Guía: Con el lanzamiento de Bert, el entrenamiento previo (pre-entrenamiento) se ha convertido en una de las direcciones más populares en el campo de la PNL. El corpus no supervisado a gran escala más una pequeña cantidad de corpus etiquetado se ha convertido en la configuración estándar de los modelos de PNL. Este artículo presentará los principios básicos y los métodos de uso de varios modelos de lenguaje comunes, así como la práctica de los modelos de lenguaje en el negocio de NLP de Netease Yanxuan, incluida la clasificación, la coincidencia de texto, el etiquetado de secuencias, la generación de texto, etc.
01
Prefacio
La representación de texto ha pasado por un largo proceso de desarrollo, desde el modelo de bolsa de palabras de arco más simple y clásico, el modelo de tema representado por LDA, el modelo de vector denso representado por word2vec, hasta el modelo de lenguaje general representado por Bert. Las palabras son expresiones de texto detalladas y, aunque los primeros vectores de palabras preentrenados son simples y fáciles de usar, no pueden resolver el problema de la polisemia. En los últimos años, basado en corpus de contexto a gran escala, el modelo de lenguaje general entrenado puede producir vectores de representación semántica más detallados, y la misma palabra puede extraer diferentes vectores semánticos en diferentes contextos.
En tareas comunes comunes de PNL, la anotación de datos es un enlace indispensable e importante. La magnitud y la calidad de los datos afectarán directamente el efecto de la tarea. En condiciones realistas, el costo del etiquetado de datos suele ser muy alto, pero afortunadamente tenemos una gran cantidad de corpus sin etiquetar. Por lo tanto, se ha convertido en una tendencia de desarrollo entrenar un modelo de lenguaje de propósito general basado en un corpus masivo no supervisado y luego marcar una pequeña cantidad de datos para diferentes tareas de NLP antes de ajustar el modelo.
02
Estructura del modelo
Seleccionamos los tres modelos de lenguaje más representativos: ELMO[1], GPT[2], BERT[3] para comparar, como se muestra en la siguiente tabla.
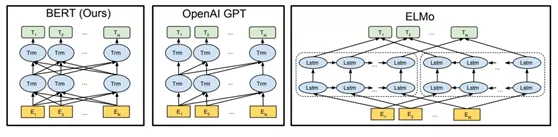
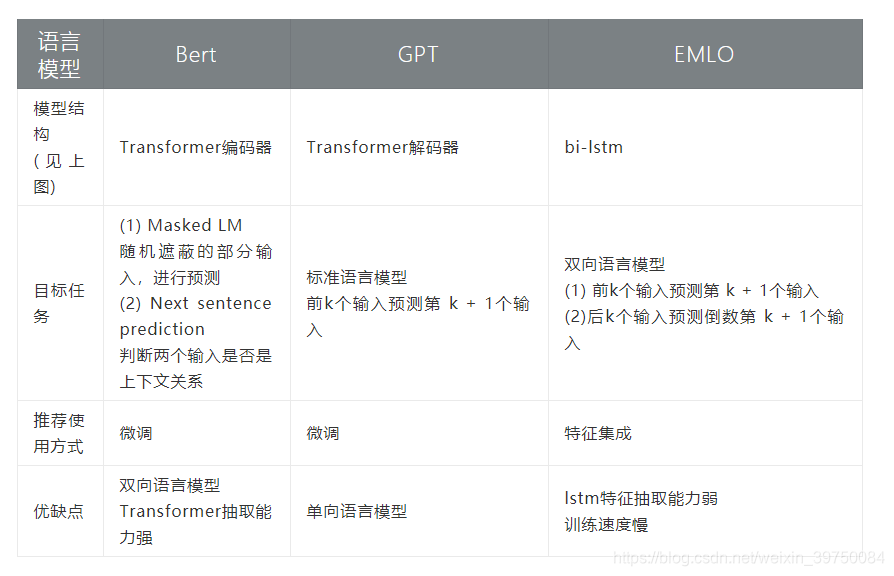
La red lstm utilizada por ELMO y la estructura de red utilizada por gpt y BERT son transformadores. Transformer es un mecanismo de autoatención propuesto en el artículo de Google de 17 años "la atención es todo lo que necesitas" [4], que reemplaza a las tradicionales RNN y CNN para la extracción de características semánticas y ha logrado excelentes resultados en la traducción automática.
