1、准备环境
centos 7.4
hadoop hadoop-3.2.1 (http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz)
jdk 1.8.x
2、配置环境变量
命令:vi /etc/profile
#hadoop
export HADOOP_HOME=/opt/module/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
命令::wq
命令:source /etc/profile (执行此命令刷新配置文件)
3、新建目录
(分别执行)
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
4、修改配置 etc/hadoop
(1)、修改 core-site.xml
在<configuration>节点内加入配置:
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://node180:9000</value>
</property>
(2)、修改 hdfs-site.xml
在<configuration>节点内加入配置:
<property>
<!-- 主节点地址 -->
<name>dfs.namenode.http-address</name>
<value>node180:50070</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
(3)、修改 mapred-site.xml
在<configuration>节点内加入配置:
<!-- 配置mapReduce在Yarn上运行(默认本地运行) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.2.1</value>
</property>
(4)、修改 yarn-site.xml
在<configuration>节点内加入配置:
<!-- Site specific YARN configuration properties -->
<property>
<description>指定YARN的老大(ResourceManager)的地址</description>
<name>yarn.resourcemanager.hostname</name>
<value>node180</value>
</property>
<!-- NodeManager上运行的附属服务。需要配置成mapreduce_shfffle,才可运行MapReduce程序默认值 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--
<property>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
</property>
-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
