La diferencia entre Bert y GPT
origen
En 2018, Google lanzó por primera vez BERT (Representaciones de codificador bidireccional de transformadores). El modelo se entrena en un gran corpus de texto utilizando una combinación de aprendizaje supervisado y no supervisado. El objetivo de BERT es crear un modelo de lenguaje que pueda comprender el contexto y el significado de una palabra en una oración, teniendo en cuenta las palabras que aparecen antes y después.
En 2018, OpenAI lanzó por primera vez GPT (Transformador preentrenado generativo). Al igual que BERT, GPT también es un modelo de lenguaje preentrenado a gran escala. Sin embargo, GPT es un modelo generativo que es capaz de generar texto por sí solo. El objetivo de GPT es crear un modelo de lenguaje que pueda generar texto coherente y contextualmente apropiado.
la diferencia
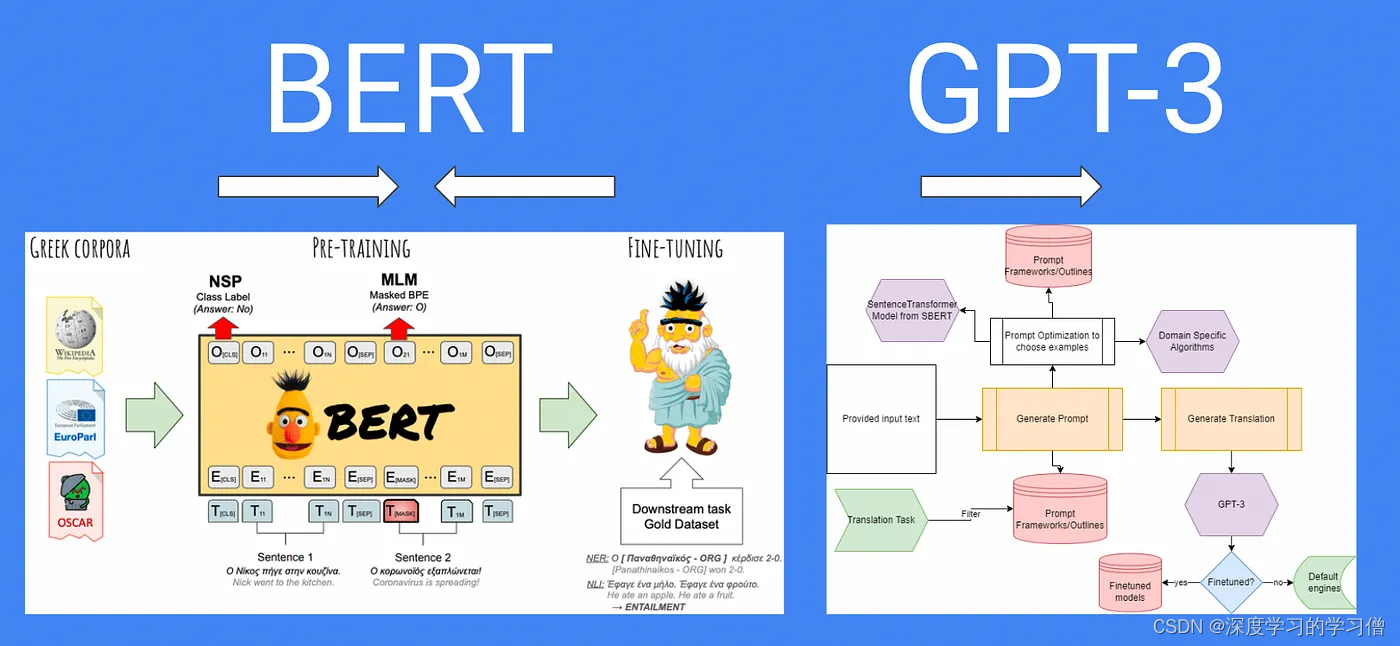
BERT y GPT son dos modelos de lenguaje preentrenado diferentes y tienen algunas diferencias notables en principio y aplicación.
Tarea objetivo:
-
BERT: BERT es un modelo de preentrenamiento basado en Transformer cuyo objetivo es aprender representaciones de palabras dependientes del contexto a través del preentrenamiento del modelo de lenguaje bidireccional. Durante el proceso de preentrenamiento, BERT se entrena a través del Modelo de lenguaje enmascarado (Modelo de lenguaje enmascarado, MLM) y las tareas de Predicción de la siguiente oración (NSP).
-
Modelo de lenguaje enmascarado (Modelo de lenguaje enmascarado, MLM): en la secuencia de entrada, BERT enmascara aleatoriamente algunas palabras y luego le pide al modelo que prediga estas palabras enmascaradas. A través de esta tarea, BERT puede aprender la capacidad de predecir las palabras que faltan según el contexto. Esto permite a BERT comprender la información semántica y contextual de las palabras. Específicamente, para cada secuencia de entrada, BERT selecciona aleatoriamente algunas palabras para enmascarar. Por lo general, las palabras seleccionadas representan alrededor del 15% del número total de palabras. Para las palabras seleccionadas, hay tres formas de tratarlas:
-
El 80% de las veces, las palabras seleccionadas se reemplazan con un token de máscara especial [MASK]. Por ejemplo, reemplace "manzanas" en la oración "Me encantan las manzanas" con "[MÁSCARA] amo [MÁSCARA]". "esta película es genial" se convierte en "esta película es [MASK]";
-
El 10% de las veces, la palabra seleccionada se reemplazó al azar con otra palabra. Dicho modelo no solo necesita comprender el contexto, sino que también debe tener la capacidad de reemplazar palabras e inferir el significado de las palabras. Por ejemplo, "esta película es genial" se convierte en "esta película es una bebida".
-
10% del tiempo, mantenga la palabra elegida sin cambios. Esto se hace para que el modelo aprenda a manejar las palabras sin máscara. "esta película es genial" se convierte en "esta película es genial"
-
A continuación, BERT introduce la secuencia de entrada procesada en el modelo, que luego se codifica mediante la estructura del codificador de Transformer. Durante la codificación, el modelo tiene en cuenta tanto las palabras enmascaradas como otra información contextual. En última instancia, el modelo produce un conjunto de predicciones para las palabras enmascaradas.
-
-
Predicción de la siguiente oración (NSP): en algunas tareas de procesamiento del lenguaje natural, es importante comprender la relación entre las oraciones. Para que el modelo aprenda relaciones a nivel de oración, BERT usa la tarea NSP. Esta tarea requiere que el modelo juzgue si dos oraciones son continuas, es decir, si una oración es la siguiente oración de otra oración. A través de esta tarea, BERT puede aprender la relación semántica y la capacidad de razonamiento a nivel de oración. Modele explícitamente relaciones lógicas entre pares de texto. Específicamente, se maneja de las siguientes maneras:
-
Para cada muestra de entrenamiento, BERT selecciona aleatoriamente dos oraciones A y B. Entre ellos, en el 50% de los casos, la oración B es la siguiente oración de la oración A, y en el otro 50% de los casos, la oración B son otras oraciones seleccionadas al azar del corpus. .
-
Para realizar tareas de NSP, BERT introduce un método de codificación de entrada especial. Para cada secuencia de entrada, BERT inserta un token separador especial [SEP] entre la oración A y la oración B, y agrega un token de oración especial [CLS] al comienzo de la entrada.
[CLS] Oración A [SEP] Oración B [SEP]
-
A continuación, BERT introduce esta secuencia codificada en el modelo y la codifica mediante la estructura del codificador de Transformer. El codificador aprenderá la representación de la oración A y la oración B de acuerdo con la información del contexto.
-
Durante la codificación, el modelo toma la secuencia completa como entrada y hace predicciones sobre tokens [CLS] especiales. Esta tarea de predicción puede ser una tarea de clasificación para juzgar si la oración A y la oración B son consecutivas. Por lo general, el modelo utilizará una capa completamente conectada para mapear el estado oculto de [CLS] en un problema de clasificación binaria, como el uso de una función de activación sigmoidea para predecir la continuidad de dos oraciones.
-
-
-
GPT: GPT es un modelo de preentrenamiento generativo basado en Transformer cuyo objetivo es aprender la capacidad de generar texto coherente a través del preentrenamiento del modelo de lenguaje autorregresivo. GPT utiliza el método de preentrenamiento del modelo de lenguaje autorregresivo. En el proceso de preentrenamiento, GPT utiliza datos de texto a gran escala y genera gradualmente la siguiente palabra a través de la regresión automática. El modelo predice la siguiente palabra en función de lo generado anteriormente y optimiza los parámetros del modelo a través de la estimación de máxima verosimilitud. Esto permite que GPT aprenda la capacidad de generar texto coherente y lógico. El proceso de implementación de GPT es más o menos el siguiente:
-
El proceso de GPT que divide los datos de texto en palabras o subpalabras generalmente se logra mediante la tokenización. En el proceso de segmentación de palabras, existen dos métodos comúnmente utilizados:
- Tokenización basada en palabras: este método divide el texto en unidades de palabras independientes. Por ejemplo, para la oración "Me encanta el procesamiento del lenguaje natural", la tokenización basada en palabras la divide en ["I", "love", "natural", "language", "processing"].
