Categoría: Catálogo General de "Procesamiento del Lenguaje Natural desde la Entrada hasta la Aplicación"
Para un texto de entrada dado w 1 w 2 ⋯ wn w_1w_2\cdots w_nw1w2⋯wn, el modelo de lenguaje bidireccional construye el modelo de lenguaje simultáneamente desde las direcciones hacia adelante (de izquierda a derecha) y hacia atrás (de derecha a izquierda). La ventaja de esto es que para cualquier palabra wt w_t en el textowt, las representaciones basadas en la información de contexto izquierda y la información de contexto derecha respectivamente pueden obtenerse al mismo tiempo. Específicamente, el modelo primero codifica cada palabra individualmente. Este proceso es independiente del contexto y utiliza principalmente la información de la secuencia de caracteres dentro de la palabra. Basado en la secuencia de representación de palabras codificadas, el modelo utiliza dos redes de memoria a corto plazo (LSTM) de múltiples capas en diferentes direcciones para calcular las representaciones de las palabras en capas ocultas hacia adelante y hacia atrás en cada momento, es decir, la función dependiente del contexto. representación vectorial de palabras. Utilizando esta representación, el modelo predice la palabra objetivo en cada momento. Para el modelo de lenguaje directo, ttLa palabra objetivo en el momento t es wt + 1 w_{t+1}wt + 1, para el modelo de lenguaje inverso, la palabra objetivo es wt − 1 w_{t-1}wt − 1。
capa de presentación de entrada
El modelo ELMo utiliza una red neuronal basada en una combinación de caracteres para representar cada palabra en el texto de entrada, con el fin de reducir el impacto de la falta de vocabulario (OOV) en el modelo. La siguiente figura muestra la estructura básica de la capa de representación de entrada. En primer lugar, la capa de vector de caracteres convierte cada carácter de la capa de entrada (con caracteres de inicio y finalización adicionales) en una representación vectorial. Supongamos que wt w_twtDe la secuencia de caracteres c 1 c 2 ⋯ cl c_1c_2\cdots c_lC1C2⋯Cyoconstituyen, para cada carácter ci c_i en élCyo, se puede expresar como: vci = E char eci v_{c_i}=E^{\text{char}}e_{c_i}vCyo=michar eCyo。其中,E char ∈ R d char × ∣ V char ∣ E^{\text{char}}\in R^{d^{\text{char}}\times |V^{\text{char}}| }micarbonizarse∈Rdcarácter ×∣Vchar ∣representa una matriz vectorial de caracteres;V char V^{\text{char}}Vchar representa todos los conjuntos de caracteres;d char d^{\text{char}}dchar representa la dimensión del vector de caracteres;eci e_{c_i}miCyoIndica el caracter ci c_iCyocodificación one-hot de . recuerda wt w_twtLa matriz compuesta por todos los vectores de caracteres en es C t ∈ R d char × l C_t\in R^{d^{\text{char}}\times l}Ct∈Rdchar ×l,即C t = [ vc 1 , vc 2 , ⋯ , vcl ] C_t=[v_{c_1}, v_{c_2}, \cdots, v_{c_l}]Ct=[ vC1,vC2,⋯,vCyo] . A continuación, utilice la red neuronal convolucional para realizar la composición semántica (Composición semántica) en la secuencia de representación vectorial a nivel de carácter. Aquí se usa una red neuronal convolucional unidimensional, y la dimensión del vector de caracteresd char d^{\text{char}}dchar se usa como el número de canales de entrada, registrado comoN en N^{\text{en}}nortein , la dimensión del vector de salida se usa como el número de canales de salida, registrados comoN out N^{\text{out}}nortefuera _ Además, mediante el uso de múltiples núcleos de convolución de diferentes tamaños (anchos), se puede utilizar información de contexto a nivel de carácter de diferentes granularidades y se pueden obtener las representaciones de vectores de capa oculta correspondientes.Las dimensiones de estos vectores de capa oculta corresponden a cada núcleo de convolución. Se determina el número de canales de salida. Al empalmar estos vectores, se obtiene la salida de convolución de cada posición. Luego, los vectores de salida de todas las posiciones de la capa oculta se agrupan para obtener la palabrawt w_twtLa representación vectorial de longitud fija de , denotada como ft f_tFt. Suponiendo que se utilizan 7 núcleos de convolución unidimensionales con anchos {1, 2, 3, 4, 5, 6, 7}, los canales de salida correspondientes son {32, 32, 64, 128, 256, 512, 1024}, entonces el vector de salida ft f_tFttiene una dimensión de 2048. 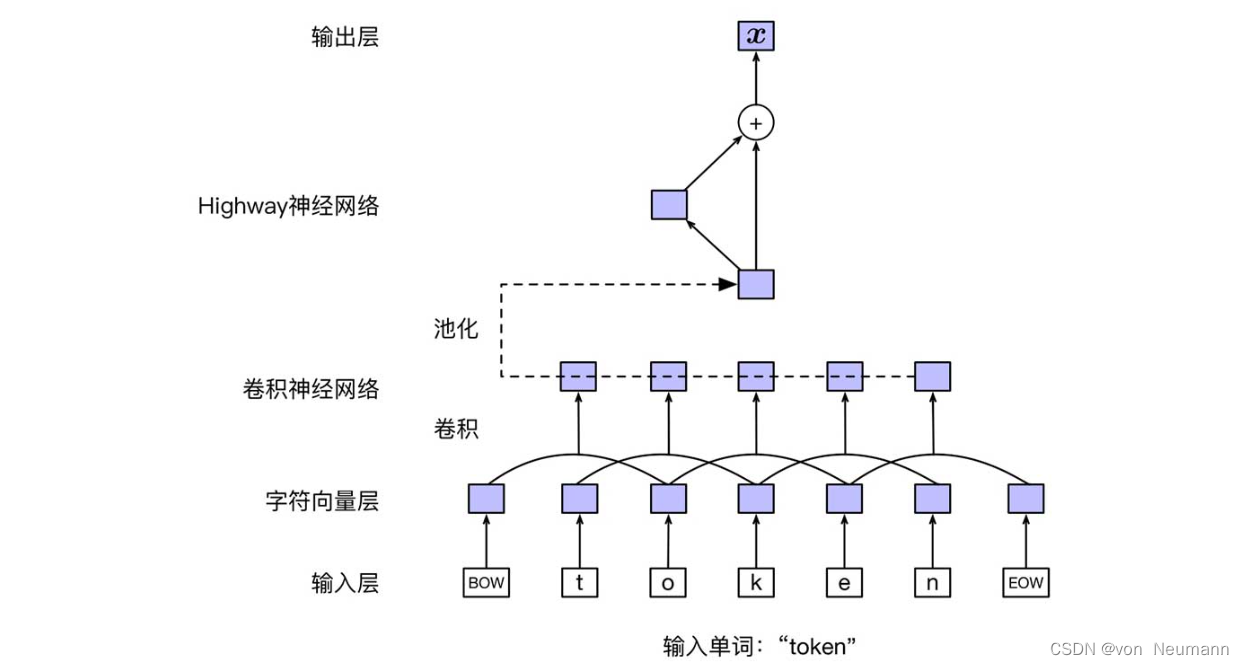 Luego, el modelo utiliza una red neuronal Highway de dos capas para transformar aún más la salida de la red neuronal convolucional para obtener la representación vectorial de palabra final xt x_tXt. La red neuronal Highway establece directamente un "canal" entre la entrada y la salida, de modo que la capa de salida pueda transmitir directamente el gradiente de regreso a la capa de entrada, evitando así el problema de la explosión o dispersión del gradiente causado por demasiadas capas de red. El método de cálculo específico de la red neuronal Highway de una sola capa es el siguiente:
Luego, el modelo utiliza una red neuronal Highway de dos capas para transformar aún más la salida de la red neuronal convolucional para obtener la representación vectorial de palabra final xt x_tXt. La red neuronal Highway establece directamente un "canal" entre la entrada y la salida, de modo que la capa de salida pueda transmitir directamente el gradiente de regreso a la capa de entrada, evitando así el problema de la explosión o dispersión del gradiente causado por demasiadas capas de red. El método de cálculo específico de la red neuronal Highway de una sola capa es el siguiente:
xt = g ⊙ ft + ( 1 − g ) ⊙ ReLU ( W ft + b ) x_t=g\odot f_t+(1 - g)\odot\text {ReLU}(Wf_t +b)Xt=gramo⊙Ft+( 1−g )⊙ReLU ( W ft+segundo )
donde _g es el vector de activación, que esft f_tFtComo entrada, se calcula mediante la función sigmoidea después de la transformación lineal:
g = σ ( W gft + bg ) g=\sigma(W^gf_t+b^g)gramo=s ( Wg ft+bg )
