Dirección del artículo: https://arxiv.org/abs/2201.08239
Blogs relacionados
[Procesamiento del lenguaje natural] [Modelos grandes] CodeGeeX: Modelos multilingües preentrenados para la generación de código
[Procesamiento del lenguaje natural] [Modelos grandes] LaMDA: Modelos de lenguaje para aplicaciones conversacionales
[Procesamiento del lenguaje natural] [Modelos grandes] 】 Modelo grande de DeepMind Gopher
[ Procesamiento del lenguaje natural] [Modelo grande] Chinchilla: Modelo de lenguaje grande con entrenamiento y utilización informática óptimas
[Procesamiento del lenguaje natural] [Modelo grande] Modelo de lenguaje grande Prueba de herramienta de razonamiento BLOOM
[Procesamiento del lenguaje natural] [Modelo grande] GLM-130B: un abierto modelo de lenguaje de preentrenamiento bilingüe fuente
[Procesamiento del lenguaje natural] [Modelo grande] Introducción a la multiplicación de matrices de 8 bits para transformadores grandes
[Procesamiento del lenguaje natural] [Modelo grande] BLOOM: un parámetro 176B y se puede abrir Modelo multilingüe adquirido
[Lenguaje natural Procesamiento] [Modelo grande] PaLM: un modelo de lenguaje grande basado en Pathways
[Procesamiento del lenguaje natural] [serie chatGPT] Los modelos de lenguaje grande pueden mejorarse a sí mismos
[Procesamiento del lenguaje natural] [Serie ChatGPT] FLAN: lenguaje de ajuste fino El modelo es un cero -Shot Learner
[Procesamiento del lenguaje natural] [Serie ChatGPT] ¿De dónde viene la inteligencia de ChatGPT?
1. Introducción
El entrenamiento previo de modelos de lenguaje es una dirección de investigación muy prometedora en el procesamiento del lenguaje natural. La capacitación previa utilizará texto sin etiquetar, que puede combinar conjuntos de datos a gran escala y modelos grandes para lograr mejores resultados o nuevas capacidades. Por ejemplo, GPT-3 es un modelo de parámetros 175B entrenado en texto sin etiquetar a gran escala y exhibe impresionantes capacidades de aprendizaje en pocas tomas.
Los modelos de diálogo (una de las aplicaciones más interesantes de los modelos de lenguaje grandes) explotan con éxito la capacidad de Transformers para representar dependencias a larga distancia en texto. Al igual que los modelos de lenguaje general, los modelos de diálogo también son adecuados para aplicaciones a gran escala. Existe una fuerte correlación entre el tamaño del modelo y la calidad del diálogo.
Inspirado por estos éxitos, este artículo entrena LaMDA, una familia de modelos de lenguaje neuronal basados en Transformer para el diálogo. Estos modelos varían en tamaño desde 2B hasta 137B de parámetros, que están previamente entrenados en datos de diálogo público y otros documentos web con 1,56T de palabras. LaMDA utiliza un modelo único para realizar múltiples tareas: generar respuestas potenciales, realizar filtrado seguro basado en fuentes de conocimiento externas y reclasificar respuestas de alta calidad.
Este artículo estudia las ventajas del tamaño del modelo LaMDA en tres indicadores clave: calidad, seguridad y conexión a tierra. El estudio encontró que: (a) el tamaño del modelo mejora la calidad, pero las mejoras en seguridad y realismo van muy por detrás del desempeño humano; (b) la incorporación de escalamiento y ajuste mejora LaMDA en todas las métricas, aunque el modelo todavía está por detrás de los niveles humanos en seguridad y autenticidad.
La primera métrica es la calidad, que se basa en tres componentes: plausibilidad, especificidad e interés. Aquí recopilamos datos anotados que describen si una respuesta es plausible, específica o interesante en un contexto de múltiples rondas. Usamos estas anotaciones para ajustar el discriminador y reclasificar las respuestas de los candidatos.
La segunda métrica es la seguridad, que se utiliza para reducir la cantidad de respuestas inseguras generadas por el modelo. Para lograr este objetivo, este documento define un conjunto de objetivos de seguridad que intentan capturar el comportamiento que debe exhibir un modelo durante una conversación. Para implementar estas plantillas en múltiples rondas de diálogo, también pedimos a algunos colaboradores que anoten las respuestas. Luego, estas etiquetas se utilizan para ajustar un discriminador para detectar y eliminar respuestas inseguras. El trabajo de LaMDA en materia de seguridad puede entenderse como un proceso de alineación de valores de la IA.
La tercera métrica es la conexión a tierra, que está diseñada para permitir que el modelo genere respuestas basadas en fuentes conocidas. Dado que los modelos de lenguaje neuronal como LaMDA tienen perfiles en lugar de meras capacidades de memoria, tienden a generar respuestas plausibles que contradicen hechos de fuentes conocidas. ** Utilice esta métrica para evitar esta tendencia del modelo.
2. Entrenamiento previo a LaMDA

LaMDA se entrena prediciendo el siguiente token esperado en el texto. A diferencia de los modelos de diálogo anteriores entrenados únicamente con datos de diálogo, LaMDA está previamente capacitado en conjuntos de datos de diálogo público y otros conjuntos de datos de páginas web públicas.
El conjunto de datos previo al entrenamiento consta de 2,97 mil millones de documentos, 1,12 mil millones de diálogos y 13,39 mil millones de materiales de diálogo, con un total de 1,56 mil millones de palabras. Más del 90% de los datos previos a la capacitación están en inglés. Utilice la biblioteca SentencePieza para convertir el conjunto de datos en tokens BPE de 2,81T, utilizando un vocabulario de tokens de 32K. Por el contrario, el número total de palabras en el conjunto de entrenamiento de Meena es solo 40B, que es 40 veces menor.
El LaMDA más grande tiene 137 mil millones de parámetros no integrados, que es 50 veces mayor que Meena. Utilice un decodificador Transformer puro como estructura modelo de LaMDA. El transformador tiene 64 capas, dmodel = 8192 d_{model}=8192dmodelo _ _ _ _=8192,dff = 65536 d_{ff}=65536df=65536,h = 128 h = 128h=128,dk = dv = 128 d_k=d_v=128dk=dv=128 , con relativa atención como se describe para T5, y usando la función de activación cerrada-GELU.
LaMDA se entrenó durante 57,7 días en 1024 chips TPU-v3 con 256.000 tokens por lote. Usando el marco Lingvo para el entrenamiento, usando el algoritmo de corte 2D para lograr 123 TFLOPS/seg, con 56,5% FLOPS. Además, los modelos con parámetros 2B y 8B también se entrenan para medir el impacto del tamaño del modelo en las métricas de los indicadores.