- Tokenización basada en subpalabras: este método divide el texto en unidades de subpalabras más pequeñas. Puede tratar con la estructura interna y la complejidad de las palabras, y es más adecuado para tratar con palabras fuera de vocabulario y raras. Por ejemplo, para la oración "Me encanta el procesamiento del lenguaje natural", la segmentación de palabras basada en subpalabras puede dividirla en ["I", "love", "nat", "ural", "language", "proceso", "cess " , "ing"].
-
Ya sea una segmentación de palabras basada en palabras o subpalabras, el objetivo final es segmentar el texto en unidades de token discretas, cada unidad de token corresponde a una palabra o subpalabra.
-
Incrustación de palabras incrustadas: codifica el token en un vector. Es decir, cada palabra o subpalabra se convertirá en un vector de incrustación correspondiente, lo que indica que el vector de incrustación es un vector real continuo utilizado para representar la posición de la palabra o subpalabra en el espacio semántico. Un enfoque común es usar un modelo de incrustación de palabras previamente entrenado como Word2Vec, GloVe o FastText para asignar palabras o subpalabras a vectores reales de dimensión fija.
-
Arquitectura de Transformer: GPT utiliza Transformer como su infraestructura. Transformer es un poderoso modelo de aprendizaje profundo cuyo mecanismo central es el mecanismo de autoatención. Es capaz de capturar dependencias globales al procesar datos de secuencia y, al mismo tiempo, tiene la capacidad de computación paralela.
-
Modelo de lenguaje autorregresivo: durante el entrenamiento previo, GPT usa un modelo de lenguaje autorregresivo para el entrenamiento. Específicamente, el modelo genera un texto coherente al generar progresivamente la siguiente palabra. Al generar la i-ésima palabra, el modelo predice la siguiente palabra utilizando las i-1 palabras anteriores ya generadas como contexto.
-
Aprendizaje de parámetros previos al entrenamiento: en los modelos de lenguaje autorregresivos, el objetivo de GPT es maximizar la probabilidad de generar muestras de entrenamiento realistas. A través de la estimación de máxima verosimilitud, los parámetros del modelo se optimizan para maximizar la probabilidad de generar muestras de entrenamiento reales. A través de datos de preentrenamiento a gran escala y un proceso de optimización iterativo, GPT puede aprender las leyes estadísticas y la estructura del lenguaje, para generar un texto lógico y coherente.
-
Generación de texto: una vez completada la capacitación previa, GPT puede generar texto. Dado un texto inicial o una oración semilla, el modelo genera progresivamente la siguiente palabra, la agrega al texto generado y luego usa el texto generado como contexto para predecir la siguiente palabra. Al repetir este proceso, el modelo puede generar un texto coherente y lógico.
-
Método de entrenamiento:
BERT: BERT utiliza una estrategia de entrenamiento de modelo de lenguaje bidireccional. En la secuencia de entrada, BERT enmascara aleatoriamente algunas palabras y le pide al modelo que prediga estas palabras enmascaradas. Este enfoque permite que BERT aprenda la información semántica y contextual de las palabras del contexto.
GPT: GPT utiliza el método de entrenamiento del modelo de lenguaje autorregresivo. Aprende la capacidad de generar texto haciendo que el modelo prediga la palabra en la posición actual. Durante el entrenamiento previo, GPT genera gradualmente la siguiente palabra y optimiza los parámetros para maximizar la probabilidad de la siguiente palabra.
Capacidad de comprensión del contexto:
dos modelos preentrenados basados en la arquitectura de Transformer, que difieren en la capacidad de comprensión del contexto y el dominio de la aplicación.
- BERT: Dado que BERT usa un modelo bidireccional, predice la relación entre las palabras cubiertas y juzga la oración. Puede obtener información más rica del contexto y tiene una gran capacidad de comprensión del contexto. Esto hace que BERT sea excelente en tareas de nivel de palabra, como el reconocimiento de entidades nombradas, la respuesta a preguntas, etc.
