Tabla de contenido
3.1 Del perceptrón a la red neuronal
3.1.1 Ejemplos de redes neuronales:
3.1.2 Conversión de funciones:
3.2.1 Tipo de función de activación:
3.2.3 Gráfico de función de clase
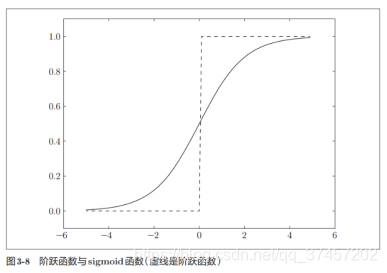
3.2.2 Comparación de la función escalonada y la función sigmoidea:
3.3 Operación de matriz multidimensional:
3.3.1 El producto interno de la red neuronal:
3.4. Implementación de una red neuronal de tres capas
3.5.1 Tres tipos de funciones de salida
3.5.2 El problema de desbordamiento de la función softmax
3.5.3 Características de la función Softmax:
3.5.4 El número de neuronas en la capa de salida
3.6 Reconocimiento de dígitos escritos a mano
Procesamiento único y procesamiento por lotes
Tres, red neuronal
Resolver el problema: El capítulo anterior puede usar AND o non para resolver varios problemas de funciones, pero los pesos se establecen manualmente . Este capítulo comienza con la realización de redes neuronales y usa datos existentes para aprender los pesos apropiados como parámetros para resolver los problemas anteriores.
3.1 Del perceptrón a la red neuronal
3.1.1 Ejemplos de redes neuronales:
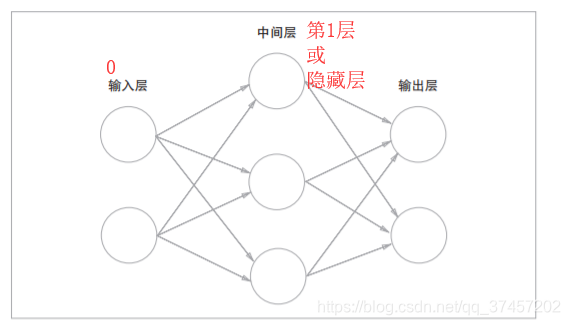
La red neuronal es en realidad lo mismo que el perceptrón
3.1.2 Conversión de funciones:
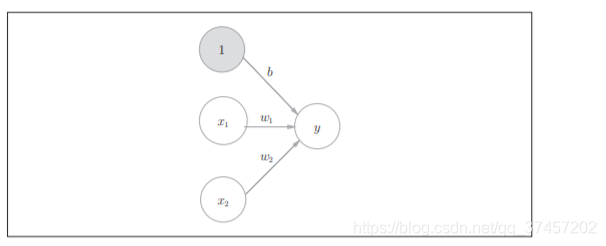
Referencia: diagrama de fórmulas compilado por el compañero de clase Fang
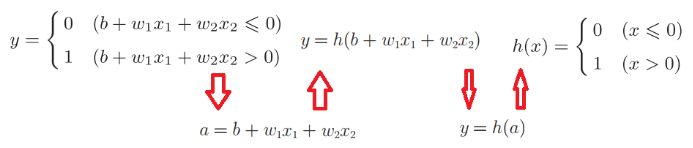
De acuerdo con la conversión de función en la figura anterior, podemos convertir a h (x), que es la función de activación
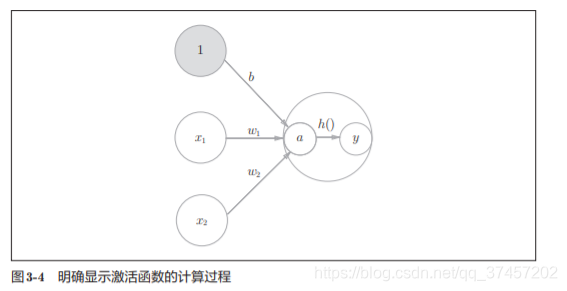
La función de activación es el puente entre el perceptrón y la red neuronal.
3.2 Función de activación
3.2.1 Tipo de función de activación:
Función de activación a un valor de umbral como límite, una vez que la entrada supera el umbral , la salida conmuta. Esta función se denomina "función escalonada" .
La función de activación se divide en una función escalonada y una función sigmoidea . La función escalonada es cambiar la salida cuando el valor de entrada excede un cierto umbral.
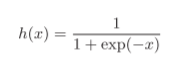
Donde exp (−x) significa, h (x) también es la función de pérdida de la clasificación de términos comunes
Código:
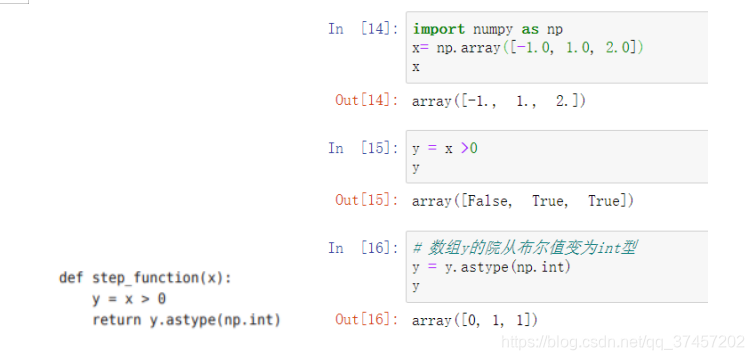
3.2.3 Gráfico de función de clase
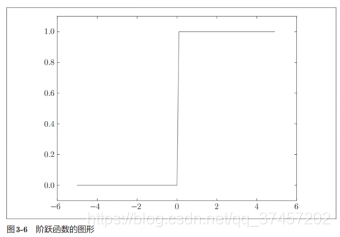
Función de paso y realización de imagen :

imagen de la función sigmoidea:
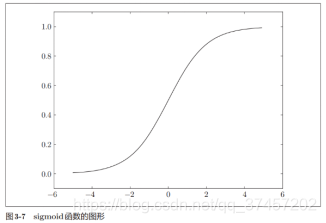
3.2.2 Comparación de la función escalonada y la función sigmoidea:
| Función de paso | función sigmoidea |
|---|---|
| No suave | Suave |
| Solo 2 valores (valor binario) | Valores reales ilimitados |
Las similitudes entre los dos es que están en el rango entre 0-1
La función de activación de la red neuronal debe utilizar una función no lineal .
Además, sigmoide es una curva no lineal , a diferencia de la función lineal (línea recta) h (x) = cx (c es una constante), porque la función lineal no tiene una capa oculta en el perceptrón multicapa, como
Lo mismo es y = ax, que no puede aprovechar múltiples capas.
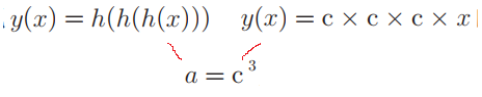
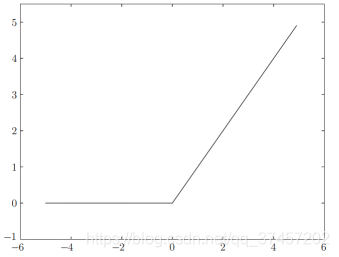
3.2.3 Función RELU:
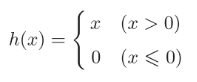
Salida x directamente cuando es mayor que 0, salida 0 cuando es menor o igual que 0
Implementación de la función: donde maxinum devuelve el valor máximo
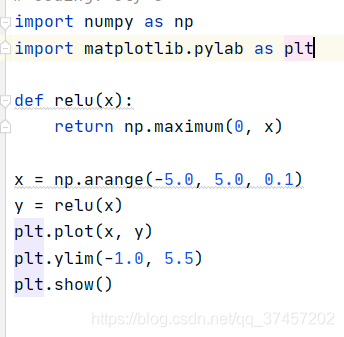
El efecto se muestra en la figura:
3.3 Operación de matriz multidimensional:
np.ndim (A) Salida A dimensión de la matriz
La forma de salida de np.shape tiene varios componentes. El resultado es una tupla.
3.3.1 El producto interno de la red neuronal:
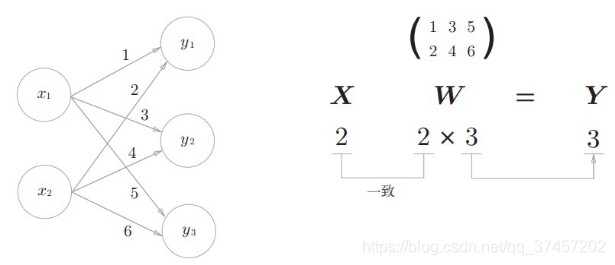
Utilice np.dot (producto escalar de matrices multidimensionales), solo operaciones matriciales
3.4. Implementación de una red neuronal de tres capas

