[ML-13-1 ] Modelo oculto de Markov HMM
[ML-13-2 ] Modelo oculto de Markov HMM- algoritmo hacia adelante y hacia atrás
[ML-13-3 ] Modelo oculto de Markov HMM - Baum-Welch ( Baum- Welch)
[ML-13-4 ] Modelo de Markov oculto HMM-- Algoritmo de Viterbi (Viterbi) para problemas de predicción
Directorio
- Introduccion
- Cálculo directo
- Algoritmo de avance
- Ejemplo de algoritmo directo
- Algoritmo hacia atrás
- Cálculo de probabilidad común de HMM
1. Introducción
En [ML-13-1] Hidden Markov Model HMM, hablamos sobre el conocimiento básico del modelo HMM y los tres problemas básicos de HMM. En este artículo, nos enfocamos en la solución del primer problema básico de HMM. Es decir, dado el modelo λ = (A, B, π) y la secuencia observada Q = {q1, q2, ..., qT}, calcule la probabilidad P (Q | λ) de la secuencia observada Q bajo el modelo λ
Probabilidad hacia adelante-probabilidad hacia atrás en realidad se refiere a la información convertida del valor de probabilidad del estado si correspondiente al tiempo t en una secuencia de observación.
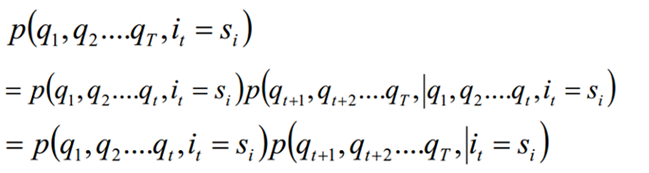
En la siguiente figura (implicada por q y observación por y), la primera es la probabilidad hacia adelante (todos los estados de observación 1-t y el estado implícito en el tiempo t), y la segunda es la probabilidad hacia atrás

2. Cálculo directo
De acuerdo con la fórmula de probabilidad, enumere todas las secuencias de estado posibles con longitud T I = {i1, i2, ..., iT}, encuentre cada secuencia de estado I y secuencia de observación Q = {q1, q2, ..., qT} Probabilidad conjunta P (Q, I; λ), y luego sumar todas las secuencias de estado posibles para obtener la probabilidad final P (Q; λ)
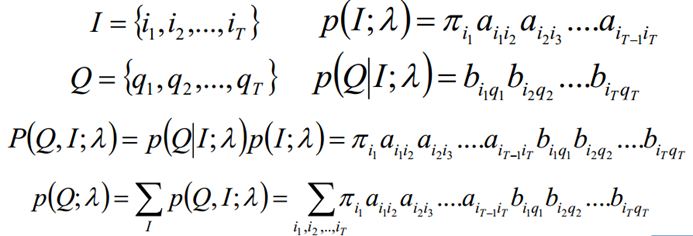

El algoritmo de avance y retroceso es para ayudarnos a resolver este problema en una menor complejidad de tiempo.
Tres, algoritmo directo
El algoritmo de avance y retroceso es un término general para el algoritmo de avance y el algoritmo de retroceso. Ambos algoritmos se pueden utilizar para encontrar la probabilidad de la secuencia de observación HMM. Primero veamos cómo el algoritmo de avance resuelve este problema.
El algoritmo directo es esencialmente un algoritmo para la programación dinámica, es decir, tenemos que encontrar la fórmula para la recursión del estado local, de modo que paso a paso, desde la solución óptima del subproblema hasta la solución óptima de todo el problema.
Definición: Dada λ, la probabilidad de que parte de la secuencia de observación en el tiempo t sea q1, q2, ..., qt y el estado oculto sea si es la probabilidad directa. Recuerda:
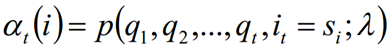
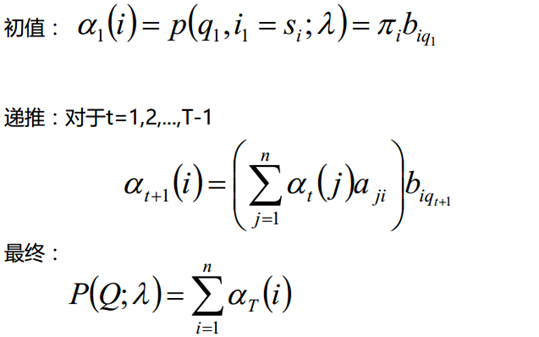
El proceso de derivación es el siguiente, y también puede comprenderlo usted mismo: el estado i en el momento t + 1 puede derivarse de cada estado después de la transformación

De la fórmula recursiva se puede ver que la complejidad temporal de nuestro algoritmo es O (TN ^ 2), que es varios órdenes de magnitud menor que la complejidad temporal de la solución de fuerza bruta O (TN ^ T).
Cuatro ejemplos de algoritmo directo
4.1 Ejemplos
Supongamos que hay tres cajas, numeradas 1,2,3; cada caja está equipada con pequeñas bolas de colores blanco y negro, la proporción de las bolas es la siguiente:
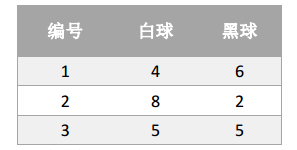
De acuerdo con las siguientes reglas, la bola con el reemplazo se extrae para obtener la secuencia de observación del color de la bola:
- Seleccione un cuadro de acuerdo con la probabilidad de π, extraiga aleatoriamente una pequeña bola del cuadro, registre el color y vuelva a colocarlo en el cuadro;
- Seleccione un nuevo cuadro de acuerdo con una cierta probabilidad condicional y repita la operación;
- Obtuve la secuencia de observación finalmente: "Blanco negro y blanco blanco negro
- Conjunto de estados: S = {Cuadro 1, Cuadro 2, Cuadro 3}
- Conjunto de observación: O = {blanco, negro}
- Secuencia de estado y longitud de secuencia de observación T = 5
- Distribución de probabilidad inicial π
- Matriz de probabilidad de transición de estado A
- Matriz de probabilidad de observación B
Dados los parámetros π, A y B, ¿cuál es la probabilidad de que la secuencia observada sea "blanca, negra, blanca, blanca y negra"? Tenga en cuenta que en este proceso, el observador solo puede ver la secuencia de colores de la pelota, pero no la pelota. Fue tomado de qué caja.

4.2 Proceso de cálculo


Obtén el resultado final:

Cinco, algoritmo hacia atrás
Familiarizado con el algoritmo hacia adelante para encontrar la probabilidad de secuencia de observación HMM, ahora mire cómo usar el algoritmo hacia atrás para encontrar la probabilidad de secuencia de observación HMM.
El algoritmo hacia atrás es muy similar al algoritmo hacia adelante. Ambos son programación dinámica. La única diferencia es que el estado local seleccionado es diferente. El algoritmo hacia atrás usa "probabilidad hacia atrás". Entonces, ¿cómo se define la probabilidad hacia atrás?
Definición: Dado λ, se define que bajo la premisa de que el estado en el tiempo t es si, la parte de la secuencia de observación de t + 1 a T es qt + 1, qt + 2, ..., y la probabilidad de qT es la probabilidad hacia atrás. Recuerda:
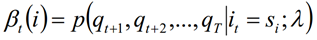
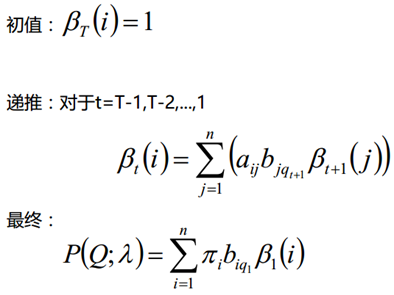
Derivación:

