Directorio de artículos
Neuronas
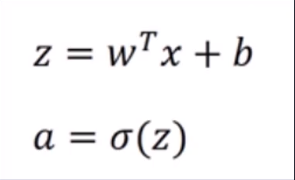
En términos simples, dado el peso w 1 w_1w1, w 2 w_2w2, Desviación bbby otros parámetros, luego ingrese los datosx 1 x_1X1, x 2 x_2X2Y así sucesivamente, después de un cambio no lineal para obtener z, y luego cambiar σ para obtener a, y finalmente calcular la función de pérdida L (a, y).
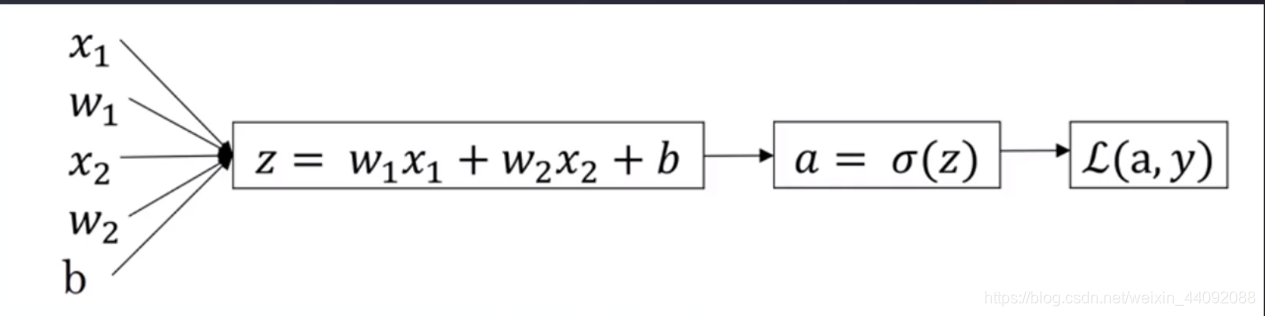
Entre ellos, hay tres cambios σ comunes de la siguiente manera:
Sigmoideo
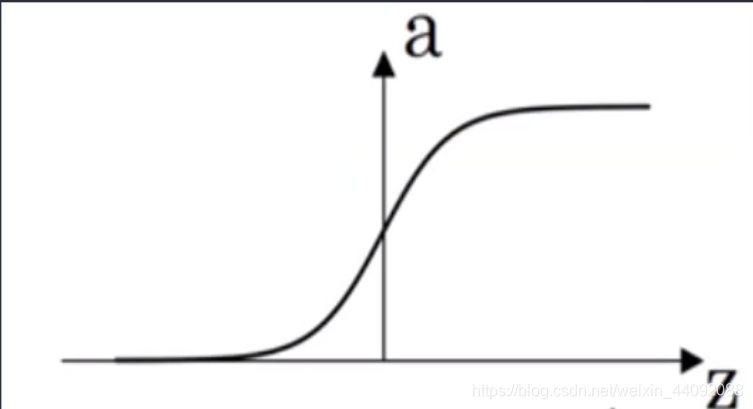
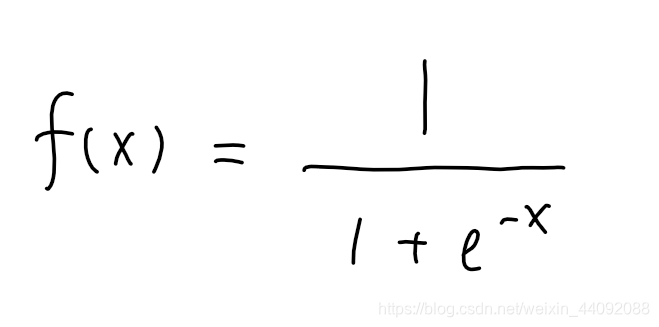
El rango de valores de f (x) es (0, 1)
Tanh
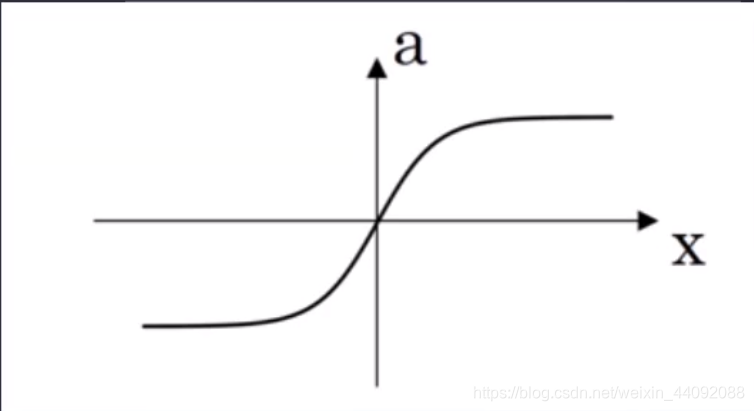
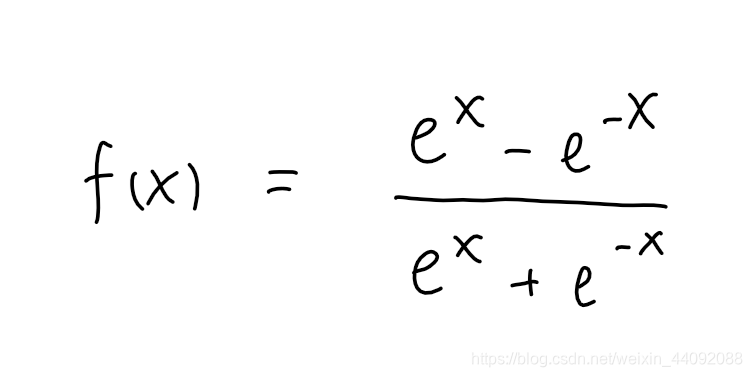
El rango de valores es (-1, 1), que es más negativo que Sigmoid.
