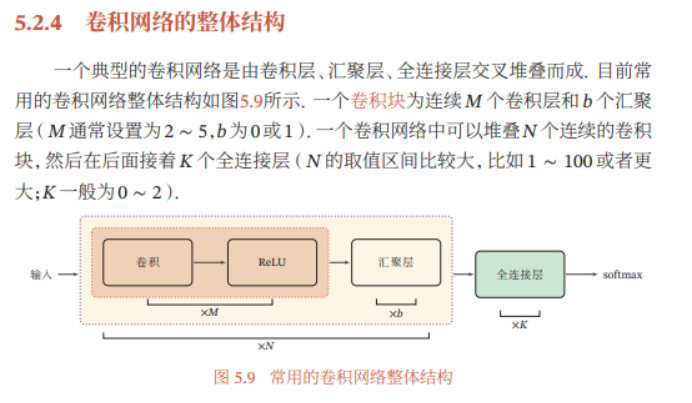
descripción general
Este artículo solo presenta la capa de convolución, la capa de agrupación y otros principios de construcción y estructura de red, así como algunos conocimientos previos sobre convolución. El contenido de la capa totalmente conectada, la construcción y optimización del modelo de clasificación y la función de pérdida son los mismos que los de la red neuronal totalmente conectada y no se explicarán aquí.
Construcción de modelos de redes neuronales e introducción de algoritmos: https://blog.csdn.net/stephon_100/article/details/125452961
La red neuronal convolucional es una red neuronal de alimentación hacia adelante profunda. Convolucionar la misma imagen con diferentes núcleos de convolución es en realidad filtrar la imagen con núcleos de convolución para extraer diferentes características.
Por lo tanto, el modelo de red neuronal convolucional también es un modelo para extraer características automáticamente, con funciones de clasificación.
Suponiendo que el número de neuronas de entrada en la capa convolucional es M, el tamaño de la convolución es K, el tamaño del paso es S y los ceros P se rellenan en ambos extremos de la entrada, entonces el número de neuronas en la capa convolucional es (M - K + 2P )/S+1
![]() Por lo general, se puede convertir en un número entero eligiendo el tamaño de convolución y el paso adecuados .
Por lo general, se puede convertir en un número entero eligiendo el tamaño de convolución y el paso adecuados .
contenido principal:
La red neuronal convolucional (CNN o ConvNet) es una red neuronal de avance profundo con conexiones locales y peso compartido.
La red neuronal convolucional se usó originalmente principalmente para procesar información de imágenes. Cuando se procesan imágenes con una red feedforward totalmente conectada, hay dos problemas:
(1) Hay demasiados parámetros: si el tamaño de la imagen de entrada es 100 × 100 × 3 (es decir, la altura de la imagen es 100, el ancho es 100 y los canales de color RGB 3), en la red feedforward completamente conectada, cada uno de los primera capa oculta Hay 100 × 100 × 3 = 30 000 conexiones independientes entre sí desde cada neurona a la capa de entrada, y cada conexión corresponde a un parámetro de peso. Con el aumento del número de neuronas en la capa oculta, la escala de los parámetros también aumentará considerablemente. Esto conducirá a una eficiencia de entrenamiento muy baja de toda la red neuronal y también es propensa al sobreajuste.
(2) Características de invariancia local: los objetos en imágenes naturales tienen características de invariancia local, como escalado, traslación, rotación y otras operaciones que no afectan su información semántica. Sin embargo, las redes feedforward totalmente conectadas son difíciles de extraer de estas características invariantes locales y, por lo general, se requiere una mejora de los datos para mejorar el rendimiento.
La capa completamente conectada generalmente se encuentra en la última capa de la red convolucional. Las redes neuronales convolucionales tienen tres propiedades estructurales: conexiones locales, peso compartido y agrupación. Estas propiedades hacen que la red neuronal convolucional sea invariable a la traducción, escala y rotación hasta cierto punto. En comparación con la red neuronal feedforward, la red neuronal convolucional tiene menos parámetros.
Preparar conocimientos complementarios.
Definición de convolución : La convolución, también llamada convolución, es una operación importante en las matemáticas analíticas. En el procesamiento de señales o procesamiento de imágenes, a menudo se utilizan convoluciones unidimensionales o bidimensionales.
Convolución unidimensional:

Convolución bidimensional:

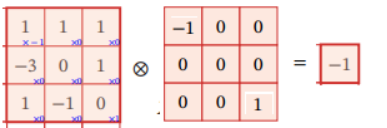
De acuerdo con la definición de convolución, el cálculo en la figura anterior requiere volcar el kernel de convolución. Voltear se refiere a invertir la correlación cruzada de dos dimensiones (de arriba a abajo, de izquierda a derecha) en un orden invertido, es decir, una rotación de 180 grados. Después de voltear, la operación del producto escalar se puede realizar directamente, es decir, las posiciones correspondientes se multiplican y luego se suman. Como se muestra en la imagen:
El filtro medio (Mean Filter) comúnmente utilizado en el procesamiento de imágenes es una convolución bidimensional, que establece el valor del píxel en la posición actual como el valor promedio de todos los píxeles en la ventana del filtro, es decir![]()
Pantalla de visualización:
En el procesamiento de imágenes, la convolución se usa a menudo como un método efectivo para la extracción de características. El resultado obtenido después de que una imagen se someta a una operación de convolución se denomina mapa de características. La figura 5.3 muestra varios filtros de uso común en el procesamiento de imágenes y sus correspondientes mapas de características. El filtro superior en la figura es un filtro gaussiano de uso común, que se puede usar para suavizar y eliminar el ruido de la imagen; los filtros central e inferior se pueden usar para extraer características de los bordes.

Por lo tanto, se concluye que convolucionar una imagen con un núcleo de convolución es en realidad filtrar una imagen con un núcleo de convolución para extraer características específicas.
( 3 ) Correlación cruzada
En el campo del aprendizaje automático y el procesamiento de imágenes, la función principal de la convolución es deslizar un núcleo de convolución (es decir, filtrar) en una imagen (o ciertas características) y obtener un nuevo conjunto de características a través de operaciones de convolución. En el proceso de cálculo de la convolución, el kernel de convolución debe invertirse. En la implementación específica, la convolución generalmente se reemplaza por operaciones de correlación cruzada, lo que reducirá algunas operaciones innecesarias o sobrecarga.
La correlación cruzada (Cross-Correlation) es un orden inverso, es decir, girado 180 grados. La función para medir la correlación entre dos secuencias generalmente se implementa calculando el producto escalar con una ventana deslizante. Dada una imagen ![]() y un núcleo de convolución
y un núcleo de convolución ![]() , su correlación cruzada es:
, su correlación cruzada es:

Comparando con la fórmula (5.7), podemos ver que la diferencia entre correlación cruzada y convolución es solo si el kernel de convolución está invertido. Por lo tanto, la correlación cruzada también puede llamarse convolución no invertida.

Comparación de convolución y correlación cruzada (extendida):
Se puede ver que la relación entre la operación de convolución y la operación de correlación cruzada es:

Dada una imagen ![]() y un núcleo de convolución
y un núcleo de convolución ![]() , su correlación cruzada es
, su correlación cruzada es

Comparando con la fórmula (5.7), podemos ver que la diferencia entre correlación cruzada y convolución es solo si el kernel de convolución está invertido. Por lo tanto, la correlación cruzada también puede llamarse convolución no invertida.
Por lo tanto, la correlación cruzada generalmente se implementa directamente mediante el cálculo del producto escalar de la ventana deslizante, en lugar de una convolución matemática estricta que consiste en voltear la ventana deslizante y luego calcular el producto escalar.
El uso de la convolución en las redes neuronales es para la extracción de características, y si el kernel de convolución se invierte no tiene nada que ver con sus capacidades de extracción de características. Especialmente cuando el kernel de convolución es un parámetro que se puede aprender, la convolución y la correlación cruzada son equivalentes en potencia. Por lo tanto, por conveniencia de implementación (o descripción), usamos correlación cruzada en lugar de convolución. De hecho, las operaciones de convolución en muchas herramientas de aprendizaje profundo son en realidad operaciones de correlación cruzada.
En la siguiente descripción, a menos que se indique lo contrario, la convolución generalmente se refiere a "correlación cruzada". El símbolo de convolución está representado por ⊗, es decir, la convolución no está invertida. La convolución real se denota con *.
Sobre la base de la definición estándar de convolución, el tamaño de paso deslizante y el relleno cero del kernel de convolución también se pueden introducir para aumentar la diversidad de convolución y realizar la extracción de características de manera más flexible.
Stride se refiere a la cantidad de píxeles cada vez que el kernel de convolución se desliza al deslizarse.
El relleno de ceros es un relleno de ceros en ambos extremos del vector de entrada.
Suponiendo que el número de neuronas de entrada en la capa convolucional es M, el tamaño de la convolución es K, el tamaño del paso es S y los ceros P se rellenan en ambos extremos de la entrada, entonces el número de neuronas en la capa convolucional es ( M - K + 2P)/S+1
![]() Por lo general, se puede convertir en un número entero eligiendo el tamaño de convolución y el paso adecuados .
Por lo general, se puede convertir en un número entero eligiendo el tamaño de convolución y el paso adecuados .
red neuronal convolucional
Según la definición de convolución, la capa convolucional tiene dos propiedades muy importantes: conexión local y peso compartido.