Significado del símbolo:
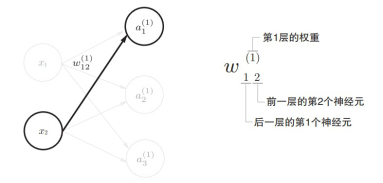
Análisis de principio:
1) Realice la 0 a la primera capa:
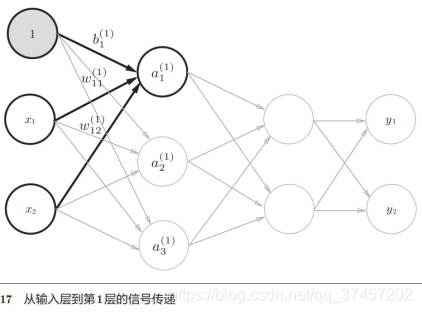
sabemos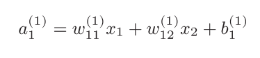
Entonces, existe el primer nivel de ponderación :
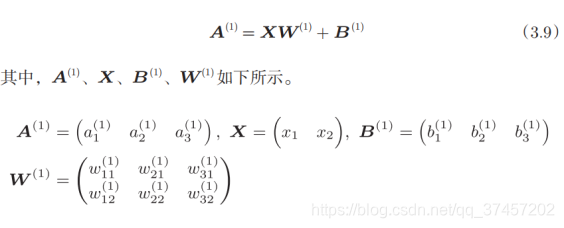
Código:

2) Realice la transformación (función sigmoidea) de la función de activación h () de a1 a z1 en la siguiente figura :
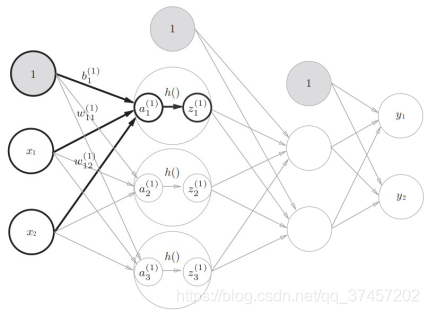
Código:

3) Igual que la primera a la segunda capa, repita los pasos anteriores directamente:
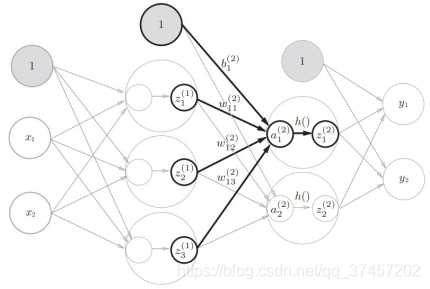
Código:

4) La segunda a la tercera capa (capa de salida) son básicamente los mismos que los pasos anteriores, pero la función de activación es diferente :
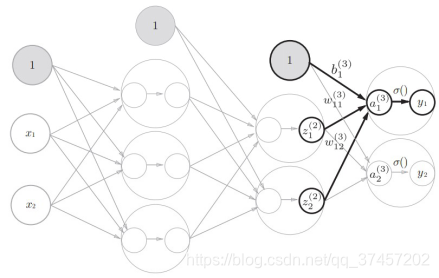

5) Implementación general del código:

Nota: Generalmente, la función de identidad se puede usar para problemas de regresión , la función sigmoidea se puede usar para problemas de clasificación binaria y la función softmax se puede usar para problemas de clasificación multivariante . 3.5 Diseño de la capa de salida:
3.5.1 Tres tipos de funciones de salida
1) Función de identidad : se genera directamente tal como está, se utiliza en problemas de regresión
2) función sigmoidea :, 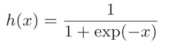 utilizada en problemas de clasificación binaria.
utilizada en problemas de clasificación binaria.
3) Función Softmax :, 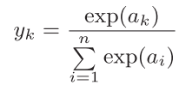 utilizada en múltiples problemas de clasificación.
utilizada en múltiples problemas de clasificación.
Entre ellos, la función softmax significa que la señal de entrada se ve afectada entre cada salida , como se muestra en la figura:
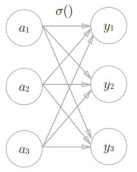
Código:


3.5.2 El problema de desbordamiento de la función softmax
Todos sabemos que e ^ x explotará cuando x sea grande , lo que provocará un desbordamiento , por lo que debemos mejorar