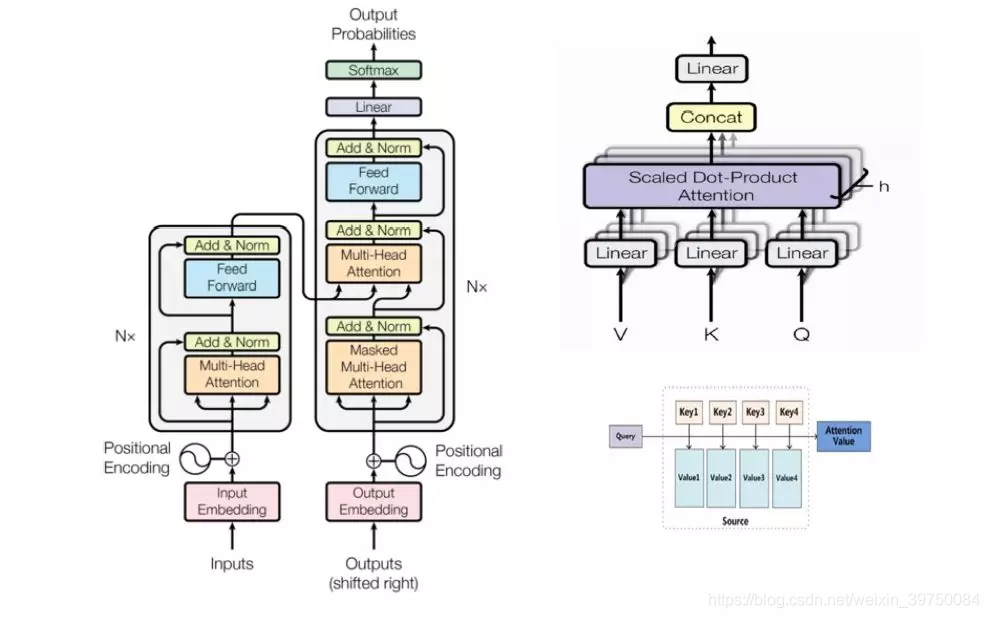
Transformer usa el modo seq2seq estándar (que se muestra en la figura de la izquierda arriba), y la parte de extracción de funciones clave usa un mecanismo de autoatención de múltiples toques (que se muestra en la figura de arriba a la derecha). El llamado multi-tap se refiere al proceso en el que múltiples mecanismos de autoatención se paralelizan y finalmente se unen en una salida. El mecanismo de atención utiliza la atención del producto escalar (que se muestra en la figura superior derecha e inferior).
El mecanismo de atención de la multiplicación de puntos tiene principalmente los siguientes cuatro pasos:
mapa de consulta a (clave, valor)
Calcular el peso entre la consulta y cada clave
Normalización del peso de la función Softmax
Peso y valor para la sumatoria ponderada
La autoatención significa que Q, K y V son todos iguales, y todos son de entrada

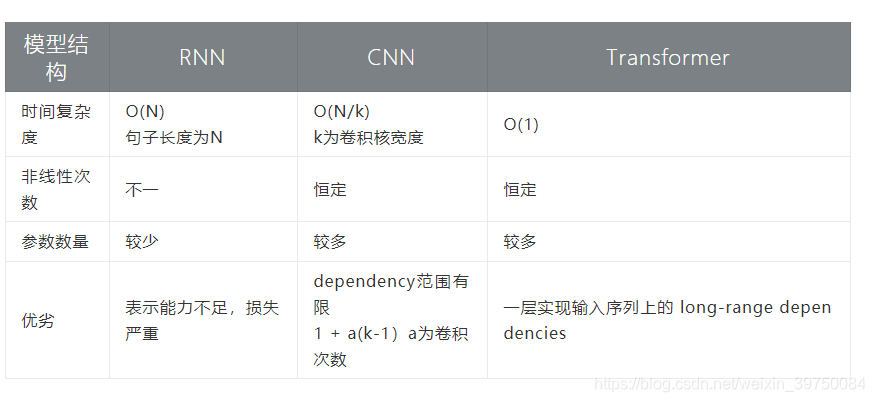
La comparación de tres métodos comunes de extracción de características de RNN CNN Transformer se resume en la siguiente tabla.
