Dirección del artículo: https://arxiv.org/pdf/2303.17568.pdf
Blogs relacionados
[Procesamiento del lenguaje natural] [Modelo grande] CodeGen: un modelo de lenguaje de código grande para síntesis de programas de múltiples rondas
[Procesamiento del lenguaje natural] [Modelo grande] CodeGeeX: un modelo de preentrenamiento multilingüe para la generación de código
[Procesamiento del lenguaje natural] 【Modelo grande】LaMDA: Modelo de lenguaje para aplicaciones conversacionales
【Procesamiento de lenguaje natural】【Modelo grande】Gopher de modelo grande de DeepMind
【Procesamiento de lenguaje natural】【Modelo grande】Chinchilla: Modelo de lenguaje grande con entrenamiento y utilización computacional óptimos
[Procesamiento de lenguaje natural] [ Modelo grande] Modelo de lenguaje grande Prueba de herramienta de razonamiento BLOOM
[Procesamiento del lenguaje natural] [Modelo grande] GLM-130B: un modelo de lenguaje bilingüe previamente entrenado de código abierto
[Procesamiento del lenguaje natural] [Modelo grande] para transformadores grandes Introducción a la matriz de 8 bits multiplicación
[Procesamiento del lenguaje natural] [Modelo grande] BLOOM: Un modelo multilingüe con 176B parámetros y acceso abierto
[Procesamiento del lenguaje natural] [Modelo grande] PaLM: Un modelo de lenguaje grande basado en Pathways
[Procesamiento del lenguaje natural] [serie chatGPT] Lenguaje grande los modelos pueden mejorarse a sí mismos
[Procesamiento del lenguaje natural] [Serie ChatGPT] FLAN: el ajuste fino de los modelos de lenguaje es un aprendiz de tiro cero
[Procesamiento del lenguaje natural] [Serie ChatGPT] ¿De dónde viene la inteligencia de ChatGPT?
1. Introducción
El objetivo de la generación de código es: dada una descripción de la intención humana (por ejemplo: "escribir una función factorial"), el sistema genera automáticamente un programa ejecutable. Esta tarea existe desde hace mucho tiempo y las soluciones son infinitas. Recientemente, la calidad de la generación de código se ha mejorado significativamente al tratar los programas como secuencias de lenguaje y modelarlos con arquitecturas transformadoras de aprendizaje profundo. Especialmente cuando los datos de código fuente abierto a gran escala se combinan con grandes modelos de lenguaje.
El modelo CodeX 12B de OpenAI demuestra el potencial de grandes modelos previamente entrenados en miles de millones de líneas de código público. Al utilizar el entrenamiento previo generativo, CodeX puede resolver muy bien problemas de programación de nivel básico en Python. Las investigaciones muestran que el 88% de los usuarios de GitHub Copilot informan una mayor productividad de la programación. Posteriormente, se han desarrollado una gran cantidad de modelos de lenguaje de código de gran tamaño, entre ellos: AlphaCode de DeepMind , CodeGen de Salesforce , InCoder de Meta y PaLM-Coder-540B de Google .
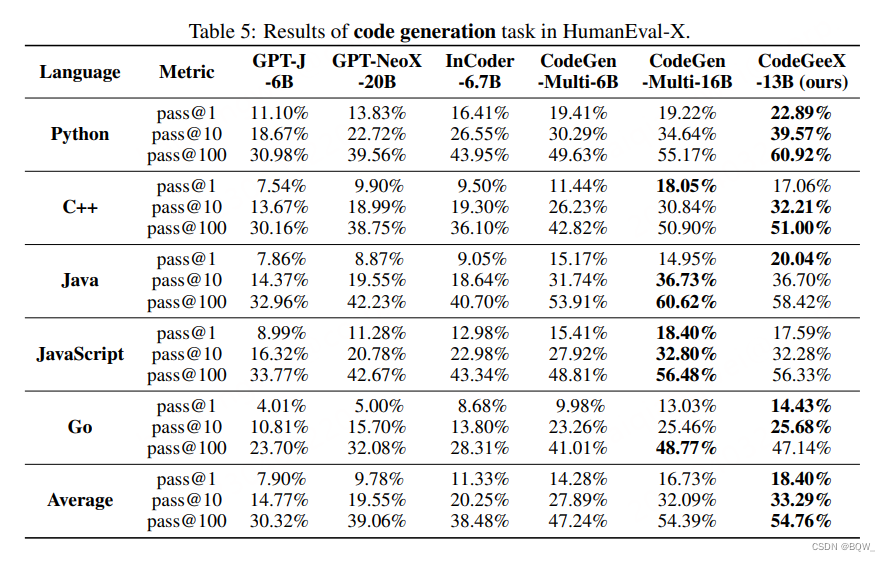
Este artículo propone CodeGeeX, un modelo de generación de código multilingüe con 13B parámetros , que está previamente entrenado en 23 lenguajes de programación. El modelo fue entrenado durante 2 meses en un clúster con 1536 procesadores de IA Ascend 910, entrenando un total de 850 mil millones de tokens. CodeGeeX tiene las siguientes características: (1) CodeGeeX es diferente de CodeX. Su modelo en sí y su código de entrenamiento son de código abierto , lo que es útil para comprender y mejorar el modelo de código previo al entrenamiento. CodeGeeX también admite la inferencia en diferentes plataformas , como las GPU Ascend y NVIDIA . (2) Además de la generación y finalización de código, CodeGeeX también admite la interpretación y traducción de código . (3) En comparación con modelos de generación de código conocidos (CodeGen-16B, GPT-NeoX-20B, InCode-6.7B y GPT-J-6B), CodeGeeX supera consistentemente a otros modelos.
Este documento también desarrolla el punto de referencia HumanEval-X para evaluar modelos de código multilingüe porque: (1) HumanEval y otros puntos de referencia solo contienen problemas de programación en un solo idioma ; (2) los conjuntos de datos multilingües existentes utilizan cadenas similares como métricas de evaluación BLEU en lugar de verificar la exactitud. del código generado . Específicamente, para cada problema de Python en HumanEval, sus indicaciones, soluciones estándar y casos de prueba se reescriben manualmente en C++, Java, JavaScript y GO. En total, en HumanEval-X se incluyen 820 "pares problema-solución" escritos a mano. Además, HumanEval-X admite tanto la generación de código como la evaluación de traducción de código.
2. Modelo CodeGeeX
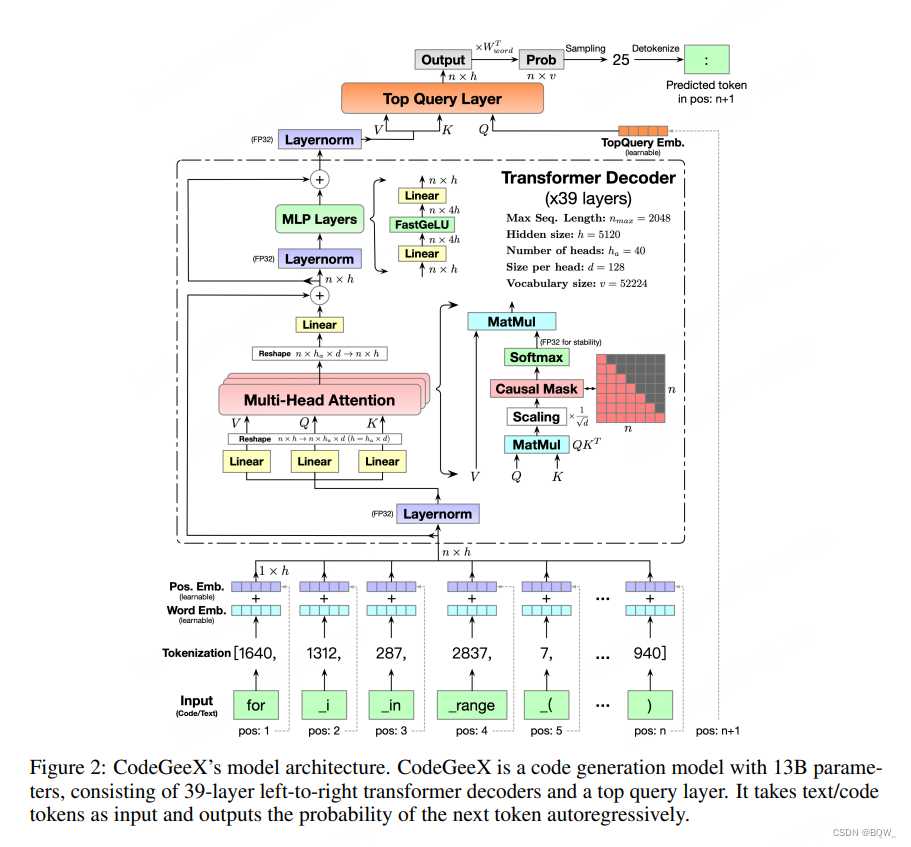
1. Arquitectura modelo
La columna vertebral del transformador . CodeGeeX utiliza una arquitectura GPT solo decodificadora y utiliza modelado de lenguaje autorregresivo. La arquitectura central de CodeGeeX es un decodificador transformador de 39 capas. En cada capa del transformador, incluye: mecanismo de autoatención de múltiples cabezales, capa MLP, normalización de capa y conexión residual. Utilice activaciones FaastGELU similares a GELU, que son más eficientes en el procesador Ascend 910 AI.