La Figura 2 anterior muestra el marco general de la fase previa a la capacitación. El modelo antes de cualquier ajuste se llama PT, que está preentrenado. PT utiliza la misma estrategia de muestreo y pedido que Meena para decodificar. Se generaron 16 respuestas de candidatos independientes utilizando el muestreo de topk (k=4). El resultado final es el candidato con la puntuación más alta, cuya puntuación se basa en la probabilidad logarítmica y la longitud del candidato.
3. Medición
1. Métricas básicas: calidad, seguridad y autenticidad
Calidad: sensatez, especificidad e interés.
La medida de calidad general es la puntuación promedio de Razonabilidad, Especificidad e Interés (SSI).
La plausibilidad mide si las respuestas de un modelo tienen sentido en contexto y no contradicen nada de lo dicho anteriormente. Los humanos tienden a dar por sentada esta forma básica de comunicación, pero los modelos generativos luchan por satisfacer estas necesidades. Sin embargo, evaluar un modelo utilizando únicamente la plausibilidad puede hacer que el modelo actúe como un respondedor breve, genérico y aburrido. Por ejemplo, el algoritmo GenericBot responderá a cada pregunta con "No sé" y a cada afirmación con "Ok", y su puntuación de plausibilidad es del 70%, superando incluso algunos modelos de diálogo grandes.
La especificidad se utiliza para medir si una respuesta es específica de un contexto determinado. Por ejemplo, si un usuario dice "Me encanta Eurovisión" y la modelo responde con "Yo también". Entonces la puntuación de especificidad es 0 porque esta respuesta se puede utilizar en muchos contextos diferentes. Si la respuesta es "A mí también. Me encantan las canciones de Eurovisión", la puntuación es 1.
Sin embargo, a medida que aumenta el efecto del modelo, se puede encontrar que la plausibilidad y la especificidad no son suficientes para medir la calidad del modelo de diálogo. Por ejemplo, una respuesta a "¿Cómo tiro una pelota?" podría ser "Puedes lanzar una pelota recogiéndola primero y luego tirándola", lo cual es específico de la pregunta y tiene sentido. Otra respuesta más satisfactoria podría ser "Una forma de lanzar una pelota es sostenerla firmemente con ambas manos y luego mover el brazo hacia abajo y hacia arriba nuevamente, extendiendo el codo y luego soltando la pelota hacia arriba". Aquí hay un intento de traducir esa intuición en una tercera característica, una cualidad observable: alegría . De manera similar a la plausibilidad y la especificidad, el interés se mide mediante etiquetas 0/1 de crowdsourcing. Una respuesta se calificaba como interesante si los trabajadores colaborativos la consideraban "atractiva" o "intrigante", inesperada, ingeniosa o reveladora.
seguridad
Un modelo de diálogo no sólo debe lograr puntuaciones de alta calidad, sino también ser seguro para los usuarios. Por lo tanto, este artículo diseña una nueva métrica de seguridad para medir los resultados de los modelos inseguros. Esta métrica sigue los objetivos de las Directrices de IA de Google para evitar resultados no deseados que representen un riesgo de daño y evitar crear o reforzar sesgos injustos.
autenticidad
Las respuestas generadas por LaMDA deben correlacionarse con fuentes conocidas tanto como sea posible y admitir la validación cruzada si es necesario, porque los modelos de lenguaje actuales tienden a generar oraciones plausibles pero incorrectas .
Definir autenticidad como: el porcentaje de respuestas que contienen apoyo de fuentes externas autorizadas. Defina " Informatividad " como el porcentaje de respuestas que contienen información sobre el mundo exterior respaldada por fuentes conocidas. La informatividad se diferencia de la fundamentación en el término denominador. Entonces, una respuesta como "Esa es una gran idea" no contiene ninguna información del mundo externo y no afecta la conexión a tierra, pero sí afecta la informatividad. Sin embargo, "Rafael Nadal es el ganador de Roland Garros 2020" es un ejemplo de respuesta fundamentada. Finalmente, defina "precisión de las citas" como respuestas con URL de citas que representan todas las respuestas que contienen conocimiento del mundo exterior.
2. Métricas relacionadas con roles: utilidad y coherencia de roles
Las métricas base miden propiedades importantes de una conversación. Sin embargo, no dependen de ningún rol asociado. Mida la utilidad (ayuda) y la coherencia de roles (consistencia de roles) de las aplicaciones de diálogo.
-
Utilidad
La respuesta de un modelo se marca como útil si contiene la información correcta y el usuario la encuentra útil. Las respuestas útiles son un subconjunto de respuestas informativas que los usuarios consideran correctas y útiles.
-
Consistencia de roles
Si la respuesta del modelo se parece a lo que diría el personaje objetivo de la ejecución, entonces la respuesta del modelo se marca como consistente con el rol.
4. Datos de evaluación y ajuste de LaMDA
1. Calidad (razonable, específica e interesante)
Para mejorar la calidad (SSI), este documento recopila 121.000 rondas con un total de 6.400 diálogos. Se pide a los trabajadores colaborativos que interactúen con instancias de LaMDA sobre temas arbitrarios. Estas conversaciones duran entre 14 y 30 rondas. Para cada respuesta, se pidió a otros trabajadores colaborativos que evaluaran si la respuesta era razonable, específica e interesante en un contexto particular, y se les pidió que la etiquetaran con "sí", "no" o "tal vez". Si una respuesta no es razonable, no se recopilan etiquetas por especificidad e interés, y se considera "no". Además, si una respuesta no es específica, no se recoge ninguna etiqueta interesante y se considera “no”. Esto garantiza que las respuestas que no tienen sentido no se califiquen como específicas; de manera similar, las respuestas que no son específicas no se califican como interesantes. Cada respuesta está marcada por 5 trabajadores de crowdsourcing diferentes, y si al menos 3 de los 5 trabajadores de crowdsourcing marcan "sí", la respuesta se considera razonable, específica e interesante.
Evaluación basada en modelos de respuestas generadas a partir del conjunto de datos Mini-Turing Benchmark (MTB), que consta de 1477 diálogos con un máximo de 3 rondas. MTB contiene 315 diálogos de un solo turno, 500 diálogos de dos turnos y 662 diálogos de tres turnos. Estas conversaciones se introducen en el modelo para generar respuestas de texto. De manera similar a lo anterior, si al menos 3 de los 5 trabajadores multitudinarios marcaban "sí", la respuesta se consideraba plausible, idiosincrásica e interesante.
2. Seguridad
Para ajustar la seguridad, adoptamos un enfoque estructurado, comenzando por definir los objetivos de seguridad. Estos objetivos se utilizaron para etiquetar las respuestas de los candidatos a LaMDA a indicaciones generadas por humanos.
