prefacio
Este artículo pertenece a la columna "Sistema teórico de Big Data". Esta columna es original del autor. Indique la fuente de la cita. Señale las deficiencias y errores en el área de comentarios, ¡gracias!
Para conocer la estructura de directorios y las referencias de esta columna, consulte Big Data Theory System
mapas mentales

base de datos
El almacén de datos es una recopilación de datos 面向主题(orientada a temas), 集成(integrada),
相对稳定(no volátil), (variable en el tiempo).反映历史变化
El objetivo principal de un almacén de datos es proporcionar datos consistentes, confiables y de fácil acceso
para respaldar la toma de decisiones y el análisis comercial.
Puede ayudar a las empresas a comprender su negocio, mercado y clientes,
y brindar soporte para la toma de decisiones y capacidades de análisis predictivo.
Los almacenes de datos se utilizan ampliamente en inteligencia comercial y análisis de datos.
Para obtener más información sobre los almacenes de datos, consulte mi blog: ¿ Qué es un almacén de datos?
Consulte mi blog sobre inteligencia comercial: ¿qué es inteligencia comercial (BI)?
Base de datos VS Almacén de datos
| la diferencia | base de datos | base de datos |
|---|---|---|
| objetivos de diseño | Apoyar las operaciones comerciales diarias de la empresa. | Apoyar la toma de decisiones y el análisis de la empresa |
| estructura de datos | diseño orientado a la aplicación | diseño orientado a temas |
| Método de procesamiento de datos | Modo de procesamiento de transacciones en línea ( OLTP) |
Modo OLAP ( OLAP) |
| rango de datos | datos de estado actual | Almacene datos históricos y completos que reflejen los cambios históricos |
| cambio de datos | Admite operaciones frecuentes de adición, eliminación, modificación y consulta | Se puede agregar, no eliminar, no cambiar y refleja los cambios históricos |
| teoría del diseño | Siga los tres paradigmas y evite la redundancia | Violación de la forma normal, redundancia apropiada |
| Capacidad de procesamiento | Frecuente, lote pequeño, alta simultaneidad, baja latencia | Infrecuente, de alto volumen, alto rendimiento, retrasado |
Para obtener detalles sobre la comparación entre bases de datos y almacenes de datos, consulte mi blog: ¿ la diferencia entre almacenes de datos y bases de datos?
OLTP frente a OLAP
| Compara artículos | OLTP | OLAP |
|---|---|---|
| usuario | Operadores, gerentes de bajo nivel | tomadores de decisiones, altos directivos |
| Función | Operaciones diarias | decisión de análisis |
| diseño de base de datos | Basado en el modelo ER, orientado a la aplicación | Modelos de estrellas/copos de nieve/constelaciones, orientados al sujeto |
| Tamaño de la base de datos | GB a TB | ≥ TB |
| datos | actualizado, detallado, bidimensional, discreto | histórico, agregado, multidimensional, integrado |
| tamaño de almacenamiento | Leer/escribir varios (incluso cientos) registros | Leer millones (o incluso cientos de millones) de registros |
| Frecuencia de operación | muy a menudo (en segundos) | Relativamente suelto (por hora o incluso por semana) |
| unidad de trabajo | asuntos estrictos | consulta compleja |
| Número de usuario | cientos a decenas de millones | varios a cientos |
| medida | rendimiento de la transacción | Rendimiento de consultas, tiempo de respuesta |
Para obtener detalles sobre la comparación entre OLTP y OLAP, consulte mi blog: ¿ la diferencia entre OLTP y OLAP?
estratificación del almacén de datos
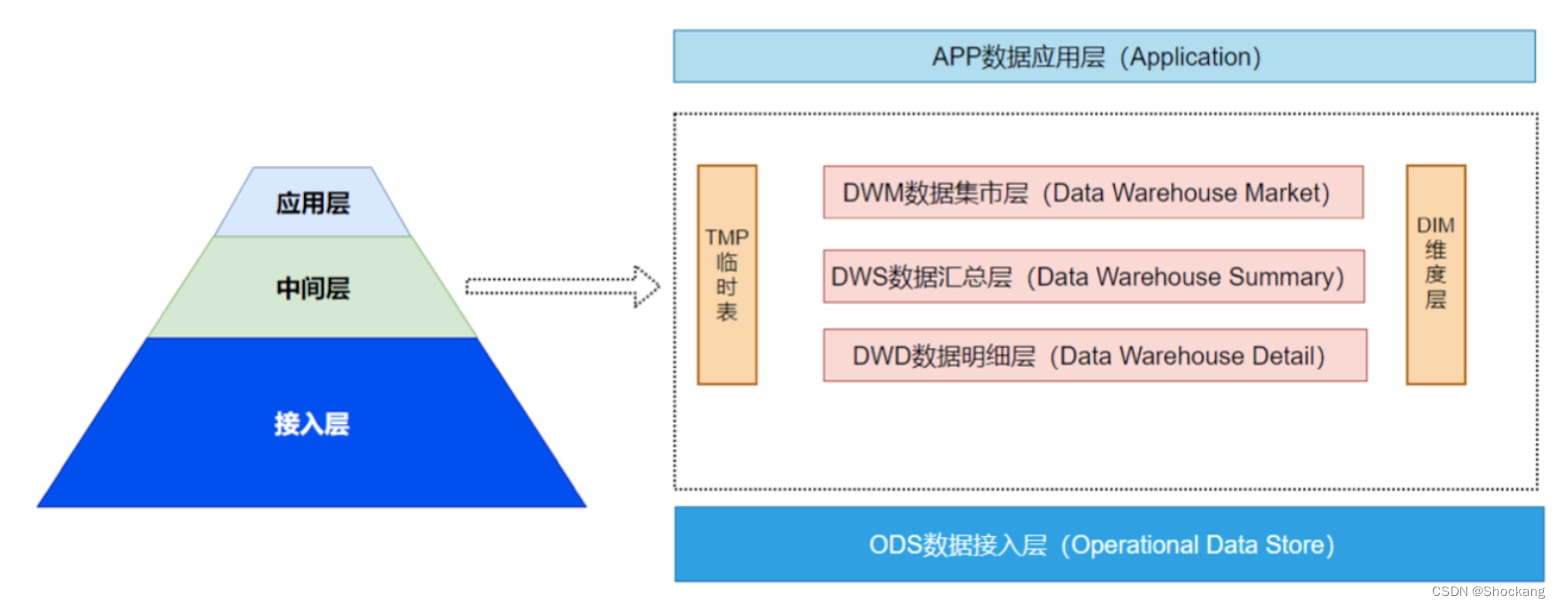
Para obtener más información sobre las capas del almacén de datos, consulte mi blog: ¿ Cómo se organiza en capas el almacén de datos?
Modelado de almacén de datos
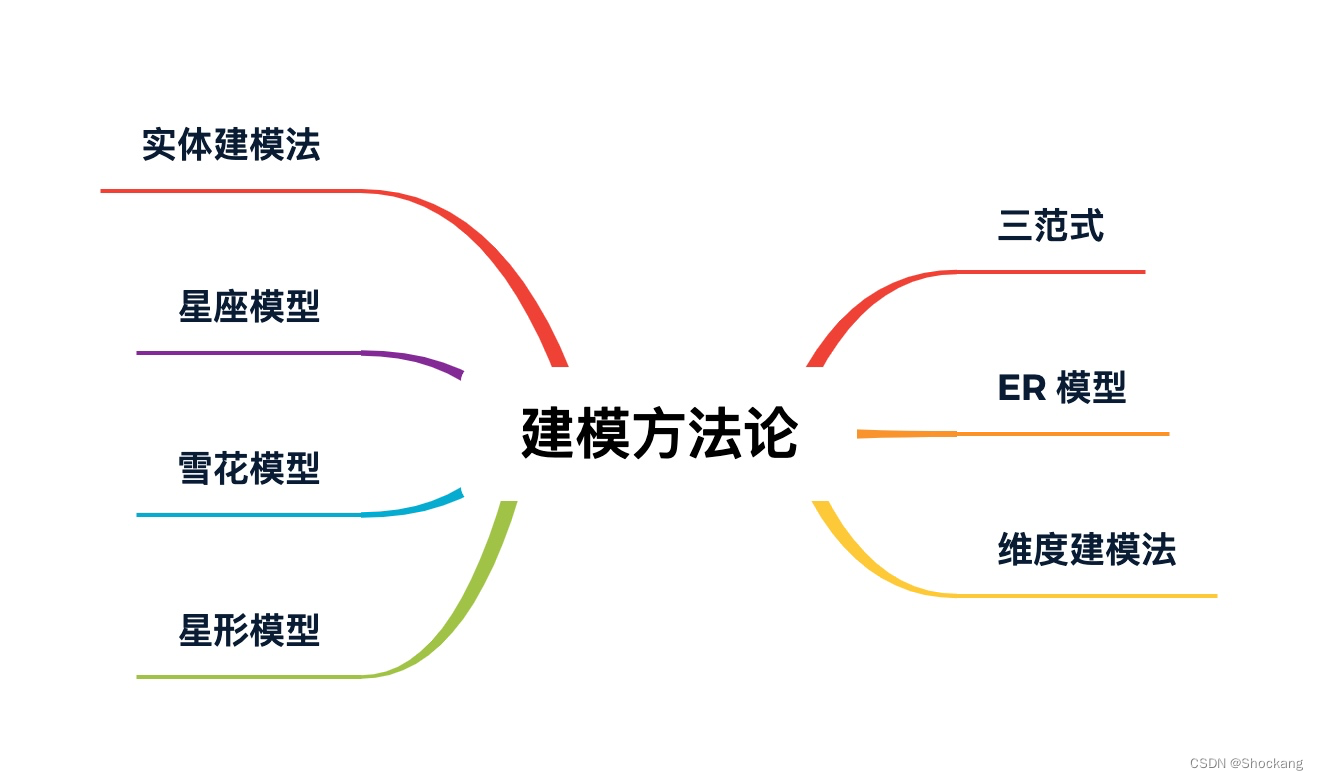
Para obtener detalles sobre la metodología de modelado, consulte mis siguientes 2 blogs:
mercado de datos
Un data mart es un subconjunto de un almacén de datos especializado para una unidad comercial o área temática en particular.
Se enfoca en almacenar una pequeña porción de los datos seleccionados de una empresa en un sistema de almacenamiento más grande
y obtiene datos de menos fuentes que un almacén de datos.
Para obtener más información sobre los data marts, consulte mi blog: ¿ qué es un data mart? ¿Cuál es la diferencia entre data mart y data warehouse?
Si el almacén de datos se considera como la recopilación de datos de toda la empresa, el data mart puede considerarse como uno de los departamentos, que solo es responsable de procesar los datos de negocios específicos.
Data Mart vs Almacén de datos
Un almacén de datos es un repositorio para toda la empresa que contiene datos integrados de diferentes negocios, sistemas y departamentos. Se basa en un modelo de datos de toda la empresa y se enfoca en temas de toda la empresa.
Las características de un almacén de datos incluyen:
- Cobertura en toda la empresa: el almacén de datos proporciona apoyo a la toma de decisiones para departamentos y operaciones en toda la empresa.
