Caracteres de ancho cero, búsqueda hacia adelante y búsqueda hacia atrás en expresiones regulares (resumen usted mismo)
Prólogo
Cuando estaba cepillando HackerRankla Pythonpregunta, me encontré con una 正则表达式relacionada y descubrí que involucra puntos de conocimiento que no conozco bien.
Titulo
Validar códigos postales
https://www.hackerrank.com/challenges/validating-postalcode/problem
Un código postal válido
P debe cumplir los dos requisitos siguientes: P debe ser un número en el rango de 100000 a 999999 inclusive.
P no debe contener más de un par de dígitos repetitivos alternos.
Los dígitos repetitivos alternos son dígitos que se repiten inmediatamente después del siguiente dígito. En otras palabras, un par de dígitos repetitivos alternos está formado por dos dígitos iguales que tienen un solo dígito entre ellos.Por ejemplo:
121426 # Aquí, 1 es un dígito repetitivo alterno.
523563 # Aquí, NO dígito es un dígito repetitivo alterno.
552523 # Aquí, 2 y 5 son dígitos repetitivos alternos.Su tarea es proporcionar dos expresiones regulares regex_integer_in_range y> regex_alternating_repetitive_digit_pair. Donde:
regex_integer_in_range debe coincidir solo con un rango entero de 100000 a 999999 inclusive
regex_alternating_repetitive_digit_pair debe encontrar pares alternos de dígitos repetitivos en una cadena dada.La plantilla de código proporcionada utilizará ambas expresiones regulares para verificar si la cadena de entrada P es un> código postal válido utilizando la siguiente expresión:
(bool (re.match (regex_integer_in_range, P))
y len (re.findall (regex_alternating_repetitive_digit_pair , P)) <2)Formato de entrada El
código auxiliar bloqueado en el editor lee una sola cadena que denota P de stdin y usa la expresión proporcionada y> sus expresiones regulares para validar si P es un código postal válido.Formato de salida
No es responsable de imprimir nada en stdout. El código auxiliar bloqueado en el editor hace eso.Entrada de muestra 0
110000Salida de muestra 0
FalseExplicación 0
1 1 0 0 0 0 : (0, 0) y ( 0 , 0 ) son dos pares de dígitos alternos. Por lo tanto, es un código postal no válido.Nota:
Se otorgará una puntuación de 0 por usar condiciones 'if' en su código.
Tienes que pasar todos los casos de prueba para obtener una puntuación positiva.regex_integer_in_range = r"_________" # Do not delete 'r'. regex_alternating_repetitive_digit_pair = r"_________" # Do not delete 'r'. # 以下代码是不能修改的,能输入的只有上面两条正则表达式 import re P = input() print (bool(re.match(regex_integer_in_range, P)) and len(re.findall(regex_alternating_repetitive_digit_pair, P)) < 2)
En pocas palabras, ingrese un número de seis dígitos y use expresiones regulares para juzgar si cumple con las siguientes reglas:
- El rango de números está dentro de 100,000 a 999999;
- No puede haber dos conjuntos
交替重复de números en el número de seis dígitos .交替重复Significa que el mismo número está separado por un número, es decir, el 5 antes y después de 0 en 505 es un grupo交替重复de números.
Proceso
# 字符串前面的r 表示原样输出,不做任何转义
# 第一个正则表达式比较简单,判断数字的范围从100000 到999999
regex_integer_in_range = r"^[1-9][0-9]{5}$" # Do not delete 'r'.
# 第二个非常tricky
regex_alternating_repetitive_digit_pair = r"(\d)\d\1" # Do not delete 'r'.
# \d 表示任何数字,
# \1 引用前面第一个括号的内容,这里是(\d)
# (\d)\d\1 即任何数字(\d) 在某个数字\d 后再同样地出现一次\1,符合交替重复的定义
# 但是,r'(\d)\d\1' 遇到1010 只能匹配到第一组交替重复的数字101 而不能匹配第二组010,所以失败了
# 以下代码是不能修改的,能输入的只有上面两条正则表达式
import re
P = input()
print (bool(re.match(regex_integer_in_range, P))
and len(re.findall(regex_alternating_repetitive_digit_pair, P)) < 2)
La respuesta
https://www.hackerrank.com/challenges/validating-postalcode/editorial
Validar códigos postales
Editorial por DOSHI
Enfoque es:a) (?=(\d)\d\1) using this regex findall how many alternating repetitive digits are there. b) ^[1-9][0-9]{5}$ using this regex check that postal code is in the range 100000 - 999999Agregue el booleano obtenido de estos a los cheques e imprima el resultado.
Establecido por
el código de DOSHI Problem Setter:import re P = raw_input() print len(re.findall(r'(?=(\d)\d\1)',P)) < 2 and bool(re.match(r'^[1-9][0-9]{5}$',P))
Entender
# 相对我的表达式
re.findall(r'(\d)\d\1',P)
# 正确答案用了零宽式断言(zero-width assertion)
re.findall(r'(?=(\d)\d\1)',P)
Según tengo entendido, una expresión regular es solo una 断言(Assertion), pero solo trata con diferentes objetos.
- expresiones regulares ordinarios, o que
普通断言se trata de un partido字符串; 零宽断言, Coincide entre cada carácter en la cadena位置.
Tome el experimento en https://regexr.com como ejemplo:
Aserción común
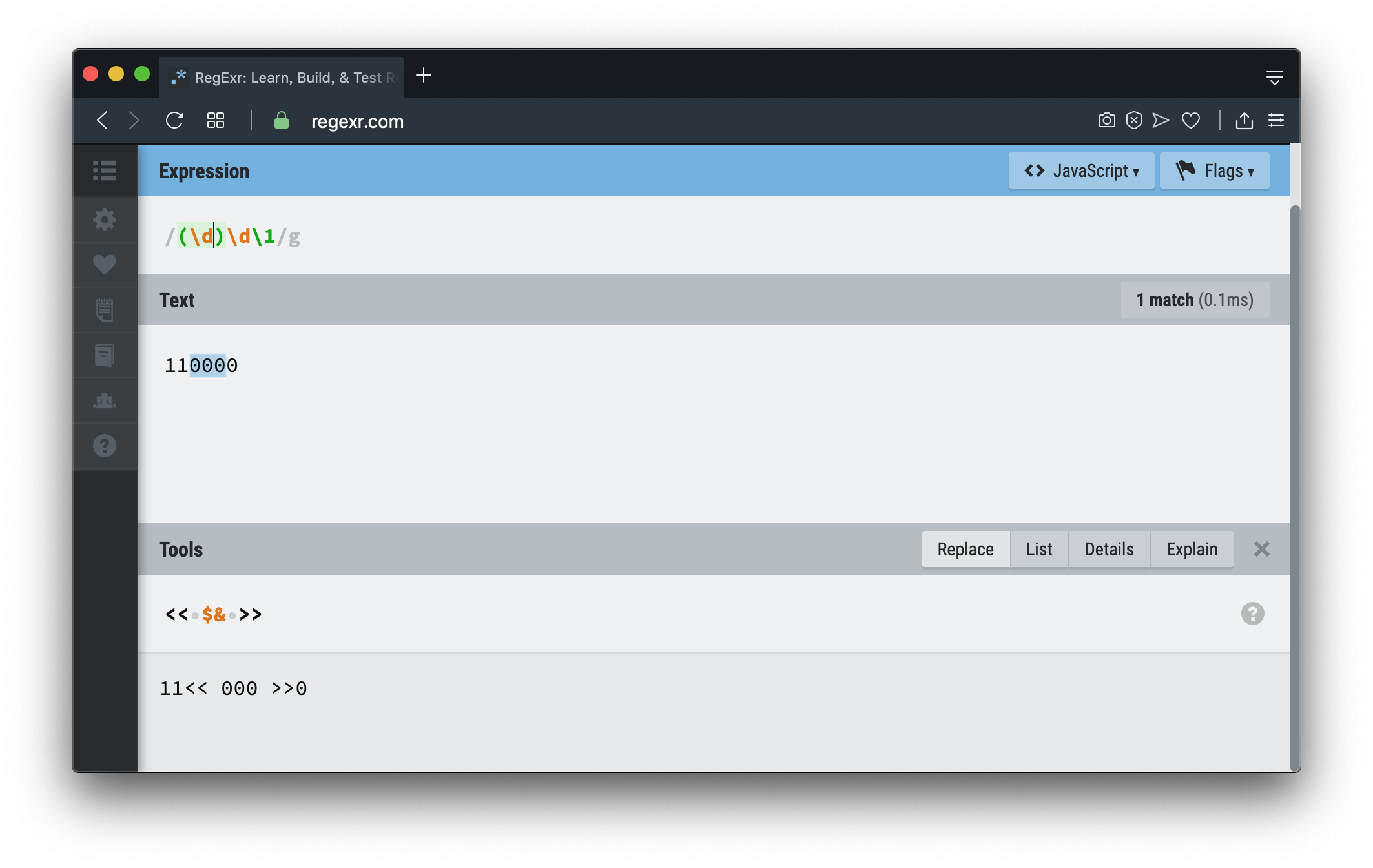
普通断言Las cadenas se harán coincidir una por una, y las cadenas buscadas no volverán y coincidirán de nuevo, lo que se llama 字符串消耗.
Como se muestra en la figura 110000, 000después de la coincidencia , se ha consumido toda la cadena 11000y ya no hay ningún contenido que pueda coincidir, y luego todo el proceso se detiene.
