiniciar y la sobrecarga es relativamente grande. la ejecución vacía conduce al desperdicio de recursos, o los recursos insuficientes conducen a la falla de la tarea
Para abordar estos problemas, comenzamos a personalizar optimizaciones para nuestros escenarios.
Solución técnica de optimización personalizada de ByteDance
01 - Capa de índice
El propósito del índice es encontrar la ubicación del archivo donde se encuentra el dato actual. Si existe en el Estado, cada dato implica una lectura y escritura del Estado. En el escenario de una gran cantidad de datos, los costos computacionales y de almacenamiento son relativamente altos.
ByteDance ha desarrollado internamente un índice basado en hash, que puede encontrar la ubicación del archivo mediante el hash directo de la clave principal. Este método puede lograr una indexación global en tablas no particionadas, evitando la necesidad de Estado. Dependencia, después de la transformación, el capa de índice se convierte en una simple operación hash.
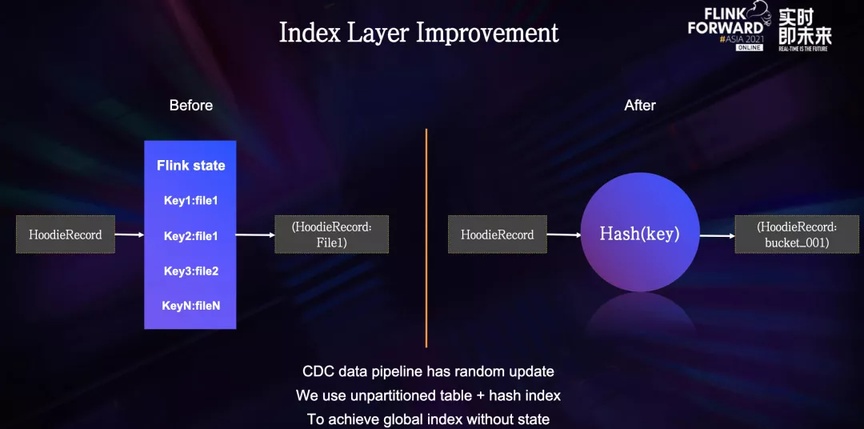
02 - Capa de escritura
La escritura inicial de Hudi estaba fuertemente ligada a Spark. A fines de 2020, la comunidad de Hudi dividió el cliente Hudi subyacente y admitió el motor Flink. Este método de transformación convierte la operación Spark RDD en una operación List, por lo que la capa inferior sigue siendo un lote. Para Flink, la lógica de cálculo que debe realizarse durante cada punto de control es similar a Spark RDD, lo que equivale a ejecutar una operación por lotes, y la carga computacional es relativamente grande.
El proceso específico de la capa de escritura es: después de que una parte de los datos pasa a través de la capa de indexación, llega a la capa de escritura. Los datos primero se acumularán en el búfer de memoria de Flink y, al mismo tiempo, se usará el monitoreo de memoria para evite la falla de la tarea causada por la memoria que excede el límite. Cuando se alcanza el punto de control, los datos se importarán al Cliente Hudi, y luego el Cliente Hudi calculará los datos escritos finales a través de operaciones como Insertar, Agregar, Combinar, etc. Una vez completado el cálculo, el nuevo archivo se escribirá en HDFS y los metadatos se recuperarán al mismo tiempo.
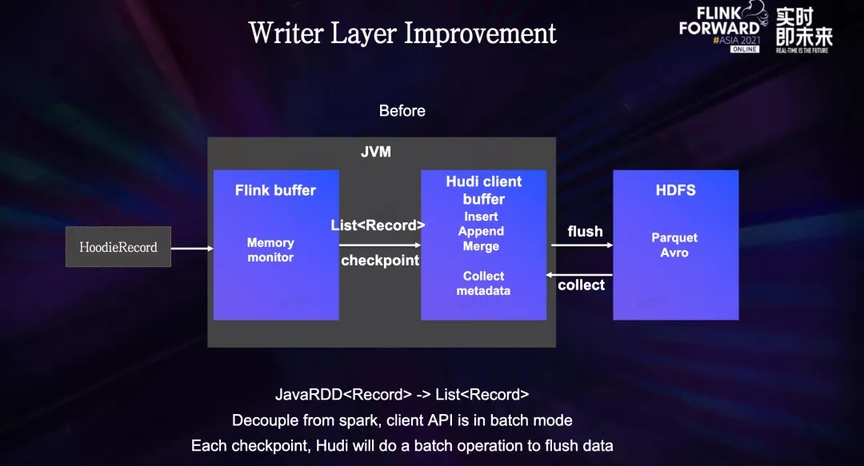
Nuestro objetivo principal es cómo hacer que este modo de escritura de microlotes sea más fluido, reduciendo así la carga computacional durante Checkpoint.
