prefacio
blog anterior: el aprendizaje tensorflow (4) - con pendiente formación tensorflow y la intersección de una función lineal
para resolver el problema de la devolución de este capítulo.
La introducción de los respectivos paquetes
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
nivel de red neuronal
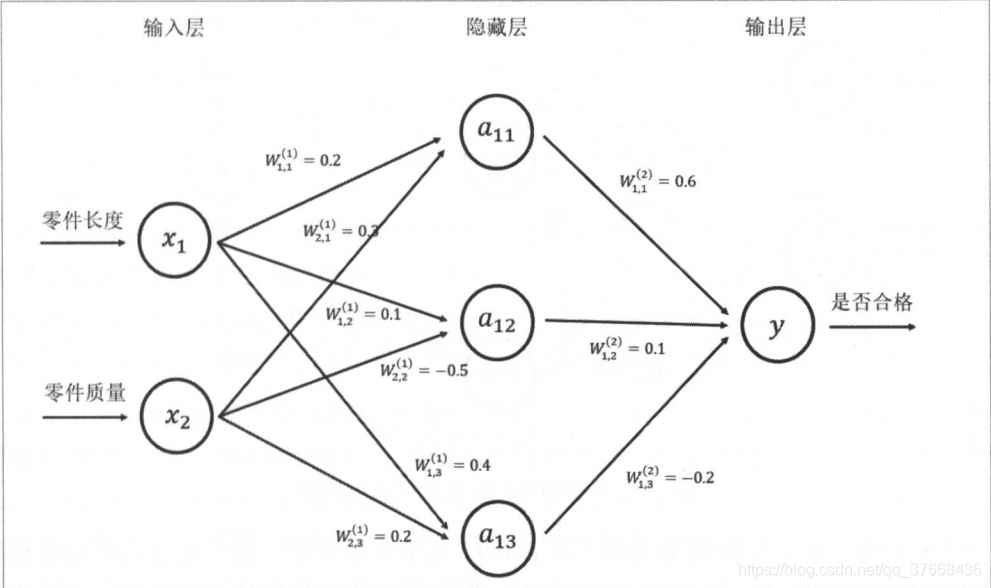
Aquí figura escoger un libro con el lado más a la izquierda es la capa de entrada de la red, en nuestro caso, se muestra el uso numpy generada al azar (x_data, y_data), W representa el peso.
Preparar la muestra de prueba
#使用numpy来生成200个随机点,等差数列
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise = np.random.normal(0,0.02,x_data.shape)
y_data = np.square(x_data) + noise
Consejos:
- [:, Np.newaxis] que es una matriz de dimensión L, que representa el rango del parámetro antes de que la dimensión litros por comas, como [1: 5, newaxis] denotan los miembros de la matriz 1-5 litros dimensiones.
- linspace (-0.5,0.5,200) Esta función es el primer parámetro, a partir de un segundo extremo, el tercero es el número total. Para la generación de una secuencia aritmética.
Diseño de la capa intermedia
#定义神经网络中间层
Weights_L1 = tf.Variable(tf.random_normal([1,10]))
biases_L1 = tf.Variable(tf.zeros([1,10]))
Wx_plus_b_L1 = tf.matmul(x,Weights_L1) + biases_L1
#激活函数
L1 = tf.nn.tanh(Wx_plus_b_L1)
Consejos:
- Weights_L1: Este es el peso de la primera capa, oculto peso de capa de esta capa de entrada x_data sólo un nodo, tf.random_normal ([1,10]) de la primera parámetro se establece en 1, entonces queremos diseñar neuronas diez, por lo el segundo parámetro se establece en 10.
- biases_L1: Este es el parámetro de desviación, y Weights_L1 como entrada sólo un nodo, queremos diseñar neuronas diez en la capa intermedia, el conjunto de parámetros a tf.Variable (tf.zeros ([1,10]))
- Wx_plus_b_L1: Esta es la figura de arriba a11, los resultados de a12, a13, introduzca la matriz por la matriz de ponderación más la matriz offset.
- L1 = tf.nn.tanh (Wx_plus_b_L1): Esta es la parte de núcleo de la red neuronal, hemos mencionado anteriormenteEnter the Matrix por la matriz de ponderación más la matriz de desplazamientoEsta frase puede saber, obviamente, una relación entre la entrada y la salida es lineal, pero en nuestro ejemplo, la muestra es una función cuadrática, al parecer por y = kx + b dichas líneas es que no podemos encajar bien curva, la función de activación se utiliza aquí es un tanh, acoplado a la lineal no lineal posible.
capa de salida Diseño
#定义输出层
Weights_L2 = tf.Variable(tf.random_normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2 = tf.matmul(L1,Weights_L2) + biases_L2
#激活函数
prediction = tf.nn.tanh(Wx_plus_b_L2)
Consejos:
- Weights_L2: Debido a que hemos diseñado neuronas anterior diez de la capa intermedia, la capa de salida, donde el peso correcto tf.Variable (tf.random_normal ([10,1])) El primer argumento se establece en 10, a continuación, ya que sólo hay una salida Y, por lo que el segundo parámetro se establece en 1.
- biases_L2: matriz sesgo Dimensión se proporciona con la misma matriz de ponderación.
- Wx_plus_b_L2: matriz de entrada por la matriz de ponderación más la matriz offset.
- predicción = tf.nn.tanh (Wx_plus_b_L2): la función de activación el mismo significado anteriormente.
formación
#二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
#用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
for i in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获得预测值
prediction_value = sess.run(prediction,feed_dict = {x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()
los resultados del entrenamiento
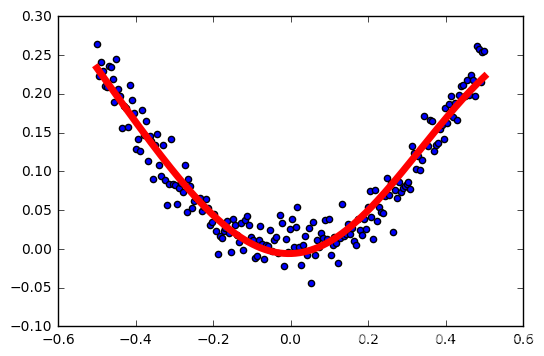
prueba de la función de activación
Leer un montón de argumento en línea función de activación, relu de uso común, tanh, sigmoide y así sucesivamente.
La razón para utilizar estas funciones están las siguientes consideraciones:
- no lineal
- rango de salida Limited, es adecuado como una capa de salida
- De salida está centrada en 0
- Fácil de calcular
- valor Hengda no es menor que cero a cero o una constante
- ...
Principiante red neuronal, ver el principio de explicación realmente no entiendo, tratar de cambiar algunos parámetros aquí y echar un vistazo a la diferencia entre la función de activación.
Relu utiliza como función de activación
función de activación: relu
#使用numpy来生成200个随机点,等差数列
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise = np.random.normal(0,0.02,x_data.shape)
y_data = np.square(x_data) + noise
#定义两个palceholder
x = tf.placeholder(tf.float32,[None,1])
y = tf.placeholder(tf.float32,[None,1])
#定义神经网络中间层
Weights_L1 = tf.Variable(tf.random_normal([1,10]))
biases_L1 = tf.Variable(tf.zeros([1,10]))
Wx_plus_b_L1 = tf.matmul(x,Weights_L1) + biases_L1
#激活函数
L1 = tf.nn.relu(Wx_plus_b_L1)
#定义输出层
Weights_L2 = tf.Variable(tf.random_normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2 = tf.matmul(L1,Weights_L2) + biases_L2
#激活函数
prediction = tf.nn.relu(Wx_plus_b_L2)
#二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
#用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)#修改学习率!!!
