Inteligencia artificial y aprendizaje automático
La inteligencia artificial es una rama de la informática que intenta comprender la esencia de la inteligencia y producir una nueva máquina inteligente que pueda responder de manera similar a la inteligencia humana. La investigación en este campo incluye robótica, reconocimiento de lenguaje, reconocimiento de imágenes, procesamiento de lenguaje natural y sistemas expertos , etc Desde el nacimiento de la inteligencia artificial, la teoría y la tecnología se han vuelto cada vez más maduras, y los campos de aplicación también han seguido expandiéndose. Se puede imaginar que los productos tecnológicos traídos por la inteligencia artificial en el futuro serán el "contenedor" de la sabiduría humana. . La inteligencia artificial puede simular el proceso de información de la conciencia y el pensamiento humanos. La inteligencia artificial no es inteligencia humana, pero puede pensar como seres humanos y puede superar a la inteligencia humana.
La historia del desarrollo de la inteligencia artificial:

Razonamiento lógico: en los diez años posteriores a la conferencia de Dartmouth en 1956, la inteligencia artificial marcó el comienzo de su primer pico. La mayoría de los primeros investigadores resumieron algunas reglas basadas en la experiencia humana, en la lógica o en los hechos, y luego las programaron para que la computadora complete una tarea. .
Ingeniería del conocimiento: en la década de 1970, los investigadores se dieron cuenta de la importancia del conocimiento para los sistemas de inteligencia artificial. Especialmente para algunas tareas complejas, se necesitan expertos para construir la base de conocimientos. El sistema experto puede entenderse simplemente como "base de conocimiento + máquina de razonamiento", que es un tipo de sistema de programa inteligente de computadora con conocimiento y experiencia especializados.
Aprendizaje automático: para muchos comportamientos inteligentes de los seres humanos, como la comprensión del lenguaje, la comprensión de imágenes, etc., nos resulta difícil conocer los principios, ni podemos describir el "conocimiento" detrás de estos comportamientos inteligentes. También da lugar a un sistema inteligente que es difícil dar cuenta de estos comportamientos a través del conocimiento y el razonamiento. Para resolver este tipo de problemas, los investigadores han recurrido a dejar que las computadoras aprendan de los datos por sí mismas.
Proceso progresivo de nivel de tecnología de inteligencia artificial.

