Red neuronal convolucional (red neuronal convolucional, CNN)
7.1 Estructura general
En la red neuronal presentada anteriormente, todas las neuronas de las capas adyacentes están conectadas , lo que se denomina completamente conectado.
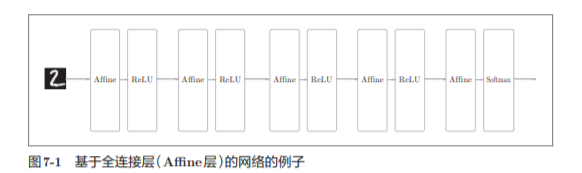
CNN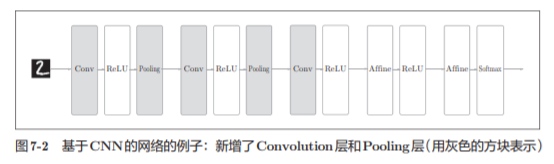
7.2 Capa convolucional
¿Cuál es el problema con la capa completamente conectada? Es decir , se "ignora" la forma de los datos . Por ejemplo, cuando los datos de entrada son una imagen, la imagen suele tener una forma tridimensional en la dirección de la altura, la longitud y el canal.
En CNN, los datos de entrada y salida de la capa convolucional a veces se denominan mapa de características . Donde los datos de entrada se denominan diagrama de características de entrada de la capa de convolución (mapa de características de entrada), los datos de salida se denominan diagrama de características de salida (mapa de características de salida).
7.2.2 Operación de convolución
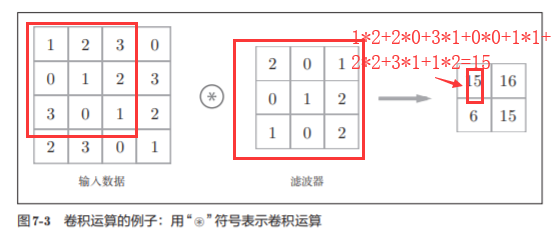
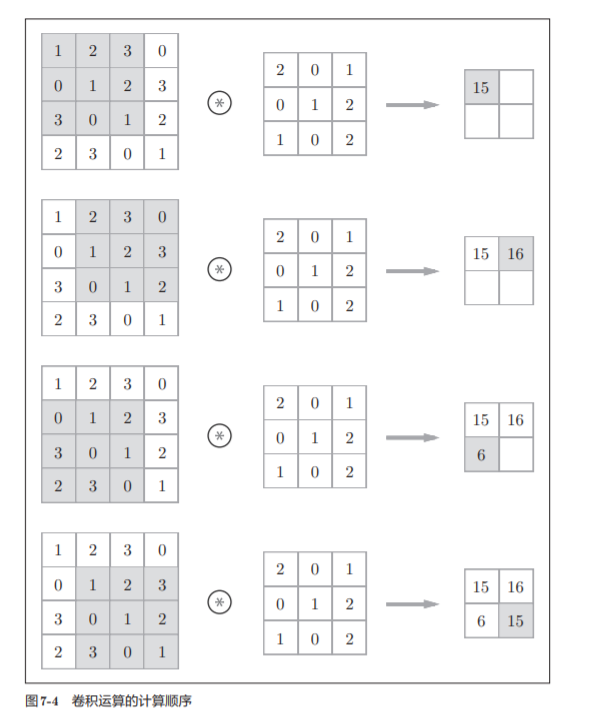
Como se muestra en la Figura 7-4 , el elemento del filtro en cada posición se multiplica por el elemento correspondiente de la entrada y luego se suma (a veces este cálculo se denomina operación de acumulación de multiplicación ).
Documento de referencia:
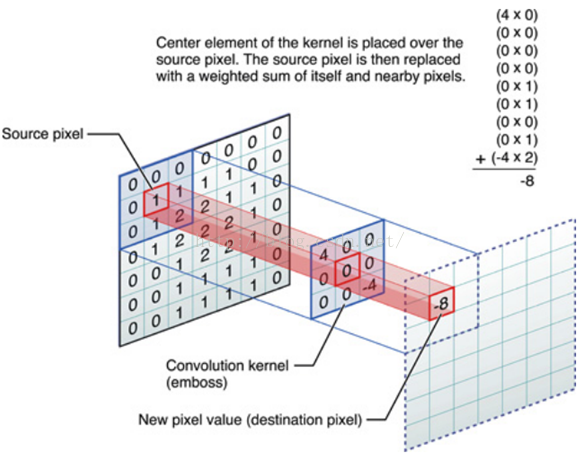
El proceso de cálculo específico:
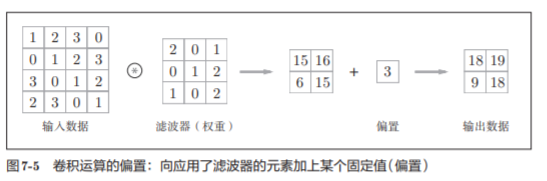
CNN también puede estar sesgada
7.2.3 Llenado
Antes de procesar la capa convolucional, a veces es necesario completar datos fijos (como 0, etc.) alrededor de los datos de entrada, lo que se denomina relleno.
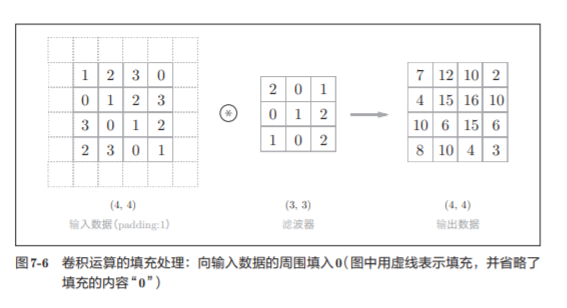
En este ejemplo, el relleno se establece en 1, pero el valor de relleno también se puede establecer en cualquier número entero, como 2, 3.
En el ejemplo de la Figura 7-5, si el relleno se establece en 2, el tamaño de los datos de entrada se convierte en (8, 8); si el relleno se establece en 3, el tamaño se convierte en (10, 10).
El uso de relleno es principalmente para ajustar el tamaño de la salida.
7.2.4 Zancada
El intervalo en el que se aplica el filtro se llama zancada.
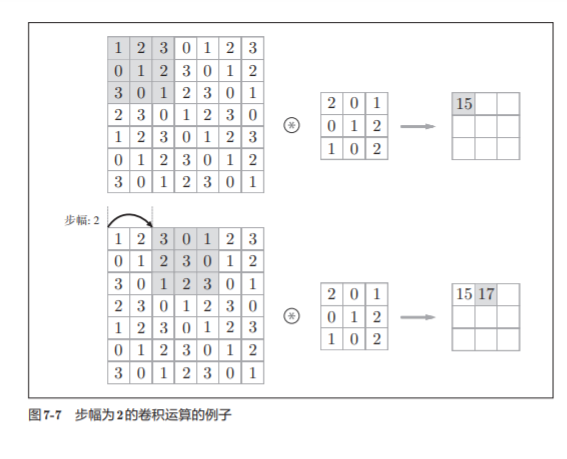
Supóngase que el tamaño de entrada (H, W es) , el tamaño del filtro (FH, FW) , el tamaño de salida es (OH, OW) , lleno de P , un paso S . En este momento, el tamaño de salida se puede calcular mediante la fórmula (7.1)
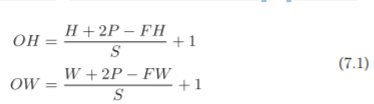
Usa la fórmula para calcular:
Dado que es una división, es necesario prestar atención a si se puede dividir , y si no se puede dividir, se tomarán medidas como la notificación de errores.
Según el marco del aprendizaje profundo, cuando el valor no se puede dividir, a veces se redondea al número entero más cercano y continúa ejecutándose sin informar un error.
7.2.5 Operación de convolución de datos 3D
Los ejemplos anteriores de operaciones de convolución se basan en formas bidimensionales con direcciones altas y largas .
Además de las direcciones de altura y longitud, también es necesario ocuparse de la dirección del canal .
La figura 7-8 es un ejemplo de operación de convolución y la figura 7-9 es la secuencia de cálculo . Aquí , los datos de 3 canales se toman como ejemplo para mostrar el resultado de la operación de convolución.
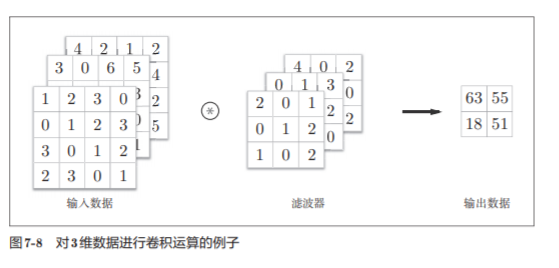
Los datos de entrada y el número de canales del filtro son los mismos, ambos son 3
El número de canales solo se puede establecer en el mismo valor que el número de canales de datos de entrada
7.2.6 Pensando con cubos
Al expresar datos tridimensionales como una matriz multidimensional, el orden de escritura es (canal, alto, ancho) . Por ejemplo, la forma de los datos con el número de canal C, la altura H y la longitud W se pueden escribir como (C, H, W). Cuando el número de canales es C, la altura del filtro es FH (Altura del filtro) y la longitud es FW (Ancho del filtro), se puede escribir como (C, FH, FW)
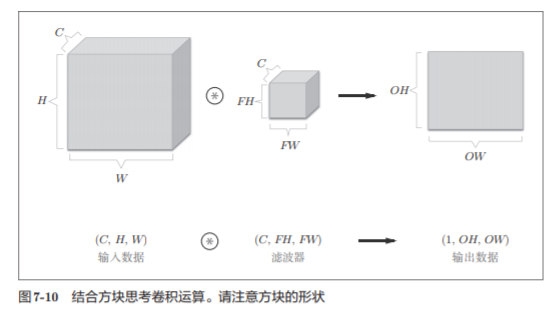
En este ejemplo, la salida de datos es un mapa de características. La figura denominada característica , en otras palabras, sobre el número de canales se caracteriza en la FIG . Entonces, ¿qué sucede si desea tener la salida de múltiples operaciones de convolución en la dirección del canal?
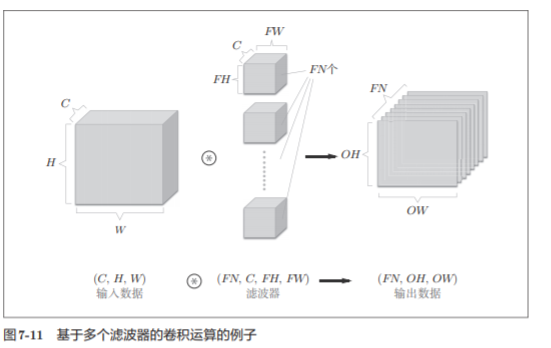
Como se muestra en la Figura 7-11, con respecto al filtro de la operación de convolución, también se debe considerar el número de filtros . Por lo tanto, como datos de 4 dimensiones, los datos de peso del filtro deben escribirse en el orden de (output_channel, input_channel, height, width).
Por ejemplo, cuando hay 20 filtros con 3 canales y un tamaño de 5 × 5, se pueden escribir como (20, 3, 5, 5).
El formato es muy importante
En el ejemplo de la figura 7-11, si se agrega más el procesamiento de adición de compensación , el resultado se muestra en la figura 7-12 a continuación.
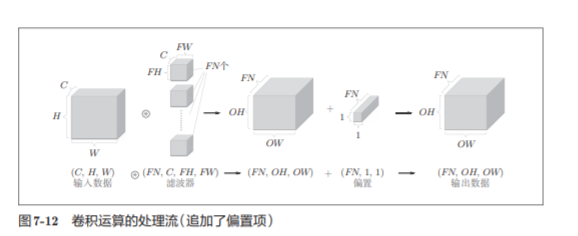
7.2.7 Procesamiento por lotes
El lote Resumen del procesamiento de N veces se convirtieron en una vez eran

7.3 Capa de agrupación
La agrupación es una operación para reducir el espacio en las direcciones de altura y longitud .
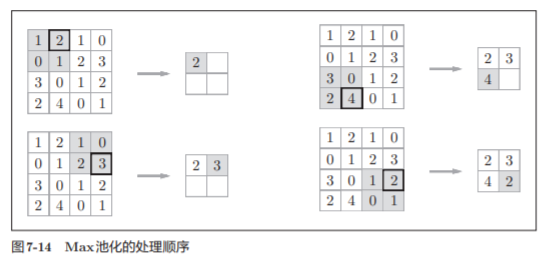
El tamaño de la ventana agrupada se establecerá en el mismo valor que la zancada
Características de la capa de agrupación
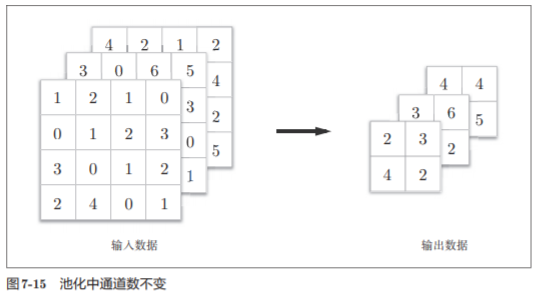
- El número de canales no cambia
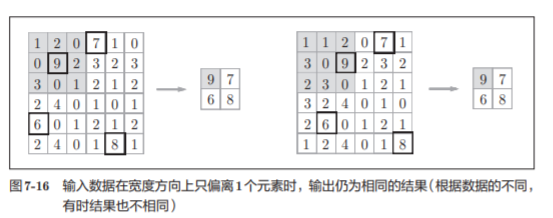
- Robusto a pequeños cambios de posición (robusto)
7.4 Implementación de la capa convolucional y la capa de agrupación
7.4.1 Matriz de 4 dimensiones
Los datos transferidos entre capas en CNN son datos de 4 dimensiones .


7.4.2 Expansión basada en im2col
El nombre im2col es la abreviatura de "imagen a columna" , que se traduce como " de imagen a matriz ".
No usamos la instrucción for, pero usamos la conveniente función im2col para una implementación simple.
im2col es una función que expande los datos de entrada para ajustarse al filtro (peso) . Como se muestra en la figura 7-17, después de los datos de entrada de la aplicación im2col tridimensional, matriz bidimensional en datos (hablando con propiedad, el paquete debe contener la cantidad de lote de datos tetradimensionales convertidos en datos bidimensionales ).
im2col expandirá los datos de entrada para ajustarse al filtro (peso) . Específicamente, como se muestra en la figura 7-18, para los datos de entrada, el área (cuadrado tridimensional) a la que se aplica el filtro se expande horizontalmente en una columna. im2col realizará este proceso de expansión dondequiera que se aplique el filtro.
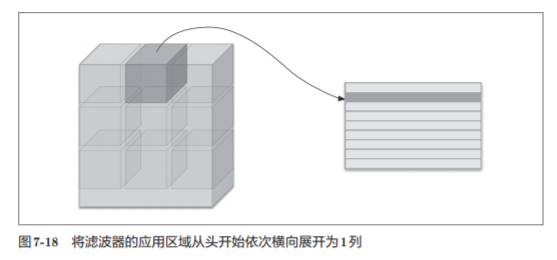
Nota:
- Para facilitar la observación , el ancho del paso se establece para que sea grande, de modo que el área de aplicación del filtro no se superponga.
- En la operación de convolución real, las áreas de aplicación de los filtros casi se superponen .
Después de usar im2col para expandir, el número de elementos expandidos será mayor que el del cuadrado original .
Por lo tanto, la implementación que usa im2col tiene la desventaja de consumir más memoria que la implementación ordinaria .
Sin embargo, las operaciones de matriz grande se pueden optimizar
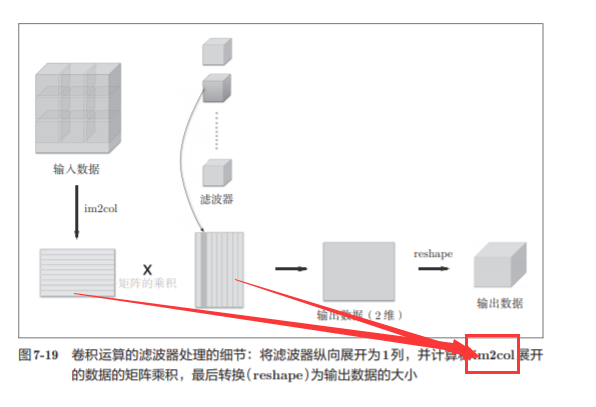
7.4.3 Implementación de la capa convolucional

Im2col considerará el tamaño del filtro, la zancada y el relleno , y expandirá los datos de entrada en una matriz de 2 latitudes
Utilice la fórmula mencionada anteriormente

La siguiente es la clase de implementación de la capa convolucional :

La función de transposición puede intercambiar la posición del elemento correspondiente del índice basado en Numpy:
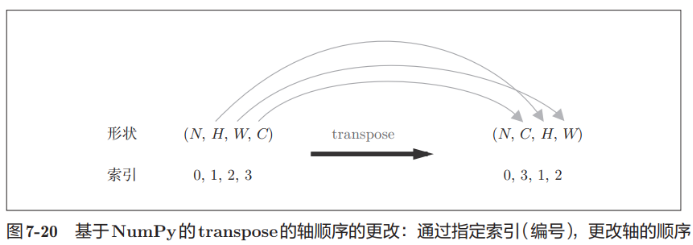
Nota:
(Peso), compensación, zancada y relleno se reciben como parámetros.
El filtro tiene una forma de 4 dimensiones de (FN, C, FH, FW) . Además, FN, C, FH y FW son las abreviaturas de Número de filtro, Canal, Altura del filtro y Ancho del filtro, respectivamente.
7.4.4 Implementación de la capa de agrupación
La capa de agrupación se puede expandir por separado por canal, como se muestra en la siguiente figura:
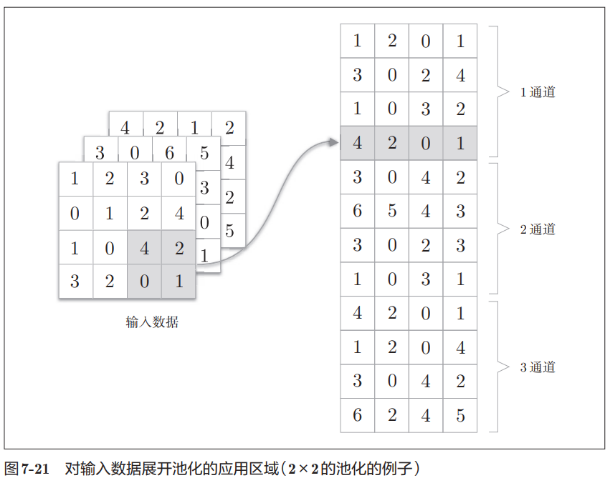
Después de la expansión, seleccione la función requerida de acuerdo con las filas de la matriz y seleccione el valor . Por ejemplo, aquí se usa la función max. Después de tomar el valor, la función de remodelación se puede usar para reconstruir la dimensión, como se muestra en la figura:
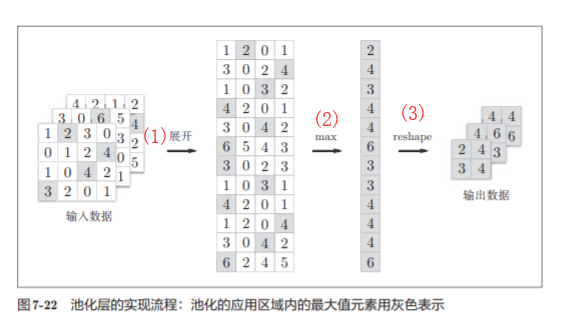
Clase de implementación de la capa de agrupación:
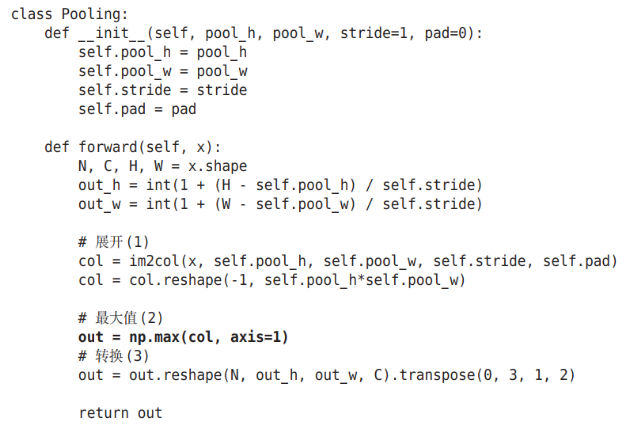
Resumen: 3 pasos para realizar la capa de agrupación:
1. Amplíe los datos de entrada
2. Encuentra el valor máximo de cada fila
3. Convierta a un tamaño de salida adecuado
7.5 Implementación de CNN
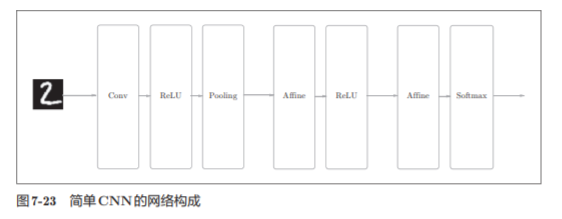
Hemos implementado la capa convolucional y la capa de agrupación, ahora combinemos estas capas.
Construya CN N para el reconocimiento de dígitos escritos a mano . Aquí para implementar la CNN como se muestra en la figura
Inicialización de SimpleConvNet (__init__)

Código de implementación:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""简单的ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 输入大小(MNIST的情况下为784)
hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
output_size : 输出大小(MNIST的情况下为10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
# 只有SoftmaxWithLoss层被添加到别的变量lastLayer中
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数
参数x是输入数据、t是教师标签
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""求梯度(数值微分)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
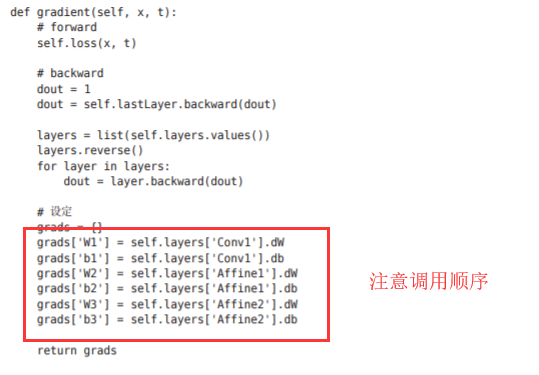
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]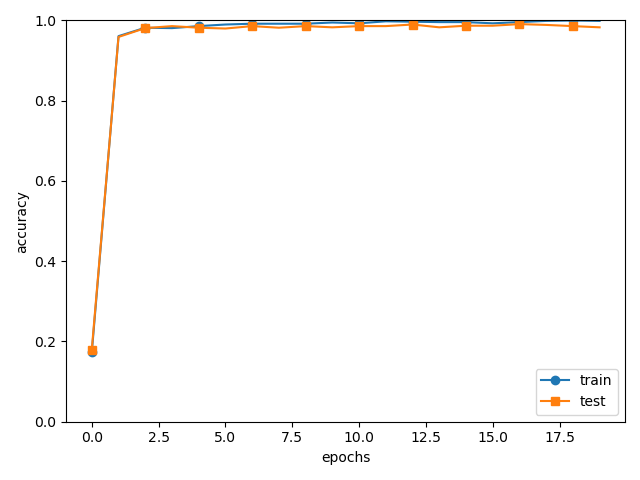
prueba acc: 0.9892
Nota:
Deje que el peso de la capa convolucional de la primera capa sea la palabra clave W 1 y el sesgo sea la palabra clave b1 . Del mismo modo, utilice las palabras clave W2, b2 y las palabras clave W3, b3 para guardar los pesos y los sesgos de la segunda y tercera capas completamente conectadas, respectivamente.
Función de predicción y pérdida

Se basa en el método de retropropagación del error para encontrar el gradiente.
La parte de implementación es la misma que la anterior:
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
# 处理花费时间较长的情况下减少数据
#x_train, t_train = x_train[:5000], t_train[:5000]
#x_test, t_test = x_test[:1000], t_test[:1000]
max_epochs = 20
network = SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
# 保存参数
network.save_params("params.pkl")
print("Saved Network Parameters!")7.6 Visualización de CNN
7.6.1 Visualización de pesos de capa 1
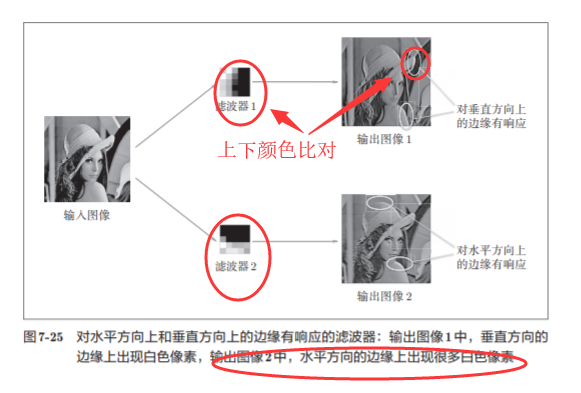
Mostramos el filtro de la capa convolucional (capa 1) como una imagen

El filtro antes del aprendizaje se inicializa aleatoriamente , por lo que no hay una regla a seguir en las sombras en blanco y negro, pero el filtro después del aprendizaje se convierte en una imagen regular.
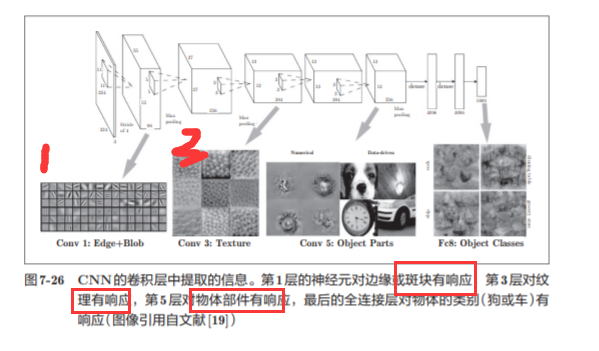
7.6.2 Extracción de información basada en estructura jerárquica
A medida que el nivel se profundiza , la información extraída (hablando correctamente, las neuronas que reflejan con fuerza) se vuelve cada vez más abstracta.
7.7 Representante de CNN
7.7.1 LeNet

Tiene una capa convolucional continua y una capa de agrupación (hablando correctamente, una capa de submuestreo que solo "selecciona elementos"), y finalmente genera el resultado a través de una capa completamente conectada .
En comparación con la "CNN actual", LeNet tiene varias diferencias:
-
La primera diferencia radica en la función de activación . La función sigmoidea se usa en LeNet, y la función ReLU se usa principalmente en la CNN actual.
-
El LeNet original que usa submuestreo (submuestreo) reduce el tamaño de los datos intermedios , ahora en la celda CNN de la corriente principal Max
Aunque LeNet es ligeramente diferente de la CNN actual, la diferencia no es tan grande.
7.7.2 AlexNet
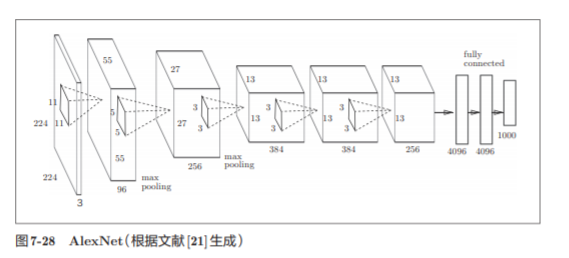
Su estructura de red es básicamente la misma que la de LeNet. AlexNet tiene múltiples capas convolucionales y capas de agrupación, y finalmente genera el resultado a través de una capa completamente conectada.
No hay una gran diferencia entre AlexNet y LeNet, pero existen las siguientes diferencias

resumen
- CNN agrega una capa convolucional y una capa de agrupación a la red de capa anterior completamente conectada.
- El uso de la función im2col puede implementar la capa convolucional y la capa de agrupación de manera simple y eficiente.
- A través de la visualización de CNN, se puede ver que a medida que el nivel se profundiza, la información extraída se vuelve más avanzada.
- LeNet y AlexNet son redes representativas de CNN.
- En el desarrollo del aprendizaje profundo, big data y GPU han hecho grandes contribuciones.
Convolution-ReLu función-agrupación capa-convolución-ReLu función-agrupación capa-convolución-ReLu función-Affine-ReLu-Affine-Softmax