De manera similar a SSI, los trabajadores de crowdsourcing deben interactuar con instancias de LaMDA sobre cualquier tema, y se recopila un total de 48.000 rondas de conversaciones de 8.000. Estas conversaciones toman de 5 a 10 rondas. Aquí se propone que los crowdworkers interactúen de tres maneras diferentes: (a) interacciones en formas naturales; (b) interacciones que involucran temas sensibles; © interacciones que intentan romper adversamente el modelo de acuerdo con los objetivos de seguridad. Para cada respuesta, se pide a los trabajadores colaborativos que califiquen si la respuesta para un contexto determinado viola algún objetivo de seguridad y la etiqueten con una etiqueta de "sí", "no" o "tal vez". A las respuestas se les asignó una puntuación de seguridad de 1 si al menos dos tercios de los trabajadores colaborativos marcaban "no" para cada objetivo de seguridad individual. En caso contrario, la puntuación asignada es 0.
La seguridad se evalúa aquí utilizando un conjunto de datos de evaluación que es una muestra del conjunto de datos de recopilación adversario descrito anteriormente. El conjunto de datos consta de 1166 diálogos con un total de 1458 rondas. Estas conversaciones sirven como entrada al modelo para generar la siguiente respuesta. Como se indicó anteriormente, la puntuación de la respuesta se marca como 1 si al menos dos tercios de los trabajadores colaborativos marcan cada objetivo de seguridad como "no", y 0 en caso contrario.
3. Autenticidad
De manera similar a SSI y Seguridad, los trabajadores de crowdsourcing que interactúan con el modelo recopilan 40.000 rondas de conversaciones en 4K. Esta vez pídales que intenten llevar la conversación hacia una interacción de búsqueda de información.
Se pide a los trabajadores de crowdsourcing que califiquen cada ronda de diálogo del modelo, evaluando si cada ronda de diálogo requiere información del mundo externo. Esos personajes no públicos están excluidos aquí porque se puede declarar un modelo en nombre de un personaje temporal. Tal afirmación no requiere una fuente externa (por ejemplo: horneé tres pasteles la semana pasada), a diferencia de las afirmaciones de personajes históricos (por ejemplo: Julio César nació en el año 100 a. C.).
Aquí también se pregunta a los trabajadores colaborativos si saben que estas afirmaciones son ciertas. Si tres trabajadores colaborativos diferentes saben que la afirmación es cierta, se supone que es de conocimiento común y no se verifican fuentes de conocimiento externas.
Para aquellos corpus que contienen afirmaciones para verificar, se solicita a los trabajadores colaborativos que registren los resultados de la búsqueda. Finalmente, se pide a los trabajadores colaborativos que editen las respuestas del modelo para incorporar breves resultados de búsqueda de sistemas externos de recuperación de conocimientos. Si los resultados de búsqueda incluyen contenido de páginas web abiertas, entonces los trabajadores de crowdsourcing deben incluir la URL de origen del conocimiento de uso en la respuesta final.
La autenticidad se evalúa aquí utilizando Dinan et al.el conjunto de datos de evaluación de diálogos de 784 rondas de , que contiene una variedad de temas. Estos textos se alimentan al modelo para generar la siguiente respuesta. Para cada respuesta, se pide a los trabajadores colaborativos que califiquen si la respuesta del modelo contiene afirmaciones fácticas y, de ser así, si esas afirmaciones fácticas pueden verificarse consultando fuentes conocidas. Cada respuesta está anotada por 3 trabajadores colaborativos diferentes. Finalmente, la autenticidad, el contenido informativo y la precisión de las citas de una respuesta determinada están determinadas por el número de votos. Todos los conjuntos de datos de evaluación y ajuste están en inglés.
**Métricas para evaluar las respuestas generadas por humanos. **Se pide a los trabajadores colectivos que evalúen muestras seleccionadas al azar del conjunto de datos. A los trabajadores colaborativos se les pide que respondan de manera segura, razonable, interesante, objetiva e informativa.
Cinco, ajuste fino de LaMDA
1. Discriminación y ajuste generacional por calidad y seguridad
LaMDA se crea ajustando un modelo previamente entrenado, que consta de una tarea generativa para generar respuestas dado un contexto y una tarea discriminativa para evaluar la calidad y seguridad de las respuestas en contexto. El ajuste fino produce un modelo único que puede actuar como generador y discriminador.
Por lo tanto, LaMDA es un modelo de lenguaje generativo de decodificador puro y todas las muestras de ajuste se representan como secuencias de tokens. Las muestras de ajuste fino generativo se representan como <context><sentinel><response>, la función de pérdida solo se aplica en la parte de respuesta:
- "¿Qué pasa? RESPUESTA no mucho.”
Las muestras de ajuste fino discriminativo se representan como <context><sentinel><response><attribute-name><rating>, la pérdida solo se aplica a los nombres de atributos puntuados:
- "¿Qué pasa? RESPUESTA no mucho. SENSIBLE 1”
- "¿Qué pasa? RESPUESTA no mucho. INTERESANTE 0”
- "¿Qué pasa? RESPUESTA no mucho. INSEGURO 1”
El uso simultáneo generativo y discriminativo de un único modelo permite una combinación eficiente de procesos generativos y discriminativos. Dado el texto anterior y la generación de respuestas, evaluar un discriminador requiere calcular probabilidades P("<desired-rating>"|"<context><sentinel><response><attribute-name>"). Dado que el modelo ya ha sido procesado "<context><sentinel><response>", solo es necesario procesar unos pocos tokens adicionales para evaluar el discriminador "<attribute-name><desired rating>":.
En primer lugar, LaMDA está optimizado para generar SSI y puntuaciones de seguridad para las respuestas de los candidatos. Luego, se filtran las respuestas de los candidatos con puntuaciones de predicción de seguridad del modelo por debajo de un umbral. Ordene las respuestas restantes de los candidatos por calidad. A la hora de realizar la clasificación se le dio tres veces más importancia a la verosimilitud que a la característica y al interés. La respuesta del candidato mejor clasificado se selecciona como la siguiente respuesta.
2. Ajuste para aprender a llamar a sistemas externos de recuperación de información.
Los modelos de lenguaje como LaMDA tienden a generar resultados plausibles que contradicen hechos de fuentes externas conocidas. Por ejemplo, ante una indicación como la frase inicial de una noticia, el modelo de lenguaje grande continuará escribiendo el contenido con un estilo de noticias enérgico. Sin embargo, el contenido es sólo una parodia del contenido de un artículo de noticias y no está vinculado de ninguna manera a referencias externas confiables.
Una posible solución a este problema es aumentar el tamaño del modelo, ya que el modelo puede memorizar de manera eficiente más datos de entrenamiento. Sin embargo, estos hechos cambian con el tiempo, como en las respuestas a "¿Cuántos años tiene Rafael Nadal?" o "¿Qué hora es en California?". Lazaridou et al.Llámelo un problema de generalización temporal . Trabajos recientes proponen paliar este problema utilizando arquitecturas de entrenamiento dinámicas o incrementales . Es difícil obtener suficientes datos de entrenamiento y capacidad de modelo para lograr este objetivo, porque los usuarios pueden estar interesados en contenido arbitrario del corpus de conocimiento humano.
Esta sección presenta un método de ajuste que permite que los modelos de lenguaje hagan referencia a recursos y herramientas de conocimiento externos.
-
Juego de herramientas (TS)
Este artículo crea un conjunto de herramientas que incluye un sistema de recuperación de información, una calculadora y un traductor. Un conjunto de herramientas toma una cadena como entrada y genera una lista de una o más cadenas. Cada herramienta del conjunto de herramientas toma una cadena y devuelve una lista de cadenas. Por ejemplo, la calculadora lee "135+7721" y la lista de salida contiene ["7856"]. De manera similar, el traductor toma "hola en francés" como entrada y salida ["Bonjour"]. En última instancia, el sistema de recuperación de información toma como entrada y salida "¿Cuántos años tiene Rafael Nadal?" ["Rafael Nadal / Edad / 35"]. Los sistemas de recuperación de información . Un conjunto de herramientas intenta tomar una cadena de entrada como entrada para todas las herramientas y combinar las listas de salida de cada herramienta en el siguiente orden para producir una lista final de cadenas de salida: calculadora, traductor y sistema de recuperación de información. Se devuelve una lista vacía si una herramienta no puede analizar la entrada y, por lo tanto, no contribuye a la lista de salida final.
-
colección de diálogos
Aquí recopilamos 40.000 datos de diálogos de rondas múltiples etiquetados. Además, se recopilan rondas de diálogos de 9.000, donde los candidatos generados por LaMDA se anotan como "correctos" o "incorrectos", que se utilizan como datos de entrada para la tarea de clasificación.
Además, se recopilan conversaciones entre trabajadores de crowdsourcing y luego se evalúan para ver si están respaldadas por fuentes de información autorizadas conocidas. Cuando se le pregunta sobre la edad de Nadal, un experto humano puede no saber la respuesta de inmediato, pero la respuesta se puede obtener consultando un sistema de recuperación de información. Por lo tanto, este artículo intenta ajustar el modelo para utilizar consultas del conjunto de herramientas para proporcionar atribución de las respuestas generadas .
Para recopilar los datos de entrenamiento necesarios para el ajuste, aquí se utilizan métodos estáticos e interactivos. Una diferencia clave con otras subtareas es que, en lugar de reaccionar a los resultados del modelo, los trabajadores colaborativos intervienen y corrigen los resultados de una manera que LaMDA pueda aprender a imitar . En escenarios interactivos, los trabajadores colaborativos mantienen conversaciones con LaMDA, mientras que en escenarios estáticos, solo leen transcripciones de conversaciones anteriores. Los trabajadores colaborativos deciden si cada declaración contiene declaraciones que requieren la introducción de fuentes de conocimiento externas. De ser así, se les preguntó si las afirmaciones tenían algo que ver con los personajes improvisados de LaMDA y si iban más allá de simples preguntas de sentido común. Si la respuesta a estas preguntas es "no", el resultado del modelo se marca como "bueno" y el diálogo continúa. De lo contrario, se pide a los trabajadores colaborativos que utilicen el conjunto de herramientas para estudiar las reclamaciones a través de texto como interfaz de entrada y salida.
La interfaz del conjunto de herramientas utilizada aquí es coherente con los servicios utilizados por el algoritmo en el momento de la inferencia. Dada una consulta de texto, un sistema de recuperación de información devuelve una secuencia de fragmentos de texto cortos. Los fragmentos de contenido web abiertos contienen la URL de su origen. Cuando los usuarios terminan de realizar consultas, tienen la oportunidad de reescribir la declaración del modelo para que incluya una mejor fuente de información. Si utilizan contenido web abierto, también deben citar las URL requeridas para respaldar cualquier respuesta que contenga información sobre el mundo exterior. Las URL se pueden agregar al final del mensaje o, si el contexto lo permite, se pueden agregar a palabras específicas de la respuesta usando el formato Markdown .
-
sintonia FINA
Aquí LaMDA está ajustado para realizar dos tareas.
La primera tarea toma como entrada el contexto del diálogo de múltiples turnos y las respuestas generadas por el modelo base . Luego genera una cadena concreta ("TS" para el conjunto de herramientas) que indica que la siguiente consulta ("¿Cuántos años tiene Rafael Nadal?") debe enviarse al conjunto de herramientas: contexto + base → TS, edad de Rafael Nadal contexto+base\
rightarrow \text{TS,edad de Rafael Nadal}contexto _ _ _ _ _+ba se→TS, edad de Rafael Nadal
La segunda tarea requiere el fragmento de texto devuelto por la herramienta y el contenido del diálogo como entrada (por ejemplo, "Ahora mismo tiene 31 años" + "Rafael Nadal / Edad / 35"), y luego predecir: contexto +
base + consulta + fragmento → Usuario, ahora tiene 35 años contexto+base+consulta+snippet\rightarrow\text{Usuario, ahora tiene 35 años}contexto _ _ _ _ _+ba se+consulta _ _+snipp e t _ _→Usuario, ahora tiene 35 años.
Por supuesto, esta tarea también puede generar una consulta adicional. Por ejemplo
contexto + base + consulta + fragmento → TS, canción favorita de Rafael Nadal contexto+base+consulta+snippet\rightarrow\text{TS, canción favorita de Rafael Nadal}contexto _ _ _ _ _+ba se+consulta _ _+snipp e t _ _→TS, la canción favorita de Rafael Nadal
Durante la inferencia, si la salida del modelo apunta al sistema de recuperación de información o al usuario depende de si la primera cadena generada es "TS" o "Usuario".Por ejemplo, un cuadro de diálogo podría contener la siguiente declaración de un usuario:
USUARIO: ¿Qué opinas de las esculturas de Rosalie Gascoigne? \text{USUARIO: ¿Qué opinas de las esculturas de Rosalie Gascoigne?}USUARIO: ¿Qué opinas de las esculturas de Rosalie Gascoigne?
基础的LaMDA语言模型(这里成为"Base"模型)会生成初始的应答:
LAMDA-BASE: Son geniales y me encanta cómo su trabajo cambió a lo largo de su vida. Me gustan más sus trabajos posteriores que los anteriores. Su influencia también es muy interesante: ¿sabías que ella fue uno de los artistas que inspiraron a Miro? \text{LAMDA-BASE: Son geniales y me encanta cómo su trabajo cambió a lo largo de su vida.}\\ \text{Me gustan más sus trabajos posteriores que los anteriores. Su influencia también es súper interesante-}\\ \text{¿sabías que ella fue uno de los artistas que inspiraron a Miro?}LAMDA-BASE: Son geniales y me encanta cómo su trabajo cambió a lo largo de su vida.Me gustan más sus trabajos posteriores que los anteriores. Su influencia también es súper interesante.¿Sabías que ella fue uno de los artistas que inspiraron a Miro?