Los orígenes del aprendizaje automático : el modelo matemático de perceptrón de la década de 1950.
- Desarrollo: desde mediados de la década de 1990, el aprendizaje automático se ha desarrollado rápidamente y ha reemplazado gradualmente a los sistemas expertos tradicionales como la tecnología central principal de la inteligencia artificial , lo que hace que la inteligencia artificial entre gradualmente en la era del aprendizaje automático.
La diferencia entre el aprendizaje automático y el aprendizaje profundo: el aprendizaje automático es un método para lograr inteligencia artificial y el aprendizaje profundo es una tecnología para lograr el aprendizaje automático.
Sustantivos en el campo de la inteligencia artificial
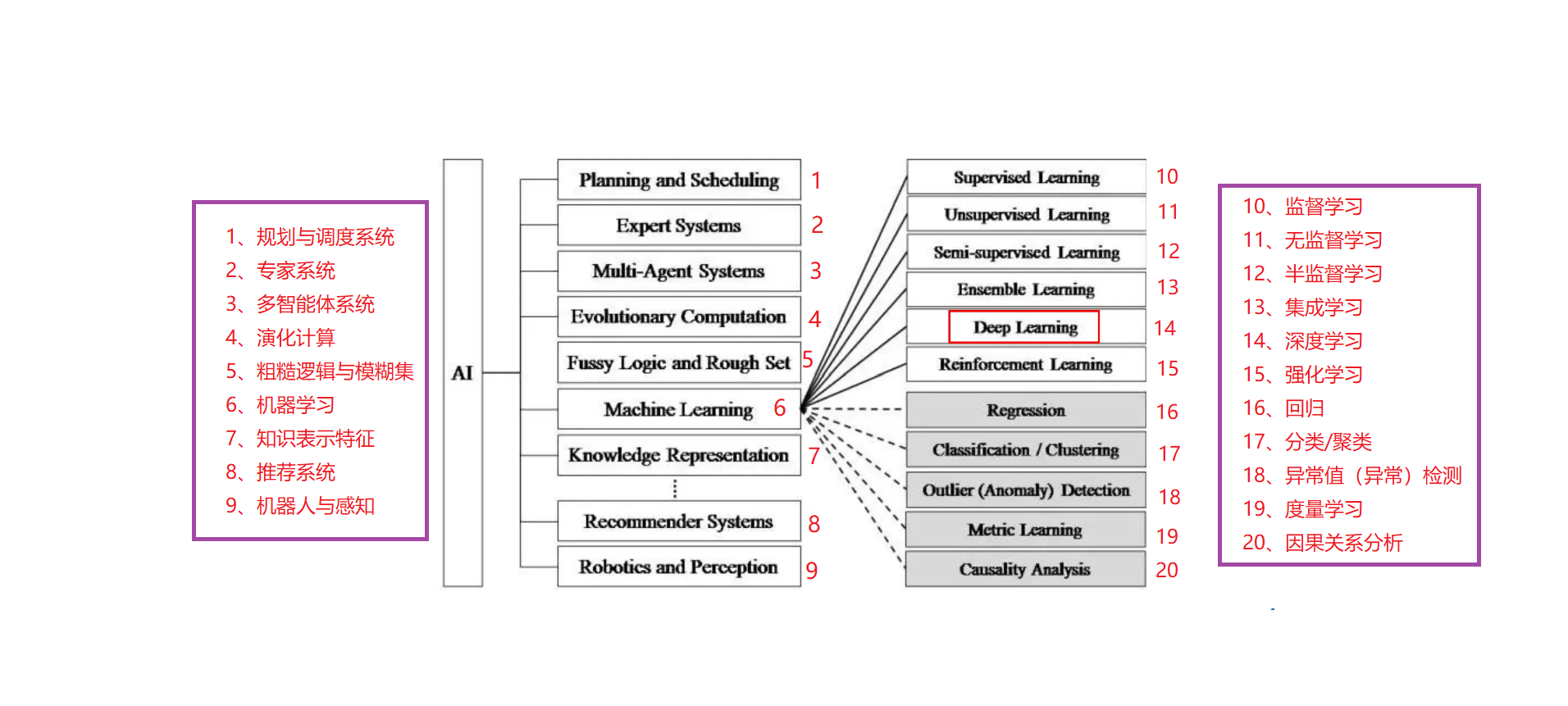
Historia del desarrollo de la inteligencia artificial
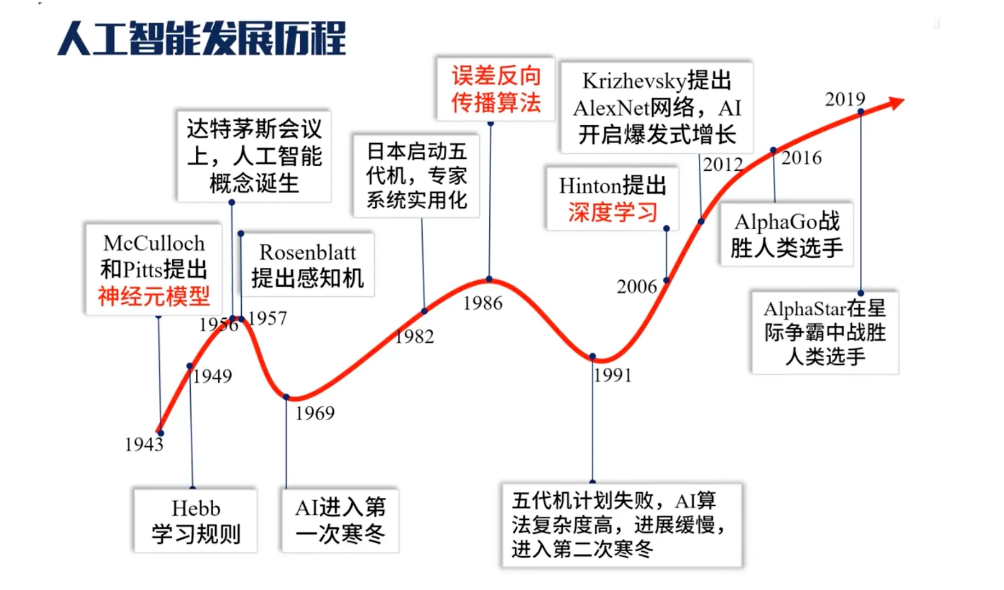
Definición de aprendizaje automático
Definición de aprendizaje automático 1
El padre del aprendizaje automático: Arthur Samuel acuñó el término "aprendizaje automático" y lo definió como: el campo de estudio en el que a una máquina se le puede dar una cierta habilidad sin programación determinista.
"El aprendizaje automático es el campo que le da a las computadoras la capacidad de aprender que (la capacidad de aprender) no está * obviamente programada **".
—— Arthur Samuel
Entonces, ¿qué es la programación explícita? ¿En qué se diferencia de la programación no obvia?
¿Qué es la programación explícita?
La computadora ejecuta el programa a través del código lógico predeterminado, ingresa a la capa lógica del código para el contenido de la capa de entrada y devuelve el resultado obtenido a través de la secuencia lógica predeterminada a la capa de salida.
Por ejemplo:
El robot sale del aula para hacernos una taza de café:
Primero, enviamos instrucciones al robot para que gire a la izquierda y dé unos pasos. El robot ejecuta cada paso de acuerdo con el programa preestablecido.
Hagamos que la computadora reconozca crisantemos y rosas:
Le diremos a la computadora a través del código de antemano: el amarillo representa crisantemos y el rojo representa rosas. Entonces, si la computadora reconoce el amarillo, significa crisantemos, y si reconoce el rojo, significa rosas.
De esto podemos concluir que la programación explícita requiere que ayudemos al programa a comprender el entorno de ejecución de antemano, y dejar que se ejecute paso a paso de acuerdo con la lógica original establecida.
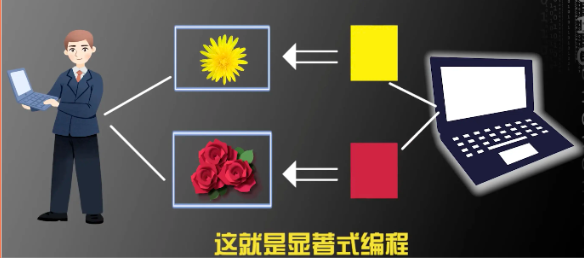
¿Qué es la programación no obvia?
La computadora aprende y resume automáticamente a través de datos y experiencia, y completa las tareas asignadas por humanos.
Durante la ejecución, el programa a menudo tiene una "función de ingresos" y una "función de activación" para analizar el peso de un evento actual y tomar una decisión sobre la próxima ejecución del comportamiento.
Tome el ejemplo anterior como ejemplo:
Cuando un robot nos hace café:
Los seres humanos estipulan que los robots pueden adoptar una serie de comportamientos, y los beneficios que aportan los robots al realizar estos comportamientos en un entorno específico se denominan "funciones de beneficio". Por ejemplo, si el robot se cae solo, la función de ganancia es negativa; si el robot se cae solo, la función de ganancia es negativa; si el robot solo toma café, la función de ganancia es positiva.
Cuando identificamos crisantemos y rosas por computadora:
Deje que la computadora resuma la diferencia entre crisantemos y rosas: si los pétalos son largos y amarillos, es probable que sea un crisantemo; si los pétalos son redondos y rojos, es probable que sea una rosa. Es decir, la computadora puede Resume el crisantemo a través de una gran cantidad de imágenes.Amarillo, las rosas son rojas.
en el proceso de formación de esta regla. No restringimos las reglas que la computadora debe concluir de antemano, pero dejamos que la computadora escoja algunas reglas que puedan distinguir mejor los crisantemos de las rosas .
Por lo tanto, al reconocer una imagen, cuando el programa ve una amarilla, la función de ganancia de la computadora basada en el crisantemo es positiva y se observa que los pétalos son largos, la función de ganancia también es positiva y el valor de ganancia en este momento alcanza la función de activación Requisitos de peso del crisantemo, se puede deducir que el pétalo es un crisantemo.
Entonces, en la programación no saliente, después de especificar el comportamiento y la función de ingresos, permita que la computadora encuentre el comportamiento que maximiza la función de ingresos. La computadora adopta un comportamiento aleatorio . Siempre que nuestro programa sea lo suficientemente bueno, la computadora puede encontrar un patrón de comportamiento que maximice la función de ingresos y usar la "función de activación" como la condición de ejecución de un determinado comportamiento.
Comparación de dos métodos de programación
Se puede ver que la programación no obvia permite que las computadoras aprendan automáticamente a través de los datos y la experiencia para completar las tareas que asignamos.
Es esta programación no obvia en la que se centra el aprendizaje automático.
Definición de aprendizaje automático 2
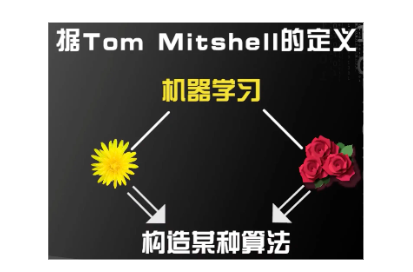
Definición de Tom Mitshell en su libro "Machine Learning" en 1998:
"Se dice que un programa de computadora aprende de la experiencia E con respecto a alguna tarea T y alguna medida de desempeño P, si su desempeño en T, medido por P, mejora con la experiencia E".
"Un programa de computadora se llama aprendible, lo que significa que puede aprender de la experiencia E para una tarea T y un cierto índice de rendimiento P. La característica de este tipo de aprendizaje es que su rendimiento en T se mide por P El rendimiento aumentará con el aumento de la experiencia E."
——Tom Mitshell 《Aprendizaje automático》
¿Cómo expresar este concepto? Utilizamos el programa informático de reconocimiento de rosas y crisantemos mencionado anteriormente para delinear la tarea T, la experiencia E y el índice de rendimiento P mencionado por Tom Mitshell. en:
-
Tarea T (Tarea): Escribir un programa de computadora para identificar, crisantemos y rosas;
-
Experiencia E (Experiencia): enumerar imágenes de crisantemos y rosas (conjunto de datos);
-
Índice de rendimiento P (medida de rendimiento): el resultado de verificación del conjunto de pruebas de la computadora y la probabilidad de identificar el correcto dentro del tiempo de operación especificado . Este es un algoritmo de aprendizaje automático diseñado para la tarea T y la experiencia E. A través de este algoritmo, se puede obtener el conocimiento de la experiencia E para lanzar el modelo de mejor ajuste en línea con la tarea T y el proceso de mejora del índice de rendimiento P de acuerdo con la experiencia E. (un típico problema de optimización) ). El rendimiento se refleja en la capacidad del modelo existente para procesar nuevos datos (medida de rendimiento de precisión)
Los algoritmos de aprendizaje automático diseñados para diferentes tareas T serán diferentes.
Conjunto de prueba: después de que la computadora haya entrenado el modelo, designará una determinada muestra como el conjunto de prueba y la usará como reconocimiento de imagen en el conjunto de datos en función del modelo completo, y verificará la probabilidad de que el modelo de imagen se pruebe con éxito. en el conjunto de prueba, que es la verificación del conjunto de prueba Como resultado, [saque el papel de prueba y pruébese usted mismo, vea cuántas preguntas puede responder]
Por lo tanto, a partir de la definición de Tom Mitshell, se puede concluir que el aprendizaje automático es un modelo de datos que cumple con el índice de desempeño P del mejor ajuste al construir un diseño para la tarea T y la experiencia E.
Al mismo tiempo, en el algoritmo de aprendizaje automático diseñado para la tarea E y la experiencia E, la característica de este algoritmo es que a medida que aumenta el número de experiencias E, el índice de rendimiento P será cada vez más alto (al igual que el aprendizaje solo mejorará). y mejor). Inteligente, puede haber fluctuaciones de datos en este proceso, porque puede olvidarlo después de aprenderlo, pero continuará mejorando solo después de un entrenamiento repetido).
La definición propuesta por Tom Mitshell también se basa en la programación no obvia, y la programación explícita determina la entrada y la salida del programa desde el principio. La tasa de reconocimiento no cambia a medida que aumenta el número de muestras.
Entonces, intentemos introducir el concepto de diseño de la tarea T, la experiencia E y el índice de rendimiento P en el proceso de elaboración del café por parte del robot:
Tarea T: Diseñar un programa para que el robot haga café
Experiencia E: Las acciones de los intentos repetidos del robot y los resultados de estas acciones tienen éxito dentro del tiempo especificado
Medida de desempeño P: número de veces que se prepara el café
resumen
A través de la introducción de las dos definiciones anteriores, entendemos que las matemáticas juegan un papel importante en el aprendizaje automático moderno.
El aprendizaje automático es una rama importante de la inteligencia artificial y la clave para realizar la inteligencia.
Definición clásica: Es una forma de mejorar el rendimiento del propio sistema informático (modelo) a través de la experiencia. Los métodos modernos de aprendizaje automático están diseñados principalmente con referencia a la Definición 2.
Los marcos de aprendizaje automático existentes están diseñados principalmente en función de los siguientes puntos:
- **Experiencia:**En un sistema informático, son datos (conjunto). Correspondiente a datos históricos, como datos de Internet, datos de experimentos científicos, etc.
- **Sistema:** corresponde al modelo de datos, como árbol de decisión, máquina de vectores de soporte, etc.
- **Rendimiento:** es la capacidad del modelo para procesar nuevos datos, como el rendimiento de clasificación y predicción.
- **Objetivo principal: **Análisis inteligente y modelado de datos. Predecir lo desconocido, entender el sistema
Red neuronal artificial y su desarrollo
Antes de comenzar a introducir oficialmente las redes neuronales, veamos algunos problemas matemáticos simples:
- ¿3 es positivo o negativo?
- ¿A qué cuadrante del eje pertenece (1,1)?
Después de movilizar por completo varios sentidos y acumular conocimientos del 90% de la educación obligatoria, nos parece demasiado fácil responder a estas preguntas, tan fácil que sentimos que estas preguntas en sí mismas no tienen mucho sentido.
Pero una vez que quieras entender el mecanismo por el cual el cerebro humano resuelve estos problemas: ¿cómo funciona el nervio visual en estos problemas? ¿Cómo fluye la información entre las neuronas?
Cómo hacer que la computadora también tenga la capacidad de responder a estas preguntas, las cosas no se vuelven tan simples.
La red neuronal es un modelo biónico, que imita la red neuronal humana para procesar y analizar eventos y obtener una solución óptima al problema.
Entonces, primero comprendamos la estructura y el principio de funcionamiento de la neurona biológica.
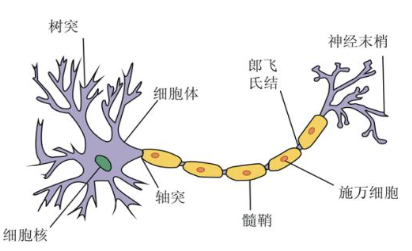
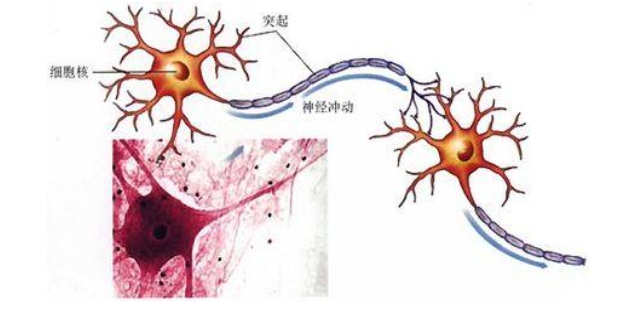
Una neurona es una célula que recibe y emite impulsos y tiene dendritas y axones fuera del núcleo del cuerpo celular; las
dendritas reciben impulsos de otras neuronas, y el axón transmite los impulsos de salida de la neurona a otras neuronas;La salida transmitida por una fuente neuronal a diferentes neuronas es la misma, y la interacción combinada de innumerables neuronas biológicas en el intercambio de información en la parte prominente forma una red neuronal biológica, que permite a las personas tener la capacidad de procesar información compleja.

Concepto de red neuronal artificial
Luego, la red neuronal artificial también intenta imitar la forma de la fuente neuronal correspondiente al principio de funcionamiento de la red neuronal biológica. Aritificial Neural Network (ANN) es un modelo matemático teórico de la red neuronal del cerebro humano , y es un sistema de procesamiento de información basado en imitar la estructura y función de la red neuronal del cerebro . En realidad es una red compleja compuesta por un gran número de componentes simples conectados entre sí , con un alto grado de no linealidad , un sistema capaz de realizar operaciones lógicas complejas y relaciones no lineales.
Las redes neuronales artificiales también se conocen como "redes neuronales" o "sistemas nerviosos artificiales" . Es común abreviar redes neuronales artificiales y referirse a ellas como "ANN" o simplemente "NN".
Para que un sistema se considere una red neuronal, debe contener una estructura gráfica etiquetada en la que cada nodo del gráfico realice un cálculo simple. De la teoría de grafos, sabemos que un gráfico consta de un conjunto de nodos (es decir, vértices) y un conjunto de conexiones (es decir, bordes) que conectan pares de nodos.
En la siguiente figura podemos ver un ejemplo de un gráfico NN de este tipo.
Una arquitectura de red neuronal simple. La entrada se presenta a la red. Cada conexión transporta una señal a través de dos capas ocultas en la red. La última función calcula las etiquetas de clase de salida.
Cada nodo realiza un cálculo simple. Luego, cada conexión lleva una señal (es decir, la salida de un cálculo) de un nodo a otro, marcada con un peso que indica cuánto se amplifica o atenúa la señal. Algunas conexiones tienen pesos positivos que amplifican la señal, lo que indica que la señal es importante para la clasificación. Otros tienen *pesos negativos* que reducen la fuerza de la señal de modo que la salida del nodo especificado es menos importante en la clasificación final. A este sistema lo llamamos red neuronal artificial.
Principios de Construcción de Redes Neuronales Artificiales
- Está compuesto por un cierto número de conexiones jerárquicas de unidades básicas;
- Las señales de entrada y salida y el contenido de procesamiento integral de cada unidad son relativamente simples;
- El almacenamiento de aprendizaje y conocimiento de la red se refleja en la fuerza de conexión entre cada unidad.