3.5.3 Características de la función Softmax:

Podemos ver que la salida y está entre 0-1, y su suma es 1, por lo que podemos convertirlo en un problema de probabilidad , es decir, cuanto mayor es la salida, mayor es su probabilidad. De la figura anterior, Se puede ver que y [2] es el más grande, por lo que la respuesta es la segunda categoría; además, e ^ x es una función que aumenta monótonamente, por lo que en el ejemplo anterior, la relación entre el tamaño de un elemento y el tamaño de y permanece sin cambios, y y [2] es el más grande. Entonces, de hecho, no necesitamos la función softmax en absoluto, y podemos saber qué probabilidad es la más grande mirando el elemento a (debido a que softmax requiere una operación exponencial, la cantidad de cálculo es bastante grande).
3.5.4 El número de neuronas en la capa de salida
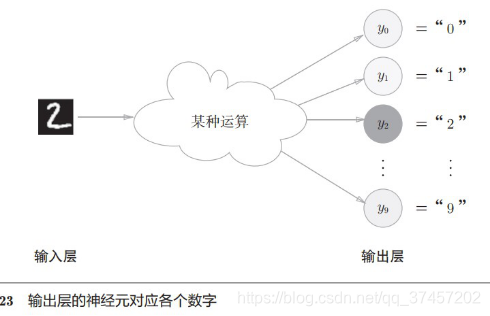
Como se puede ver en la figura anterior, el número de neuronas de salida está determinado por el número de categorías. Si el resultado de salida es 10 categorías de 0 a 9, entonces la salida de neuronas es 10.
3.6 Reconocimiento de dígitos escritos a mano
A continuación, utilizaremos nuestro algoritmo en aplicaciones prácticas, el ejemplo clásico de reconocimiento de dígitos escritos a mano.
Los comentarios del código son los siguientes, por lo que no los describiré uno por uno.

La función load_mnist devuelve los datos MNIST leídos en forma de "(imagen de entrenamiento, etiqueta de entrenamiento), (imagen de prueba, etiqueta de prueba)".