reanudar
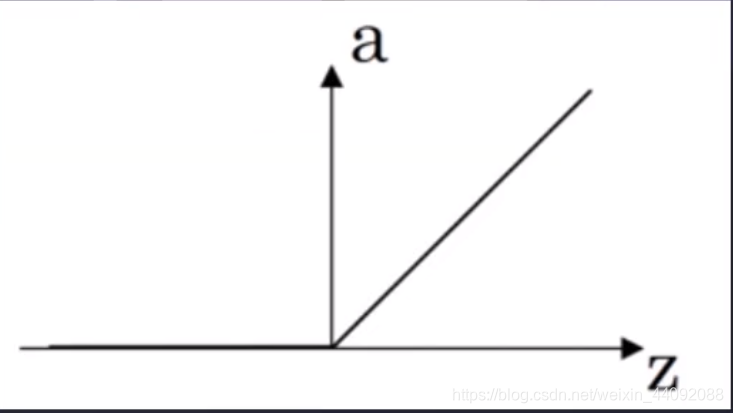
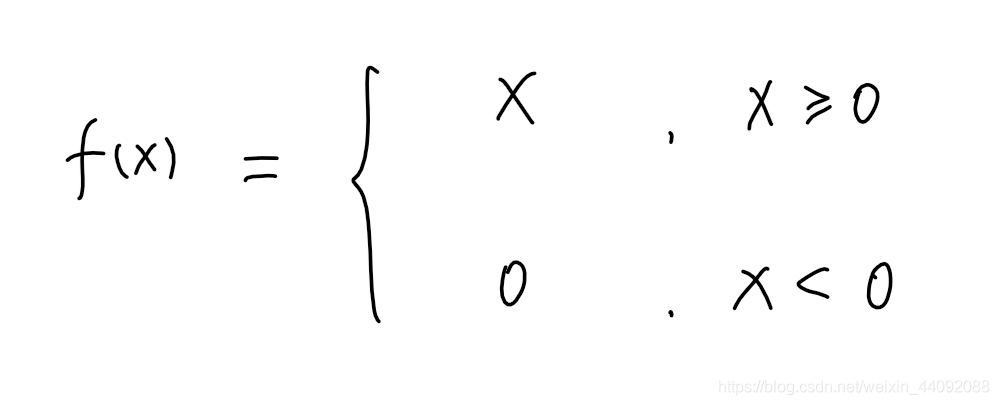
El rango de valores es [0, + ∞)
Función de pérdida
Función de pérdida, lo que queremos es que esta pérdida sea lo más pequeña posible.
L1
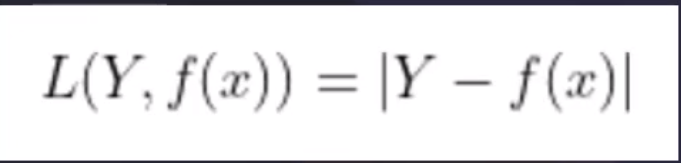
L2
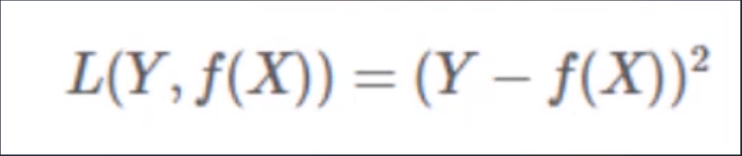
Entropía cruzada
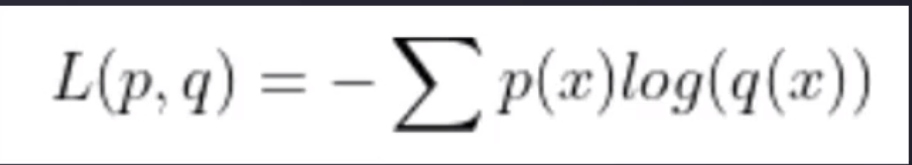
Descenso de gradiente
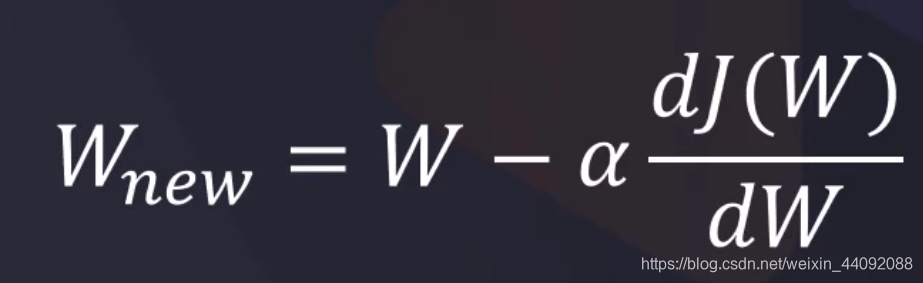
Es la derivada de la función de pérdida L con respecto a W, porque esperamos que la pérdida sea lo más pequeña posible, por lo que esperamos que esta derivada sea negativa, luego restarla de la W original hará que W cambie, lo que indica que pagamos preste más atención, y espero continuar, no olvide que W es el peso, por lo que será más efectivo al calcular el promedio ponderado. (Explique por qué el incómodo signo menos en el descenso de gradiente)
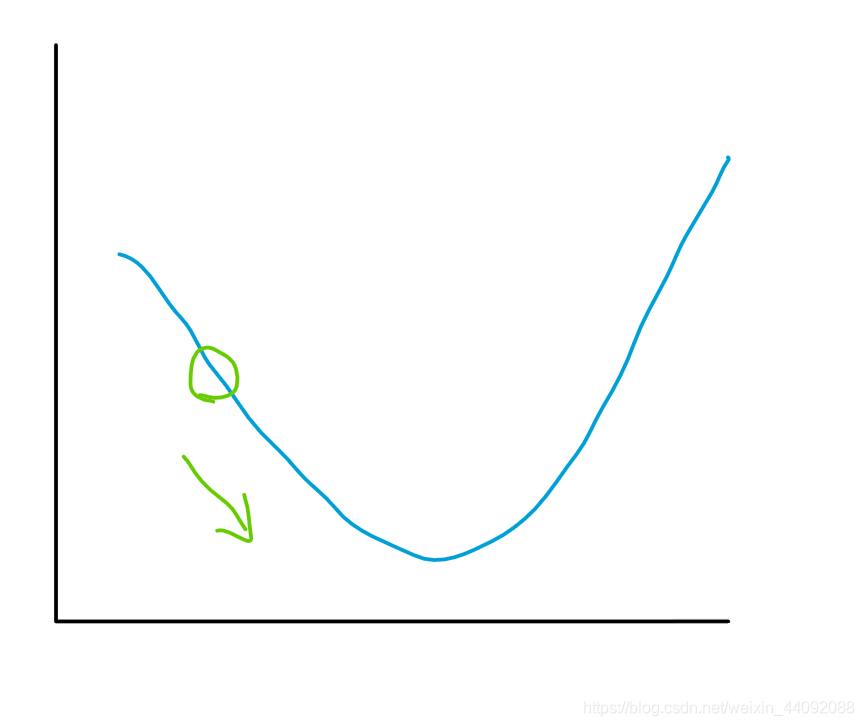
En pocas palabras, simplemente vaya en la dirección del gradiente, y será más intuitivo usar la imagen de la función para ilustrar. Ahora tome la imagen de la función bidimensional como ejemplo: simplemente
camine en la dirección del hueco.