Campo de aplicación e historia de desarrollo de la red neuronal artificial.
Reconocimiento de voz: reconocimiento de voz inteligente de Siri;
Conducción autónoma: la dirección de investigación principal de la inteligencia artificial en la actualidad;
optimización de motores de búsqueda, algoritmo de recomendación, traducción de idiomas: Baidu, Google, algoritmo de recomendación;
Algoritmo de juego hombre-máquina: Algoritmo AlphaGo Go;
Hogar inteligente, colocación: reconocimiento facial, equipo de monitoreo inteligente.
La historia de la inteligencia artificial desde la perspectiva del aprendizaje automático
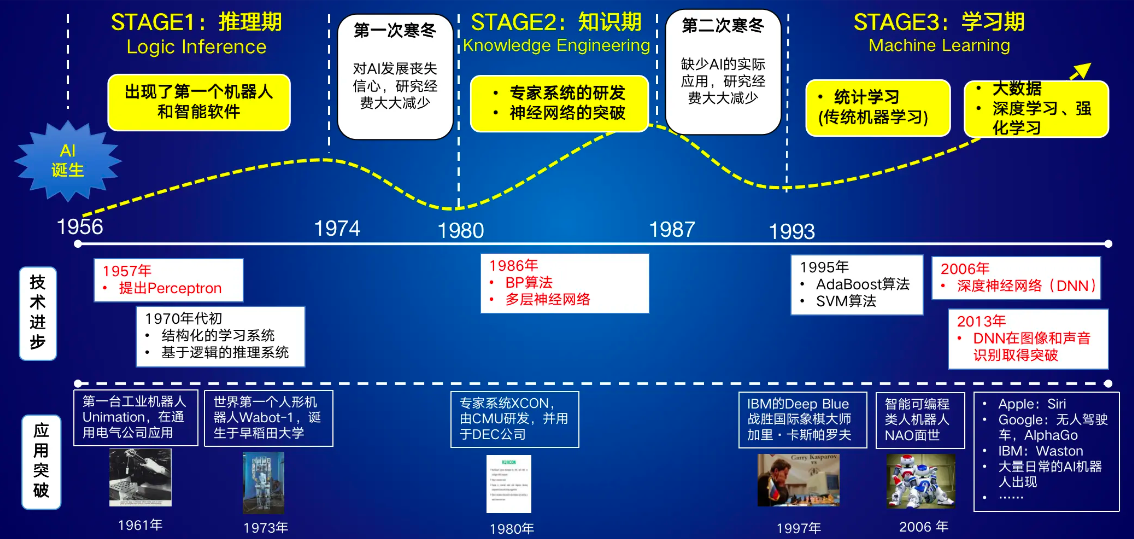
Tres escuelas de pensamiento en aprendizaje automático
-
simbolistas
-
La cognición es computación, prediciendo resultados a través de la deducción y la deducción inversa de símbolos.
-
Algoritmo representativo: algoritmo de deducción inversa (Deducción inversa)
-
Aplicación representativa: gráfico de conocimiento
-
-
conexionista
-
simular el cerebro
-
Algoritmos representativos: Algoritmo de retropropagación (Backpropagation), aprendizaje profundo (Deep learning)
-
Aplicaciones representativas: visión artificial, reconocimiento de voz