En cuanto a la estructura de la tabla, hemos elegido el formato Merge on Read, que es más compatible con la escritura de transmisión. El operador de escritura solo es responsable de la escritura adicional en el archivo de registro y no realiza ninguna otra operación adicional, como escribir con el archivo base fusionar.
En términos de memoria, eliminamos el búfer de memoria de la primera capa de Flink, construimos directamente el búfer de memoria en el cliente hudi y realizamos un monitoreo de memoria mientras escribíamos datos para evitar que la memoria exceda el límite. operación y Checkpoint están desacoplados. Durante la operación de la tarea, cada pequeño lote de datos se escribirá en HDFS una vez. Dado que HDFS admite operaciones de escritura adicionales, esta forma no provocará el problema de los archivos pequeños, lo que hace que Checkpoint sea tanto como El peso ligero evita el problema del tiempo de espera del punto de control causado por la fluctuación de HDFS y el cálculo excesivo.
03- Capa de compactación
La tarea de compactación es esencialmente una tarea por lotes, por lo que debe dividirse con la escritura de transmisión.Actualmente, Hudi en Flink admite la ejecución asincrónica de compactación, y todas nuestras tareas en línea usan este modo.
En este modo, las tareas de transmisión pueden enfocarse en escribir, mejorar el rendimiento y la estabilidad de escritura, y las tareas de compactación de tipo por lotes pueden desacoplar las tareas de transmisión, escalar de manera elástica para utilizar eficientemente los recursos informáticos y enfocarse en la tasa de utilización de recursos y el ahorro de costos.
Después de esta serie de optimizaciones, probamos en una fuente de datos Kafka de 2 millones de rps, utilizando 200 importaciones simultáneas a Hudi. En comparación con el tiempo anterior, el tiempo del punto de control se ha reducido de 3 a 5 minutos a menos de 1 minuto, y la tasa de fallas de la tarea causada por el jitter de HDFS también se ha reducido considerablemente. Debido a la reducción del tiempo del punto de control, el tiempo real utilizado para el procesamiento de datos se ha vuelto más El rendimiento de datos se duplica, mientras que la sobrecarga de almacenamiento estatal se minimiza.

Este es el diagrama de flujo final de importación de datos de CDC
Primero, diferentes bases de datos enviarán Binlog a la cola de mensajes, y la tarea Flink convertirá todos los datos al formato HoodieRecord, y luego encontrará el ID de archivo correspondiente a través del índice hash. Después de una capa de barajado para el ID de archivo, los datos llegan Al escribir en la capa, el operador de escritura frecuentemente escribe datos en HDFS en forma de escrituras adicionales. Después de que se activa Checkpoint, Flink recopilará todos los metadatos y los escribirá en el sistema de metadatos de hudi. Marca la finalización de un envío de Commit y un nuevo Commit se iniciará en consecuencia.
Los usuarios pueden consultar los datos enviados casi en tiempo real a través de motores de consulta como Flink Spark Presto.
El servicio de Compactación alojado en la plataforma del lago de datos enviará periódicamente la tarea de Compactación en modo Flink Batch para comprimir la tabla Hudi, este proceso es imperceptible para el usuario y no afecta la tarea de escritura.