- Datos integrados: el almacén de datos reúne datos de varias empresas, sistemas y departamentos y, a través de la limpieza, integración y transformación de datos, satisface las necesidades de análisis e informes de la empresa.
- Arquitectura de nivel empresarial: un almacén de datos es una solución de nivel empresarial, generalmente diseñada, construida y mantenida por un equipo profesional.
- Tema orientado a la empresa: el tema del almacén de datos está relacionado con el funcionamiento de toda la empresa, como ventas, clientes, cadena de suministro, etc.
Data Mart es un depósito de datos temáticos para un dominio comercial específico o unidad funcional. Por lo general, es departamental y brinda apoyo a la toma de decisiones a los gerentes dentro de un área local.
Las características de un data mart incluyen:
- Aplicación a nivel de departamento: el data mart atiende principalmente las necesidades comerciales de un departamento específico o unidad funcional y proporciona análisis de datos e informes para el departamento.
- Tema orientado al departamento: El tema del data mart está relacionado con un negocio específico o unidad funcional, como el rendimiento de ventas, marketing, finanzas, etc.
- Fuente de datos: la fuente de datos del data mart se puede obtener del almacén de datos (data mart subordinado) o de varios sistemas de producción (data mart independiente).
- Escala relativamente pequeña: la escala del data mart suele ser del orden de decenas de gigabytes, que es relativamente pequeña en comparación con el almacén de datos.