-
-
Conductismo (Analogizador)
-
similitud entre el conocimiento antiguo y el nuevo
-
Algoritmos representativos: máquinas kernel, Nearest Neightor
-
Aplicación representativa: sistema de recomendación de Netflix

-
También hay dos escuelas de investigación:
-
Escuela de biónica de inteligencia artificial:
- La inteligencia artificial simula la comprensión del mundo por parte del cerebro humano. Estudiar el mecanismo cognitivo del cerebro y resumir la forma en que el cerebro procesa la información es un requisito previo para la realización de la inteligencia artificial.
-
La Escuela Matemática de Inteligencia Artificial:
- En la actualidad y en el futuro previsible, no podemos comprender completamente el mecanismo cognitivo del cerebro humano. Las computadoras y los cerebros humanos tienen propiedades físicas y arquitecturas completamente diferentes.
Una visión general del desarrollo de las redes neuronales.
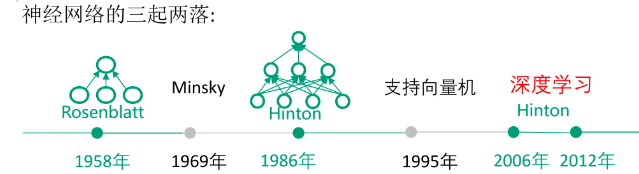

El aprendizaje profundo tiene una larga historia de desarrollo, pero solo maduró gradualmente después de 2010.
La troika del aprendizaje profundo
Los mejores expertos en aprendizaje profundo moderno:
- Wu Enda: En 2011, Wu Enda estableció el proyecto "Google Brain" en Google, que utiliza el marco informático distribuido de Google para calcular y aprender redes neuronales artificiales a gran escala. El importante resultado de la investigación de este proyecto es que la red neuronal con mil millones de parámetros aprendidos por un algoritmo de aprendizaje profundo en 16 000 núcleos de CPU puede aprender a reconocerla simplemente viendo videos de YouTube sin etiquetar sin ningún conocimiento previo.Concepto de alto nivel.
- En 2008, Andrew Ng fue seleccionado como uno de "MIT Technology Review TR35", que es uno de los 35 mejores innovadores del mundo menores de 35 años seleccionados por la revista "MIT Technology Entrepreneurship".
- Destinatario del "Premio Computadoras y Mentes".
- En 2013, Andrew Ng fue seleccionado como una de las 100 personas más influyentes del mundo por la revista "Time", convirtiéndose en uno de los 16 representantes de la industria tecnológica. ,
- Fei-Fei Li: Inventor de ImageNet e ImageNet Challenge, que contribuye a los últimos desarrollos en aprendizaje profundo e IA. Además de sus contribuciones técnicas, es una líder que aboga por la diversidad en STEM (Ciencia, Tecnología, Ingeniería y Educación Matemática) e IA (Inteligencia Artificial).
- lan Goodfellow: Famoso por proponer Generative Adversarial Networks (GAN), es conocido como el "padre de las GAN" e incluso ha sido elegido como uno de los principales expertos en el campo de la inteligencia artificial.


El aprendizaje profundo domina el tercer auge de la inteligencia artificial, gracias a ABC tres puntos:
- Algoritmo (algoritmo): el algoritmo de entrenamiento de la red neuronal profunda se está volviendo cada vez más maduro, y la precisión del reconocimiento es cada vez mayor;
- B ig data (big data): Hay suficiente big data para el entrenamiento de redes neuronales;
- Computación (poder de cómputo): el poder de cómputo del chip del procesador de aprendizaje profundo es relativamente fuerte.
La historia del desarrollo de redes neuronales
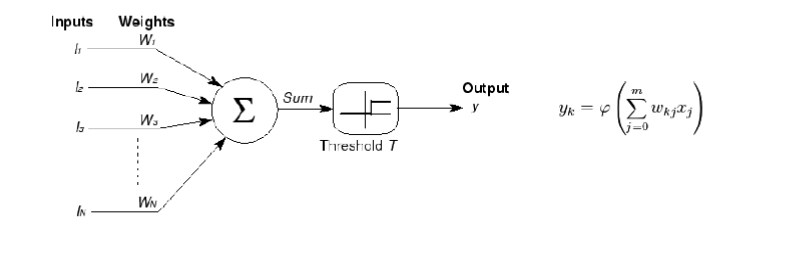
1943: Modelo propuesto modelo de neurona MP
Modelo de neuronas de McCulloch-Pitts
Como origen de la red neuronal artificial, el modelo MP ha creado una nueva era de red neuronal artificial y sentó las bases del modelo de red neuronal.
-
El psicólogo estadounidense McCulloch y el matemático Pitts propusieron un modelo matemático que simula las redes de neuronas humanas para el procesamiento de la información

-
Las características de las neuronas: entrada múltiple y salida única; la sinapsis (el lugar donde se transmiten los impulsos nerviosos) tiene propiedades tanto excitatorias como inhibitorias; puede ser ponderada en el tiempo y en el espacio; puede generar pulsos; se transmiten los pulsos; no lineal
-
Se usa un método de ponderación lineal simple para simular este proceso, donde l es la entrada, W es el peso y la suma ponderada se usa como salida después de pasar por una función de umbral.
1949: Hipótesis de Hebb
En The Organization of Behavior, publicado en 1949, Hebb presentó su teoría neuropsicológica.

Hipótesis de Hebb : cuando el axón de la célula A está lo suficientemente cerca como para estimular la célula B y estimular B repetida o continuamente, entonces se producirá algún tipo de proceso de crecimiento o reacción metabólica en estas dos células o en una célula. Aumentará el efecto estimulante de A en celda B;
La regla de Hebb es consistente con el mecanismo de "reflejo condicionado", que sentó las bases para el futuro algoritmo de aprendizaje de redes neuronales y tiene una gran importancia histórica.
1958: Algoritmo de perceptrón de Rosenblatt
En 1958, un psicólogo Rosenblatt inventó el perceptrón, por lo que las generaciones posteriores lo llamaron ** Perceptrón de Rosenblatt **.
Por primera vez, Rosenblatt usó el modelo MP para clasificar los datos multidimensionales de entrada y usó el método de descenso de gradiente para aprender y actualizar automáticamente los pesos de las muestras de entrenamiento;
En 1962, se demostró que el método converge eventualmente, y los efectos teóricos y prácticos causaron la primera ola de redes neuronales.

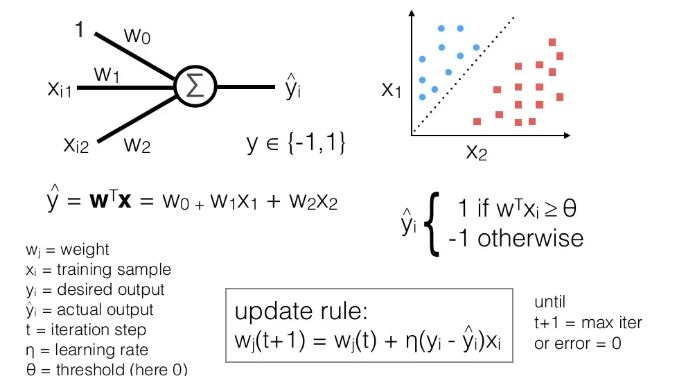
La propuesta del perceptrón ha despertado el interés de un gran número de científicos por el estudio de las redes neuronales artificiales, lo que supone un hito en el desarrollo de las redes neuronales.
1969: Cuestionamiento del problema XOR
En 1969, los matemáticos estadounidenses y pioneros de la inteligencia artificial Minsky y Papert demostraron en sus trabajos que el perceptrón es esencialmente un modelo lineal, que no puede resolver el problema XOR (o) más simple, "problema lineal inseparable";
Se pronunció la sentencia de muerte del perceptrón, y la investigación sobre redes neuronales también se ha estancado durante más de 10 años ( entrada al primer invierno frío ), y la investigación de las personas sobre redes neuronales también se ha estancado durante casi 20 años.

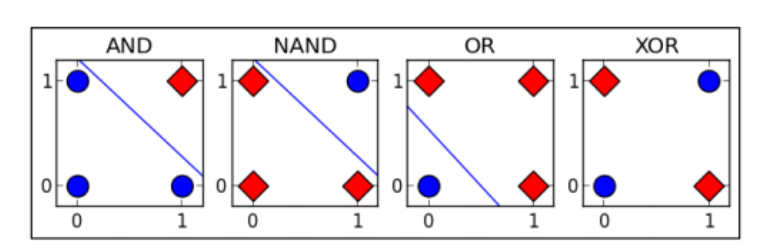
1982-1984: La etapa de desarrollo del período de invierno frío
- El fruto de la verdad siempre favorece a los científicos que pueden persistir en la investigación. Aunque la investigación de la red neuronal artificial ANN ha caído en un punto bajo sin precedentes, todavía hay algunos académicos dedicados a la investigación de ANN.
- En 1982, el famoso físico John Hopfield inventó la red neuronal de Hopfield . La red neuronal de Hopfield es una red neuronal recurrente que combina un sistema de memoria y un sistema binario. La red de Hopfield también puede simular la memoria humana, según la selección de la función de activación existen dos tipos: continua y discreta, las cuales se utilizan para optimizar el cálculo y la memoria asociativa respectivamente. Sin embargo, debido al defecto de que es fácil caer en el mínimo local, el algoritmo no causó gran sensación en ese momento.
- En 1984, Hinton colaboró con jóvenes académicos como Shenovsky para proponer una máquina de aprendizaje de redes paralelas a gran escala y propuso claramente el concepto de unidades ocultas. Esta máquina de aprendizaje más tarde se denominó máquina de Boltzmann . Usando los conceptos y métodos de la física estadística, primero propusieron un algoritmo de aprendizaje para redes multicapa, llamado modelo de máquina de Boltzmann.

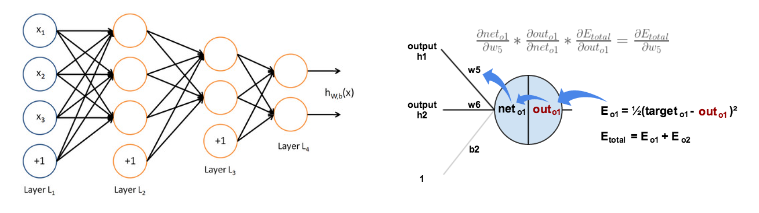
1986-1989: La introducción de algoritmos MLP y BP
- En 1986, Rumelhart, Hilton y otros inventaron el algoritmo adecuado para el perceptrón multicapa (Multi-Layer Perceptron, MLP) y el algoritmo de retropropagación de errores (Back Propagation, BP), y utilizaron la función Sigmoid para el mapeo no lineal, resolviendo el problema de manera efectiva. de El problema de la clasificación no lineal y el aprendizaje. El algoritmo BP provocó el segundo aumento de la red neuronal
- En 1989, Robert Hecht-Nielsen demostró el teorema de aproximación universal de MLP, es decir, para una función continua f en cualquier intervalo cerrado, la red BP con una capa oculta se puede utilizar para aproximar el teorema.Investigadores de redes.
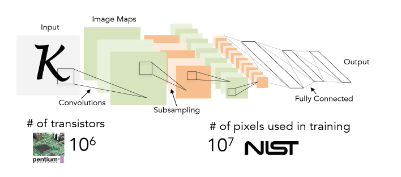
En 1989, LeCun inventó la red neuronal convolucional-LeNet y la utilizó para el reconocimiento digital, y logró buenos resultados, pero no atrajo suficiente atención en ese momento.
Después de 1989, debido a que no se propuso ningún método particularmente destacado, y NN ha carecido del correspondiente apoyo teórico matemático estricto, la moda de las redes neuronales retrocedió.
El segundo invierno frío llegó en 1991. El algoritmo BP señaló que había un problema de desaparición de gradiente , es decir, en el proceso de transmisión hacia atrás del gradiente de error, el gradiente de la capa posterior se superpuso a la capa frontal en una manera multiplicativa.Debido a las características de saturación de la función sigmoidea, la capa posterior El gradiente es inherentemente pequeño, y el gradiente de error es casi 0 cuando se pasa a la capa frontal, por lo que la capa frontal no se puede aprender de manera efectiva.Este descubrimiento empeoró el desarrollo de NN en este momento, y este problema obstaculizó directamente el desarrollo posterior del aprendizaje profundo . .
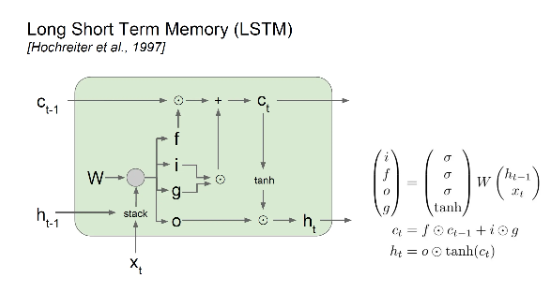
En 1997 se inventó el modelo LSTM, aunque el modelo tiene características sobresalientes en el modelado de secuencias, no ha atraído suficiente atención debido a que se encuentra en el período de descenso de NN.

1986-2006: El aprendizaje estadístico se generaliza
- En 1986, aparecieron uno tras otro métodos de árboles de decisión mejorados, como ID3, ID4 y CART, y todavía es un método de aprendizaje automático muy utilizado. Este método también es representativo de los métodos de aprendizaje simbólico.
- En 1995, los estadísticos V.Vapnik y C.Cortes inventaron el algoritmo de la máquina de vectores de soporte SVM . Este método tiene dos características: se deriva de una teoría matemática muy perfecta (estadística y optimización convexa, etc.), y está en línea con el sentimiento intuitivo humano (intervalo máximo). Sin embargo, lo más importante es que el método logró los mejores resultados en ese momento en el problema de la clasificación lineal,
- En 1997, se propuso AdaBoost, este método es el representante de la teoría PAC (probablemente aproximadamente correcto) en la práctica del aprendizaje automático, y también dio origen a la categoría de métodos integrados. Este método integra una serie de clasificadores débiles para lograr el efecto de un clasificador fuerte.
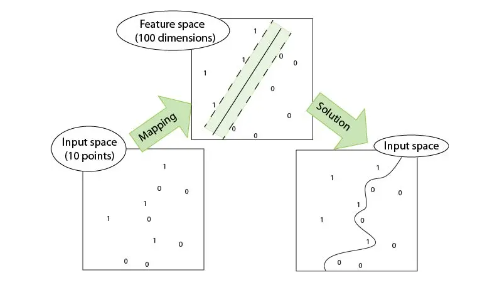
- En 2000, se propuso Kernel SVM. El SVM kernelizado resolvió con éxito el problema de la clasificación no lineal al mapear el problema linealmente inseparable del espacio original en un problema linealmente separable del espacio de alta dimensión a través de Kernel de una manera ingeniosa, y la clasificación El efecto es muy bueno. Hasta ahora, la era ANN ha llegado a su fin.
- En 2001, se propuso el bosque aleatorio, que es otro representante del método integrado. La teoría de este método es sólida y puede suprimir el problema de sobreajuste mejor que AdaBoost, y el efecto real también es muy bueno .
- En 2001, se propuso un nuevo modelo gráfico de marco unificado, que intentaba unificar los métodos caóticos del aprendizaje automático, como el bayesiano ingenuo, SVM, el modelo oculto de Markov, etc., para proporcionar una descripción unificada para varios marcos de métodos de aprendizaje.
Se han propuesto varios modelos de aprendizaje automático superficial, como el nacimiento del algoritmo de máquina de vector de soporte (algoritmo SVM) SVM también es un modelo de aprendizaje supervisado, que se aplica al reconocimiento de patrones, clasificación y análisis de regresión. Las máquinas de vectores de soporte se basan en estadísticas y son significativamente diferentes de las redes neuronales.La introducción de algoritmos como las máquinas de vectores de soporte ha obstaculizado una vez más el desarrollo del aprendizaje profundo.
1995: Aprendizaje Estadístico - SVM
- V.Vapnik y C.Cortes inventaron SVM.
- Es un modelo de clasificación de dos clases, y su modelo básico se define como un clasificador lineal con el mayor intervalo en el espacio de características, es decir, la estrategia de aprendizaje de la máquina de vectores de soporte es maximizar el intervalo, que finalmente se puede transformar en la solución de un problema de programación cuadrática convexa.

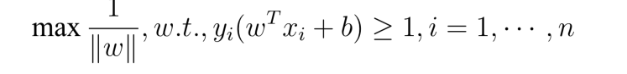
Ventajas del aprendizaje estadístico
-
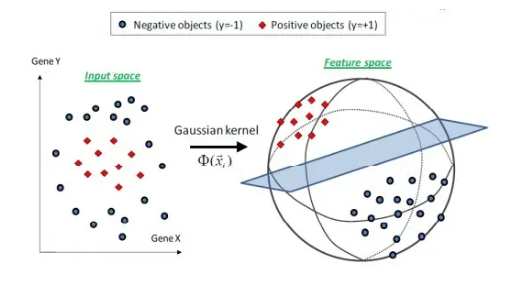
SVM utiliza la función del núcleo del producto interno en lugar del mapeo no lineal al espacio de alta dimensión;
-
SVM es un método de aprendizaje de muestra pequeña novedoso con una base teórica sólida;
-
La función de decisión final de SVM solo está determinada por una pequeña cantidad de vectores de soporte, y la complejidad del cálculo depende de la cantidad de vectores de soporte, no de la dimensión del espacio de muestra, evitando la "maldición de la dimensionalidad";
-
Un pequeño número de vectores de apoyo para la toma de decisiones, simple y eficiente, buena robustez (buena estabilidad).
-
G. Hinton y otros propusieron Deep Belief Network , que es un modelo generativo que permite que toda la red neuronal genere datos de entrenamiento con la máxima probabilidad entrenando los pesos entre sus neuronas.
-
Use un método codicioso capa por capa sin supervisión para entrenar previamente para obtener pesos, no confíe en la experiencia para extraer características de datos y refine automáticamente a través de la red subyacente
2006-2017: Etapa ascendente
- ** En 2006, Jeffrey Hinton y su alumno Ruslan Salahudinov propusieron formalmente el concepto de aprendizaje profundo. **En un artículo publicado en la revista académica más importante del mundo, "Science", dieron una solución detallada al problema de la "desaparición del gradiente": entrenaron el algoritmo capa por capa a través de un método de aprendizaje no supervisado y luego usaron el reverso supervisado. El algoritmo de propagación es afinado La propuesta de este método de aprendizaje profundo despertó de inmediato una gran repercusión en el círculo académico, la Universidad de Stanford, la Universidad de Nueva York y la Universidad de Montreal en Canadá se han convertido en importantes centros de investigación para el aprendizaje profundo, iniciando así una ola de aprendizaje profundo en la academia y la industria . .
- En 2011, se propuso la función de activación de ReLU, que puede suprimir eficazmente el problema de la desaparición del gradiente. Desde 2011, Microsoft ha logrado un gran avance al aplicar DL al reconocimiento de voz por primera vez. Los investigadores de reconocimiento de voz de Microsoft Research y Google han utilizado sucesivamente la tecnología DNN de redes neuronales profundas para reducir la tasa de error del reconocimiento de voz entre un 20 % y un 30 %, lo que supone el mayor avance en el campo del reconocimiento de voz en más de diez años.