FastGELU ( X i ) = X i 1 + exp ( − 1.702 × ∣ X i ∣ ) × exp ( 0.851 × ( X i − ∣ X i ∣ ) ) (1) \text{FastGELU}(X_i)=\ frac{X_i}{1+\exp(-1.702\times|X_i|)\times\exp(0.851\times(X_i-|X_i|))} \tag{1}RápidoGELU ( Xyo)=1+exp ( -1,702 _×∣X _yo∣ )×exp ( 0,851×( Xyo−∣X _yo∣ ))Xyo( 1 ) Objetivo
generativo. Adopte el paradigma de GPT para entrenar el modelo en datos de código no supervisados a gran escala. En general, toma iterativamente el token del código como entrada, predice el siguiente token y lo compara con el token real. Específicamente, para longitudnnCualquier secuencia de entrada de n { x 1 , x 2 , … , xn } \{x_1,x_2,\dots,x_n\}{
x1,X2,…,Xnorte} , la salida de CodeGeeX es la distribución de probabilidad del siguiente token
P ( xn + 1 ∣ x 1 , x 2 , … , xn , Θ ) = pn + 1 ∈ [ 0 , 1 ] 1 × v (2) \mathbb { P}(x_{n+1}|x_1,x_2,\dots,x_n,\Theta)=p_{n+1}\in[0,1]^{1\times v} \tag{2}P ( xnorte + 1∣x _1,X2,…,Xnorte,yo )=pagnorte + 1∈[ 0 ,1 ]1 × v( 2 )
Entre ellos,Θ \ThetaΘ denota todos los parámetros,vvv es el tamaño del vocabulario. Al comparar el token predicho con la distribución verdadera, se puede optimizar la función de pérdida de entropía cruzada:
L = − ∑ n = 1 N − 1 yn + 1 log P ( xn + 1 ∣ x 1 , ) (3) \mathcal {L} =-\sum_{n=1}^{N-1}y_{n+1}\log \mathbb{P}(x_{n+1}|x_1,) \tag{3}l=−norte = 1∑norte - 1ynorte + 1iniciar sesiónP ( xnorte + 1∣x _1,)( 3 ) Capa de consulta
superior. El GPT original utiliza la función de agrupación para obtener el resultado final. Agregamos una capa de consulta adicional (también utilizada por Huawei "Pangu") en todas las capas del transformador para obtener la incrustación final. Como se muestra en la figura anterior, la entrada de la capa de consulta superior se reemplaza por la posiciónn + 1 n+1norte+1 consulta incrustada. El resultado final se multiplica por la transposición de la matriz de incrustación de palabras para obtener la distribución de probabilidad de resultado. Para resolver estrategias, CodeGeeX admite muestreo codicioso, de temperatura, muestreo top-k, muestreo top-p y búsqueda de haz.
