1. VGG
VGG es la profundidad límite que pueden alcanzar las pilas de redes neuronales tradicionales .
VGG se divide en VGG16 y VGG19, ambos con las siguientes características:
①Según la capa de agrupación 2x2, la red se puede dividir en varios segmentos
② Cada segmento se compone de varias operaciones de convolución iguales, y el número de mapas de características en el segmento es fijo;
③El mapa de funciones aumenta en múltiplos de 2 (64-128-256-512), y después del cuarto párrafo, es 512
Debido a esta característica, el número de segmentos se puede ajustar de manera flexible según la tarea Cada vez que se agrega un segmento, el tamaño del mapa de características se reduce a la mitad.
①Estructura de red

Los dos modelos están igualmente divididos en 5 bloques, y cada bloque está conectado con las siguientes muestras; cada bloque usa un núcleo de convolución de 3x3; a medida que el borde del bloque se vuelve más profundo, la cantidad de canales se duplicará.
Todos tienen las siguientes propiedades:
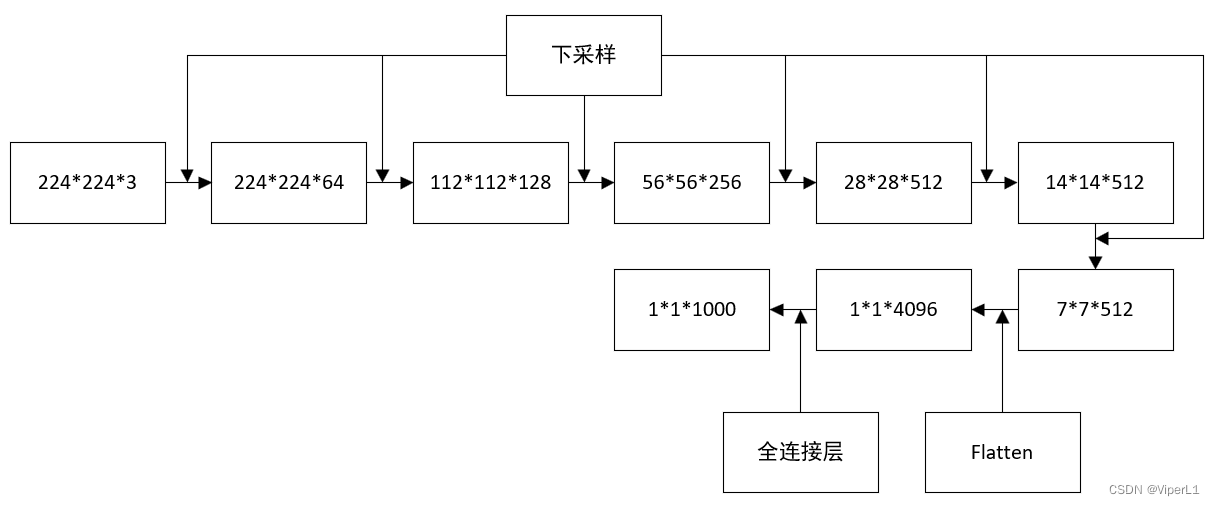
①El tamaño de entrada es 224x224;
② Hay 5 capas de Max Pooling, que eventualmente generarán un mapa de características de 7x7;
③La capa de características pasará por dos conexiones completas 4096 y finalmente conectará un clasificador softmax de clase 1000;
④El modelo se puede expresar como mx(nx(conv33)+max_pooling)
Generalmente, el kernel de convolución de VGG se reemplaza con un kernel de convolución de tamaño pequeño de 3x3 o 1x1 para mejorar el rendimiento. (En el caso del mismo campo receptivo, el núcleo de convolución de tamaño pequeño tiene una profundidad más profunda; la fórmula del campo receptivo : tamaño rf = (fuera-1) x zancada + tamaño k)
El número de núcleos de convolución de la red VGG:
VGG-16: 2,2,3,3,3
VGG-19: 2,2,4,4,4
A medida que aumenta el número de capas de red, la longitud y el ancho de la dimensión disminuyen y aumentan los canales del nivel semántico .
②VGG16
El tamaño del mapa de características cambia de la siguiente manera
Consumo de recursos: la mayor parte de la huella de memoria es aportada por las dos primeras capas convolucionales
La mayoría de los parámetros son aportados por la primera capa completamente conectada.
La precisión de VGG es promedio y la cantidad de parámetros es grande
En comparación con AlexNet, VGG utiliza un núcleo de convolución de 3x3 (tamaño de 1 paso), que pierde menos información y no utiliza la normalización.
Núcleo de convolución ③3x3
Un kernel de convolución de 3x3 con 2 capas es equivalente a un kernel de convolución de 5x5 ; un kernel de convolución de 3x3 con 3 capas es equivalente a un kernel de convolución de 7x7
Aunque el tamaño de su campo receptivo es el mismo, una red más profunda puede traer: mayor no linealidad, mejor capacidad de representación, menos parámetros .