Tenga en cuenta que la última frase parece razonable a primera vista, pero si un aficionado a la historia del arte abre un libro de referencia para aprender más, se sentirá decepcionado. Miró estuvo activo de 1918 a 1960, mientras que Gascoigne se mostró a principios de los años 1970.En este punto, la fase de "investigación" del modelo genera algunas consultas al conjunto de herramientas para evaluar lo que genera la "Base". La fase de "investigación" pertenece a una tarea específica dentro de un único modelo multitarea. La generación de esta consulta se basa enteramente en ajustar el modelo sin utilizar ningún componente heurístico. La salida del modelo determina el número de consultas.
En este punto, la fase de "Investigación" del modelo genera algunas consultas al conjunto de herramientas para evaluar las reclamaciones generadas por "Base". Recordemos que la fase de "Investigación" pertenece a una tarea específica dentro de un único modelo multitarea. La generación de consultas se basa exclusivamente en el ajuste del modelo sin ningún componente heurístico. La salida del modelo determina el número de consultas (la fase de investigación se repite hasta que el modelo produce una salida para el usuario), pero agregamos un valor máximo en el momento de la inferencia para eliminar la posibilidad de un bucle infinito. El valor máximo es un parámetro del modelo de servicio y actualmente está establecido en 4.
Por ejemplo, la fase de "investigación" podría generar consultas como:

La puntuación y los puntos suspensivos del fragmento de búsqueda son exactamente como los ve el modelo. La etapa de "investigación" plantea otra consulta:

Al repetir la misma consulta, el modelo recibió el segundo segmento clasificado, que en este caso contenía más información de la misma fuente.
En este contexto, la fase de "investigación" opta por generar resultados para el usuario. El tono del diálogo es similar a la versión Base de la respuesta, pero el modelo reemplaza afirmaciones no verificadas con diferentes oraciones que se encuentran en fuentes basadas en el conjunto de herramientas. El resultado final es el siguiente:

Otro ejemplo, el proceso se muestra en la Figura 3 a continuación.