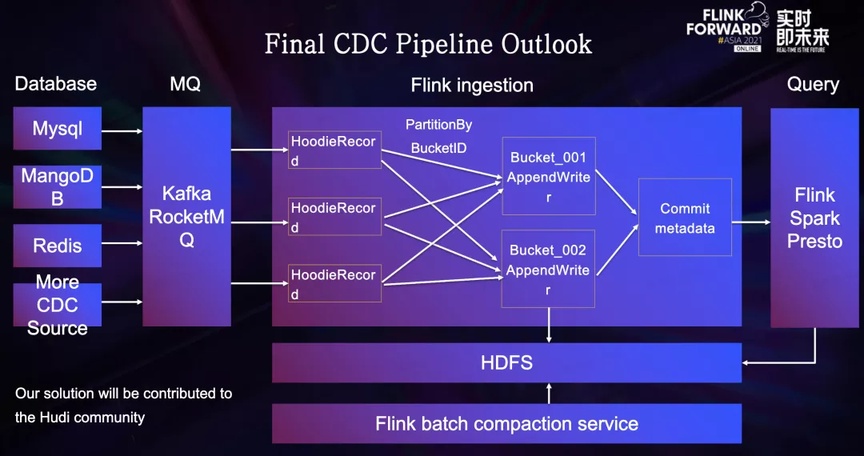
Nuestro conjunto completo de soluciones también se contribuirá a la comunidad, y los estudiantes interesados pueden seguir los últimos desarrollos en la comunidad de Hudi.
Escenarios de aterrizaje típicos del marco de integración del lago de datos de transmisión
Después de la transformación del marco de integración del lago de datos de transmisión, encontramos algunos escenarios de aterrizaje típicos:
La aplicación más común es el escenario de importar una base de datos en línea a un almacén de datos fuera de línea para su análisis.En comparación con el enlace fuera de línea de Spark anterior: el retraso de datos de extremo a extremo se ha reducido de más de una hora a 5-10 minutos, y los usuarios pueden realizar operaciones de análisis de datos casi en tiempo real.
En términos de utilización de recursos, simulamos un escenario de importación de Mysql en un almacén de datos fuera de línea para su análisis, y comparamos la solución de importar la transmisión de Flink en Hudi y la fusión fuera de línea de Spark. recursos Ahorre alrededor del 70%.
En el escenario del almacén de datos del volumen de datos de nivel EB de ByteDance, los beneficios que aporta esta mejora en la utilización de recursos son enormes.

Para los usuarios que crean almacenes de datos en tiempo real basados en colas de mensajes y Flink, pueden importar datos en tiempo real de diferentes niveles de almacén de datos en Hudi. Hay muchos casos de actualización de datos de este tipo, por lo que en comparación con Hive, Hudi puede proporcionar una alta eficiencia. y bajo costo Operación Upsert rentable, para que los usuarios puedan consultar la cantidad total de datos casi en tiempo real, evitando una operación de deduplicación.
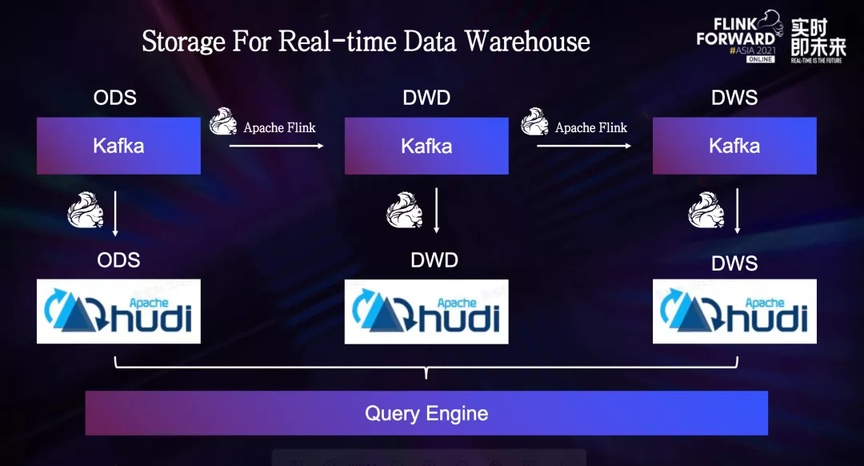
Este es un escenario de Unión de flujo dual de Flink. Muchos usuarios de Flink usarán Unión de flujo dual para el empalme de campo en tiempo real. Al usar esta función, los usuarios generalmente abren una ventana de tiempo y luego combinan los datos de diferentes fuentes de datos en este tiempo. ventana Empalme de datos, esta función de empalme de campo también se puede implementar en el nivel de Hudi.