Retropropagación
Después de una gran cantidad de cálculos, se obtiene una solución óptima global aproximada.
Red neuronal convolucional

Capa convolucional: detección de bordes
Los datos de entrada
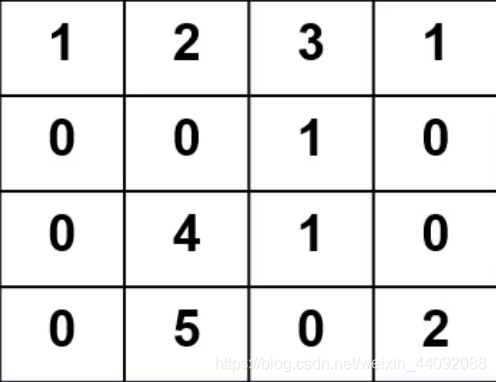
Operador de convolución
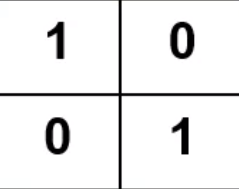
El operador de convolución se ajusta constantemente a través del cálculo,
y cada valor es equivalente a una neurona, y el valor es el peso W
Operación de convolución
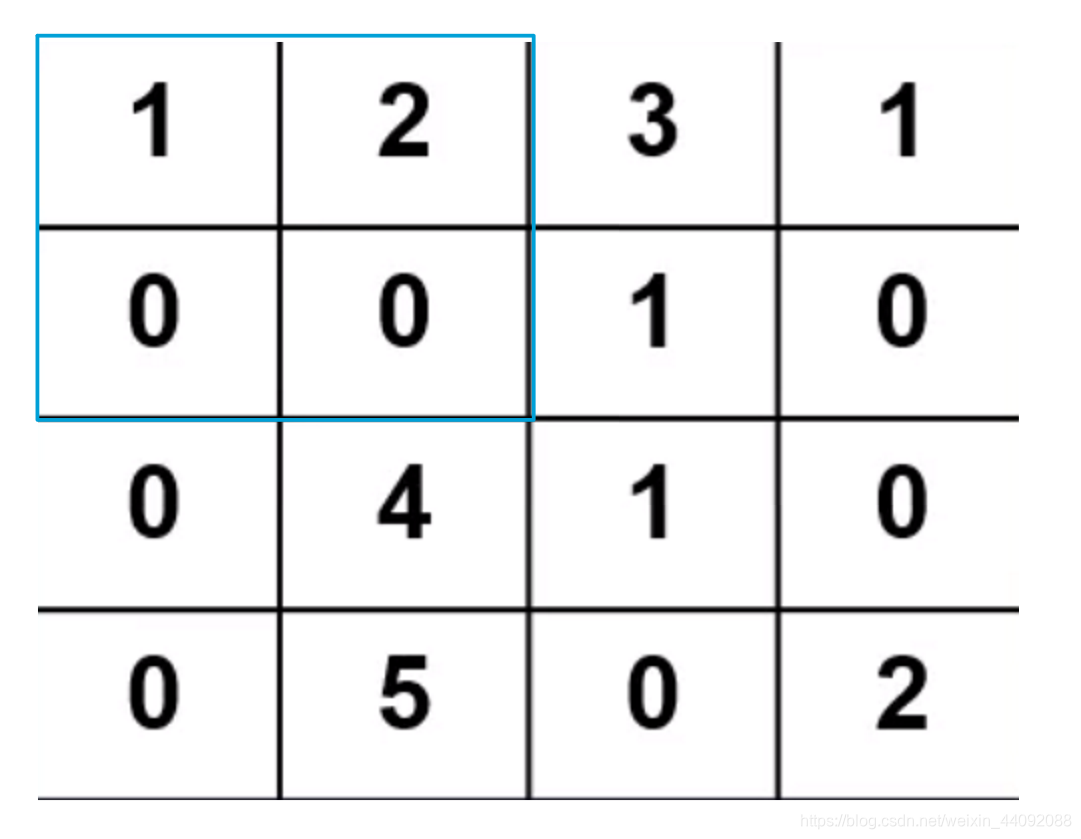
El operador de convolución es una matriz pequeña. Coloque el operador en los datos de entrada y tome cada valor del operador como el peso del valor en la misma posición de los datos de entrada para calcular el promedio ponderado. De
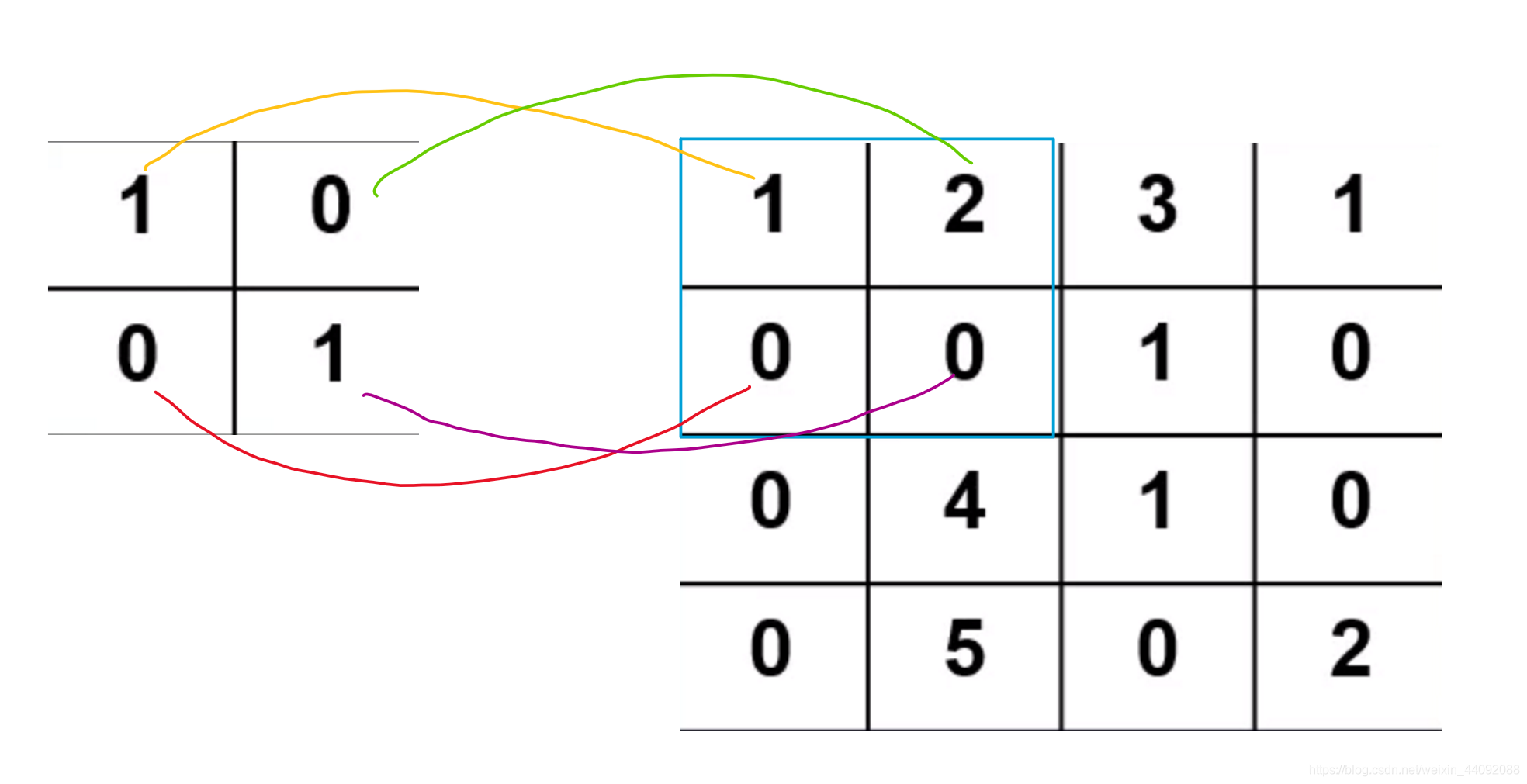
esta manera, calcule 1 ∗ 1 + 2 ∗ 0 + 0 ∗ 0 + 0 ∗ 1 1 * 1 + 2 * 0 + 0 * 0 + 0 * 11∗1+2∗0+0∗0+0∗1. Obtenga el resultado 1, guárdelo en otra matriz, luego mueva el operador de convolución a la siguiente posición y