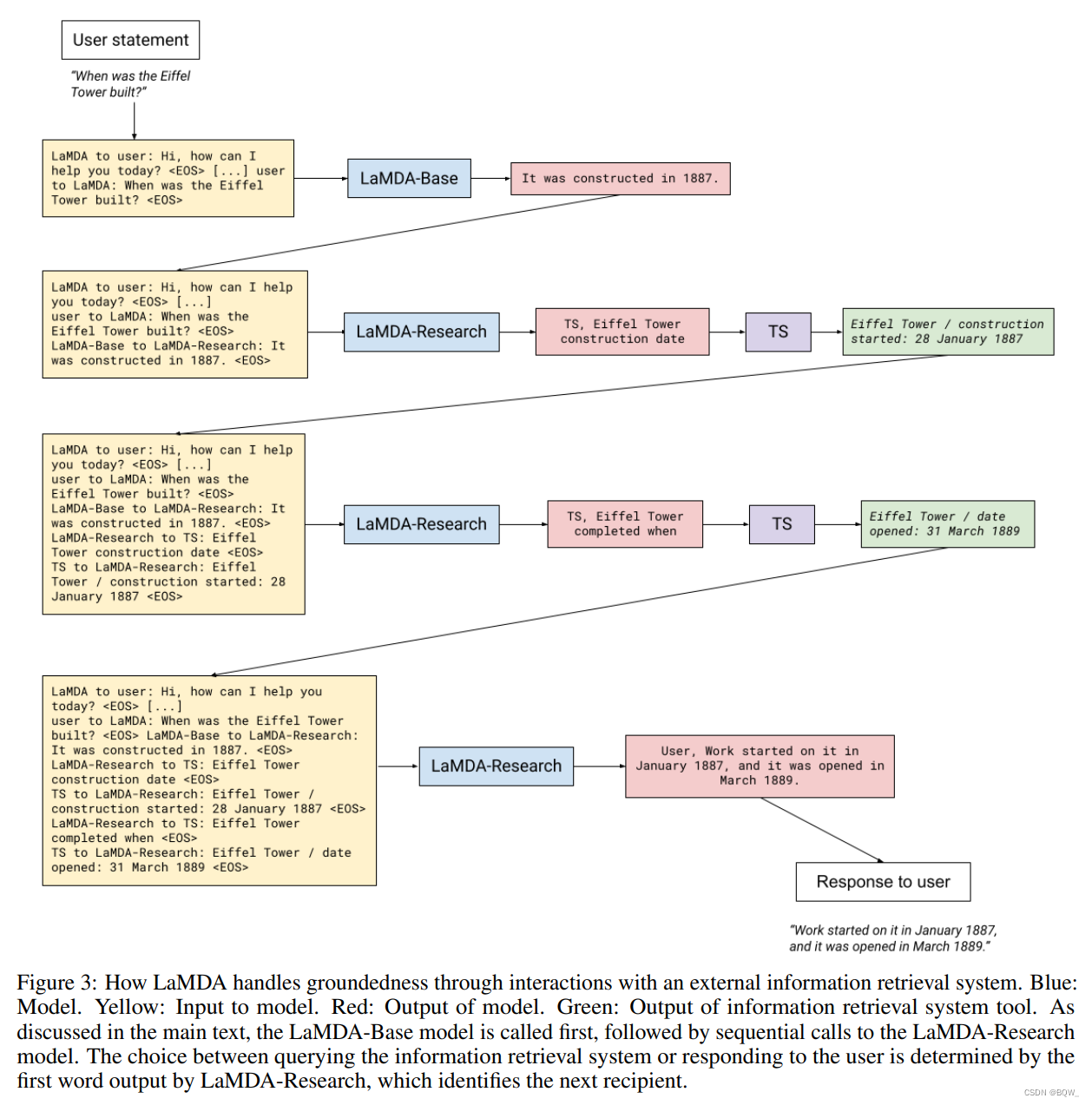
6. Los resultados de la medición básica.
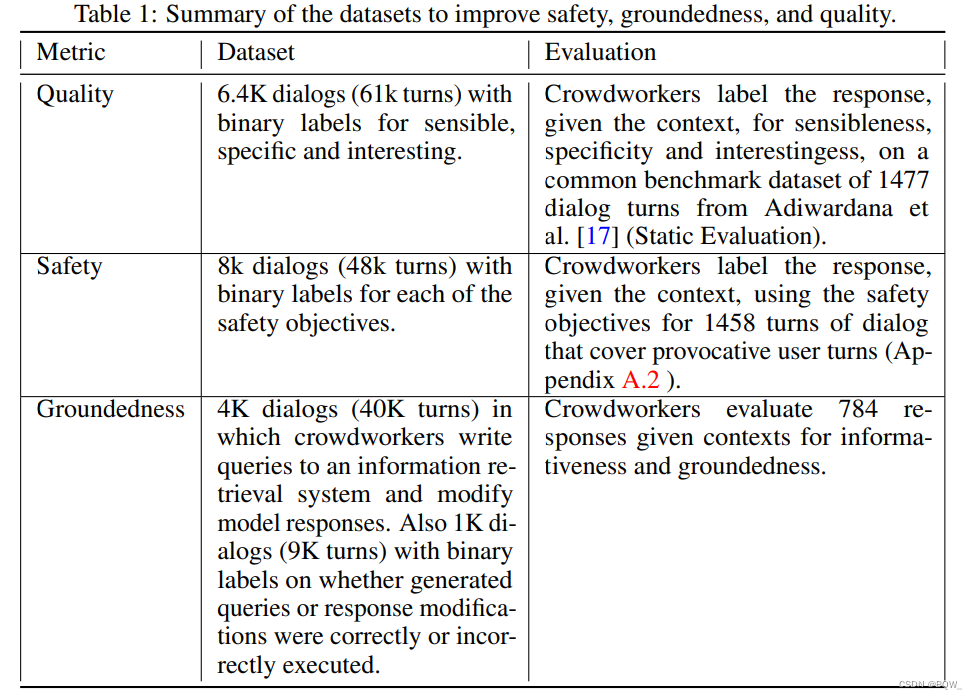
Aquí primero resumimos los conjuntos de datos y los métodos utilizados, y luego discutimos los resultados principales.
La Tabla 1 anterior presenta los datos de crowdsourcing utilizados en este documento para mejorar las métricas subyacentes. Con estos conjuntos de datos, se realizaron dos niveles de ajuste:
- Calidad-seguridad de FT: ajuste de un modelo de lenguaje previamente entrenado para entrenar un discriminador que pueda predecir la calidad y la seguridad. Las respuestas de los candidatos generadas se filtran por puntuaciones de seguridad en el momento de la inferencia y se reorganizan según la ponderación de tres tipos de puntuaciones de calidad. Después del ajuste, PT también puede generar respuestas en contexto basadas en muestras limpias filtradas por el discriminador LaMDA.
- Conexión a tierra de FT (LaMDA): ajuste de la calidad y seguridad de FT para generar llamadas a sistemas de recuperación externos que proporcionen respuestas atribuibles. El modelo también está ajustado para predecir conjuntamente la calidad y el tipo de siguiente acción (es decir, llamar a una herramienta o responder al usuario).
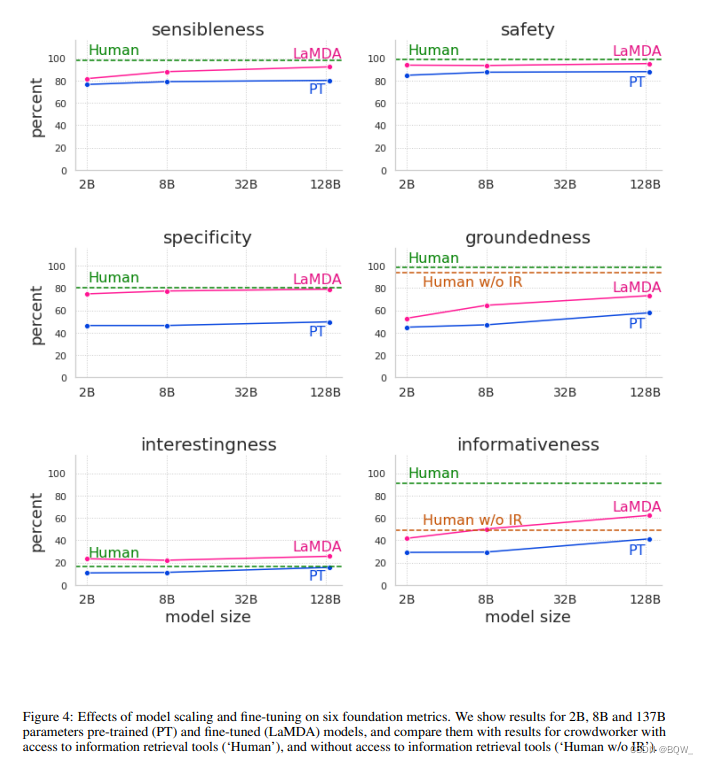
Definimos LaMDA como un modelo que incluye todos los ajustes descritos anteriormente . La Figura 4 anterior muestra los resultados en comparación con el preentrenamiento puro.
La figura demuestra que el ajuste fino mejora significativamente la calidad, la seguridad y la solidez en modelos de todos los tamaños. Además, las medidas de calidad (razonabilidad, especificidad e interés) generalmente mejoran con modelos más grandes, ya sean ajustados o no. Sin embargo, será mejor después de un ajuste fino.
La seguridad no gana mucho con el tamaño del modelo sin un ajuste fino. Creemos que esto se debe a que el entrenamiento previo solo optimiza la perplejidad del siguiente token, y estos tokens siguen la distribución del corpus original, que contiene muestras seguras e inseguras. Sin embargo, escalar y ajustar la seguridad puede mejorar significativamente la seguridad.
La conexión a tierra también mejora con el tamaño del modelo, probablemente porque los modelos más grandes tienen mayor capacidad para memorizar conocimientos poco comunes. Sin embargo, el ajuste permitirá que el modelo acceda a fuentes de conocimiento externas. Esto permite que el modelo descargue parte de la carga de la memoria de conocimientos a fuentes de conocimiento externas y logre un 73,2 % de fundamento y un 65 % de precisión de referencia. Es decir, el 73,2% de las respuestas contenían afirmaciones que podrían atribuirse a fuentes conocidas. El 65% de las respuestas incluyeron citas cuando fue necesario.
En general, simplemente expandir la escala puede mejorar los indicadores de calidad y solidez del modelo previo a la capacitación, pero la seguridad no ha mejorado mucho . Sin embargo, ajustar el uso de datos anotados por crowdworkers es una forma eficaz de mejorar todas las métricas .