Estamos explorando una función que solo une los datos de diferentes temas en Flink, y luego escribe los datos de la misma clave principal en el mismo archivo a través del mecanismo de indexación de Hudi, y luego empalma los datos a través de la operación de compactación.
La ventaja de este método es que podemos realizar un empalme de campo global a través del mecanismo de indexación de Hudi sin estar limitado por una ventana.
Toda la lógica de empalme es implementada por HoodiePayload. Los usuarios pueden simplemente heredar HoodiePayload y luego desarrollar su propia lógica de empalme personalizada. El tiempo de empalme puede ser una tarea de compactación o una consulta de combinación en lectura casi en tiempo real. uso de recursos informáticos. Sin embargo, en comparación con Flink Dual-Stream Join, este modo tiene una desventaja, es decir, el rendimiento en tiempo real y la facilidad de uso son peores.
Epílogo
Después de esta serie de trabajos, estamos llenos de expectativas sobre el futuro del lago de datos, y también establecemos objetivos claros.
En primer lugar, esperamos utilizar Hudi como almacenamiento subyacente para todas las fuentes de datos de CDC, reemplazar por completo el esquema de fusión fuera de línea basado en Spark y transmitir la importación a través del motor de integración de datos, brindando capacidades de análisis fuera de línea casi en tiempo real a todas las bases de datos en línea. .
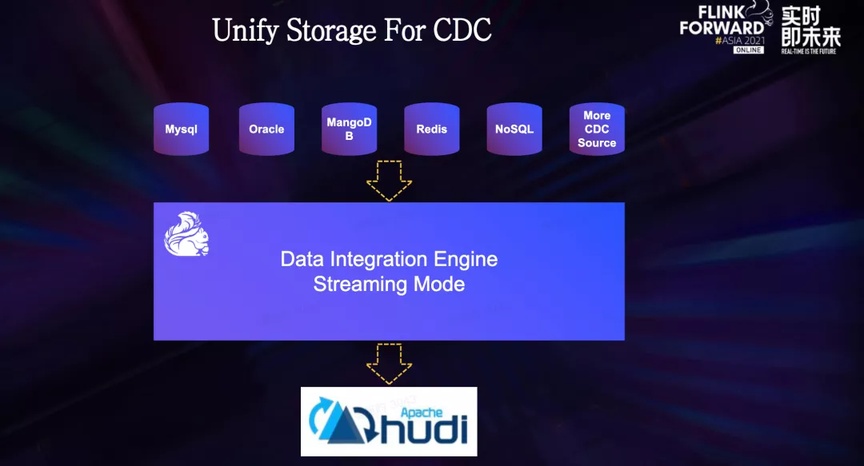
A continuación, el escenario de ETL incremental también es un escenario de aterrizaje importante. Para escenarios en los que la tolerancia de retraso de datos está en el nivel de un minuto, Hudi puede servir como un almacenamiento unificado tanto para enlaces en tiempo real como fuera de línea, actualizando así el almacén de datos Lambda tradicional. arquitectura a una verdadera integración flujo-lote.

Finalmente, esperamos construir una plataforma de lago de datos inteligente, que alojará la gestión de operación y mantenimiento de todos los lagos de datos y logrará un estado de autogobierno, para que los usuarios no tengan que preocuparse por la operación y el mantenimiento.
Al mismo tiempo, esperamos proporcionar la función de ajuste automático para encontrar los mejores parámetros de configuración en función de la distribución de datos, como la compensación de rendimiento entre los diferentes índices mencionados anteriormente, esperamos encontrar la mejor configuración a través de algoritmos. mejorando así la utilización de los recursos y reduciendo el umbral de uso de los usuarios.
Una excelente experiencia del usuario también es una de nuestras metas. Esperamos lograr una entrada con una sola tecla en el almacén en el lado de la plataforma, lo que reducirá en gran medida el costo de desarrollo de los usuarios.

La tecnología de integración del lago de datos también se ha abierto al mundo exterior a través de DataLeap, la suite de gobierno de I+D de big data de Volcano Engine .
Bienvenido a la cuenta pública del mismo nombre de la plataforma de datos ByteDance