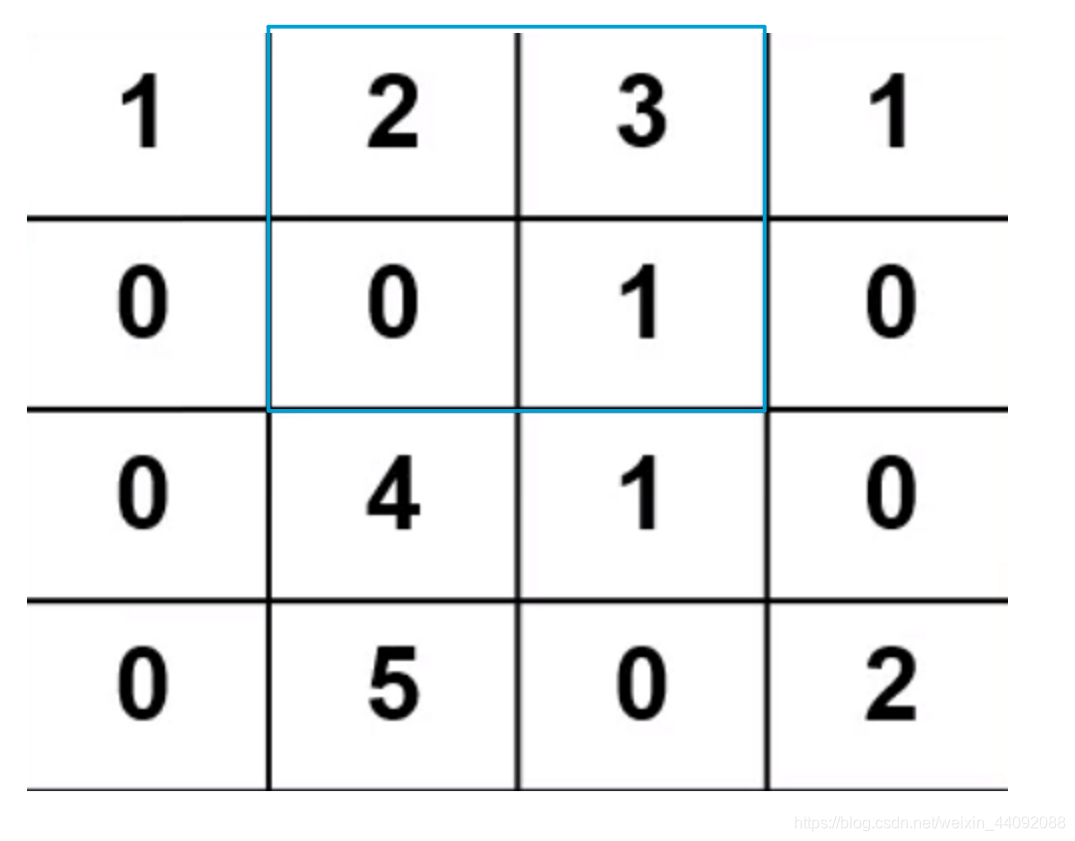
continúe el cálculo hasta que se atraviesen todos los datos de entrada.
El tamaño de paso predeterminado aquí, que es la distancia de cada traslación del operador de convolución, es 1
y finalmente se obtiene el resultado de convolución, que es una matriz de 3 * 3
Avanzado
Este operador de convolución también puede tener muchas, muchas capas, y se ve así:
entonces el resultado de convolución obtenido también puede tener muchas, muchas capas:

el trabajo de cada capa de operador de convolución es diferente, entiendo que detectan diferentes características del imagen.
Después de esta operación de convolución, el tamaño anterior es M ∗ N ∗ 3 M * N * 3METRO∗norte∗3 , se volverá muy profundo, el último número puede convertirse en 32, 64 o similar.
Tenga en cuenta que los datos de entrada también pueden tener muchas capas. Para comprender cómo cambian los datos de una sola capa, simplemente superponga varias capas de datos.
Zancada de convolución y acolchado
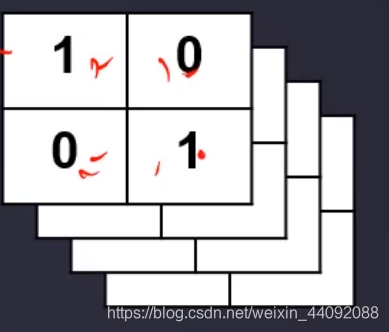
Paso
La distancia que el operador de convolución se mueve cada vez. Si zancada = 2,
entonces el movimiento es así:
-
primer paso:
-
El segundo paso:
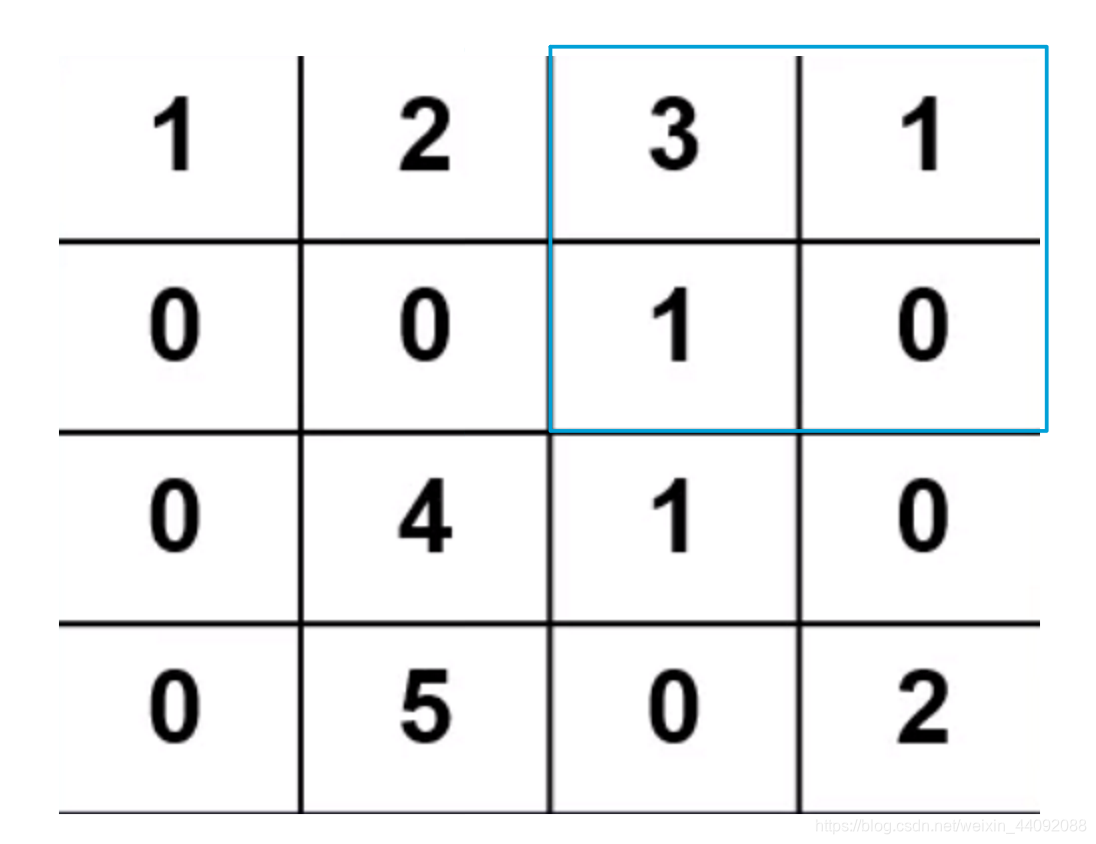
-
tercer paso:
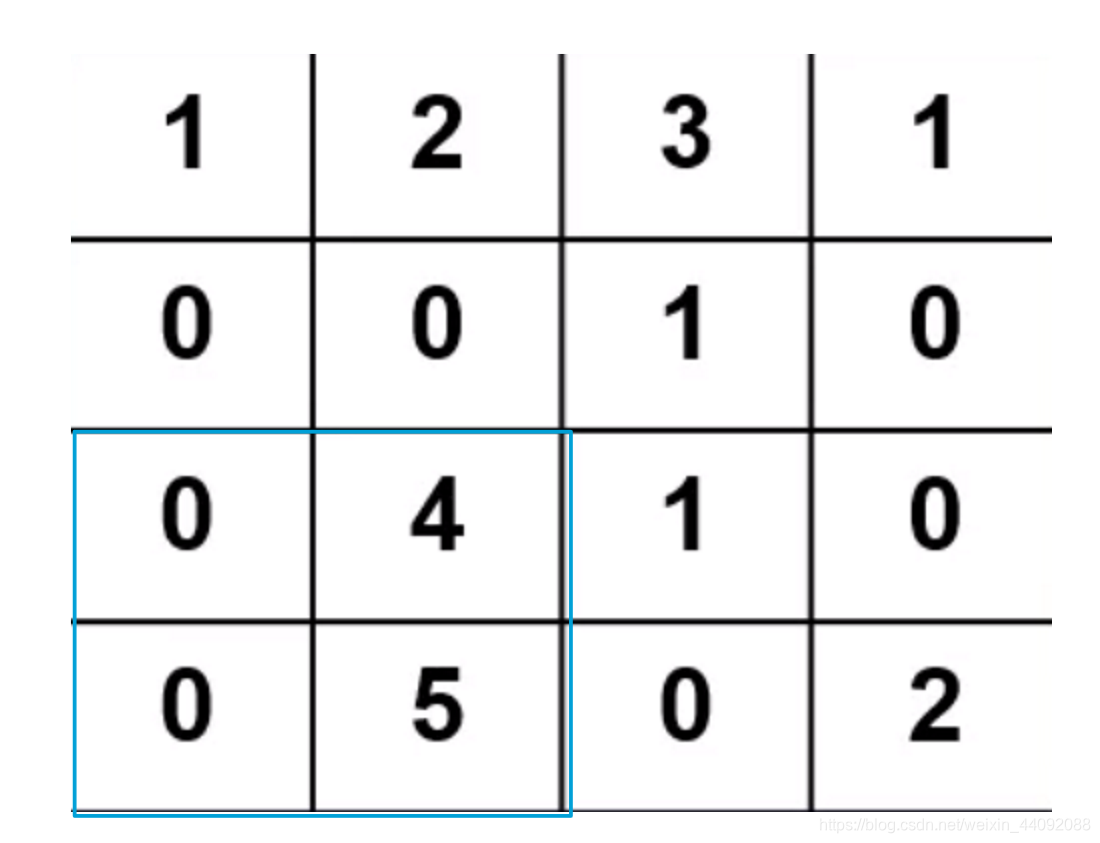
Finalmente obtén una matriz de 2 * 2
relleno
En pocas palabras, la matriz de resultado de convolución final es demasiado pequeña, así que rellene un círculo a su alrededor,
suponiendo que padding = 1, agregue un círculo alrededor del resultado:
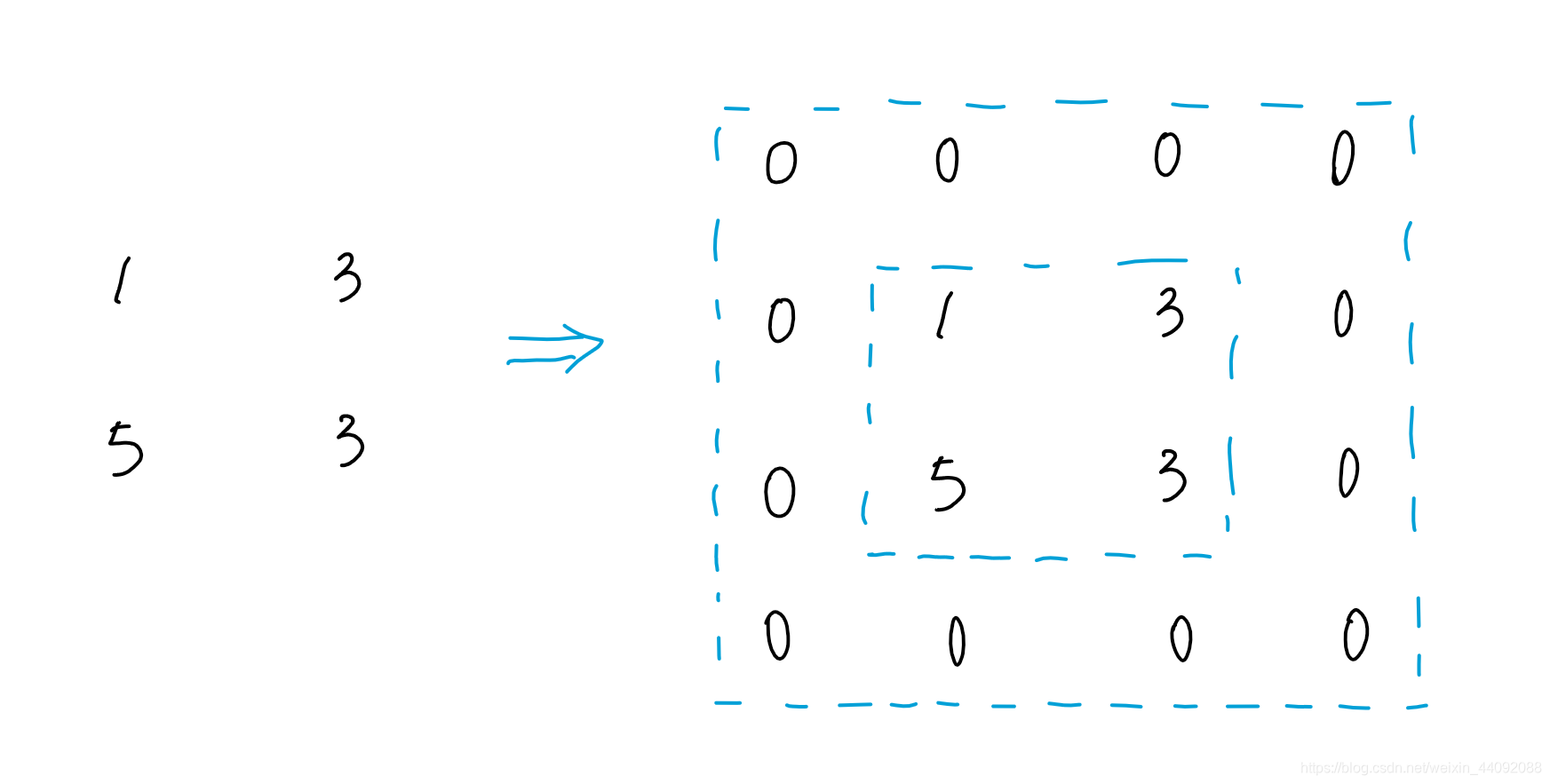
Tamaño del resultado de convolución
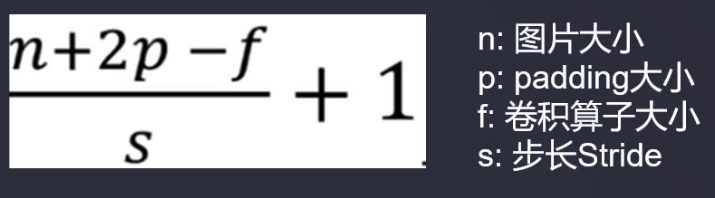
Capa de agrupación
El operador de agrupación tiene la misma estructura que el operador de convolución, pero solo hay dos tipos:
tomar el valor máximo y calcular el promedio ponderado
Capa completamente conectada
Principalmente hacen el trabajo del clasificador, los comunes son SVM, FCN, global pooling;
el final del modelo está conectado a la salida.
La información de salida es la categoría predicha y el modelo de salida considera la categoría más probable, como un gato, con una probabilidad del 88%.
Estructura de red neuronal convolucional clásica
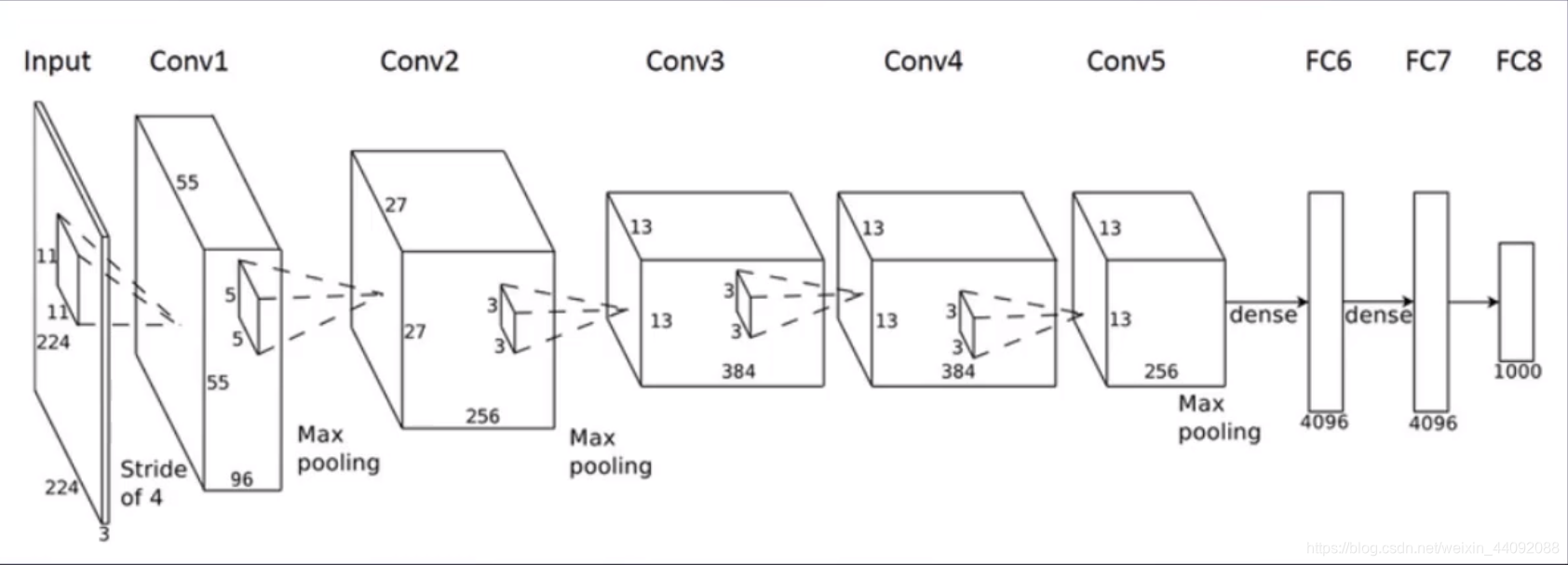
ALEXNET
El nombre de la red neuronal convolucional se lanzó de una sola vez


Con más y más capas ocultas, la tasa de precisión de la clasificación cae en su lugar. Este tipo de fenómeno es más desaparición de gradiente o explosión de gradiente . Por
ejemplo, si hay un parámetro de peso de 2, 10 iteraciones es 2 10 = 1024 (explosión de gradiente), otro parámetro es muy pequeño, 0.5, y es 0.00097 (gradiente desaparición) durante diez iteraciones
Una función de activación inadecuada o un peso inicial demasiado grande también pueden hacer que el gradiente desaparezca .
Como recordatorio, las razones de los dos no son consistentes.
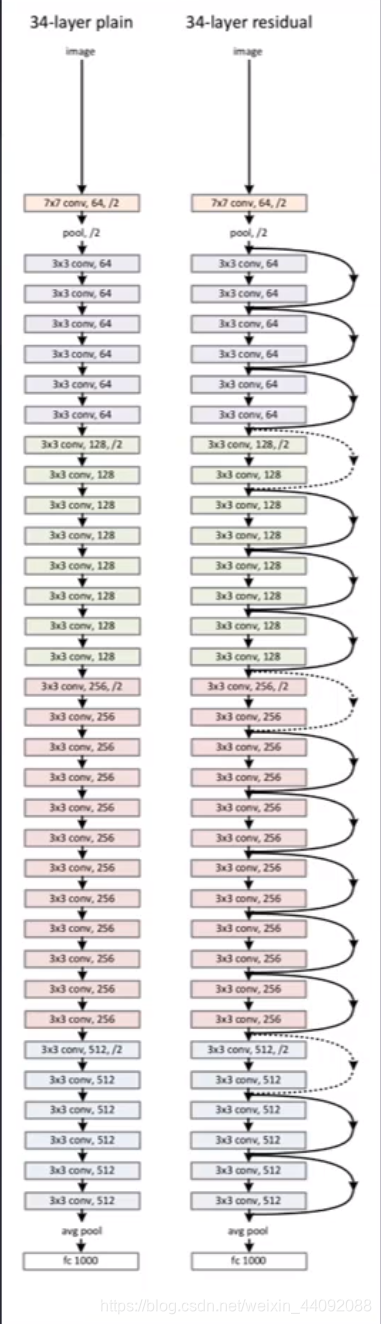
ResNet
Es una red neuronal residual , un modelo nacido específicamente para resolver los problemas previos de desaparición y explosión del gradiente.
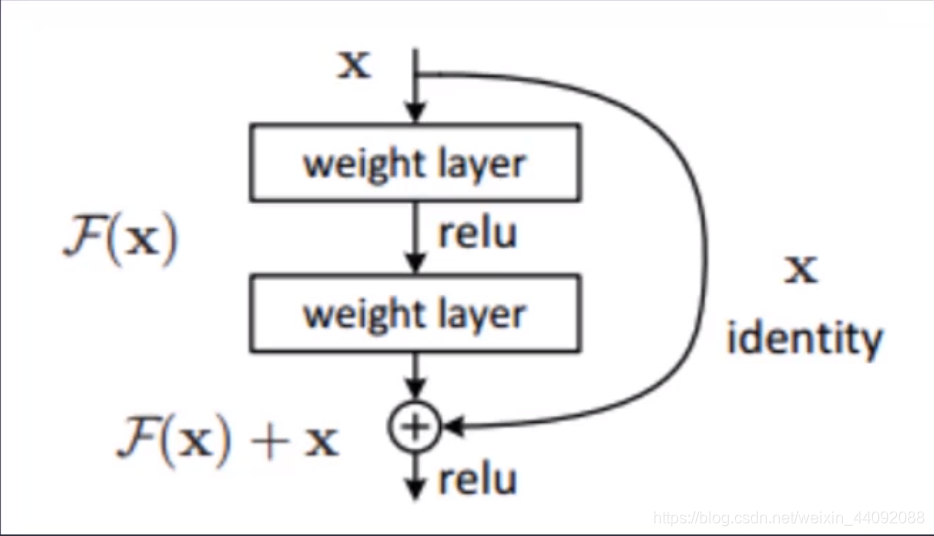
La principal innovación es superponer los datos de entrada originales y los datos transformados juntos, y continuar pasándolos, lo que puede corregir bien la desaparición del gradiente y el descenso del gradiente
. La red neuronal en el futuro puede ser muy larga y muy larga.

Comienzo
El tamaño del operador de convolución se especifica artificialmente, lo cual es muy difícil . Ya sea que elija 1 1, 3 3 o 5 * 5,
solo los quiero todos y no hago preguntas de opción múltiple. Esta es la parte principal de este Innovación: ¡
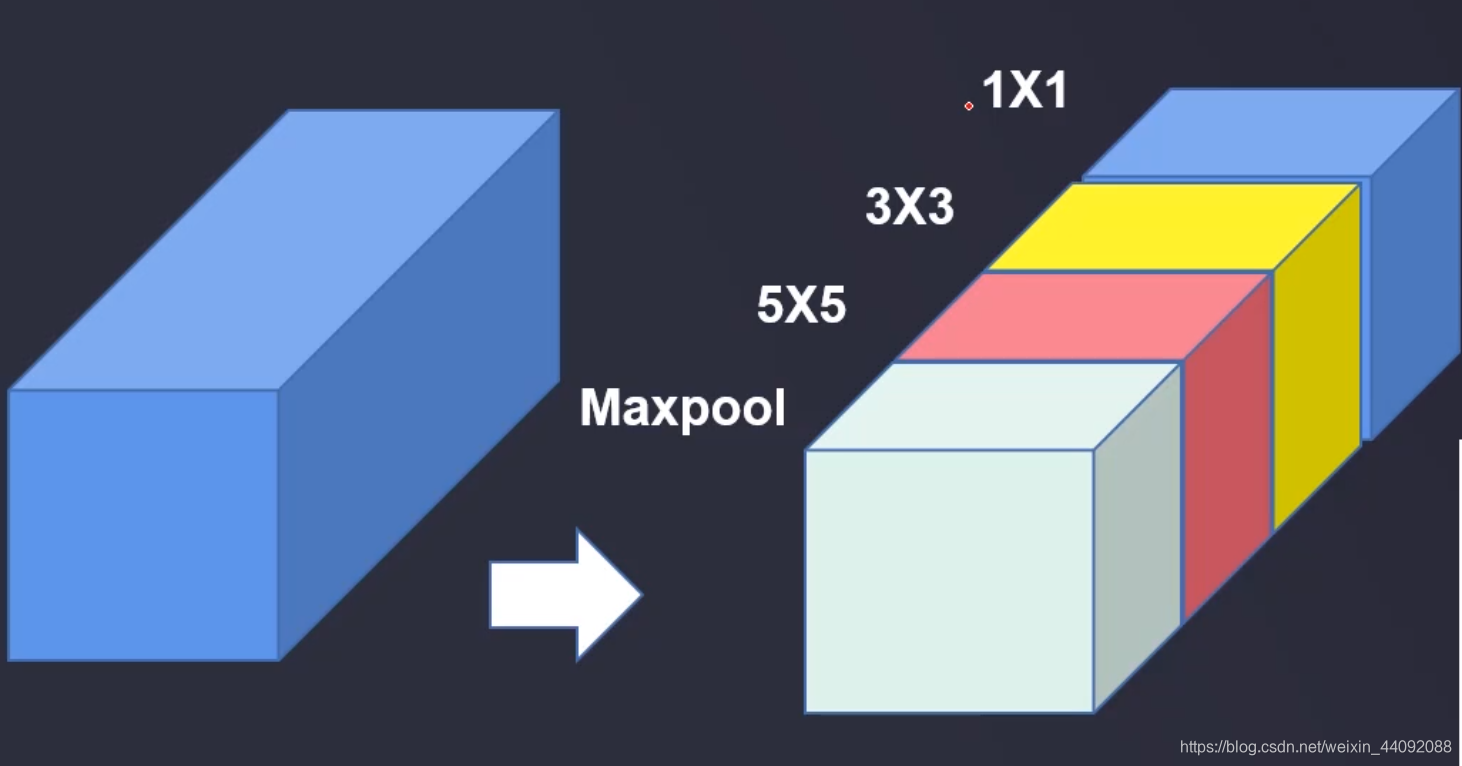
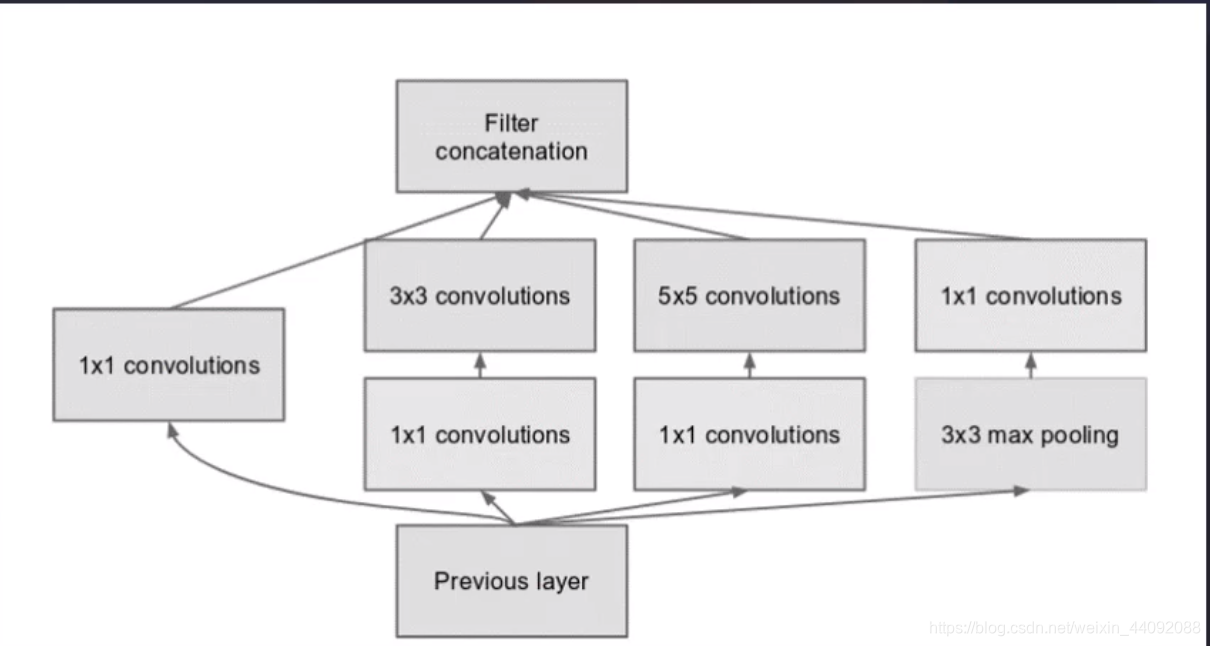
El tipo de tamaño de operador que se debe elegir también se entrega al modelo para la capacitación!