03
Cómo usar
- Modo de aplicación
Cuando se aplica el modelo de lenguaje previamente entrenado a nuevas tareas de PNL, existen los siguientes dos modos de aplicación.

Lógicamente hablando, varios modelos de lenguaje se pueden utilizar de estas dos maneras, así que, cómo elegir, algunos estudios [5][6][7] arrojaron las siguientes conclusiones:
Para ELMO, la aplicación de la integración de funciones es más estable que el ajuste fino;
Tareas de coincidencia de oraciones (ingresar varias oraciones), el efecto de ajuste fino de Bert es significativamente mejor que la integración de características;
Para otros tipos de tareas, al aplicar Bert, el modo de ajuste fino es ligeramente mejor que el modo de integración de funciones, o ambos tienen efectos similares.
- Representación de características
Este tipo de modelo de lenguaje es un empalme de red de múltiples capas, por lo que cuando lo usamos, también hay dos métodos de representación de características.
Use solo funciones de nivel superior
Funciones ponderadas de varias capas
La investigación anterior arrojó las siguientes conclusiones:
ELMO da sugerencias de uso en el texto original. Para diferentes tareas, use diferentes vectores de peso para ponderar las características de cada capa y multiplicarlas por el factor de escala correspondiente.
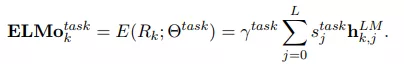
Para tareas de NLP de múltiples entradas, como la coincidencia de oraciones, es más fácil usar las funciones de más alto nivel directamente y el efecto es el mejor.
Para tareas de etiquetado de secuencias, la fusión de características multicapa puede ser más adecuada para escenarios de aplicación.
04
práctica
- Clasificación
La clasificación es una de las tareas más comunes en la PNL, entre las que se incluyen el análisis de sentimientos y la clasificación de textos, que hemos cubierto.
Análisis de sentimientos: como el análisis de las emociones en los comentarios de los usuarios o las sesiones de atención al cliente de los usuarios, es necesario apaciguar a los usuarios con emociones negativas graves.
Reconocimiento de intención: por ejemplo, en el servicio de atención al cliente inteligente, después de que llega la pregunta del usuario, primero se debe reconocer la pregunta del usuario para determinar si la pregunta del usuario es "preguntas relacionadas con la posventa", "preguntas de conocimiento del producto de preventa" o simplemente "chateando" u otros tipos, y luego se distribuyen a diferentes módulos para obtener respuestas y respuestas.
Los modelos de algoritmos para la clasificación de texto se usan comúnmente en varias estructuras de red como rnn o cnn integradas en el mecanismo de atención. Cuando construimos el sistema de clasificación de reconocimiento de intenciones de servicio al cliente inteligente de Yanxuan, adoptamos la estructura del modelo ABL (attention bi-lstm). Aprenda el método de codificación en "todo lo que necesita es atención" [4:1]. Además de la codificación semántica, agregue incrustación de posición (codificación de posición) para representar mejor las oraciones.
Sobre la base del uso del ajuste fino de bert, la prueba se llevó a cabo en el modelo de clasificación de procesos comerciales del módulo inteligente de reconocimiento de intención de servicio al cliente de Yanxuan. La evaluación del rendimiento en el mismo equipo de prueba se muestra en la siguiente tabla.

Se puede observar que
en la tarea de clasificación de textos, la mejora aportada por bert es relativamente limitada. La razón puede ser que la tarea de clasificación no requiere características semánticas profundas. Las características semánticas capturadas por los métodos tradicionales ya pueden resolver mejor el problema de clasificación y no pueden ejercer el poder del modelo de lenguaje pre-entrenado.
La ventaja es que bert puede obtener una mejor capacidad de generalización con menos muestras y reducir el costo del etiquetado manual, pero al mismo tiempo necesita pagar más recursos informáticos.
- Representación de texto
En muchos casos, necesitamos convertir oraciones en espacio vectorial para obtener una representación.
Cuando se realiza un cálculo no supervisado de la similitud entre dos textos o un análisis de conglomerados de textos, es necesario extraer las características del texto Además de las características tradicionales, las características semánticas también son un componente importante.
Al responder las preguntas frecuentes de los usuarios, generalmente se requieren dos procesos de recuperación y clasificación. Recuperación Además de la recuperación literal (como BM25), puede utilizar los vectores de preguntas frecuentes estándar almacenados previamente para realizar la recuperación semántica (como ANN).
En el ejemplo oficial dado por Google, lo que obtiene bert es la salida incrustada por cada token (palabra) en cada capa de las últimas cuatro capas. Si necesita obtener un vector de oración, debe realizar una combinación ponderada de cada token y el vector de cada capa.
En el uso real, encontramos que el vector de oración obtenido al ponderar solo el vector de token de salida de la penúltima capa tiene el mejor efecto de coincidencia. La razón puede ser que el vector semántico de la salida de la capa más alta de bert está orientado a dos tareas objetivo previamente entrenadas, mientras que el vector de la penúltima capa está más cerca del significado de la oración en sí. En la tarea de representación del texto, no se afinará el modelo original, y solo se requiere la representación del significado de la oración en sí.
- Coincidencia de texto La
coincidencia de texto es un tipo muy clásico de tarea de PNL, el nombre completo es Inferencia de lenguaje natural, la tarea se define como: dada una premisa, inferir la relación entre la hipótesis y la premisa. La relación se divide en tres categorías: vinculación, contradicción y neutral. En el campo de la respuesta automática a preguntas, la tecnología NLI se aplica a menudo en tareas de discriminación de similitud de oraciones y discriminación de correlación de oraciones de pregunta y respuesta.
Desde el Siamese-LSTM más simple hasta InferNet, Descomposable Attention, ESIM y BERT, el algoritmo de coincidencia de texto también ha sufrido una serie de cambios en la estructura de la red. La aparición de BERT nos ha ayudado a lograr un buen efecto de coincidencia con una pequeña cantidad de muestras etiquetadas.
En el proyecto de servicio al cliente inteligente de Yanxuan, hemos adoptado una variedad de esquemas de coincidencia de preguntas:
La pregunta Q está asociada con la respuesta A
Coincidencia de similitud entre la pregunta Q1 y la pregunta Q2
Asociación de emparejamiento de la pregunta Q con la pregunta estándar QS
Los tres tipos de métodos pueden garantizar respectivamente el efecto de recuerdo similar de la oración de pregunta y el efecto de coincidencia de la asociación pregunta-respuesta En las etapas de coincidencia y clasificación, la estrategia puede ponderarse de manera flexible para la discriminación.
Bajo la estricta selección de datos etiquetados a escala 6W, comparamos el efecto coincidente de Siamese-LSTM y BERT:

De los resultados anteriores, se puede ver que el efecto bert es significativamente mejor que la red gemela. La razón puede ser:
Una de las tareas objetivo de bert en la etapa previa al entrenamiento es predecir si existe una relación contextual entre dos oraciones y aprender el conocimiento de la relación entre oraciones.
El mecanismo de autoatención es mejor para capturar la semántica profunda y puede obtener resultados de coincidencia detallados entre las palabras de la oración A y cualquier palabra de la oración B, lo cual es crucial en las tareas de coincidencia de texto.
- Etiquetado de secuencias El
etiquetado de secuencias es una de las cuatro tareas principales en el campo de la PNL, incluida la segmentación de palabras, el etiquetado de partes del discurso, el reconocimiento de entidades nombradas y otras tareas de PNL. Nos enfocamos principalmente en la tarea de Reconocimiento de entidades nombradas (NER), que tiene como objetivo identificar entidades nombradas comunes, como nombres de personas y nombres de lugares en el corpus.
En el escenario de nuestro servicio al cliente inteligente, la principal preocupación es la entidad del producto, la entidad del nombre del atributo y la entidad del valor del atributo en la pregunta del usuario. Tome la siguiente imagen como ejemplo:
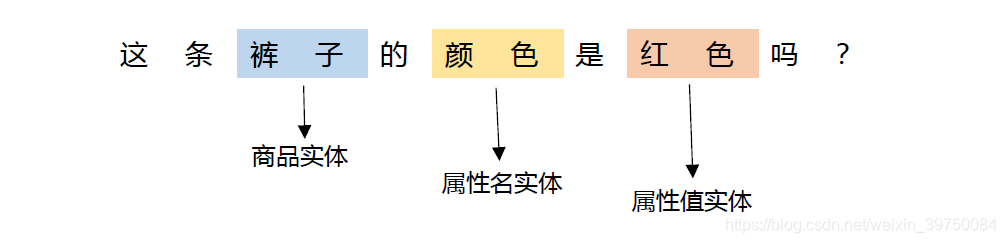
En esta oración, la entidad del producto que le importa al usuario es "pantalones", el nombre del atributo del usuario es "color" y el valor del atributo es "rojo". El propósito de NER es analizar estos tres tipos de entidades de las preguntas del usuario para realizar más análisis y respuestas.