En la fórmula, W g W^gWg ybgb^gbg es la matriz de transformación lineal y el vector de sesgo en la red de activación. Se puede ver que la salida de la red neuronal Highway es en realidad el resultado de la interpolación lineal entre la capa de entrada y la capa oculta. Por supuesto, la estructura del modelo generalmente se ajusta y determina de acuerdo con el experimento, y también podemos probar otras estructuras modelo por nosotros mismos. Por ejemplo, una secuencia de cadenas dentro de una palabra se puede codificar mediante una red LSTM bidireccional a nivel de caracteres. A continuación, sobre la base de los vectores de palabras libres de contexto obtenidos por el proceso anterior, la información de contexto hacia adelante y hacia atrás se codifica por separado utilizando el modelo de lenguaje bidireccional, para obtener la representación dinámica del vector de palabras en cada momento.
modelo de lenguaje directo
En el modelo de lenguaje directo, la predicción de la palabra objetivo en cualquier momento solo depende de la información del contexto o la historia en el lado izquierdo del momento. Aquí usamos un modelo de lenguaje de red de memoria a corto plazo basado en el apilamiento de múltiples capas. Registre los parámetros del LSTM apilado multicapa en el modelo como θ → LSTM \overrightarrow{\theta}^\text{LSTM}iLSTM , los parámetros de la capa de salida de Softmax se registran comoθ out \theta^\text{out}ifuera _ Entonces, el modelo se puede expresar como:
p ( w 1 w 2 ⋯ wn ) = ∏ t = 1 n P ( wt ∣ x 1 : t − 1 ; θ → LSTM ; θ out ) p(w_1w_2\cdots w_n)=\ prod_{ t=1}^nP(w_t|x_{1:t-1}; \overrightarrow{\theta}^\text{LSTM}; \theta^\text{out})pag ( w1w2⋯wn)=t = 1∏nPAG ( wt∣ x1 : t − 1;iLSTM ;ifuera )
modelo de lenguaje inverso
A diferencia del modelo de lenguaje hacia adelante, el modelo de lenguaje hacia atrás solo considera la información de contexto a la derecha en un momento determinado. Se puede expresar como:
p ( w 1 w 2 ⋯ wn ) = ∏ t = 1 norte PAGS ( wt ∣ xt + 1 : norte ; θ ← LSTM ; θ fuera ) p(w_1w_2\cdots w_n)=\prod_{t= 1 }^nP(w_t|x_{t+1:n}; \overleftarrow{\theta}^\text{LSTM}; \theta^\text{fuera})pag ( w1w2⋯wn)=t = 1∏nPAG ( wt∣ xt + 1 : norte;iLSTM ;ifuera )
Referencias:
[1] Che Wanxiang, Cui Yiming, Guo Jiang. Procesamiento del lenguaje natural: un método basado en el modelo de entrenamiento previo [M]. Electronic Industry Press, 2021. [2] Shao Hao, Liu Yifeng. Modelo de lenguaje de entrenamiento
previo [M] ]. Electronic Industry Press, 2021.
[3] He Han. Introducción al procesamiento del lenguaje natural [M]. People's Posts and Telecommunications Press, 2019 [ 4]
Sudharsan Ravichandiran. BERT Basic Tutorial: Transformer Large Model Combat [M] Sociedad editorial de correos y telecomunicaciones del pueblo, 2023
[5] Wu Maogui, Wang Hongxing. Integración simple: análisis de principios y práctica de aplicación [M]. Prensa de la industria de maquinaria, 2021.