妙趣横生大数据 Day2
Datawhale
大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data
三、Hadoop 分布式文件系统(HDFS)
1. 分布式文件系统
分布式文件系统:管理网络中跨多台计算机存储的文件系统;解决海量数据的高效存储。
文件采取“块”的方式存储,块是数据读取的基本单元。HDFS默认一个块大小为64MB(普通文件系统磁盘块为512字节),设计比较大的块的目的是为了最小化寻址开销;同时也要避免块过大影响MapReduce并行速度。
设计:“客户机/服务器”(Client/Server)
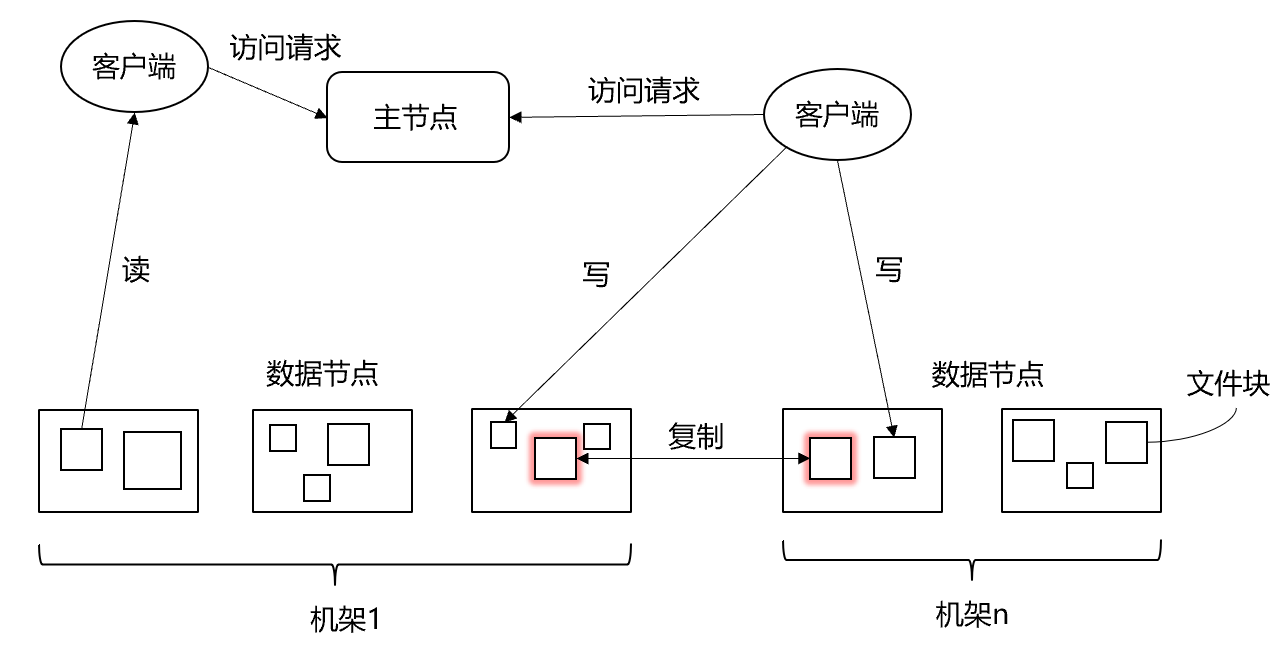
物理结构:
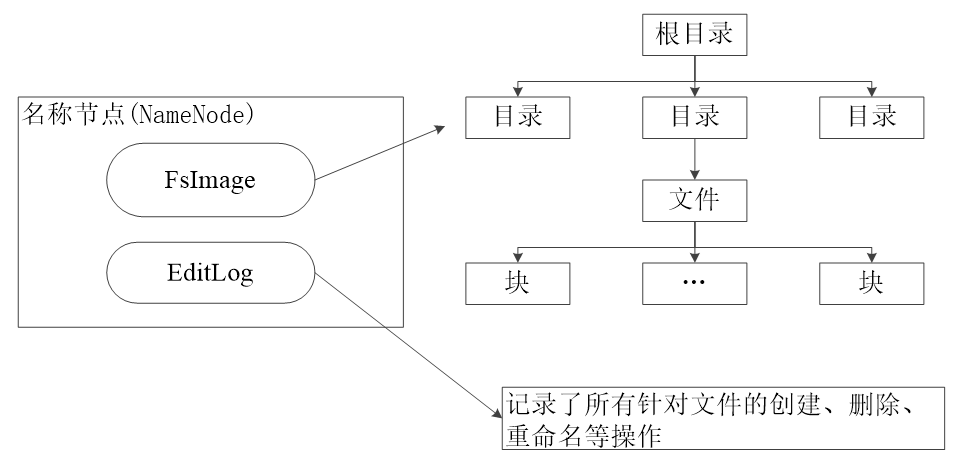
- 主节点(Master Node),名称节点(NameNode)
- 文件和目录的创建、删除和重命名
- 管理数据节点和文件快的映射关系
- 从节点(Worker Node),数据节点(DataNode)
- 数据的存储和读取
- 分布式文件系统采用多副本存储,以保证数据完整性
- 分布式文件系统为大规模数据存储设计(TB级文件)
2. HDFS 简介
HDFS(Hadoop Distribute File System)
- 是大数据领域中以分布式方式存储超大数据量文件的存储系统
- HDFS是Hadoop和其他组件的数据存储层
优点:
- 兼容廉价的硬件设备:实现在硬件故障的情况下也能保障数据的完整性
- 流数据读写:不支持随机读写的操作
- 大数据集:数据量一般在GB、TB以上的级别
- 简单的文件模型:一次写入、多次读取
- 强大的跨平台兼容性:采用
Java语言实现
局限性:
- 不适合低延迟数据访问:流式数据读取,较高延迟
- 无法高效存储大量小文件:影响元数据减少效率、增加Mpa任务线程管理开销、数据节点间跳跃频繁影响性能
- 不支持多用户写入及任意修改文件:一个文件只有一个写入者,只允许对文件追加操作
3. HDFS 体系结构
主从(Master/Slave)结构模型
一个HDFS集群包括:
- 一个名称节点(NameNode)
- 若干个数据节点(DataNode)
- 周期性发送“心跳”信息,报告状态
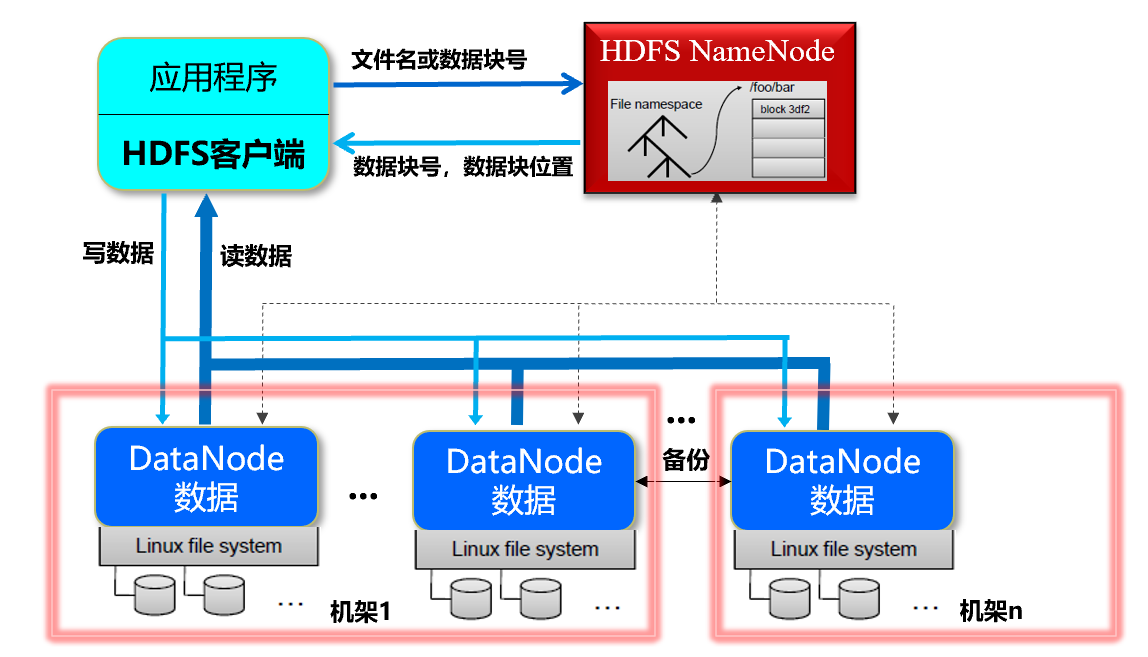
【说明】用户使用 HDFS,
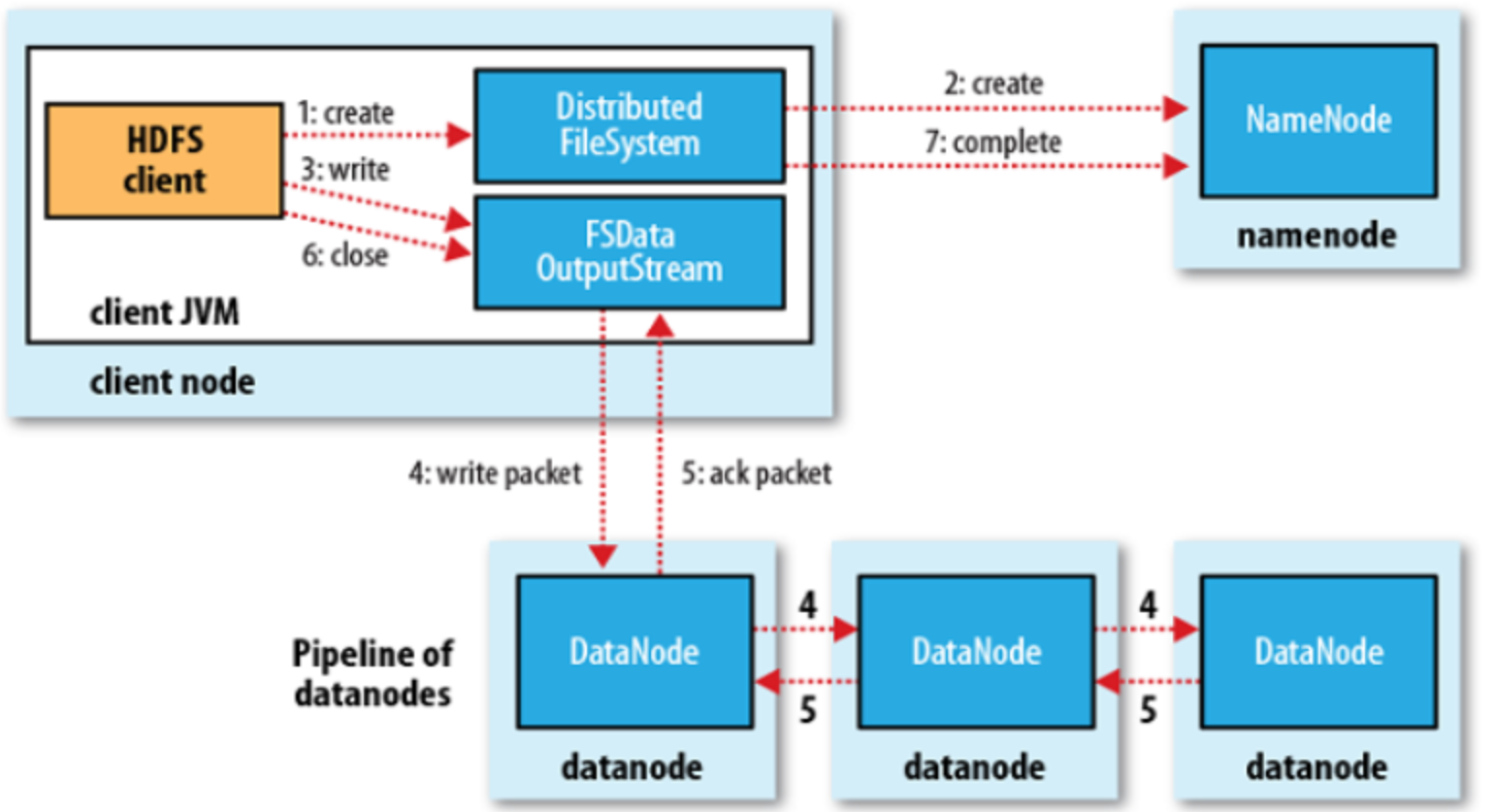
客户端存储时:
- 一个文件分为若干个数据块存储
- 每个数据块分布存储到若干个 DataNode 上
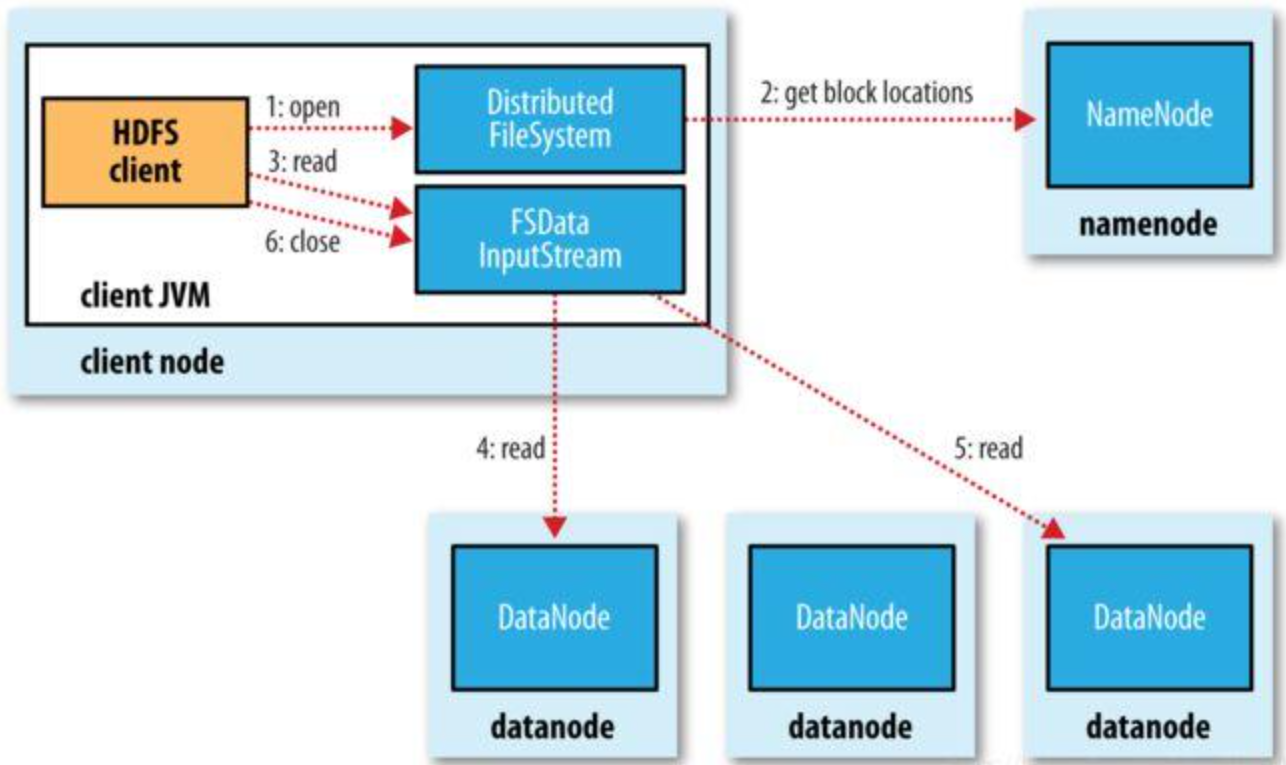
客户端读取时:
- 根据文件名从 NameNode 获取 数据块 和 数据块位置(DataNode)
- 访问 DataNode 获取数据
【优点】提高了数据访问速度,读取一个文件时从不同 DataNode 上并发访问
4. HDFS存储原理
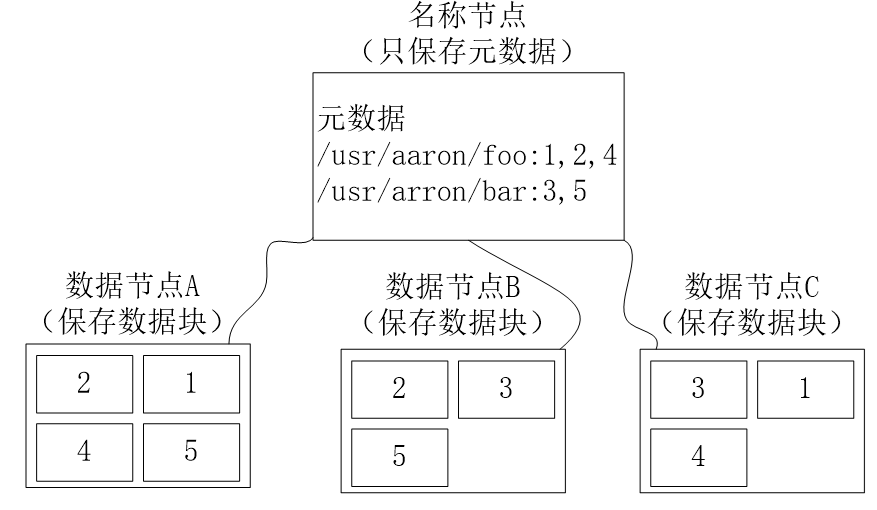
数据冗余存储
多副本方式,一个数据块的多个副本被分布到不同的数据节点上
- 加快数据传输速度
- 容易检出数据错误
- 保证数据的可靠性
数据存储策略
-
数据存储
-
HDFS采用了以 **机架(Rack)**为基础的数据存放策略,一个HDFS集群通常包含多个机架
- 不同机架之间的数据通信需要经过交换机或路由器
- 同一机架的不同机器之间数据通信不需要交换机或路由器(通信带宽比不同机架间通信带宽大)
-
HDFS 默认每个数据节点都是在不同机架上
-
缺点:写入数据的时候不能充分利用同一机架内部机器之间的带宽
-
优点:1. 很高的数据可靠性
2. 多机架并行读取数据,提高数据读取速度
3. 更容易实现系统内部负载均衡和错误纠正
-
-
HDFS默认的冗余复制因子是 3
- 每一个文件会被同时保存到 3 个地方
- 两份副本放在同一个机架的不同机器上面
- 第三个副本放在不同机架的机器上面
- 每一个文件会被同时保存到 3 个地方
-
-
数据读取
- HDFS提供了一个确定DataNode所属机架 ID 的 API,读取时就近读取
-
数据复制
- 流水线复制(第一个DataNode写入数据后,会根据列表中DataNode将数据和列表传给第二个DataNode,以此类推)
数据错误与恢复
-
NameNode 出错
- NameNode 元数据信息同步存储到其他文件系统
- 第二名称节点
-
DataNode 出错
- NameNode 没收到 DataNode 的‘心跳’信息,便定义为‘宕机’,数据标记为不可读,取消 I/O 请求
- 名称节点检查发现某个数据的副本数量小于冗余因子时,启动数据冗余复制生成新的副本
-
数据出错
- 网络传输和磁盘错误
md5和sha1校验、信息文件校验
5. HDFS数据读写过程
读写过程
翻译经典 HDFS 原理讲解漫画 之一----系统构成和写数据过程_笑寒x的博客-CSDN博客
HDFS故障类型和其检测方法
- 读写故障的处理
- 读:从其他备份的节点读取(NameNode会返回数据块存在的所有DataNode)
- 写:没有收到DataNode接受数据块的应答信号,调整通道跳过这个节点
翻译经典 HDFS 原理讲解漫画 之二----读数据和容错_笑寒x的博客-CSDN博客
-
DataNode故障处理
-
NameNode 表
- 数据块列表:数据块N —— 存储在 DN1, DN2, DN3
- DataNode列表:DATANODE 1 —— 存储数据块1,…,数据块N
-
持续更新这两个表
-
数据未充分备份会启动DataNode备份(前提是HDFS至少存在一个备份)
-
-
副本布局策略
- 第一个:就近
- 后续:不同机架(每个机架最多存储两份副本)
翻译经典 HDFS 原理讲解漫画 之三—容错和副本布局策略_笑寒x的博客-CSDN博客
HDFS编程实验
1. 本地和集群文件间操作
# 拷贝目录到集群
hadoop fs -put <local dir> <hdfs dir>
# 拷贝文件
hadoop fs -put <local file> <hdfs dir>
# 拷贝到本地
hadoop fs -get < hdfs file or dir > < local file or dir>
# 拷贝并移除
hadoop fs -moveFromLocal <local src> <hdfs dst>


2. 基本文件操作
# 查看
hadoop fs -ls / # -R: 包含子目录下文件
# 删除
hadoop fs -rm -r <hdfs dir> ...
hadoop fs -rm <hdfs file> ...
# 创建
hadoop fs -mkdir <hdfs path>
# 复制
hadoop fs -cp <hdfs file or dir>... <hdfs dir>
# 移动
hadoop fs -mv <hdfs file or dir>... <hdfs dir>
# 统计路径下的目录个数,文件个数,文件总计大小
hadoop fs -count <hdfs path>
#显示文件夹和文件的大小
hadoop fs -du <hdsf path>
# 查看文件
hadoop fs -cat /demo.txt
hadoop fs -tail -f /demo.txt
# 更改权限
hadoop fs -chown user:group /datawhale
hadoop fs -chmod 777 /datawhale
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ObVAZO1S-1676724750207)(HDFS/image-20230218171901366.png)]](https://img-blog.csdnimg.cn/683538375ed349de99e8ece10c41820a.png#pic_center)
# 本地文件内容追加到hdfs文件系统中的文本文件
hadoop fs -appendToFile <local file> <hdfs file>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H9cJuM6m-1676724750207)(HDFS/image-20230218202538200.png)]](https://img-blog.csdnimg.cn/2cf7535a6b5c45d8804a9e97da5cb307.png#pic_center)
这里遇到一个错误:Failed to APPEND_FILE /p1 for DFSClient_NONMAPREDUCE_985284284_1 on 192.168.137.101 because lease recovery is in progress. Try again later.
解决:hdfs dfs -appendToFile error 问题解决_故事の尾音的博客-CSDN博客_hdfs appendtofile
# 修改 hdfs-stie.xml 文件
<!-- appendToFile追加 -->
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
<value>true</value>
</property>
3. Hadoop 系统操作
# 改变文件在hdfs文件系统中的副本个数
hadoop fs -setrep -R 3 <hdfs path>
# 查看对应路径的状态信息
hdoop fs -stat [format] < hdfs path >
# %b:文件大小
# %o:Block大小
# %n:文件名
# %r:副本个数
# %y:最后一次修改日期和时间
# 手动启动内部的均衡过程(DataNode 数据保存不均衡)
hadoop balancer # 或 hdfs balancer
# 管理员通过 dfsadmin 管理HDFS
hdfs dfsadmin -help
hdfs dfsadmin -report
hdfs dfsadmin -safemode <enter | leave | get | wait>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WPScNjvH-1676724750207)(HDFS/image-20230218204809616.png)]](https://img-blog.csdnimg.cn/b94e06de44f84f5c9fa6ddc7d1cd09a5.png#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IjuanMXa-1676724750208)(HDFS/image-20230218205017836.png)]](https://img-blog.csdnimg.cn/609cfeaf796446e9aa9f5d7eb0f3afb6.png#pic_center)
Datawhale
大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data