A continuación se muestra una tabla que describe la diferencia entre un almacén de datos y un data mart:
| base de datos | mercado de datos | |
|---|---|---|
| Ámbito de aplicación | toda la empresa | departamento específico o unidad funcional |
| Fuentes de datos | Integre datos de diferentes negocios, sistemas y departamentos | Disponible desde el almacén de datos o desde cada sistema de producción |
| escala | Más grande (clase empresarial) | relativamente pequeño (nivel departamental) |
| arquitectura | Arquitectura empresarial | estructura departamental |
| tema | Para temas empresariales | tema departamental |
| Objetivo | Soporte de decisiones para todos los departamentos de la empresa | Apoyo a la toma de decisiones para sectores específicos |
| Función | Proporcione informes y análisis de datos de toda la empresa | Proporcionar informes y análisis de datos a nivel de departamento |
lago de datos
Un lago de datos es un método organizativo para almacenar datos diversos y a gran escala . Puede almacenar datos de alta calidad. Es un almacén de almacenamiento de datos flexible y a gran escala que puede integrar todas las fuentes de datos de una empresa .结构化非结构化半结构化
Para obtener más información sobre los lagos de datos, consulte mi blog: ¿ Qué es un lago de datos? ¿Por qué necesita un lago de datos?
datos estructurados, semiestructurados y no estructurados
Los datos estructurados, semiestructurados y no estructurados son diferentes tipos de clasificación de datos.
-
Datos estructurados: los datos estructurados se refieren a los datos que se pueden representar y almacenar mediante una base de datos relacional, generalmente en
二维表forma de . Los datos estructurados tienen las siguientes características:- Los datos están en unidades de filas, cada fila de datos representa la información de una entidad y los atributos de cada fila son los mismos.
- Los datos se pueden representar mediante una estructura unificada, como números, símbolos, etc.
- Los datos se pueden implementar en una representación lógica de una estructura de tabla bidimensional, incluidos atributos y tuplas. Por ejemplo, una transcripción podría ser un atributo y una puntuación de 90 podría ser una tupla correspondiente.
- Hay ciertas reglas en el almacenamiento y la disposición, que son convenientes para operaciones como consulta y modificación.
-
Datos semiestructurados: los datos semiestructurados son una forma de datos estructurados que no se ajustan completamente a las especificaciones de los datos relacionales. Los datos semiestructurados tienen las siguientes características:
- Los datos semiestructurados tienen datos y estructura, pero la estructura no es estrictamente fija.
- Los datos semiestructurados pueden usar varios formatos de representación de datos, como
XML,JSONetc. - La estructura de los datos puede variar de un registro a otro, pero todavía es algo analizable y organizado.
- Los datos semiestructurados se encuentran comúnmente en escenarios como datos web, archivos de registro y archivos de configuración.
-
Datos no estructurados: los datos no estructurados se refieren a datos sin una estructura y formato fijos, y por lo general no se pueden almacenar ni representar en forma de una base de datos relacional. Los datos no estructurados tienen las siguientes características:
- Los datos no tienen una estructura organizativa clara y pueden ser gratuitos , y
文本otras formas de datos.图像音频视频 - Los datos no estructurados no son adecuados para el almacenamiento y la gestión mediante bases de datos relacionales tradicionales.
- El análisis y procesamiento de datos no estructurados requiere el uso de tecnologías y herramientas específicas, como procesamiento de lenguaje natural, procesamiento de imágenes, procesamiento de audio, etc.
- Los datos no estructurados se encuentran comúnmente en el contenido de las redes sociales, correos electrónicos, documentos, archivos multimedia y más.
- Los datos no tienen una estructura organizativa clara y pueden ser gratuitos , y
En resumen, los datos estructurados son datos con una estructura fija y disposición regular, los datos semiestructurados son una forma de datos entre datos estructurados y datos no estructurados, y los datos no estructurados son datos sin una estructura y un formato claros . Estos diferentes tipos de datos requieren diferentes métodos y herramientas para procesar y administrar al analizarlos y procesarlos.
Almacén de datos frente a lago de datos
| parámetro | base de datos | lago de datos |
|---|---|---|
| almacenamiento de datos | datos estructurados | datos estructurados, semiestructurados y no estructurados |
| preparación de datos | Datos limpios y procesados | Datos sin procesar, sin necesidad de preprocesamiento |
| estructura de datos | Esquemas predefinidos con esquema estricto | Sin esquema fijo, los datos se almacenan sin formato |
| finalidad de los datos | Soporte para inteligencia de negocios y análisis | Soporte para análisis exploratorio y aprendizaje automático |
| usuario | Analistas comerciales y usuarios comerciales | Científicos e ingenieros de datos |
| acceso a los datos | consulta SQL | 多种工具和技术,如Apache Spark和Hadoop |
| 数据规模 | 相对较小(相对于数据湖) | 可以存储大规模数据,包括PB级数据 |
| 数据处理方式 | 提取、转换和加载(ETL) | 提取、加载和转换(ELT) |
| 数据处理速度 | 高性能,适合历史数据分析 | 高度灵活,适合实时和流式数据分析 |
| 数据架构 | 星型或雪花型 | 没有特定的数据架构 |
| 成本 | 相对较高,需要预定义模式和规划 | 相对较低,可以存储各种类型的数据 |
数据网格
数据网格(DataMesh)是一个新兴的概念,旨在帮助组织更好地管理和利用分散在不同系统和应用程序中的数据资产。它强调将数据资产转化为可重用、可组合、可交互的数据元素,以支持组织内部和跨组织的业务创新和数字化转型。
DataMesh的核心理念是基于事件驱动的架构,通过将业务事件和数据元素相结合,将数据资产转化为可编程的、可组装的服务和功能。这种方法可以帮助组织更好地理解和利用其数据资产,并支持更高效、更灵活的业务流程和数据处理。
DataMesh还强调数据治理和数据安全,以确保数据的准确性、可靠性和安全性。它提供了一组数据管理和治理工具,以帮助组织更好地管理其数据资产,并确保符合法规和标准的要求。
关于数据网格的详情请参考我的博客——数据网格(Data Mesh)是什么?