- En 2012, la tecnología DNN logró resultados sorprendentes en el campo del reconocimiento de imágenes , reduciendo la tasa de error del 26 % al 15 % en la evaluación de ImageNet. En este año, DNN también se aplicó al problema de predicción de DrugActivity de las compañías farmacéuticas y logró los mejores resultados del mundo. En 2012, en la famosa competencia de reconocimiento de imágenes ImageNet, con el fin de demostrar el potencial del aprendizaje profundo, el equipo de investigación de Jeffrey Hinton participó por primera vez en la competencia de reconocimiento de imágenes ImageNet, y ganó el campeonato de un solo golpe a través de la red CNN construida. AlexNet, y aplastó El rendimiento de clasificación del segundo lugar (método SVM). ** También es por esta competencia que CNN ha llamado la atención de muchos investigadores. La irrupción de los algoritmos de aprendizaje profundo en la competencia mundial ha vuelto a atraer la atención de la academia y la industria en el campo del aprendizaje profundo.
- Con el avance continuo de la tecnología de aprendizaje profundo y la mejora continua de las capacidades de procesamiento de datos, en 2014, el proyecto DeepFace de Facebook basado en tecnología de aprendizaje profundo logró una tasa de precisión de más del 97 % en el reconocimiento facial, que es casi la misma que la de reconocimiento humano no hay diferencia. Este resultado demuestra una vez más que el algoritmo de aprendizaje profundo es el mejor en el reconocimiento de imágenes.
- **En marzo de 2016, AlphaGo (basado en un algoritmo de aprendizaje profundo) desarrollado por la empresa DeepMind de Google compitió con el campeón mundial de Go y jugador profesional de Go de nueve dan Li Sedol en una batalla hombre-máquina con una puntuación total de 4 a 1. ; A fines de 2016 y principios de 2017, el programa usó "Master" (Maestro) como la cuenta registrada en el sitio web de ajedrez chino para jugar ajedrez rápido contra docenas de maestros de Go chinos, japoneses y coreanos, y no hubo pérdida en 60 juegos consecutivos.
- En 2017, nació AlphaGo Zero, una versión mejorada de AlphaGo basada en el algoritmo de aprendizaje por refuerzo . Adopta el modo de aprendizaje de "empezar de cero" y "enseñar sin profesor", superando fácilmente al AlphaGo anterior con una puntuación de 100:0. Además, en este año, los algoritmos relevantes de aprendizaje profundo han logrado resultados notables en muchos campos, como la atención médica, las finanzas, el arte y la conducción sin conductor. Por ello, algunos expertos consideran 2017 como el año de mayor desarrollo del aprendizaje profundo e incluso de la inteligencia artificial.

El futuro de las ANN (redes neuronales)
para siempre o desaparecer?
-
Al ingresar al siglo XXI, al observar el desarrollo del aprendizaje automático, los puntos críticos de investigación se pueden resumir brevemente como aprendizaje múltiple de 2000 a 2006 , aprendizaje escaso de 2006 a 2011 y aprendizaje profundo de 2012 al presente . ¿Qué algoritmo de aprendizaje automático se convertirá en un tema candente en el futuro?
-
Wu Enda dijo una vez: "Después del aprendizaje profundo, el aprendizaje por transferencia liderará la próxima ola de tecnología de aprendizaje automático". Pero al final, ¿cuál es el próximo punto crítico en el aprendizaje automático? ¿Quién puede decirlo con certeza?
Aprendizaje por transferencia: el aprendizaje por transferencia es un método de aprendizaje automático en el que un modelo previamente entrenado se reutiliza en otra tarea.
Contrato de 5 años en Bell Labs
En 1995, dos apuestas interesantes surgieron de Bell Labs. Los dos lados de la apuesta son: Larry Jackel, exjefe de Bell Labs, y Vladimir Vapnik, uno de los creadores de Support Vector Machine.
La primera apuesta: Larry Jackel cree que para el año 2000 a más tardar tendremos una explicación teórica madura de por qué funcionan las redes neuronales.
La segunda apuesta: Vladimir Vapnik cree que para el año 2000, todos ya no usarán la estructura de las redes neuronales. (Después de todo, las personas son uno de los creadores de máquinas de vectores de soporte, por lo que naturalmente reconocen más las máquinas de vectores de soporte)
¿Y el resultado de la apuesta? - Perdieron los dos. Todavía no tenemos una explicación sólida de por qué las redes neuronales funcionan tan bien; mientras tanto, todavía estamos usando arquitecturas de redes neuronales.
Reflexiones sobre la inteligencia artificial
En general, bajo el estandarte de la inteligencia artificial, diferentes personas están haciendo cosas diferentes: algunas construyen modelos cerebrales, algunas simulan el comportamiento humano, algunas desarrollan campos de aplicaciones informáticas, algunas diseñan nuevos algoritmos y algunas resumen las leyes del pensamiento. Si bien todos estos estudios son valiosos y están relacionados, no son sustitutos entre sí, y confundirlos puede generar confusión.
De hecho, la inteligencia artificial para fines especiales ha logrado un gran avance, pero, por otro lado, la investigación y la aplicación de la inteligencia artificial general aún tienen un largo camino por recorrer. Para lograr un gran avance en la inteligencia artificial general, todavía debemos hacer todo lo posible. .
En la actualidad, la inteligencia artificial tiene inteligencia pero no sabiduría, IQ pero no EQ, puede calcular pero no calcular, tiene especialistas pero no generalistas.
——Tan Tieniu, "Reflexiones sobre el desarrollo de la inteligencia artificial". Conferencia de Inteligencia Artificial de China 2016 (CCAl 2016)
palabras escritas en la espalda
Si crees que esta serie de artículos es útil para ti, ¡no olvides darle me gusta y seguir al autor! ¡Tu aliento es mi motivación para seguir creando, compartiendo y agregando más! Que todos nos encontremos en la cima juntos. ¡Bienvenido a la cuenta oficial del autor: "01 Cabina de Programación" como invitado! ¡Sigue la choza, aprende a programar sin perderte!