2. ShuffleNet V1
①Grupo Pointwise Convolución (grupo 1x1 convolución)
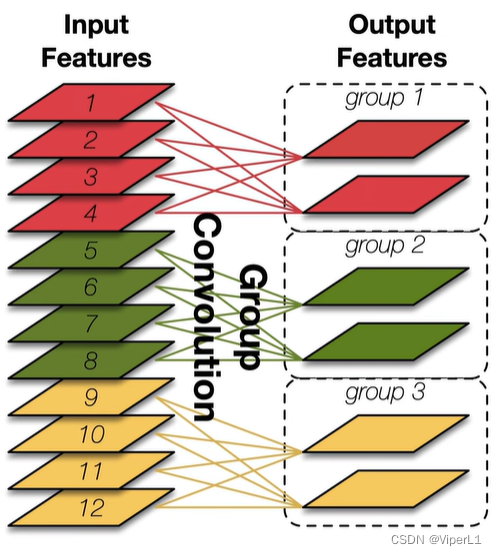
Cada kernel de convolución solo procesa una parte de los canales (tradicionalmente, un kernel de convolución procesa todos los canales), lo que puede reducir efectivamente la cantidad de parámetros.
②Channel Shuffle (reorganización de canales)
El objetivo es introducir la fusión de información entre grupos.
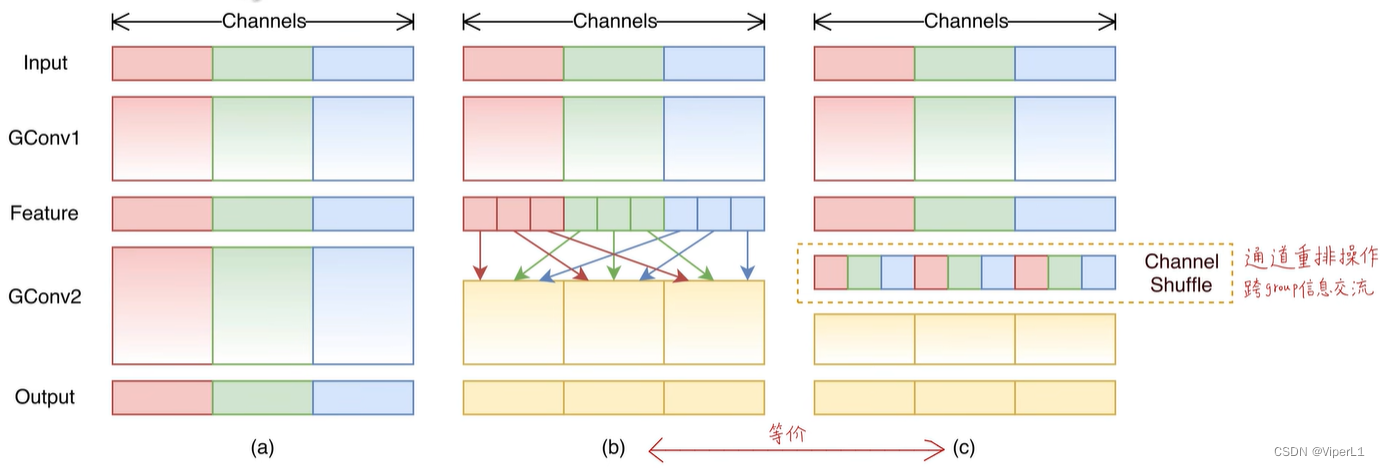
Operación aleatoria de canales:
①Reorganizar el canal en una matriz de n columnas
② Transponer la matriz
③ Vuelve a aplanarlo (Aplanar)

La reproducción aleatoria de canales se puede implementar directamente usando la API de pytorch, y se puede diferenciar y guiar (se puede realizar un entrenamiento de extremo a extremo); al mismo tiempo, no se introduce ningún cálculo adicional
③Estructura de red
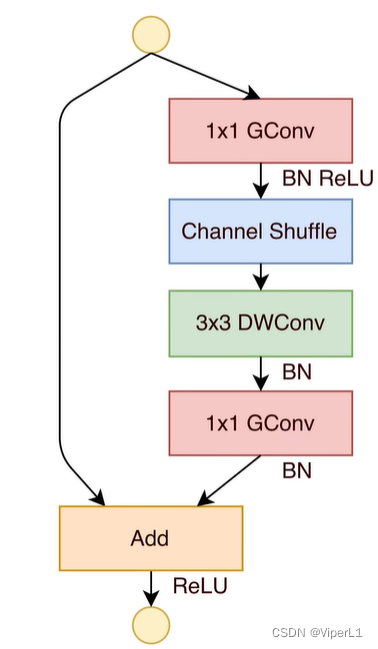
Shuffle Block mejorado de Bottleneck Block de ResNet:
1. Cambie la reducción de dimensionalidad 1x1 y la mejora de dimensionalidad a convolución de grupo
2. Introducir el canal Shuffle después de la reducción de dimensionalidad ;
3. Reemplace la convolución estándar 3x3 con la convolución Depthwise .
La siguiente figura muestra el bloque Shuffle estándar (el izquierdo es el bloque estándar y el derecho es el bloque de reducción de resolución <Stride=2>)
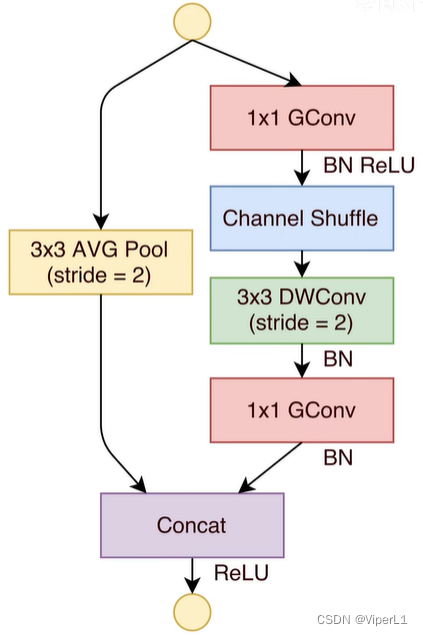
El número de grupos de convolución agrupados es diferente, y el número de núcleos de convolución disponibles es diferente (el número de grupos es proporcional )
Operación Concat : apile los mapas de características calculados en lugar de agregar elementos
Estructura de la red: En términos generales, g=3 es el ShuffleNet V1 de uso común
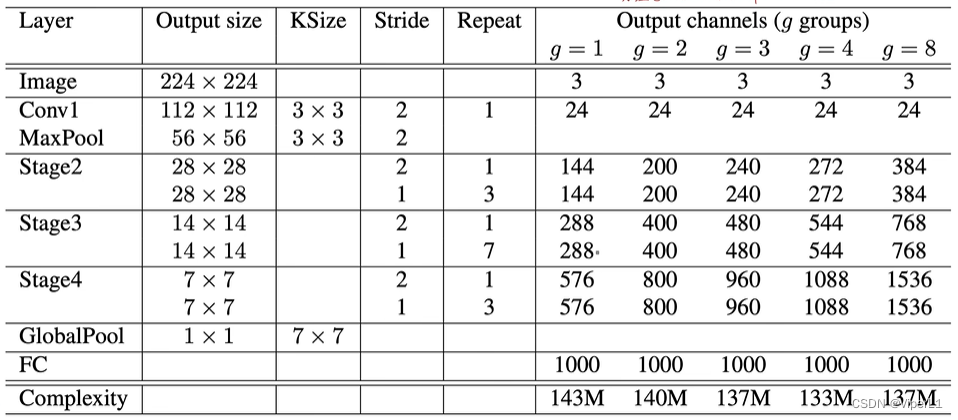
El hiperparámetro g se puede utilizar para controlar el número de grupos de agrupación; cuanto mayor sea el número de grupos de agrupación, mayor será la tasa de precisión
3. ShuffleNet V2
① Criterios para red ligera
1. Cuando los canales de entrada y salida son los mismos, la huella de memoria (MAC) es la más pequeña (para convolución 1x1)
2. La convolución de paquetes con demasiados paquetes aumentará la MAC
3. Las operaciones de fragmentación no son compatibles con la aceleración paralela
4. No se puede ignorar el consumo de memoria y tiempo causado por las operaciones elemento por elemento.
②Módulo ShuffleNet V2
La siguiente figura muestra el módulo básico (imagen de la izquierda); el módulo de reducción de resolución (imagen de la derecha)

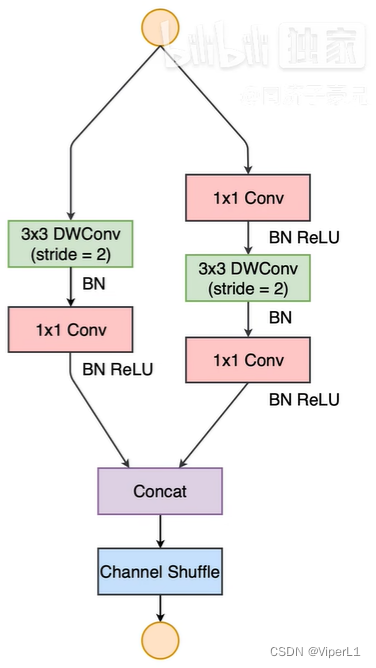
Las mejoras son las siguientes:
① Operación de división de canal : divida el canal de entrada en dos y distribúyalos a la conexión residual y la red convolucional respectivamente
② Operación Concat : apila los mapas de características calculados en lugar de agregar elementos
③Convolución 1x1 sin convolución de grupo
Channel Shuffle y Channel Split son una operación en el código