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
for i in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获得预测值
prediction_value = sess.run(prediction,feed_dict = {x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()
salida
tasa de aprendizaje: 0,04

tasa de aprendizaje: 0,1
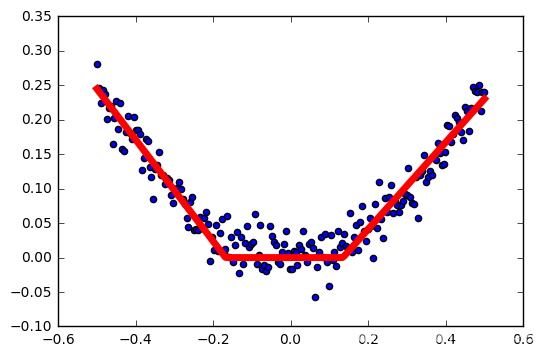
tasa de aprendizaje: 0,2
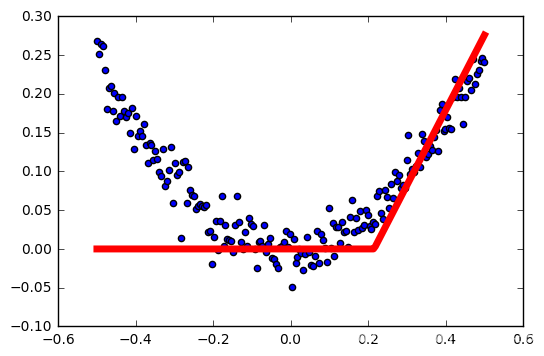
tasa de aprendizaje: 0,3
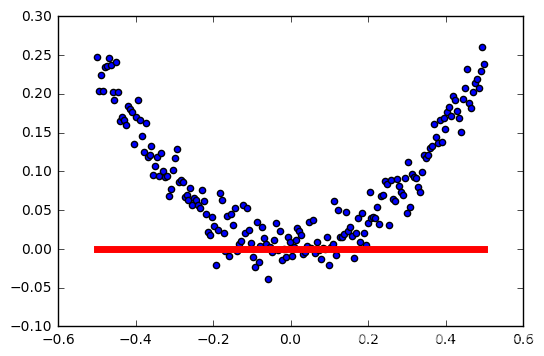
tasa de aprendizaje: 0,4
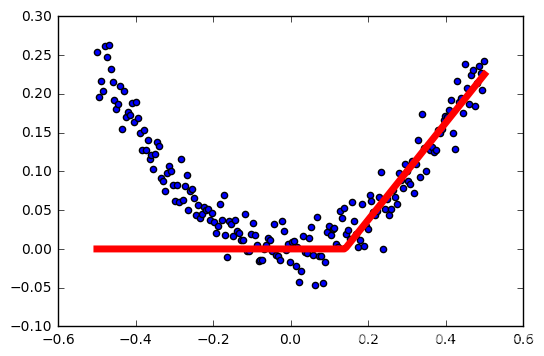
tasa de aprendizaje: 0,5
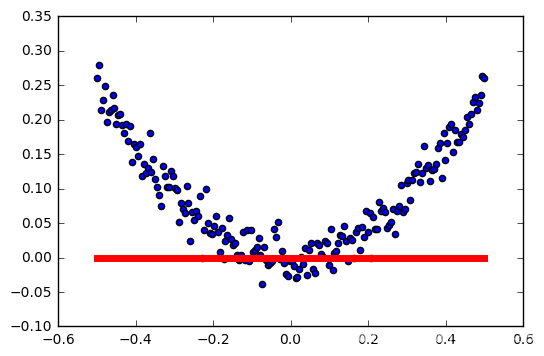
tasa de aprendizaje: 0.6
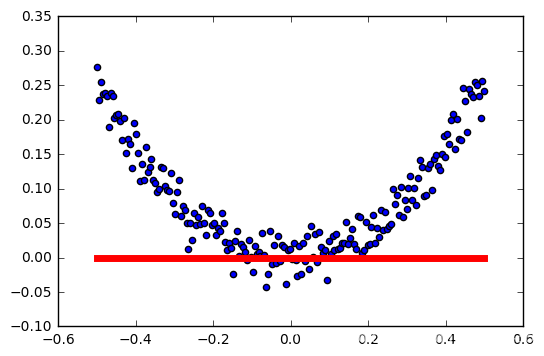
resumen relu
Cuanto mayor sea la tasa de aprendizaje, la activación más fácil falló.