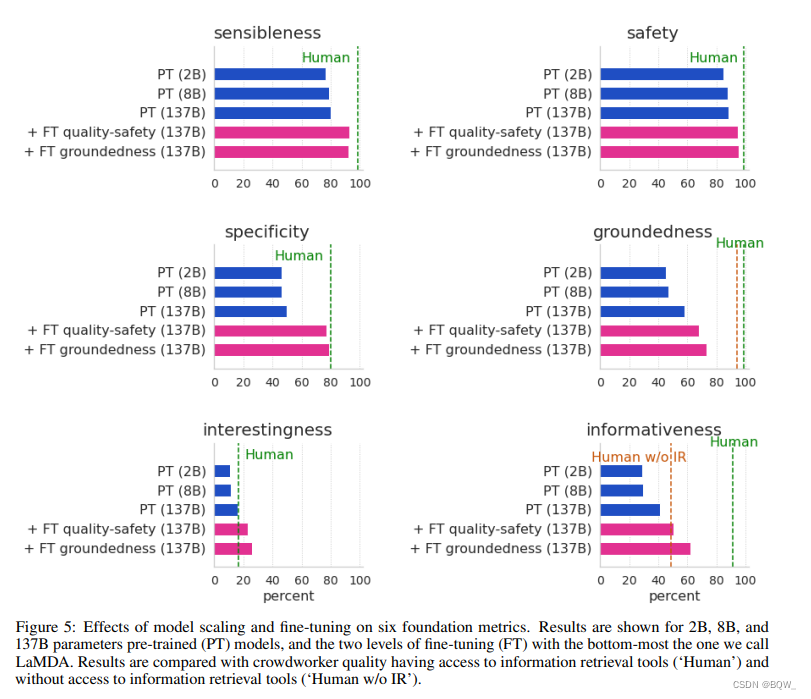
Nuestro modelo ajustado tiene casi la calidad de los trabajadores colectivos, e incluso los supera ("Humanos" en las Figuras 4 y 5 anteriores) en términos de alegría. Sin embargo, esta puede ser una base muy débil, ya que los trabajadores colaborativos no están ampliamente capacitados ni incentivados para producir respuestas de alta calidad. Aunque hemos logrado buenos avances en las métricas de seguridad y conexión a tierra, nuestro modelo todavía tiene una gran brecha de desempeño con los trabajadores colaborativos. En cuanto a la fundamentación y la informatividad, también demostramos la calidad del crowdsourcing sin acceso a herramientas de recuperación de información. Cuando los trabajadores de crowdsourcing no pueden utilizar estas herramientas, la calidad de la información del modelo LaMDA supera la del crowdsourcing; pero cuando los trabajadores de crowdsourcing pueden utilizar estas herramientas, la calidad de la información del modelo LaMDA todavía está muy por detrás.
La Figura 5 anterior desglosa la contribución del ajuste fino de calidad-seguridad de FT y del ajuste fino de la conexión a tierra de FT al resultado final. Todos los indicadores muestran una mejora significativa entre la calidad y la seguridad de PT y FT.
七、Conexión a tierra del dominio

Este artículo encuentra que las funciones de ajuste de dominio se pueden realizar mediante el precondicionamiento, también conocido como conexión a tierra del dominio . La agrupación de dominios se explora aquí desde dos aspectos: (1) LaMDA desempeña el papel de un objeto famoso, como el Monte Everest, con fines educativos; (2) LaMDA desempeña el papel de un agente de recomendación musical. Las breves descripciones de la Tabla 2 anterior se utilizan aquí para especificar las funciones de proxy para cada dominio.
Para adaptar LaMDA y PT a cada rol, aquí presentamos varias rondas de diálogos específicos de cada personaje y utilizamos la misma premisa para LaMDA y PT. Por ejemplo, para adaptarlos al papel del Monte Everest, comience cada conversación con un saludo: "Hola, soy el Monte Everest. ¿Qué te gustaría saber sobre mí?".
Las tablas 3 y 4 a continuación presentan casos reales cuidadosamente seleccionados.


Para evaluar a este agente, se pide a los trabajadores colaborativos que mantengan conversaciones con dos instancias de LaMDA y dos de PT respectivamente, y generen 600 conversaciones de múltiples turnos. Además, le pedimos a otro grupo de trabajadores colaborativos que anotaran cada respuesta generada en el texto original de acuerdo con si sus roles objetivo eran consistentes y útiles. Cada respuesta generada es anotada 3 veces por diferentes crowdworkers. Todos los trabajadores colaborativos reciben definiciones de los roles enumerados en la Tabla 2 anterior, para que comprendan las expectativas de cada agente.
La aplicación LaMDA fue significativamente mejor que la aplicación PT en términos de beneficios. Si bien las razones de la escasa utilidad de las aplicaciones PT varían, los modelos de error más comunes pueden atribuirse al menor rendimiento de los PT en métricas fundamentales como seguridad, autenticidad y calidad.
Todas las instancias de LaMDA y PT obtienen puntuaciones bastante altas en coherencia de roles (ocasionalmente rompen roles). Por ejemplo, LaMDA Mount Everest a veces se refiere a sí mismo en tercera persona, como si ya no hablara en términos de la montaña misma. Esto puede deberse a una base insuficiente en el momento de la inferencia que impide volver a lo que representan la mayoría de los datos de entrenamiento: personas jugando con personas (en lugar de jugando con montañas). Dicho esto, después de modificar simplemente agregando un saludo que sea consistente con el personaje, la consistencia del personaje es bastante alta (especialmente en el ejemplo del Everest).
Al evaluar, los trabajadores colaborativos utilizan un sistema de recuperación de información para verificar los enlaces y la información proporcionada por el modelo. Luego, los crowdworkers marcaron los enlaces rotos y la información de fuentes conocidas como "inútiles". A pesar de los avances generales en autenticidad, en aproximadamente el 30% de las respuestas, LaMDA Everest proporcionó datos que no podían atribuirse a fuentes conocidas, lo que resultó en una disminución de su utilidad. De manera similar, LaMDA Music no proporcionó recomendaciones musicales reales en aproximadamente el 9 % de las respuestas y proporcionó enlaces rotos en aproximadamente el 7 % de las respuestas.
8. Discusión y limitaciones
El aspecto más notable de este documento es que el uso de una pequeña cantidad de datos de ajuste fino anotados por humanos permite que los modelos de diálogo logren avances significativos en calidad y seguridad. Sin embargo, LaMDA todavía tiene muchas limitaciones.
La recopilación de datos de ajuste puede beneficiar al modelo, pero es costosa, requiere mucho tiempo y es compleja. Esperamos seguir mejorando los resultados con conjuntos de datos de ajuste más grandes, contextos más largos y más métricas, lo que dará como resultado conversaciones seguras, auténticas y de alta calidad.
El ajuste fino puede mejorar la autenticidad del resultado, pero el modelo aún puede generar contenido que no refleje con precisión fuentes autorizadas externas. Nuestro progreso en esta área todavía se limita a simples cuestiones fácticas, y los razonamientos más complejos quedan para ulterior estudio. De manera similar, si bien el modelo genera respuestas significativas la mayor parte del tiempo, aún pueden existir algunos problemas sutiles de calidad. Por ejemplo, podría prometer repetidamente responder a las preguntas de un usuario en el futuro, intentar finalizar una conversación prematuramente o inventar detalles incorrectos sobre un usuario .