数据仓库 VS 数据网格
| 特征 | Data Warehouse(数据仓库) | DataMesh(数据网格) |
|---|---|---|
| 来源 | 传统上,数据仓库是将各种异构数据源集成到一个集中的位置(通常是一个数据库)中。 | 数据网格将数据分散在不同的领域团队中,每个团队负责自己的数据产品。 |
| 数据拥有权 | 数据仓库通常由中央团队负责管理和维护。 | 数据网格将数据拥有权下放给领域团队,每个团队可以自主管理和拥有自己的数据。 |
| 架构 | 数据仓库通常采用集中式架构,将数据集成到一个中心存储中。 | 数据网格采用分布式架构,数据存储在不同的领域团队中,通过标准化的规则和语法进行连接和交互。 |
| 数据冗余性和业务对齐 | 数据仓库通常会合并和整合数据,以消除冗余并满足业务需求。 | 数据网格允许数据在不同的领域团队之间存在冗余,以满足各自的业务需求。 |
| 数据观测性的重要性 | 数据仓库需要观测数据质量,以确保数据的高质量和可靠性。 | 数据网格同样需要观测数据质量,确保数据的可靠性和可发现性。 |
| 目标 | 数据仓库旨在提供一个一致、可信赖的数据源,用于企业的决策支持和分析。 | 数据网格旨在通过领域团队拥有的数据产品,实现更快速的洞察和分析,并推动数据驱动的决策制定。 |
湖仓一体
湖仓一体是一个全新的开放式数据架构,它将数据湖和数据仓库的优势组合在一起,
提供了数据湖的灵活性和可扩展性以及数据仓库的数据管理功能。
这个架构是在数据湖较低成本的数据存储基础设施上构建的,
它不仅保留了数据湖的特点,如存储非结构化数据和半结构化数据,
还可以支持事务、数据治理和数据模型化等功能,这些特点是数据仓库所具备的。
关于湖仓一体的详情请参考我的博客——湖仓一体(Lakehouse)是什么?
数据仓库 VS 湖仓一体
| 特征 | 数据仓库 | 湖仓一体 |
|---|---|---|
| 数据存储方式 | 结构化数据 | 结构化、半结构化和非结构化数据 |
| 数据处理方式 | 批量处理 | 批量处理和实时处理 |
| 数据集成 | 集成的 | 非集成的 |
| 数据模型 | 事实和维度模型 | 没有明确的数据模型 |
| 数据更新频率 | 周期性更新 | 实时或近实时更新 |
| 数据访问方式 | 预定义的查询 | 自助查询 |
| 数据可伸缩性 | 受限制 | 高度可伸缩 |
| 数据安全性 | 严格的访问控制 | 灵活的访问控制 |
| 数据处理工具和技术 | ETL工具和SQL | 大数据处理工具和技术 |
| 目标用户 | 决策者和分析师 | 决策者、分析师和数据科学家 |
总结
数据库、数据仓库、数据集市、数据湖、数据网格和湖仓一体是数据管理和存储的不同解决方案,它们在以下方面有所区别:
- 数据库(Database)是一个存储相关数据的地方,用于捕获特定情况的数据。它可以是结构化、关系型、非结构化或NoSQL数据库。数据库主要用于在线事务处理(
OLTP),处理实时的事务数据,并具有特定的目的和应用。 - 数据仓库(Data Warehouse)是组织的核心分析系统,用于存储历史数据和支持数据分析。数据仓库与操作数据存储(Operational Data Store,ODS)一起工作,将各种数据库中的数据捕获并统一存储在一个位置。数据仓库采用提取-转换-加载(Extract-Transform-Load,ETL)或类似的ELT过程,将数据从数据库中提取出来,经过转换和清洗后加载到数据仓库中。数据仓库通常使用SQL查询数据,并使用表、索引、键、视图和数据类型进行数据组织和完整性。数据仓库主要用于在线分析处理(
OLAP),支持企业内部的数据分析和商业智能。 - 数据集市(Data Mart)是数据仓库的子集,为
特定的业务部门或业务单元提供数据支持。数据集市通常是针对特定需求进行建立的,以满足某个部门的数据分析和决策需求。数据集市包含在数据仓库中,其中的数据集是为了实时分析和行动结果而使用。 - 数据湖(Data Lake)是一个用于存储原始数据的大型存储库,可以存储