2. Configuraciones previas al entrenamiento
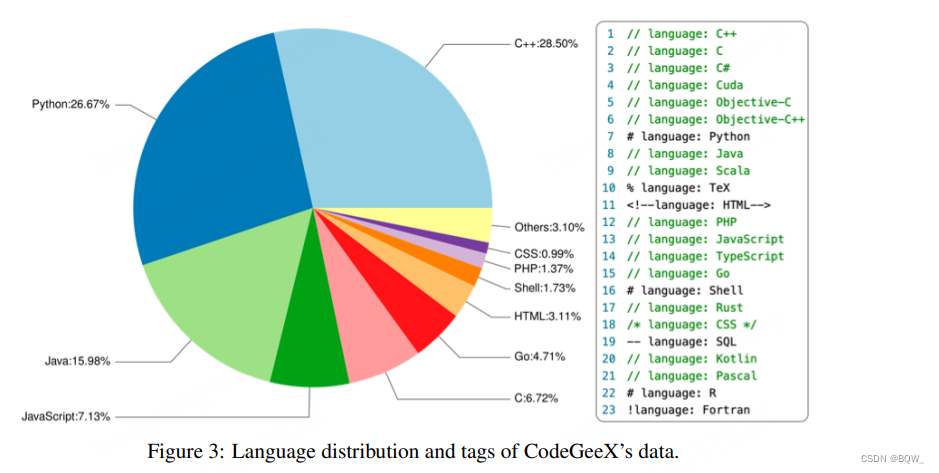
Corpus de código . El corpus de formación consta de dos partes. La primera parte son conjuntos de datos de código fuente abierto: Pile y CodeParrot. La segunda parte es código Python, Java y C++ rastreado directamente desde GitHub para complementar la primera parte. Seleccione el almacén de códigos con al menos una estrella y menos de 10 MB, y luego filtre los archivos: (1) cada línea supera los 100 caracteres; (2) generado automáticamente; (3) la proporción de letras es inferior al 40%; (4) mayor a 100 KB o menor a 1 KB. La figura anterior muestra la proporción de 23 lenguajes de programación en los datos de entrenamiento. Los datos de entrenamiento se dividen en segmentos de igual longitud . Para ayudar al modelo a distinguir entre varios idiomas, se agregan etiquetas relacionadas con el idioma antes de cada fragmento, por ejemplo: idioma: Python.
Tokenización . Teniendo en cuenta que hay una gran cantidad de anotaciones en lenguaje natural en los datos del código y que los nombres de las variables, funciones y categorías suelen ser palabras significativas, los datos del código también se utilizan como datos de texto y se utiliza el tokenizador GPT- 2 . El tamaño del vocabulario inicial es 50000 y se codifican varios espacios como tokens adicionales para aumentar la eficiencia de la codificación. Específicamente, L tokens en blanco se representan como <|extratoken_X|>, donde X=8+L. Dado que el vocabulario contiene tokens en varios idiomas , esto permite a CodeGeeX manejar tokens en varios idiomas, como chino, francés, etc. El tamaño final del vocabulario es v = 52224 v=52224v=52224 .
Incrustaciones de palabras . La matriz de incrustación de palabras se expresa como W palabra ∈ R v × h W_{word}\in\mathbb{R}^{v\times h}W.palabra o d∈Rv × h , la matriz de incrustación de posición se expresa comoW pos ∈ R nmax × h W_{pos}\in\mathbb{R}^{n_{max}\times h}W.pos _∈Rnortemáx _× h , dondeh = 5120 h=5120h=5120 ynmáx = 2048 n_{máx}=2048nortemáx _=2048 . Cada token corresponde a una palabra que se puede aprender y que incluyexword ∈ R h x_{word}\in\mathbb{R}^hXpalabra o d∈Rh y unaque se puede aprenderincorporandoxpos ∈ R h x_{pos}\in\mathbb{R}^{h}Xpos _∈Rh . Las dos incrustaciones se suman para obtener el vector de incrustación de entradaxin = xword + xpos x_{in}=x_{word}+x_{pos}Xen=Xpalabra o d+Xpos _. Finalmente, toda la secuencia se transforma en una matriz de incrustación X en ∈ R n × h X_{in}\in\mathbb{R}^{n\times h}Xen∈Rnorte × h,nnn es la longitud de la secuencia.
3. Formación CodeGeeX
Ascend 910 entrenamiento paralelo . CodeGeeX utiliza Mindspore en un grupo de procesadores Ascend 910 AI (32 GB) para capacitación. La formación se llevó a cabo durante 2 meses en 1526 procesadores de IA en 192 nodos. Se consumieron un total de 850 mil millones de tokens, aproximadamente 5 épocas (213 000 pasos). Para mejorar la eficiencia del entrenamiento, se utiliza el paralelismo de modelos de 8 vías y el paralelismo de datos de 192 vías, y se utiliza el optimizador ZeRO-2 para reducir aún más el consumo de memoria. Finalmente, el tamaño del microlote en cada nodo es 16 y el tamaño del lote global es 3072.
Específicamente, utilice el optimizador Adam para optimizar la pérdida. Los pesos del modelo están en formato FP16, y Layer-Norm y Softmax usan FP32 para mayor precisión y estabilidad. El modelo ocupa 27 GB de memoria GPU. La tasa de aprendizaje inicial es 1e-4 y se aplica un programa de tasa de aprendizaje coseno:
lrcurrent = lrmin + 0.5 ∗ ( lrmax − lrmin ) ∗ ( 1 + cos ( ncurrentndecay π ) ) (4) lr_{current}=lr_{ min}+ 0.5*(lr_{max}-lr_{min})*(1+\cos(\frac{n_{current}}{n_{decay}}\pi)) \tag{4}l ractual _ _ _ _=l rmin+0,5∗( l rmáx _−l rmin)∗( 1+porque (nortediciembre a y _norteactual _ _ _ _pag ))( 4 )
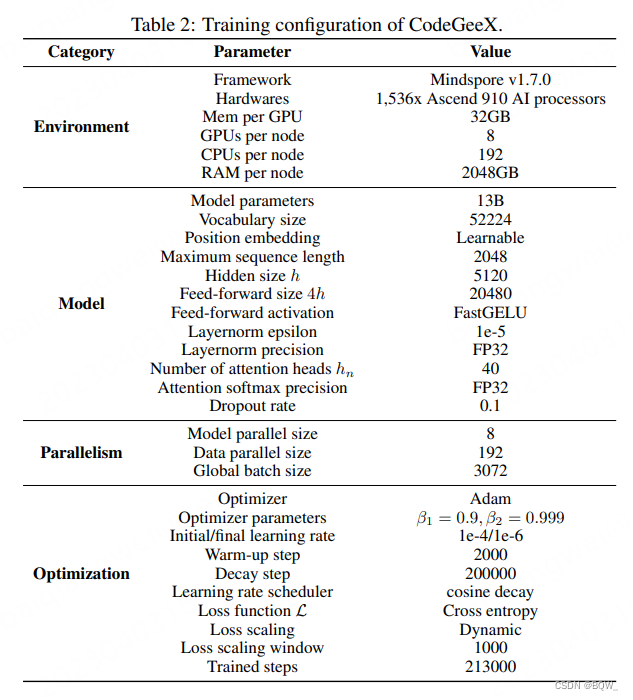
Los parámetros de entrenamiento detallados se muestran a continuación.
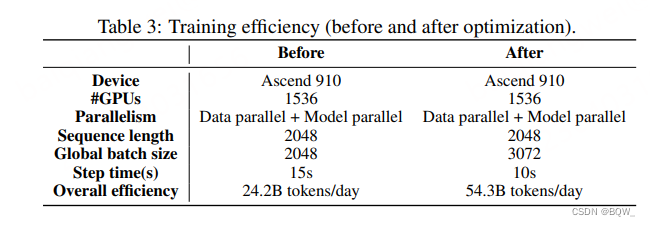
Eficiencia de entrenamiento . Optimizar el marco Mindspore para liberar el potencial del Ascend 910. Se emplean dos técnicas para mejorar significativamente la eficiencia del entrenamiento: (1) fusión de kernel; (2) optimización de Auto Tune. La siguiente tabla es una comparación antes y después de la optimización.
4. Razonamiento rápido
Cuantificar . Aplique tecnología de cuantificación posterior al entrenamiento para reducir el consumo de memoria de la inferencia de CodeGeeX. Cuantizar todos los pesos de las capas lineales WW utilizando el máximo absolutoW se convierte de FP16 a INT8:
W q = Redondo ( W λ ) , λ = Max ( ∣ W ∣ ) 2 b − 1 − 1 (5) W_q=\text{Round}(\frac{W}{\lambda } ),\lambda=\frac{\text{Max}(|W|)}{2^{b-1}-1} \tag{5}W.q=redondo (yoW) ,yo=2segundo - 1−1Máx ( ∣ W ∣ )( 5 )
dondebbb es el ancho de bits,b = 8 b=8b=8 λ\lambdaλ es el factor de escala.
acelerar . Después de la cuantización de 8 bits, se implementó una versión más rápida de CodeGeeX utilizando FasterTransformer de NVIDIA.
3. Punto de referencia HumanEval-X
El punto de referencia HumanEval, similar a MBPP y APPS, solo contiene problemas de programación Python escritos a mano y no se puede aplicar directamente a la evaluación sistemática de la generación de código multilingüe. Por lo tanto, este artículo desarrolla una variante multilingüe de HumanEval, HumanEval-X. Cada problema en HumanEval se define en Python y reescribimos indicaciones, soluciones estándar y casos de prueba en C++, Java, JavaScript y Go. Hay un total de 820 "pares problema-solución" en HumanEval-X.
tarea . HumanEval-X evalúa 2 tareas: generación de código y traducción de código. La tarea de generación de código toma una declaración de función y una descripción textual como entrada y genera el código de implementación de la función. La tarea de traducción de código toma como entrada una solución implementada en el idioma de origen y genera una implementación correspondiente en el idioma de destino.
Métrico . Utilice casos de prueba para evaluar la exactitud del código generado y medir su pass@k. Específicamente, use un método imparcial para estimar pass@k:
pass@k : = E [ 1 − ( n − ck ) ( nk ) ] , n = 200 , k ∈ { 1 , 10 , 100 } (6) \ text{ pasar@k}:=\mathbb{E}[1-\frac{\left(\begin{array}{l}nc \\ k\end{array}\right)}{\left(\begin{ array} {l}n \\ k\end{array}\right)}],\quad n=200,k\in\{1,10,100\} \tag{6}pasar@k:=mi [ 1−(nortek)(norte−Ck)] ,norte=200 ,k∈{
1 ,10 ,100 }( 6 )
dondennn es el número total generado (200), k es el número de muestras,ccc es el número de muestras que pasan todos los casos de prueba.
4. Evaluación de CodeGeeX
- Generación de código multilingüe
- Traducción de códigos multilingües