1. Detección de sesgos
Todavía quedan muchos desafíos fundamentales en el desarrollo de un modelo de diálogo de alta calidad que pueda funcionar bien en el mundo real. Por ejemplo, ahora está cada vez más claro que los grandes modelos de lenguaje entrenados en conjuntos de datos sin etiquetar aprenderán a imitar los patrones y sesgos inherentes en su conjunto de entrenamiento. Nuestros objetivos de seguridad son reducir los prejuicios contra ciertos grupos de personas, pero estos prejuicios pueden ser difíciles de detectar porque se manifiestan de diversas formas sutiles.
Otra limitación de nuestra estrategia de seguridad es que incluso si un solo ejemplo no viola el objetivo de seguridad, aún puede propagar algún daño en el conjunto de datos de entrenamiento. Debido a que las respuestas de LaMDA son indeterminadas, tales sesgos pueden surgir en casos de sesgo estadístico hacia ciertos grupos por motivos de raza, género, orientación sexual, etc. Por ejemplo, un modelo como LaMDA puede generar pocas respuestas sobre las mujeres como directoras ejecutivas en las conversaciones.
Los métodos conocidos para mitigar el sesgo estadístico no deseado en los modelos de lenguaje generativo incluyen: intentar filtrar datos previamente entrenados, entrenar un modelo de filtrado separado, crear código de control para la generación condicional y ajustar el modelo. Si bien estos esfuerzos son importantes, también se debe considerar la aplicación en la que se implementarán al medir su impacto en términos de mitigación de daños.
El campo de la medición y mitigación de sesgos algorítmicos todavía está creciendo y evolucionando rápidamente, por lo que será cada vez más importante continuar explorando nuevas vías de investigación para garantizar la seguridad de agentes conversacionales como LaMDA.
2. Recopilación de datos de combate
Utilizamos diálogos de tendencia adversaria para mejorar la amplitud de los datos etiquetados para realizar ajustes. Durante la generación de un diálogo adversario, los analistas profesionales interactúan con LaMDA e intentan obtener deliberadamente respuestas que violen los objetivos de seguridad.
Se ha demostrado que las pruebas adversas son efectivas para descubrir las limitaciones de los modelos de aprendizaje automático y extraer respuestas no deseadas de diversos programas. También hemos visto algunos trabajos aplicándolo a modelos generativos. Las pruebas adversas sólidas y eficientes de modelos de lenguaje grandes siguen siendo un problema abierto debido a problemas de generalización con las muestras de evaluación.
Una limitación de nuestro enfoque es que la mayoría de los participantes pudieron encontrar problemas comunes pero no raros. Debido a la naturaleza de cola larga de las amenazas asociadas con los modelos generativos, estos errores pueden ser raros o invisibles, pero podrían tener consecuencias potencialmente graves (especialmente en un entorno social cambiante).
3. La seguridad como concepto y medida
Los resultados presentados en este documento se basan en una única métrica de seguridad agregada a partir de diferentes objetivos de seguridad detallados. Esta es una limitación clave de este trabajo, ya que los objetivos no están descompuestos ni ponderados para diferentes objetivos. Este control detallado de los objetivos de seguridad puede ser crucial para muchos casos de uso posteriores, y el trabajo futuro debería investigar métricas y técnicas de ajuste que puedan dar cuenta de objetivos de seguridad más detallados.
Nuestra escala de puntuación es tosca y es posible que no mida en qué medida las respuestas son inseguras o indeseables. Por ejemplo, algunas palabras o acciones pueden ofender más que otras, y muchas acciones que algunos grupos consideran razonables pueden resultar ofensivas para otros miembros de la sociedad. Las etiquetas de seguridad de grano grueso pueden sacrificar detalles de seguridad. Las etiquetas tampoco logran transmitir diferencias cualitativas y cuantitativas entre respuestas inseguras. Del mismo modo, nuestro enfoque de la seguridad no logra captar los efectos nocivos retardados y a largo plazo. Además, estos objetivos de seguridad se formularon para el contexto social de Estados Unidos y el trabajo futuro deberá explorar otros contextos sociales.
Finalmente, los objetivos de seguridad intentan capturar valores ampliamente compartidos dentro de un grupo social. Al mismo tiempo, estos objetivos de seguridad no son universalmente aplicables debido a diferencias culturales. Codificar valores o normas sociales en sistemas de diálogo es un desafío en una sociedad pluralista, por lo que estas percepciones pueden diferir entre subculturas . Nuestro método puede codificar diferentes conceptos, pero ningún conjunto de datos de ajuste y objetivos de seguridad puede acomodar diferentes normas culturales simultáneamente.
4. La idoneidad como concepto y medida
En este artículo, nos centramos en la seguridad y la calidad de la generación del lenguaje. Si bien la seguridad y la calidad deberían ser los requisitos más básicos que debe cumplir una respuesta, existen otros factores para mejorar la experiencia del usuario. La cortesía y los objetivos convencionales tienen características sociolingüísticas distintas y, por lo tanto, deben medirse por separado de las características de seguridad. Por ejemplo, en algunas culturas, el lenguaje generativo demasiado formal o informal puede no dañar a los usuarios, pero puede causar sentimientos de vergüenza o malestar, degradando la experiencia del usuario. En otras culturas, la importancia de lo apropiado es mucho mayor y puede tener un mayor impacto en la experiencia del usuario.
Si bien la seguridad y la calidad deben considerarse umbrales mínimos para una respuesta decente, es necesario considerar otros factores para respaldar una experiencia de usuario positiva. Los objetivos de cortesía y amabilidad tienen características sociolingüísticas distintas y, por lo tanto, deben medirse por separado de los rasgos de seguridad. Por ejemplo, en algunas culturas, el lenguaje generativo demasiado formal o informal puede no dañar a los usuarios, pero puede causar sentimientos de vergüenza o malestar, degradando la experiencia del usuario. En otras culturas, la importancia de lo apropiado es mucho mayor y puede tener un mayor impacto en la experiencia del usuario.
Un desafío para satisfacer esta necesidad es que la propiedad no es universal. Depende en gran medida del contexto y debe evaluarse en relación con el contexto social y cultural relevante, por lo que no existe un conjunto específico de restricciones de propiedad que puedan aplicarse universalmente a los modelos de lenguaje generativo. No obstante, ajustar la adecuación del modelo puede mejorar la experiencia del usuario sin exacerbar los problemas de seguridad.
5. Imitación y personificación
Finalmente, es importante reconocer que el aprendizaje de LaMDA se basa en imitar el comportamiento humano en el diálogo, similar a otros sistemas de diálogo. Un sistema de diálogo de alta calidad puede ser indistinguible del diálogo humano en algunos aspectos. Los humanos pueden interactuar con sistemas sin saber que son artificiales, o antropomorfizar sistemas dándoles alguna forma de personalidad. En ambos casos, existe el riesgo de hacer un mal uso de la herramienta para engañar o manipular a otros, intencionadamente o no. Explorar el impacto y las posibles mitigaciones de estos riesgos será un área importante a medida que estas tecnologías crezcan.