Tome la imagen de arriba como un ejemplo:
Si se trata de una operación completamente conectada, cada neurona necesita conectar todos los 25 píxeles de entrada x anteriores, por lo que hay 25 pesos w y 1 sesgo b.
Pero si se trata de una operación de convolución, toda la imagen de 5x5 solo usa esta ventana del kernel de convolución para deslizarse, por lo que el parámetro de peso solo requiere un tamaño de ventana de convolución de 3x3=9 parámetros y un parámetro de polarización b. La figura anterior se basa en el paso tamaño Es 1 y el resultado de la convolución obtenido al deslizar la ventana sin sumar 0 en ambos extremos de la imagen
Por lo general, el tamaño del kernel de convolución es mucho más pequeño que el tamaño de la imagen de entrada que se está convolucionando, por lo que la operación de convolución requiere que se entrenen muchos menos parámetros que la conexión completa.
(1) capa de convolución
La función de la capa convolucional es extraer una imagen filtrada de la imagen de entrada, es decir, una característica de la imagen de entrada. Diferentes núcleos de convolución son equivalentes a diferentes extractores de características. El contenido mencionado anteriormente es la convolución de imágenes bidimensionales. Pero, por lo general, una imagen en color se compone de múltiples canales de color, por lo que generalmente se representa como información tridimensional. Luego, las neuronas del kernel de convolución también están enrevesadas en tres dimensiones.
La estructura tridimensional generalmente se expresa como, su tamaño es alto x ancho x profundidad, es decir, MxNxD,
En la capa de entrada, el mapa de características es la imagen misma. Si es una imagen en escala de grises, hay un mapa de características y la profundidad de la capa de entrada es D=1; si es una imagen en color, hay mapas de características de canales de tres colores RGB y la profundidad de la capa de entrada es D=3.
Un mapa de características es una característica extraída por una imagen (u otro mapa de características) después de la convolución, y cada mapa de características se puede usar como una clase de características de imágenes extraídas. Para mejorar la capacidad de representación de la red convolucional, se pueden apilar múltiples núcleos de convolución diferentes en cada capa convolucional para obtener múltiples mapas de características diferentes de una imagen para representar mejor las características de la imagen.

Explicación: cada capa convolucional contiene neuronas P, es decir, el kernel de convolución, por lo que la convolución de esta capa generará mapas de características P. El tamaño de una imagen de entrada es MxN y la profundidad es D. Si es una imagen en color, hay 3 canales de RGB, por lo que d=3. El tamaño del kernel de convolución es del tamaño de UxV, y la profundidad es D.

(2) Capa de agrupación (capa de agrupación)
La capa de agrupación (Pooling Layer) también se denomina capa de submuestreo (Capa de submuestreo), y la función de la capa de agrupación es realizar la selección de características y reducir la cantidad de características, reduciendo así la cantidad de parámetros y evitando el sobreajuste.
(1) Agrupación máxima (Agrupación máxima o Agrupación máxima): para una región, seleccione el valor de actividad máxima de todas las neuronas en esta región como la representación de esta región
(2) Mean Pooling: Generalmente, se toma el valor promedio de los valores de actividad de todas las neuronas del área.
La capa de agrupación no solo puede reducir efectivamente la cantidad de neuronas, sino que también puede hacer que la red sea invariable a algunos pequeños cambios de forma locales y tenga un campo receptivo más grande.
Una capa de agrupación típica divide cada mapa de características en regiones de 2 × 2 que no se superponen y, a continuación, utiliza el método de agrupación máxima para la reducción de resolución. La capa de agrupación también se puede considerar como una capa de convolución especial, el tamaño del núcleo de convolución es KxK, el tamaño de paso es SxS y el núcleo de convolución es una función máxima o una función media. Un área de muestreo demasiado grande reducirá drásticamente el número de neuronas y provocará una pérdida de información excesiva.