(5)、workers文件
改为:
node180
node181
node182
(6)、修改 hadoop-env.sh、mapred-env.sh、yarn-env.sh
加入jdk 配置路径
# jdk
export JAVA_HOME="/opt/module/jdk1.8.0_161"
5、修改 sbin
(1)、修改 start-dfs.sh、stop-dfs.sh
首行加入
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(2)、修改 stop-dfs.sh、stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6、同步文件,各个节点
(1)同步hadoop文件夹
scp -r hadoop-3.2.1/ [email protected]:/opt/module
scp -r hadoop-3.2.1/ [email protected]:/opt/module
(2)同步数据文件夹
scp -r /root/hadoop/ [email protected]:/root
scp -r /root/hadoop/ [email protected]:/root
6、启动hadoop
(1)、在namenode上执行初始化
打开文件夹 :cd /opt/module/hadoop-3.2.1/bin
执行命令:./hadoop namenode -format
(2)、在namenode上执行启动
打开文件夹 :cd /opt/module/hadoop-3.2.1/sbin
执行命令:./start-all.sh
7、测试hadoop
https://blog.csdn.net/weixin_38763887/article/details/79157652
https://blog.csdn.net/s1078229131/article/details/93846369
打开:http://192.168.0.180:50070/

打开:http://192.168.0.180:8088/
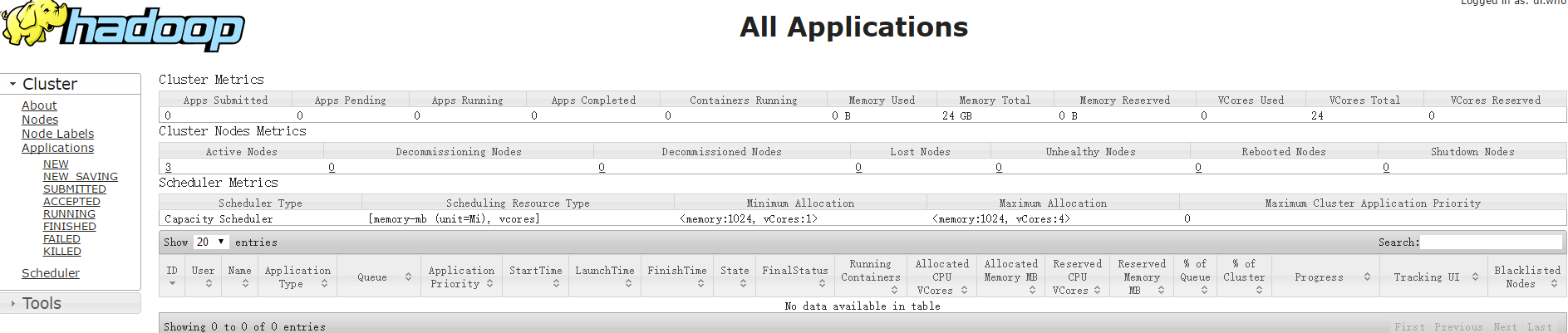
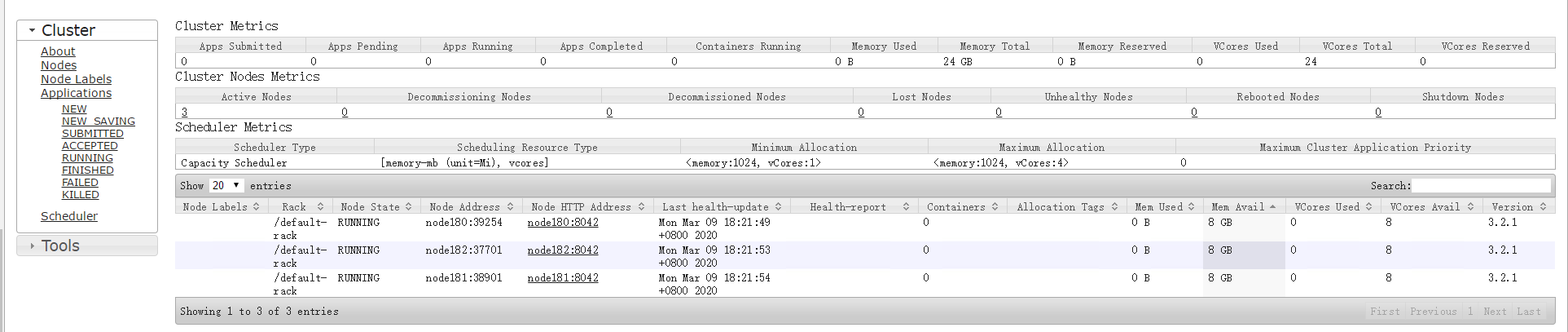
8、测试分析
创建文件夹:hdfs dfs -mkdir -p /user/root
上传分词文件到hadoop服务器:wc.txt
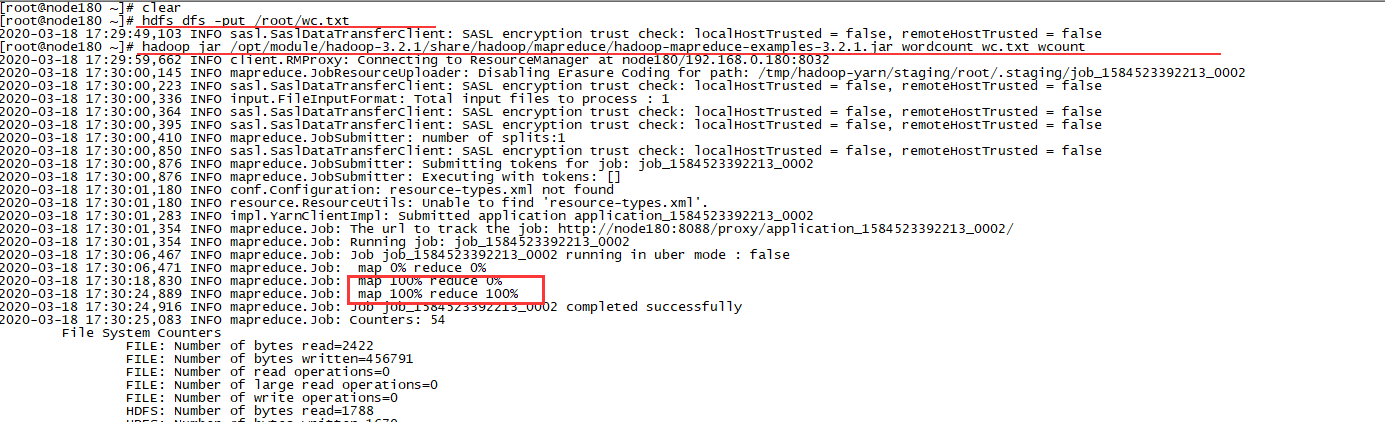
执行命令: hdfs dfs -put /root/wc.txt
执行分词命令:hadoop jar /opt/module/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount wc.txt wcount
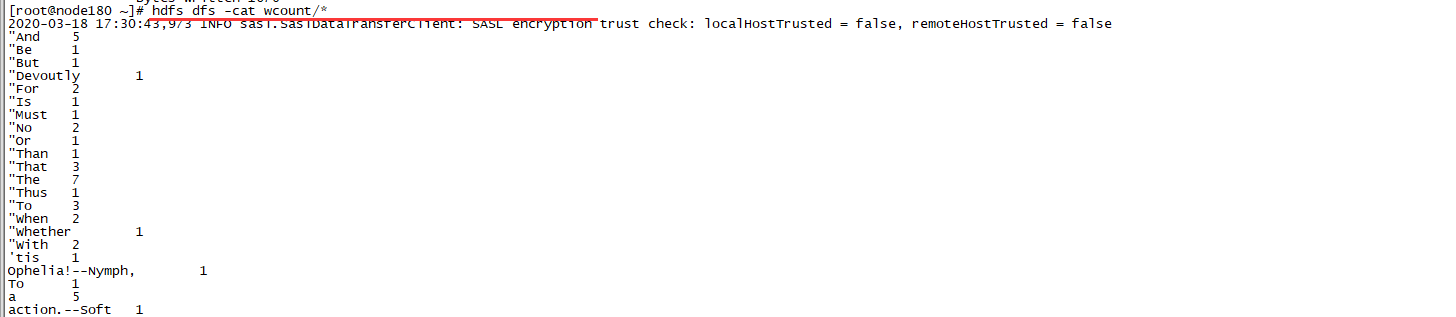
执行结果查看命令:hdfs dfs -cat wcount/*
效果如图: