prefacio
El año pasado, el segundo año, de repente me quiero probar el aprendizaje de la red neural y el aprendizaje profundo. Después de todo, los bloggers quieren hacer es la visión por ordenador más tarde, se veía mi mentor huele un poco en relación con los métodos de aprendizaje, por lo que el maestro me dio un comportamiento animal rancho juez de predecir proyecto. Para ser sincero, al principio mi corazón está todavía muy lejos de la marca, después de todo, en consecuencia, no se ah CpC. Pero la gente no es un cambio cualitativo de 0-1 a mejorarla? Así que compré un montón de libros. Aquí estoy más recomendado
- "La programación Python" de 'China agua de alimentación Pulse' Liu Yu
- 'China Agua de alimentación Pulse' Jiang Ziyang de "TensorFlow profunda algoritmos de aprendizaje y programación de los principios de combate."
- 'Pos Pulse' Kang Yi Saito "aprendizaje profundo portal"
- 'Pos Pulse' Sr. Tariq Rashid "Python neuronal programación de la red."
- 'Pos Pulse' IAN Goodfellow, YOSHUA Bengio, AARON COURVILLE con los tres co-escribió "aprendizaje profundo"
Sobre curso de vídeo, recomiendo a la estación B Mo problemas Python, video Mr. Andrew Ng, y 3Blue1Brown y así sucesivamente.
Uno de montaje para diversos biblioteca
De hecho, tengo un montón de blog que dijo, el blog de pitón o antes si la biblioteca no instala sus propios estudiantes Baidu o leer a mí.
import numpy as np#numpy做矩阵运算十分方便
import math#math函数用来设置一些激活函数
import random#需要随机数来做初始权重
import string
import matplotlib as mpl#如果你需要作图就用上
import matplotlib.pyplot as plt
import sys#需要保存最后的合理权重
import xlrd#因为我的数据集是从excel里面读出来的
from sklearn import preprocessing#需要对数据集做高斯分布或归一化的可以用这个Leer datos
Tengo aquí es el uso de un conjunto de datos de Excel desde el interior respecto a la estancia, si se trata de un amigo o conjuntos de datos MNIST de otras fuentes pueden omitir este paso. Casi una de datos tridimensionales, cada vez que tomo a partir de dos tipos de comportamiento que 500 conjuntos de datos en una matriz, y darles etiquetados 0 o 1. [[[954], [4652], [--456] [1] ]] es casi esto, en frente de la lista tridimensional, seguida de la etiqueta adjunta.
def read_excel():
# 打开Excel
workbook = xlrd.open_workbook('all.xls')
# 进入sheet
eating = workbook.sheet_by_index(0)
sleeping=workbook.sheet_by_index(1)
# 获取行数和列叔
Srows_num=sleeping.nrows
Scols_num=sleeping.ncols
ListSleep=[]
Erows_num = eating.nrows
Ecols_num = eating.ncols
ListEat=[]
ListEatT=[]
ListSleepT=[]
ListT=[]
i = 1
while i <= 500:
if Erows_num > 10 or Srows_num>10:
# 生成随机数
random_numE = random.randint(1, Erows_num - 1)
E_X = eating.row(random_numE)[1].value
E_Y = eating.row(random_numE)[3].value
E_Z = eating.row(random_numE)[5].value
ListEat.append([[int(E_X),int(E_Y),int(E_Z)],[1]])
random_numS = random.randint(1, Srows_num - 1)
S_X = sleeping.row(random_numS)[1].value
S_Y = sleeping.row(random_numS)[3].value
S_Z = sleeping.row(random_numS)[5].value
ListSleep.append([[int(S_X),int(S_Y),int(S_Z)],[0]])
i = i + 1
else:
print("数据不足,请添加")
break
List=ListEat+ListSleep
print(List)
read_excel()II. Función de activación
Aquí es el paso más importante, aplicar una buena calidad de su decisión de activar la función de esta red.
1 , la función sigmoide
curva de función sigmoide como sigue:
función de activación sigmoide, realista, cuando el valor de entrada es pequeño, la salida está cerca de 0; cuando el valor de entrada es grande, el valor de salida está cerca de 1. Pero la función de activación sigmoide tiene una desventaja más grande es principalmente dos cosas:
(1) gradiente propensos desaparece. Cuando el valor de entrada es pequeño o grande, el gradiente tiende a 0, la función correspondiente a la curva de función extremos izquierdo y derecho derivado hacia cero.
(2) el centro de la no-cero, afectará a la dinámica del descenso de gradiente.
def sigmoid(x):
'''
定义sigmoid函数
'''
return 1.0/(1.0+np.exp(-x))
def derived_sigmoid(x):
'''
定义sigmoid导函数
'''
return sigmoid(x)*(1-sigmoid(x))2, la función tanh
curva de función tanh como sigue:
En comparación con el sigmoide, la salida se convierte en 0 en el centro del rango de [-1, 1]. Pero la desaparición del gradiente todavía existe.
def tanh(x):
'''
定义tanh函数
'''
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
def derived_tanh(x):
'''
定义tanh导函数
'''
return 1-tanh(x)*tanh(x)3, la función Relu
La unidad de corrección es una lineal Relu tiene muchas ventajas, la red neuronal es la función de activación más utilizado.
curva de la función de la siguiente manera:
Ventajas: (1) gradiente no va a desaparecer más rápido de convergencia;
(2) antes de la cantidad de cálculo es pequeño, sólo necesitan contar max (0, x), no hay cálculo del índice sigmoide;
(3) cálculos de propagación de vuelta rápida, cálculo derivado simple, no índice se calcula de partida;
(4) Algunas neuronas es 0, por lo que la red tiene propiedades saprse, exceso de montaje se puede reducir.
Desventajas: (1) relativamente vulnerables a la "muerte" en la formación, propagación hacia atrás si el argumento es 0, no se actualizarán este último parámetro. Utilice tasa de aprendizaje apropiado debilitará el caso.
def relu(x):
'''relu函数'''
return np.where(x<0,0,x)
def derivedrelu(x):
'''relu的导函数'''
return np.where(x<0,0,1)4, la función de fugas Relu
Fugas Relu Relu es una mejora sobre las deficiencias, cuando el valor de entrada es menor que 0, el valor de salida de [alfa] x, donde α es una constante pequeña. Tales circunstancias "mueren" no es propenso a reducir la propagación.
def leakyrelu(x,a=0.01):
'''
定义leakyrelu函数
leakyrelu激活函数是relu的衍变版本,主要就是为了解决relu输出为0的问题
'''
return np.where(x<0,a*x,x)
def derived_leakyrelu(x,a=0.01):
'''
定义leakyrelu导函数
'''
return np.where(x<0,a,1)
4, la función elu
# 定义elu函数elu和relu的区别在负区间,relu输出为0,而elu输出会逐渐接近-α,更具鲁棒性。
def elu(x,a=0.01):
#elu激活函数另一优点是它将输出值的均值控制为0(这一点确实和BN很像,BN将分布控制到均值为0,标准差为1)
return np.where(x<0,a*(np.exp(x)-1),x)
def derived_elu(x,a=0.01):
'''
定义elu导函数
'''
return np.where(x<0,a*np.exp(x),1)Además, hay muchos función de activación derivada, por favor usted mismo excavado.
Tres. Un procesamiento de datos normalizados
entrada y salida de datos de pre-procesamiento: escalamiento. También se conoce como escala cambia la normalización o la normalización, el procesamiento de conversión se refiere a la red de datos de entrada y de salida está limitado a [0,1] o [1,1] intervalo y similares. Hay tres razones de transformación:
1). Redes de datos de entrada respectiva a menudo tienen diferente significado y diferentes dimensiones físicas. Todos los componentes son de escala variar dentro de un rango, por lo que el entrenamiento de la red comienza poniendo cada uno la misma importancia a los componentes de entrada;
. 2) sobre la PA neuronas de la red neural se utilizan función sigmoide, la conversión se puede evitar debido a demasiado grande un valor absoluto de la entrada neta de la salida de neurona saturado, por lo que el ajuste de peso, entonces entra en la zona de la superficie error plana;
. 3). Salidas función sigmoide en [1,1] dentro del intervalo [0,1] función tanh o, proceso de conversión de datos de salida si no deseada está obligado a hacer el valor absoluto de error es un componente grande, componente de valor pequeño error absoluto pequeña, corta, los mejores datos a normalizarse.
2, (0,1) Normalización:
Esta es la forma concebible más simple y fácil a través de cada recorrido de datos de vector de características donde el Max y Min del registro, por Max-Min como la base (es decir, Min = 0, Max = 1) normalizaron los datos un tratamiento:
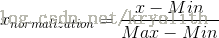
implementación de Python:
def MaxMin(x,Max,Min):
x = (x - Min) / (Max - Min);
return x2, Z-score normalizaron:
Este método de administración de la media en bruto de datos (media) y la desviación estándar (desviación estándar) de los datos normalizados. Procesado de datos de una distribución normal estándar, una media de 0 y desviación estándar 1, una clave compuesta aquí es que la distribución normal estándar:

implementación de Python:
def Z_Score(x,mu,sigma):
x = (x - mu) / sigma;
return x3, la normalización media
En dos formas, el método de normalización como denominador max max-min y el denominador en el método de normalización
def average():
# 均值
average = float(sum(data))/len(data)
# 均值归一化方法
data2_1 = [(x - average )/max(data) for x in data]
data2_2 = [(x - average )/(max(data) - min(data)) for x in data]Tienda. Función de error de función / pérdidas
Un error cuadrático medio Error Cuadrático Medio
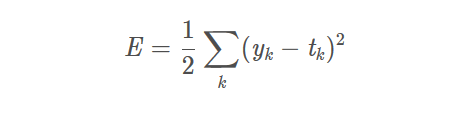
yk es la salida de la NN
tk es una etiqueta, la etiqueta es sólo una respuesta correcta y los demás son 0. k es la dimensionalidad de los datos
de manera que se calcula el error cuadrático medio de la diferencia al cuadrado para cada elemento de la NN salida a los datos correctos de la etiqueta y , y luego buscar la suma.
def get_standard_deviation(records):
"""
标准差 == 均方差 反映一个数据集的离散程度
"""
variance = get_variance(records)
return math.sqrt(variance)En segundo lugar, el promedio Promedio
def get_average(records):
"""
平均值
"""
return sum(records) / len(records)En tercer lugar, el error de entropía cruzada Cruz Entropía error
![]()
de error de entropía cruzada cálculo de las salidas de datos de entrenamiento individuales sólo la solución correcta del logaritmo natural de la etiqueta.
yk es la salida de la etiqueta tk NN, la etiqueta es sólo una solución correcta, y el otro son 0, k es la dimensionalidad
Por lo tanto, cuando la probabilidad de solución correcta NN salida y es 1, la pérdida de entropía cruzada es 0; y como la probabilidad solución correcta disminuye a 0, la pérdida de entropía cruzada se reduce (reducido a un valor negativo, el valor de la pérdida es en realidad el aumento)
def cross_entropy(a, y):
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
# tensorflow version
loss = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1]))
# numpy version
loss = np.mean(-np.sum(y_*np.log(y), axis=1))Kivu. Para construir redes neuronales


Esta cifra anterior es sólo un ejemplo, mi último punto de salida de una sola salida, a juzgar por el comportamiento del juez cercano a 0 ó 1, recomendaciones multi-clasificación Finalmente softmax. pesos iniciales aquí me tienen que decir algo, lo mejor es establecer un múltiplo de 2, y en particular a los estudiantes acelerados por la GPU.
# 构造三层BP网络架构
class BPNN:
def __init__(self, num_in, num_hidden, num_out):
# 输入层,隐藏层,输出层的节点数
self.num_in = num_in + 1 # 增加一个偏置结点
self.num_hidden = num_hidden + 1 # 增加一个偏置结点
self.num_out = num_out
# 激活神经网络的所有节点(向量)
self.active_in = [1.0] * self.num_in
self.active_hidden = [1.0] * self.num_hidden
self.active_out = [1.0] * self.num_out
# 创建权重矩阵
self.wight_in = makematrix(self.num_in, self.num_hidden)
self.wight_out = makematrix(self.num_hidden, self.num_out)
# 对权值矩阵赋初值
for i in range(self.num_in):
for j in range(self.num_hidden):
self.wight_in[i][j] = random_number(-2.4, 2.4)
for i in range(self.num_hidden):
for j in range(self.num_out):
self.wight_out[i][j] = random_number(-0.2, 0.2)
# 最后建立动量因子(矩阵)
self.ci = makematrix(self.num_in, self.num_hidden)
self.co = makematrix(self.num_hidden, self.num_out)propagación hacia adelante, aquí se utiliza el sigmoide como el conjunto inicial normalizada de datos, porque los datos que he aquí el máximo y mínimo tan mal esta brecha y 10003, ya que hay demasiada diferencia entre estos datos deben estar normalización. función de activación tanh como una capa oculta, los datos en la capa oculta se unifican entre [-1,1]. Por último, estos datos se determina por la salida cerca sigmoide a 0 o cerca de 1.
def update(self, inputs):
print(len(inputs))
if len(inputs) != self.num_in - 1:
raise ValueError('输入层节点数有误')
# 数据输入输入层
for i in range(self.num_in - 1):
self.active_in[i] = sigmoid(inputs[i]) #在输入层进行数据处理归一化
self.active_in[i] = inputs[i] # active_in[]是输入数据的矩阵
# 数据在隐藏层的处理
for i in range(self.num_hidden - 1):
sum = 0.0
for j in range(self.num_in):
sum = sum + self.active_in[i] * self.wight_in[j][i]
self.active_hidden[i] = tanh(sum) # active_hidden[]是处理完输入数据之后存储,作为输出层的输入数据
# 数据在输出层的处理
for i in range(self.num_out):
sum = 0.0
print(self.wight_out)
for j in range(self.num_hidden):
sum = sum + self.active_hidden[j] * self.wight_out[j][i]
self.active_out[i] = sigmoid(sum) # 与上同理
return self.active_out[:]
Volver Propagación

# 误差反向传播
def errorback(self, targets, lr, m): # lr是学习率, m是动量因子
if len(targets) != self.num_out:
raise ValueError('与输出层节点数不符!')
# 首先计算输出层的误差
out_deltas = [0.0] * self.num_out
for i in range(self.num_out):
error = targets[i] - self.active_out[i]
out_deltas[i] = derived_sigmoid(self.active_out[i]) * error
# 然后计算隐藏层误差
hidden_deltas = [0.0] * self.num_hidden
for i in range(self.num_hidden):
error = 0.0
for j in range(self.num_out):
error = error + out_deltas[j] * self.wight_out[i][j]
hidden_deltas[i] = derived_tanh(self.active_hidden[i]) * error
# 首先更新输出层权值
for i in range(self.num_hidden):
for j in range(self.num_out):
change = out_deltas[j] * self.active_hidden[i]
self.wight_out[i][j] = self.wight_out[i][j] + lr * change + m * self.co[i][j]
self.co[i][j] = change
# 然后更新输入层权值
for i in range(self.num_in):
for j in range(self.num_hidden):
change = hidden_deltas[j] * self.active_in[i]
self.wight_in[i][j] = self.wight_in[i][j] + lr * change + m * self.ci[i][j]
self.ci[i][j] = change
# 计算总误差
error = 0.0
for i in range(len(targets)):
error = error + 0.5 * (targets[i] - self.active_out[i]) ** 2
return errorj [0] para entrar en la lista de tres dimensiones, j [1] es la tasa de aprendizaje para la etiqueta de cada lista, lr, ya que con la disminución en el gradiente, la tasa de aprendizaje también se reduce como el mejor, al igual que una persona que entrena aprendizaje, al principio hay mucho que aprender, y, finalmente, para aprender la multa.


m MOMENTUMMETHOD algoritmo BP mejorado puede ser utilizado
método impulso se introdujo en la fase de actualización de peso α BP factor de algoritmo de impulso estándar (0 <α <1) , que el valor del peso de corrección con una cierta inercia, es decir, error que no puede sustancialmente cambio ajuste del valor de la señal vuelve a un pequeño pero mayor que la energía total de error y el error total puede resultar conjunto de entrenamiento. En esta ocasión se añadió un factor que contribuye al impulso de la señal de error de retroalimentación hace que el valor de los pesos de las neuronas hasta oscilaciones de nuevo. En la fórmula original de ajuste de peso, el factor de impulso, y el peso añadido de la cantidad de cambio en el tiempo. Se indica que la actualización mayor impulso de la dirección y la magnitud de este valor de peso, calculando un gradiente obtenido con sólo esto, sino también con la última actualización relacionada con la dirección y magnitud. Momentum refleja los ajustes de experiencia acumulada previamente, ajustado para el tiempo t tuvieron un efecto amortiguador. Cuando se produce la repentina fluctuación superficie de error, el choque puede ser reducida tendencia a mejorar la velocidad de entrenamiento.
def train(self, pattern, itera=200000, lr=0.1, a=0.5):
for i in range(itera):
error = 0.0
for j in pattern:
input = j[0]
targ = j[1]
self.update(input)
error = error + self.errorback(targ, lr, m)
if i % 200 == 0:
lr*=0.99
print('误差 %-.5f' % error) Registre el peso final guardado en txt documento
def weights(self):
f = open("getwights.txt", "w")
weightin = []
weightout = []
print("输入层权重")
for i in range(self.num_in):
print(self.wight_in[i])
weightin.append(self.wight_in[i])
print("输入矩阵", weightin)
print("输出层权重")
for i in range(self.num_hidden):
print(self.wight_out[i])
weightout.append(self.wight_out[i])
print("输出矩阵", weightout)
f.write(str(weightin))
f.write("\n")
f.write(str(weightout))
f.close()A continuación, crear una red neuronal, si no está 3X3X1 tipo, también puede modificar su propia, y luego modificarlo en clase el mismo número de nodos que se puede utilizar
def BP():
# 创建神经网络,3个输入节点,3 个隐藏层节点,1个输出层节点
n = BPNN(3, 3, 1)
# 训练神经网络
n.train(List)
# 保存权重值
n.weights()
if __name__ == '__main__':
BP()Ahora que tenemos el derecho de sostener el pesado de formación después de que el último curso de su uso. Y, de hecho, es el mismo que antes, es el peso inicial ya no es un número aleatorio pero nuestro previamente guardado, entonces sólo la propagación hacia adelante.
class BPNN:
def __init__(self, num_in, num_hidden, num_out):
# 输入层,隐藏层,输出层的节点数
self.num_in = num_in + 1 # 增加一个偏置结点
self.num_hidden = num_hidden + 1 # 增加一个偏置结点
self.num_out = num_out
# 激活神经网络的所有节点(向量)
self.active_in = [1.0] * self.num_in
self.active_hidden = [1.0] * self.num_hidden
self.active_out = [1.0] * self.num_out
# 创建权重矩阵
self.wight_in = makematrix(self.num_in, self.num_hidden)
self.wight_out = makematrix(self.num_hidden, self.num_out)
# 对权值矩阵赋初值
f = open("getwights.txt", "r")
a = f.readline()
b = f.readline()
listone = eval(a)
listtwo = eval(b)
f.close()
for i in range(len(listone)):
for j in range(len(listone[i])):
self.wight_in[i][j] = listone[i][j]
for i in range(len(listtwo)):
for j in range(len(listtwo[i])):
self.wight_out[i][j] = listtwo[i][j]
self.co = makematrix(self.num_hidden, self.num_out)
# 信号正向传播
def update(self, inputs):
if len(inputs) != self.num_in - 1:
raise ValueError('与输入层节点数不符')
# 数据输入输入层
for i in range(self.num_in - 1):
# self.active_in[i] = sigmoid(inputs[i]) #或者先在输入层进行数据处理
self.active_in[i] = inputs[i] # active_in[]是输入数据的矩阵
# 数据在隐藏层的处理
for i in range(self.num_hidden - 1):
sum = 0.0
for j in range(self.num_in):
sum = sum + self.active_in[i] * self.wight_in[j][i]
self.active_hidden[i] = tanh(sum) # active_hidden[]是处理完输入数据之后存储,作为输出层的输入数据
# 数据在输出层的处理
for i in range(self.num_out):
sum = 0.0
for j in range(self.num_hidden):
sum = sum + self.active_hidden[j] * self.wight_out[j][i]
self.active_out[i] = sigmoid(sum) # 与上同理
return self.active_out[:]
# 测试
def test(self, patterns):
distingish=[]
List_update=[]
num=0
sum=0
for i in patterns:
List_update.append(self.update(i[0]))
sum=np.sum(List_update,axis=0)
average=sum/(len(patterns))
#print(average)
for i in patterns:
num += 1
if (num <= testnums and self.update(i[0]) > average):
distingish.append(True)
if (num > testnums and self.update(i[0]) < average):
distingish.append(True)
print(i[0], '->', self.update(i[0]))
print("正确率", len(distingish) / num)
# 实例
def BP():
# 创建神经网络,3个输入节点,3个隐藏层节点,1个输出层节点
n = BPNN(3, 3, 1)
# 测试神经网络
n.test(ListT)
if __name__ == '__main__':
BP()Después de la orden
Escribí un artículo sobre Pyecharts se trata de visualización de datos, los amigos que estén interesados pueden ir a ver
https://blog.csdn.net/weixin_43341045/article/details/104137445 ,
Sobre el origen de los datos ah, que puede ser muy muchos, yo estoy aquí para introducir los reptiles. Reptiles hay muchas bibliotecas, escribieron un reptil en el selenio https://blog.csdn.net/weixin_43341045/article/details/104014416 .
9 hay una imagen columna B línea de parada que se arrastra (BeautifulSoup4)
https://blog.csdn.net/weixin_43341045/article/details/104411456
Fue sólo un poco profundas de segundo año de becas mediocre a escribir un experto Opinión reúnen en este país, pero también la esperanza perdonáis a una gran cantidad de señalar experto de alto nivel. Invitamos al país para unirse a nuestro estudio de código de cambio de grupo: 871 352 155 (ya sea que C / C ++ o Java, Python o PHP ...... Estamos interesados son bienvenidos a unirse, pero también, por favor rellene además de información de grupo dentro del grupo se encuentra actualmente en su mayoría estudiantes universitarios, publicidad, Sr. Presidente, por favor, no pereiópodo arriba. esperamos tener las personas mayores visionarios pueden hacer recomendaciones para guiar la dirección de la pantorrilla temprano a punto de entrar en la comunidad).