Número de pantalla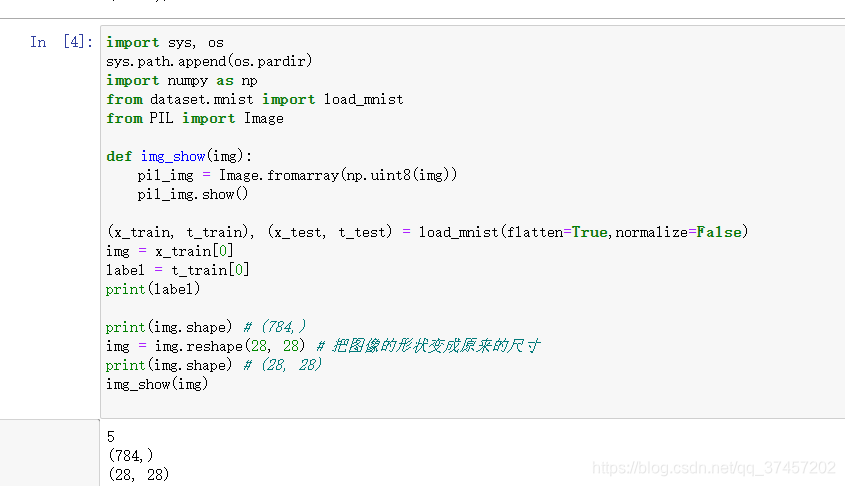
Salida de red neuronal
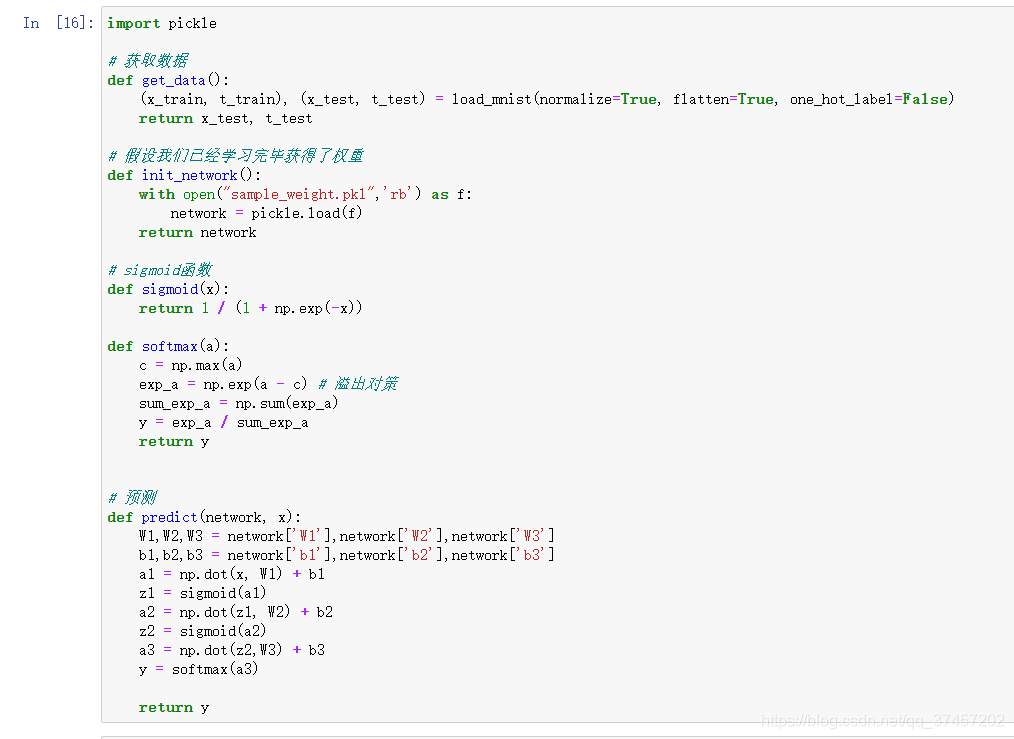
Procesamiento único y procesamiento por lotes
Por el ejemplo anterior, sabemos que la capa de entrada tiene 784 neuronas (28 * 28) y la capa de salida tiene 10 neuronas. Suponiendo que hay 50 y 100 neuronas en las 1-2 capas de la capa oculta, tenemos el siguiente procesamiento de código :
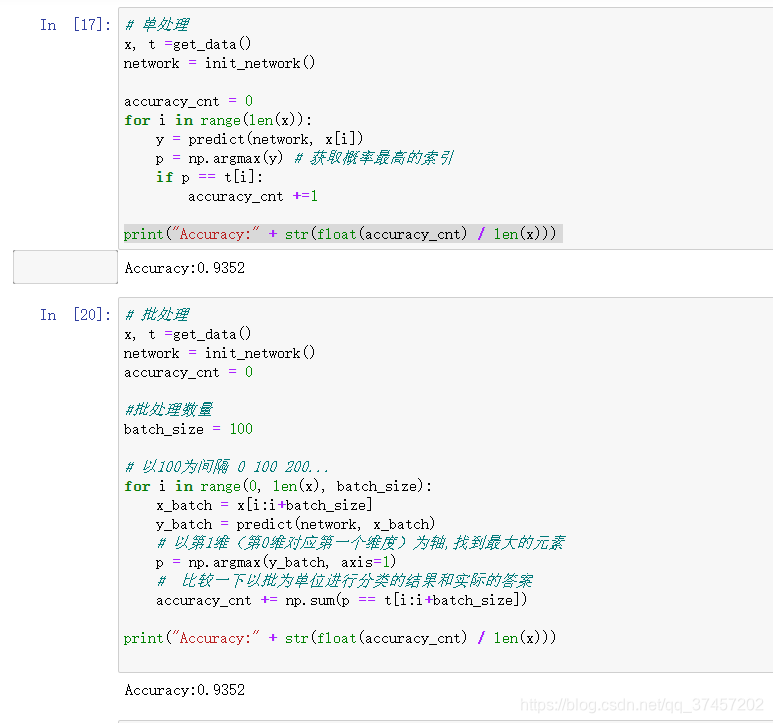
1) Procesamiento único:
Usando el conocimiento de la función anterior, ahora podemos juzgar formalmente la precisión entre la imagen y la etiqueta después del entrenamiento:
2) Procesamiento por lotes:
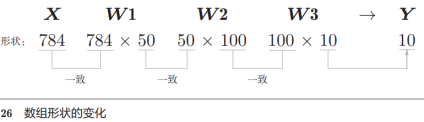
Del ejemplo anterior (arriba), conocemos la forma de la matriz después de 1 entrada de imagen (1 * 28 * 28 ) y salida (probabilidad de 10 categorías)
A continuación, empaquetaremos el ejemplo anterior en 100 imágenes a la vez para el cálculo.
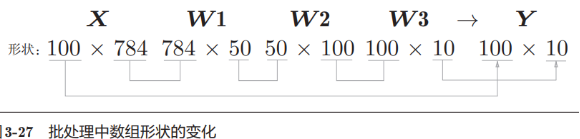
Los beneficios del procesamiento por lotes: cada vez que calculamos una imagen, io solo toma 1 imagen a la vez . Ahora tomamos 100 io a la vez para calcular , debido a que la velocidad de cálculo es más rápida que la velocidad de io, el procesamiento por lotes cambiará en el cálculo general Más rápido
Código:
resumen:
Como en el capítulo anterior, no consideramos cómo encontrar los pesos específicos y la salida a través de las funciones de cada capa, formando así una red neuronal simple.
Los parámetros anteriores se explicarán más adelante.