结构化、半结构化和非结构化数据。数据湖接收来自不同来源的数据,而不对其进行特定格式的转换和处理。数据湖存储的数据可以在需要时进行处理和分析。数据湖适用于需要存储大量原始数据,并进行灵活的数据分析和探索的场景。 - 数据网格(DataMesh)是一种数据组织和架构的概念,旨在实现
数据的自治和共享。DataMesh鼓励将数据所有权和管理责任下放给数据所有者,以便更好地支持跨组织和跨团队的数据共享和协作。 - 湖仓一体(LakeHouse)是将
数据湖和数据仓库集成在一起的解决方案。它结合了数据湖的灵活性和数据仓库的结构化分析能力,使得用户可以同时进行原始数据探索和历史数据分析。
综上所述,数据库主要用于在线事务处理,数据仓库用于存储历史数据和支持数据分析,数据集市是数据仓库的子集,满足特定业务部门的需求,数据湖存储原始数据并支持灵活的数据分析,数据网格鼓励数据自治和共享,湖仓一体则是将数据湖和数据仓库集成在一起的解决方案。
下面是一个表格,描述了数据库、数据仓库、数据集市、数据湖、数据网格和湖仓一体之间的主要区别:
| 数据库(Database) | 数据仓库(Data Warehouse) | 数据集市(Data Mart) | 数据湖(Data Lake) | 数据网格(DataMesh) | 湖仓一体(LakeHouse) | |
|---|---|---|---|---|---|---|
| 定义 | 存储相关数据的地方 | 存储历史数据和支持数据分析 | 针对特定业务部门的数据子集 | 存储原始数据的大型存储库 | 数据的自治和共享 | 将数据湖和数据仓库集成的解决方案 |
| 用途 | 在线事务处理(OLTP) | 在线分析处理(OLAP) | 特定业务部门的数据分析和决策支持 | 灵活的数据分析和探索 | 跨组织和跨团队的数据共享和协作 | 原始数据探索和历史数据分析 |
| 数据类型 | 结构化、关系型、非结构化、NoSQL | 结构化 | 结构化 | 结构化、半结构化、非结构化 | 结构化、半结构化、非结构化 | 结构化、半结构化、非结构化 |
| 数据处理 | 实时事务数据处理 | 提取-转换-加载(ETL)或类似ELT过程 | 针对特定需求的数据提取和整合 | 原始数据存储,按需处理和分析 | 数据所有者自治,分布式数据共享 | 结合原始数据探索和历史数据分析 |
| 查询 | SQL查询 | SQL查询 | SQL查询 | 按需处理和分析 | 分布式数据查询和共享 | 结合原始数据探索和历史数据分析 |
| 数据组织 | 表、索引、键、视图、数据类型 | 表、索引、键、视图、数据类型 | 表、索引、键、视图、数据类型 | 灵活的数据组织 | 分布式数据组织和架构 | 灵活的数据组织 |
| 数据共享 | 有限的共享能力 | 针对特定用户和部门的共享 | Uso compartido para unidades comerciales específicas | Énfasis en compartir entre organizaciones y equipos | Énfasis en la autonomía y el intercambio de datos | Combinando las capacidades de intercambio de lagos de datos y almacenes de datos |
| análisis de los datos | Análisis de datos transaccionales en tiempo real | Análisis de datos históricos e inteligencia de negocios | Análisis de datos y soporte de decisiones para unidades de negocio específicas | Análisis y exploración de datos flexibles | Análisis de datos y colaboración entre organizaciones y equipos. | Combine la exploración de datos sin procesar y el análisis de datos históricos |