Afirmación de ancho cero
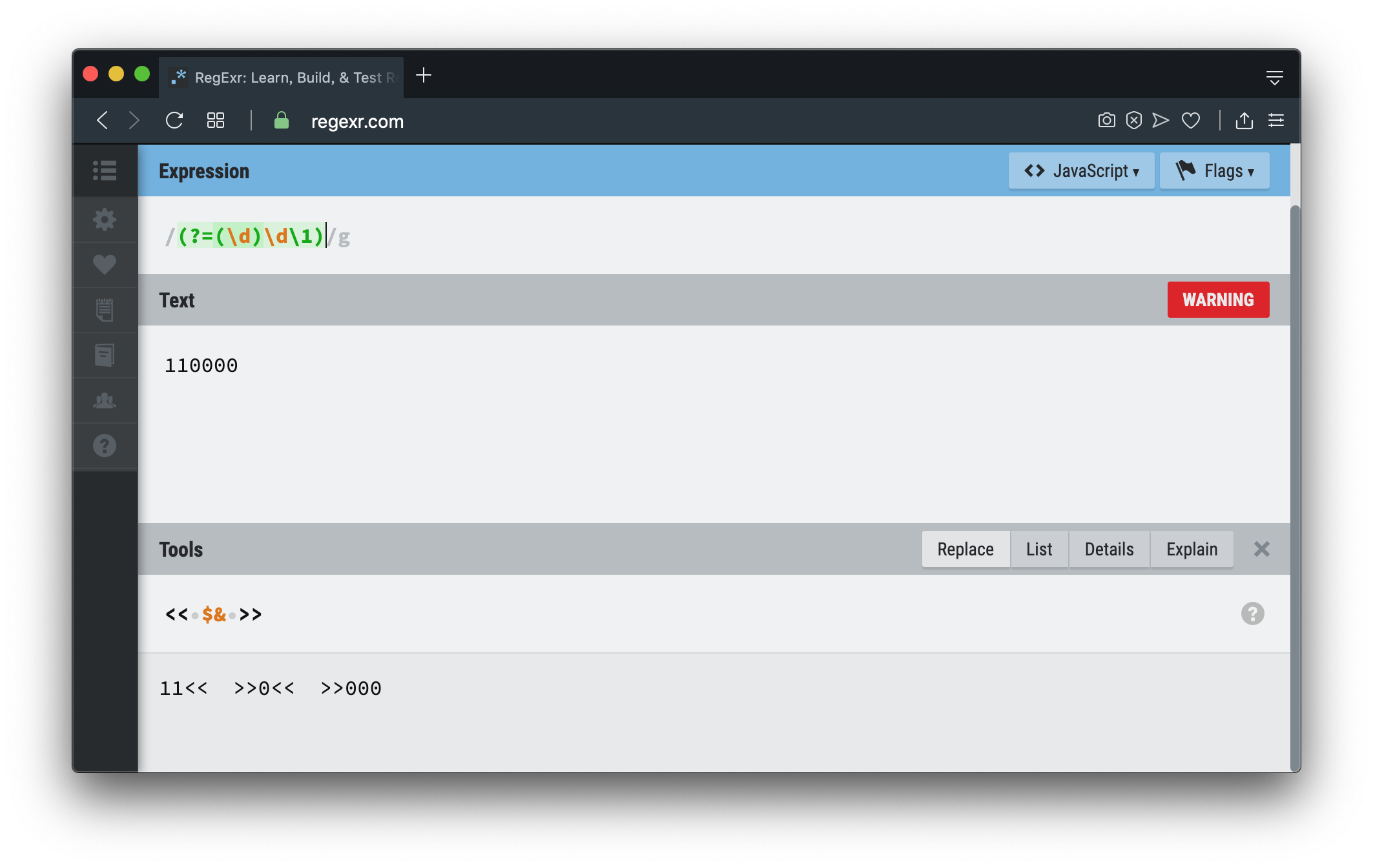
零宽断言También hará coincidir las cadenas una por una, pero la 普通断言diferencia es que la 零宽断言preocupación es 位置que 位置no mirará hacia atrás y volverá a coincidir.
Tales como el principio de una línea ^, final de la línea $entre el personaje \by por lo que estos son 位置.
宽度Es para el 字符的数量propósito, como el aancho es 1, el abancho es 2, pero no 位置es un carácter, por lo que 没有宽度es 0.
En la figura 110000, 000después de la coincidencia , se 零宽断言guarda lo 000anterior 位置. Si se |expresa 位置, es decir, 11 |0000,
continúe buscando hacia atrás desde esta posición. Después de encontrar la segunda 000, se guardará lo mismo 位置, es decir, 110 |000, por lo que está en línea con 位置Hay dos condiciones .
En otras palabras, 零宽断言use caracteres para ir 匹配o decir 侦测, y luego guarde el comienzo de la cadena coincidente 位置, y luego continúe buscando,
lo que se llama 不消耗字符串solo porque el 零宽断言registro es 位置solo.
Comprender el 零宽断言significado 正向预查, 反向预查sino de uno 位置a la derecha (parte delantera) o izquierda (posterior) coincide sólo, 积极, 消极es decir,匹配O 不匹配significado.
Específicamente 正向预查, 反向预查ejemplos ver referencia en las "aplicaciones RegExp: búsqueda hacia delante, de búsqueda hacia atrás".
Referencia
Afirmación
RegExp Aplicación RegExp: mirar hacia adelante, mirar hacia atrás
Expresión regular de Python dos: capturar
la expresión regular de Python tres:
expresión regular codiciosa afirmación de ancho cero, expresión regular codiciosa y perezosa
prueba en línea
Python3.7 Doc-Lookahead Assertions