Esto no es muy rigurosa, las muestras son generados al azar, cada generación es diferente, no controlan las variables ... pero probablemente puede ver el impacto de la función de activación relu tasa de aprendizaje.
Se utiliza como la función de activación tanh
#使用numpy来生成200个随机点,等差数列
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise = np.random.normal(0,0.02,x_data.shape)
y_data = np.square(x_data) + noise
#定义两个palceholder
x = tf.placeholder(tf.float32,[None,1])
y = tf.placeholder(tf.float32,[None,1])
#定义神经网络中间层
Weights_L1 = tf.Variable(tf.random_normal([1,10]))
biases_L1 = tf.Variable(tf.zeros([1,10]))
Wx_plus_b_L1 = tf.matmul(x,Weights_L1) + biases_L1
#激活函数
L1 = tf.nn.tanh(Wx_plus_b_L1)
#定义输出层
Weights_L2 = tf.Variable(tf.random_normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2 = tf.matmul(L1,Weights_L2) + biases_L2
#激活函数
prediction = tf.nn.tanh(Wx_plus_b_L2)
#二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
#用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.04).minimize(loss)
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
for i in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获得预测值
prediction_value = sess.run(prediction,feed_dict = {x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()
salida
tasa de aprendizaje: 0,01
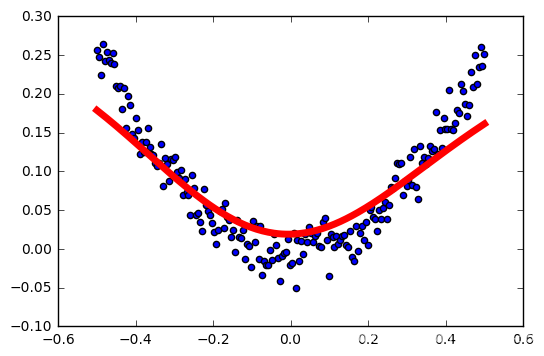
tasa de aprendizaje: 0,04
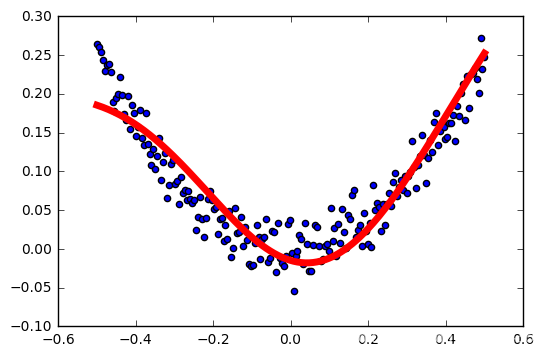
tasa de aprendizaje: 0,1
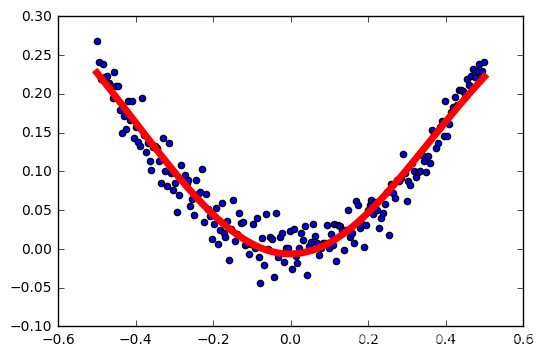
tasa de aprendizaje: 0,2
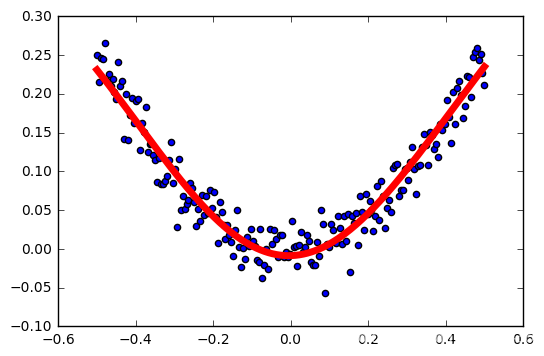
tasa de aprendizaje: 0,3
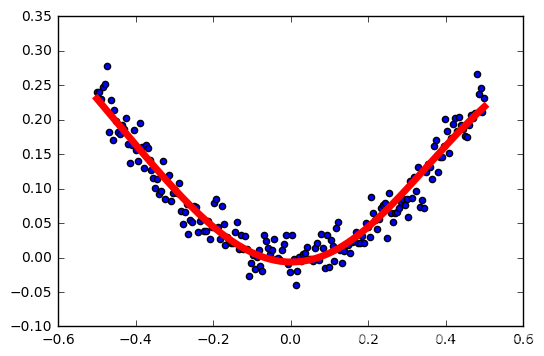
tasa de aprendizaje: 0,4
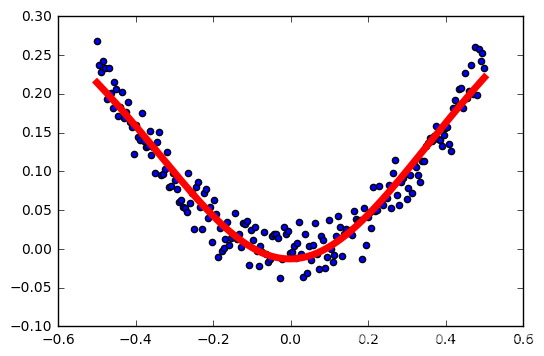
tasa de aprendizaje: 0,5
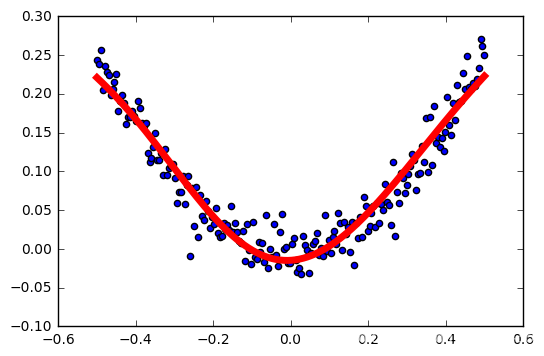
tasa de aprendizaje: 0.6

resumen
tasa de aprendizaje es demasiado baja, el resultado no es exacta
Uso como función de activación sigmoide
#使用numpy来生成200个随机点,等差数列
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise = np.random.normal(0,0.02,x_data.shape)
y_data = np.square(x_data) + noise
#定义两个palceholder
x = tf.placeholder(tf.float32,[None,1])
y = tf.placeholder(tf.float32,[None,1])
#定义神经网络中间层
Weights_L1 = tf.Variable(tf.random_normal([1,10]))
biases_L1 = tf.Variable(tf.zeros([1,10]))
Wx_plus_b_L1 = tf.matmul(x,Weights_L1) + biases_L1
#激活函数
L1 = tf.nn.sigmoid(Wx_plus_b_L1)
#定义输出层
Weights_L2 = tf.Variable(tf.random_normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2 = tf.matmul(L1,Weights_L2) + biases_L2
#激活函数
prediction = tf.nn.sigmoid(Wx_plus_b_L2)
#二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
#用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.04).minimize(loss)
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
for i in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获得预测值
prediction_value = sess.run(prediction,feed_dict = {x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()
salida
tasa de aprendizaje: 0,04
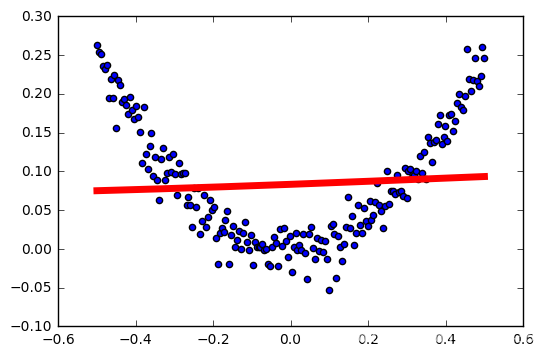
tasa de aprendizaje: 0,1

tasa de aprendizaje: 0,2
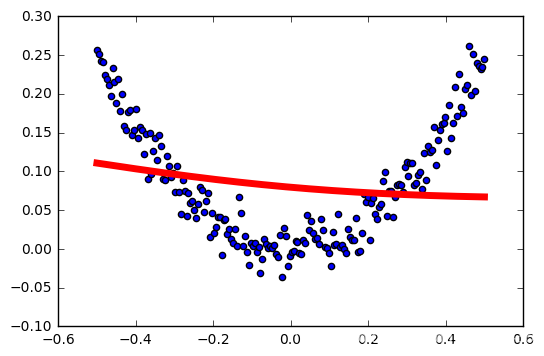
tasa de aprendizaje: 0,3
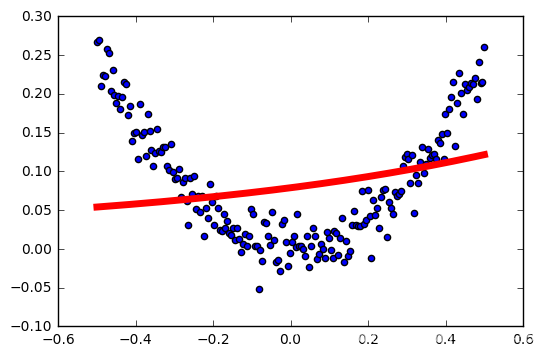
tasa de aprendizaje: 0,4

tasa de aprendizaje: 0,5
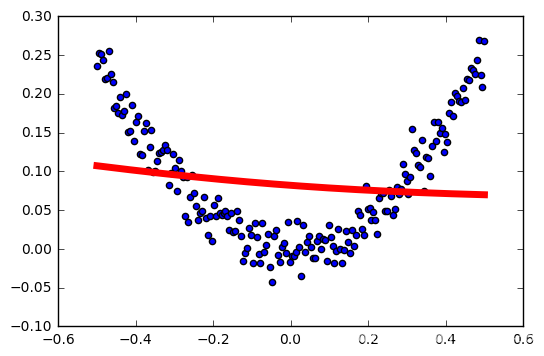
tasa de aprendizaje: 0.6
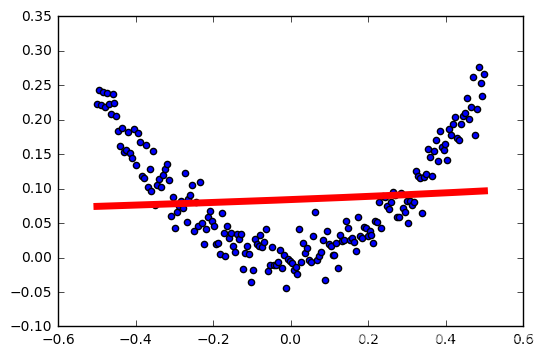
resumen
Esto es claramente la función de activación inapropiada como nuestro modelo.