- GPT: GPT es un modelo unidireccional, solo puede confiar en lo generado anteriormente para predecir la siguiente palabra. Durante el preentrenamiento, GPT se entrena utilizando un modelo de lenguaje autorregresivo que aprende a generar texto coherente al generar gradualmente la siguiente palabra. Debido a la limitación del modelo unidireccional, GPT se desempeña mejor en tareas generativas, como la generación de diálogos, generación de texto, etc. GPT puede generar texto contextualmente coherente y lógico porque tiene en cuenta el contexto generado previamente al generar cada palabra.
Idoneidad de tareas posteriores:
- BERT: debido a la sólida capacidad de comprensión del contexto de BERT y las características de un modelo bidireccional, se desempeña bien en varias tareas posteriores, como la clasificación de texto, el reconocimiento de entidades nombradas y el juicio de relaciones semánticas.
- GPT: GPT se utiliza principalmente para tareas generativas, como la generación de diálogos, la generación de texto y la traducción automática. Es capaz de generar texto natural y suave, pero es débil en algunas tareas que requieren alineación de entrada y salida.
- En la primera etapa, el objetivo de modelado de lenguaje se utiliza en datos sin etiquetar para aprender los parámetros iniciales del modelo de red neuronal.
- En la segunda etapa, el modelo GPT preentrenado es generativo y, en aplicaciones específicas, GPT se puede usar para tareas posteriores específicas a través del ajuste fino. En la etapa de ajuste fino, se pueden agregar capas o estructuras específicas de la tarea y los datos de tareas etiquetados se pueden usar para ajustar aún más el modelo a los requisitos de la tarea específica.
En general, existen diferencias entre BERT y GPT en las tareas objetivo, los métodos de capacitación, la capacidad de comprensión del contexto y la aplicabilidad. BERT es adecuado para varias tareas posteriores, mientras que GPT se usa principalmente para tareas generativas. El modelo a elegir depende de los requisitos específicos de la tarea y los escenarios de aplicación.
el código
Bert implementa el código. Use el tutorial de código proporcionado por Hands-on Deep Learning aquí
import torch
from torch import nn
from d2l import torch as d2l
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{
i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
#@save
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1,1])
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
#@save
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
#@save
class BERTModel(nn.Module):
"""BERT模型"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
hid_in_features=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size,
query_size=query_size, value_size=value_size)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None,
pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
código GPT
GPT = Atención multicabezal + Avance + capa LN + residual
Dado que Decoder tiene la capacidad de generar texto, GPT, que se enfoca en tareas generativas, eligió la parte Transformer Decoder como arquitectura central.
Sin embargo, solo se conservan la capa de atención multicabezal, la capa de atención multicabezal y la capa feedforward de la red neuronal feedforward, y finalmente se agrega la capa pre-LN + residual sumada y normalizada.
Aquí, GPT2 se usa como código para explicar
import torch
import torch.nn as nn
from transformers import GPT2Model, GPT2Tokenizer
class GPT2(nn.Module):
def __init__(self, num_layers, d_model, num_heads, d_ff, vocab_size, max_sequence_length):
super(GPT2, self).__init__()
self.tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
self.embedding = nn.Embedding(vocab_size, d_model)
self.transformer = GPT2Model(
num_layers=num_layers,
d_model=d_model,
nhead=num_heads,
dim_feedforward=d_ff,
max_position_embeddings=max_sequence_length
)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, inputs):
embedded = self.embedding(inputs)
outputs = self.transformer(embedded)
logits = self.fc(outputs.last_hidden_state)
return logits
# GPT-2 hyperparameters
num_layers = 12
d_model = 768
num_heads = 12
d_ff = 3072
vocab_size = 50257
max_sequence_length = 1024
# Create GPT-2 model instance
model = GPT2(num_layers, d_model, num_heads, d_ff, vocab_size, max_sequence_length)
# Example input
input_ids = torch.tensor([[31, 51, 99, 18, 42, 62]]) # Input token IDs
# Forward pass
logits = model(input_ids)
El código anterior es un ejemplo de implementación simplificado que utiliza PyTorch y la biblioteca de transformadores de Hugging Face. El modelo GPT-2 usa los pesos previos al entrenamiento de GPT-2, donde GPT2Model es el modelo de transformador principal de GPT-2 y GPT2Tokenizer se usa para convertir texto en la entrada requerida por el modelo.

¡Continuará!