El modelo comúnmente utilizado del algoritmo NER es el LSTM bidireccional más el CRF de campo aleatorio condicional. El primero puede capturar las características del contexto del texto del diálogo, comprender el contexto y extraer completamente la información del contexto. El último se enfoca en el contexto local. información del texto de diálogo actual y extrae de manera efectiva el contexto actual Información semántica del texto de diálogo.
Nuestra primera versión de comercio electrónico NER es un modelo de granularidad de palabras basado en bi-lstm más crf, que sirve al sistema inteligente de servicio al cliente en línea. Luego comparamos los modelos de integración y ajuste de características basados en bert:
Integración de características: conecte la incrustación obtenida en base a bert con el modelo tradicional lstm plus crf
Ajuste fino del modelo: comparación de los efectos de las características de alto nivel y la fusión de características multicapa
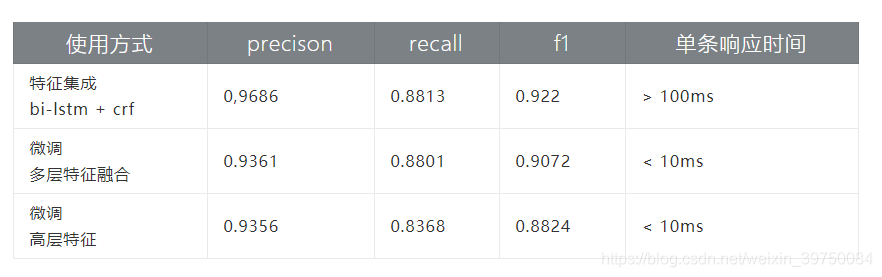
En nuestro conjunto de datos, se pueden obtener los siguientes resultados:
La forma de integración de características es mejor que el ajuste fino. La razón puede ser que agregamos parámetros adicionales (capas bi-lstm y crf) durante la integración de funciones. Esta comparación también se llevó a cabo en el estudio de [5:1]. Los resultados de la comparación muestran que el efecto de agregar parámetros adicionales es mejor que el del modelo sin parámetros adicionales. Si el modelo de ajuste fino también se integra en la capa crf, el efecto de los dos métodos de uso casi. El efecto de agregar parámetros adicionales para lograr la integración de características es significativamente mayor que el del ajuste fino.
El efecto de la fusión de funciones multicapa es mejor que usar solo funciones de alto nivel. Razón Para la tarea de etiquetado de secuencias, no solo necesitamos considerar la representación del significado de la oración, sino también integrar representaciones de otras granularidades de las oraciones.
En términos de tiempo de respuesta, el método de integración de funciones (agregar parámetros adicionales) no puede cumplir con los requisitos en línea y es adecuado para servicios fuera de línea, mientras que el modelo ajustado se puede usar para servicios en línea.
- Tareas generativas
El propio Native Bert no se puede utilizar para tareas generativas, lo que está determinado por sus tareas de destino y la estructura del modelo. Posteriormente se desarrollaron algunos modelos de pre-entrenamiento que pueden ser utilizados para tareas generativas, como MASS [8]. Por supuesto, el texto también se puede generar usando solo un modelo de lenguaje entrenado, como la versión mejorada de gpt[9] presentada anteriormente, basada en corpus a gran escala y modelos enormes, solo usando un modelo de lenguaje unidireccional ha logrado buenos resultados en la generación de artículos El efecto ha llamado la atención de la industria. En escenarios cuidadosamente seleccionados, además de los chatbots, también se intenta utilizar para la generación de copias.
Robot de chismes
El módulo de chat en el servicio de atención al cliente inteligente, además del módulo de respuesta y recuperación de preguntas de personalidad del robot, necesita un modelo generativo para realizar otras preguntas de chat y bromas no configuradas de los usuarios. Recopilamos datos de diálogo externo y construimos un módulo de chat generativo de servicio al cliente inteligente, el efecto se muestra en la figura a continuación.

Debido a los niveles desiguales de expectativas externas, ocasionalmente aparecerán algunas palabrotas y otras respuestas que no se pueden mostrar a los usuarios.
Robot de coplas
Estos son algunos de nuestros intentos durante el Festival de Primavera. Recopilamos 700.000 datos de coplas en Internet y construimos dos formas de robots de coplas para coplas superiores e inferiores, y coplas con cabezas tibetanas. La conexión directa del pareado inferior se puede construir directamente mediante el uso del transformador, mientras que el pareado principal oculto también requiere un modelo de lenguaje para generar el pareado superior basado en el primer carácter.
Dados dos ejemplos:
El segundo pareado:
el pareado superior: El agua del grifo de Shanghái proviene del mar
El segundo pareado: Las hojas de alerce de Zhongshan caen en las montañas
Pareado de cabeza oculta:
Cabeza oculta: NetEase
Shanglian: Wanghua lee como un invitado que regresa a casa por primera vez
El siguiente pareado: Yi Shui escucha la sorpresa y aún no ha regresado
Robot Kua Kua
Este es un juego popular hace algún tiempo. La falta de habilidades lingüísticas de las personas que se jactan puede dejar que los robots lo hagan por ti. Recolectamos algo de corpus en Douban y construimos un Kuwabot basado en dos métodos de recuperación y generación.
El efecto es el siguiente:
P1: Comí muchos bocadillos para presumir
A1: ¡Vaya, vaya, esto es realmente bueno! ¡Ve a comer unos bocadillos para consolarte!
P1: Hay un problema con el código, alardea
A1: ¡Conociendo mis defectos, eso es genial! Te volverás más y más fuerte ~
Generación de textos publicitarios
En escenarios de publicidad y búsqueda cuidadosamente seleccionados, es necesario generar automáticamente textos publicitarios para productos bajo puntos de venta designados. Además de los métodos extractivos tradicionales, también intentamos utilizar modelos de lenguaje previamente entrenados para la generación de copias. Tome una "camisa para niños" como ejemplo para mostrar la copia del punto de venta generada mediante el uso del modelo de lenguaje previamente entrenado.

Entre ellos, cuando bert se usa para tareas generativas, se usa como modelo codificador de seq2seq.
- Otros
Además de las diversas aplicaciones mencionadas anteriormente, los modelos de lenguaje también tienen escenarios de aplicación en otros campos de la PNL, y también lo estamos intentando.
Comprensión de lectura: a diferencia del conocimiento de los atributos de los productos básicos, que es estructurado y estable, el conocimiento de las reglas de actividad en su mayoría no está estructurado y las actividades se actualizan con frecuencia. Es más adecuado para los usuarios utilizar la tecnología de comprensión de lectura para responder a las preguntas de las reglas de actividad.
Resumen de texto: habrá múltiples rondas de interacción entre el usuario y el servicio al cliente, y algunas de las oraciones contienen información valiosa. Podemos utilizar la tecnología de extracción de resúmenes para resumir, organizar y analizar las sesiones de cada sesión.
05
Posdata
Bert ha publicado una gran cantidad de trabajos relacionados desde que salió hace medio año, incluida la aplicación de Bert en varios campos de NLP o varios modelos de lenguaje actualizados (gpt2 [9: 1], MASS [8: 1], Xl- Neto[10], etc.). El corpus no supervisado a gran escala más una pequeña cantidad de corpus etiquetado se ha convertido en la configuración estándar de los modelos NLP. El uso de modelos de lenguaje de código abierto puede resolver el dilema de los recursos informáticos insuficientes y el corpus insuficiente para los usuarios comunes.
Sin embargo, para atender tareas en línea, también es necesario considerar el QPS del modelo y los recursos informáticos requeridos. También se ha desarrollado un modelo de lenguaje ligero preentrenado similar a albert[11] para mejorar la velocidad de la inferencia del modelo y reducir los recursos informáticos dependientes.
Los modelos de lenguaje pre-entrenados son ampliamente utilizados en escenarios de PNL estrictamente seleccionados.Al mismo tiempo, utilizamos técnicas como la destilación de conocimiento para comprimir modelos tan complejos para mejorar la velocidad de la predicción en línea y reducir el consumo de recursos informáticos. Y con la ayuda del aprendizaje de tareas múltiples, deje que los modelos de tareas múltiples compartan la información del modelo de lenguaje previamente entrenado subyacente, mejoren entre sí y mejoren aún más la capacidad de generalización del modelo.
Eso es todo por el compartir de hoy, gracias a todos.
06
Referencias
[1] Peters ME, Neumann M, Iyyer M, et al. Representaciones de palabras contextualizadas profundas [J]. arXiv preprint arXiv:1802.05365, 2018.
[2] Radford A, Narasimhan K, Salimans T, et al. Mejorar la comprensión del lenguaje mediante el preentrenamiento generativo[J]. URL https://s3-us-west-2. amazonas com/openai-assets/research-covers/languageunsupervised/documento de comprensión del idioma. pdf, 2018.
[3] Devlin J, Chang MW, Lee K, et al. Bert: Pre-entrenamiento de transformadores bidireccionales profundos para la comprensión del lenguaje[J]. arXiv preprint arXiv:1810.04805, 2018.
[4] Vaswani A, Shazeer N, Parmar N, et al. Todo lo que necesitas es atención[C]//Avances en los sistemas de procesamiento de información neuronal. 2017: 5998-6008.
[5] Peters M, Ruder S, Smith N A. ¿Afinar o no afinar? Adaptación de representaciones preentrenadas a diversas tareas[J]. preimpresión de arXiv arXiv:1903.05987, 2019.
[6] Qiao Y, Xiong C, Liu Z, et al. Comprender los comportamientos de BERT en Ranking[J]. Preimpresión de arXiv arXiv:1904.07531, 2019.
[7] Kaneko M, Komachi M. Multi-Head Multi-Layer Attention to Deep Language Representations for Grammatical Error Detection[J]. preimpresión de arXiv arXiv:1904.07334, 2019.
[8] Song K, Tan X, Qin T, et al. Masa: Preentrenamiento de secuencia a secuencia enmascarada para la generación de lenguaje[J]. preimpresión de arXiv arXiv:1905.02450, 2019.
[9] Radford A, Wu J, Child R, et al. Los modelos de lenguaje son aprendices multitarea no supervisados[J]. Blog de OpenAI, 2019, 1(8).
[10] Yang Z, Dai Z, Yang Y, et al. XLNet: Preentrenamiento autorregresivo generalizado para la comprensión del lenguaje[J]. preimpresión de arXiv arXiv:1906.08237, 2019.
[11] Lan Z, Chen M, Goodman S, et al. ALBERT: Un BERT ligero para el aprendizaje autosupervisado de las representaciones del lenguaje[J]. preimpresión arXiv arXiv:1909.11942
;
Ji Zhiwei, se graduó de la Universidad de Zhejiang con una maestría en 2018 y luego se unió al Departamento de algoritmos Yanxuan de NetEase. Participó en la construcción del algoritmo del servicio de atención al cliente inteligente de Netease Yanxuan desde cero y brindó soporte de capacidad de algoritmo para el servicio de atención al cliente inteligente de Koala. Comprometidos a combinar nuevas tecnologías en el campo del procesamiento del lenguaje natural con los negocios, potenciando varios escenarios como el servicio al cliente inteligente de Yanxuan, el banco de trabajo de servicio al cliente manual y la inspección de calidad del servicio al cliente.
Al final del artículo, comparte, dale me gusta y mira, haz un triple clic~~
Recomendación de la comunidad:
Bienvenido a unirse al grupo de intercambio de algoritmos de DataFunTalk NLP y comunicarse con sus compañeros a distancia cero. Si desea unirse al grupo, identifique el código QR a continuación y siga las indicaciones para unirse al grupo de forma independiente.
Recomendación de artículo:
Corrección de errores ASR basada en BERT
Sobre nosotros:
DataFunTalk se centra en el intercambio y la comunicación de grandes aplicaciones de tecnología de datos e inteligencia artificial. Lanzado en 2017, ha realizado más de 100 salones, foros y cumbres fuera de línea en Beijing, Shanghái, Shenzhen, Hangzhou y otras ciudades, y ha invitado a casi 500 expertos y académicos a participar en el intercambio. Su cuenta oficial, DataFunTalk, ha producido más de 300 artículos originales, con millones de lecturas y más de 70.000 fans precisos.