De acuerdo con esta fórmula, las probabilidades en la sección anterior también se pueden calcular y los resultados obtenidos son los mismos. Este artículo no dará ejemplos.
6. Cálculo de probabilidades comunes de HMM
Usando las probabilidades hacia adelante y hacia atrás, podemos calcular la fórmula de probabilidad para un solo estado y dos estados en el HMM.
6.1 Probabilidad de un solo estado
Dado el modelo λ y la secuencia de observación Q, la probabilidad de estar en el estado si en el tiempo t se escribe como:
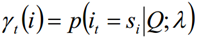
La importancia de la probabilidad de un solo estado se usa principalmente para juzgar el estado más probable en cada momento, de modo que se pueda obtener una secuencia de estado como resultado final de la predicción.
Usando la definición de probabilidad hacia adelante y hacia atrás, podemos saber:
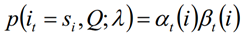
De las dos expresiones anteriores:
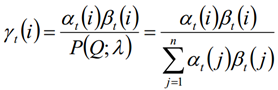
6.2 Probabilidad conjunta de dos estados
Dado el modelo λ y la secuencia de observación Q, la probabilidad de estar en el estado si en el tiempo t y estar en el estado sj en el tiempo t + 1 se escribe como:

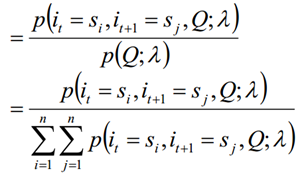
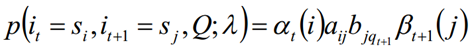
6.3 Se pueden obtener las dos sumas anteriores:



Apéndice 1: probabilidad de avance
| 1 2 3 4 4 5 5 6 6 7 7 8 9 9 10 11 12 13 14 15 dieciséis 17 18 años 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# - codificación: utf-8 - "" " Un algoritmo implementado en clase para calcular la probabilidad directa en el modelo HMM ( algoritmo directo )" "" importar numpy como np def calc_alpha (pi, A, B, Q, alfa): "" " Calcule la probabilidad de avance alfa y guarde el resultado en la matriz alfa (T * n) : param pi: 1 * n : detener A: n * n : parámetro B: n * m : parámetro Q: 1 * T => T array : parámetro alfa: T * n : retorno: alfa "" " # 1. Obtenga información variable relacionada n = np. forma (A) [ 0 ] T = np. forma (Q) [ 0 ] # 2 Actualice el valor de probabilidad directa en el tiempo t = 1 para i en rango (n): alpha[0][i] = pi[i] * B[i][Q[0]] # 3. 更新t=2... T时刻对应的前向概率值 tmp = np.zeros(n) for t in range(1, T): # 迭代计算t时刻对应的前向概率值 for i in range(n): # 计算时刻t状态为i的前向概率 # a. 计算上一个时刻t-1累计到当前状态i的概率值 for j in range(n): tmp[j] = alpha[t - 1][j] * A[j][i] # b. 更新时刻t对应状态i的前向概率值 alpha[t][i] = np.sum(tmp) * B[i][Q[t]] # 4. 返回结果 return alpha if __name__ == '__main__': # 测试 pi = np.array([0.2, 0.5, 0.3]) A = np.array([ [0.5, 0.4, 0.1], [0.2, 0.2, 0.6], [0.2, 0.5, 0.3] ]) B = np.array([ [0.4, 0.6], [0.8, 0.2], [0.5, 0.5] ]) # 白,黑,白,白,黑 Q = [0, 1, 0, 0, 1] alpha = np.zeros((len(Q), len(A))) # 开始计算 calc_alpha(pi, A, B, Q, alpha) # 输出最终结果 print(alpha) # 计算最终概率值: p = 0 for i in alpha[-1]: p += i print(Q, end="->出现的概率为:") print(p) |
结果:
[[0.08 0.4 0.15 ]
[0.09 0.0374 0.1465 ]
[0.032712 0.093384 0.037695 ]
[0.01702872 0.04048728 0.03530505]
[0.0142037 0.00651229 0.01829338]]
[0, 1, 0, 0, 1]->出现的概率为:0.03900936690000001
附件一:手写练习
