一、HDFS是什么
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上,具有高容错、高可靠性、高可扩展性、高吞吐率等特征,为超大数据集的应用处理带来了很多便利。HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入或者任意修改文件的场景。
- 分布式计算(Distributed computing)是一种把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算,在上传运算结果后,将结果统一合并得出数据结论的科学。
- 分布式文件系统(Distributed File System)是用来管理网络中跨多台计算机存储的文件系统。
- 流数据模式访问:HDFS采用 “一次写入,多次读取” 的高效的访问模式。数据集通常是由数据源生成或者从数据源复制而来,接着长时间在此数据集上进行各类分析,每次分析都涉及该数据集的大部分或者是全部,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更为重要。这里书上讲的比较晦涩,简单说明下。流式数据访问是来了一点数据就进行处理(举个例子,边下边播),而与之对应的非流式数据访问就是等数据全部就绪后,在进行处理(举个例子,下完在播)。
- 低时间延迟的数据访问:要求低时间延迟数据访问的应用,例如几十毫秒范围,不适合在HDFS上运行。记住,HDFS是为高数据吞吐量应用优化的,这可能会导致时间延迟提高。目前,对于低延迟的访问需求,HBase是更好的选择。
- 大量的小文件:小文件通常指文件大小要比HDFS块(Block)大小还要小很多的文件。如果存在大量小文件,则会对整个存储系统有一定影响:(1)由于namenode将文件系统的元数据存储在内存中,因此大量的小文件会耗尽namenode的内存,影响HDFS的文件存储量;(2)如果使用mapreduce处理小文件,则会增加map任务数量,增加寻址次数。
- 多用户写入,任意修改文件:HDFS中的文件写入只支持单个写入者,而且写操作总是以“只添加”方式在文件末尾写数据。它不支持多个写入者的操作,也不支持在文件的任意位置进行修改。
二、HDFS相关概念解析
- Block(块):在操作系统中,每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位(计算机存储术语: 扇区,磁盘块,页)。而HDFS同样也有块(Block)的概念,但是大得多,默认为128MB(可通过dfs.blocksize设置)。与单一磁盘上的文件系统相似,HDFS上的文件也被划分成块大小的多个分块(Chunk),作为独立的存储单元。但与面向单一磁盘的文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间。例如,一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128MB(扩展:HDFS中的block、packet、chunk)。注意:文件块越大,寻址时间越短,但磁盘传输时间越长;文件块越小,寻址时间越长,但磁盘传输时间越短。
- Namenode(管理节点):用来管理文件系统的命名空间(namespace),它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件(FSImage)和编辑日志文件(Editlog)。namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。
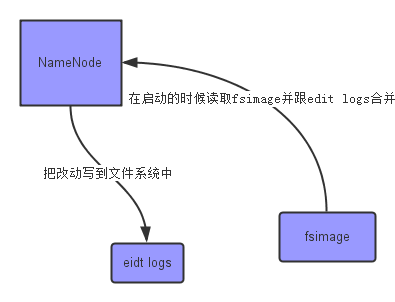
- FSImage(命名空间镜像文件):FSImage保存了最新的元数据检查点,在HDFS启动时会加载FSImage的信息,包含了整个HDFS文件系统的所有目录和文件的信息。 对于文件来说这包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。fsimage文件,一般以
fsimage_为前缀进行存储。 - Editlogs(编辑日志文件):Editlogs主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到Editlogs中。edit logs文件,一般以
edits_为前缀进行存储。FSImage与Editlogs文件均存储在${dfs.namenode.name.dir}/current/路径下。 - Datanode(数据节点):是文件系统的工作节点,是实际存储数据的节点。它们根据需要存储并检索数据块(受客户端或namenode调度),并且定期向namenode发送它们所存储的块的列表。
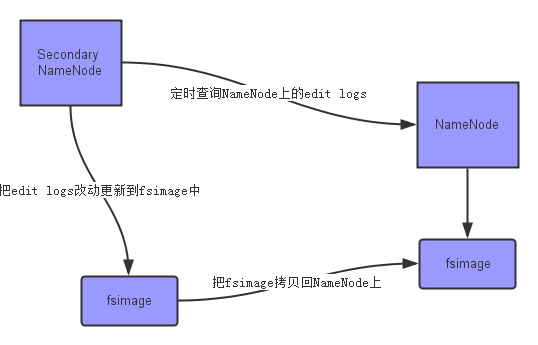
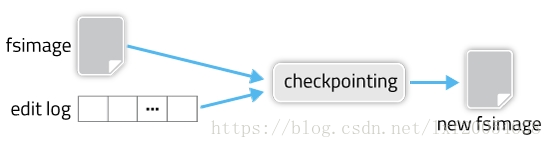
- Secondary Namenode(辅助节点/检查节点):因为NameNode是通过“FSImage + Editlogs”来存储元数据的,而edit logs只有在NameNode重启时,才会合并到fsimage中,从而得到一个文件系统的最新快照(检查点 checkpoint:将edit log文件合并到fsimage文件,该合并过程叫做checkpoint)。但是在生产环境中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大,这就会导致一些问题,比如必要时重启namenode(如namenode宕机重启)会花费许多时间(需要将Editlogs合并到FSImage中)。为了解决这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。这跟Windows的恢复点是非常像的,Windows的恢复点机制允许我们对OS进行快照,这样当系统发生问题时,我们能够回滚到最新的一次恢复点上。Secondary Namenode就是来帮助解决上述问题的,它会定时(默认1小时,可通过dfs.namenode.checkpoint.period修改;而dfs.namenode.checkpoint.txns,默认设置为1百万,是用来定义NameNode上的未经检查的事务的数量,这将强制紧急检查点,即使尚未达到检查点周期)从Namenode上获取FSImage和Edits并进行合并,然后再把最新的FSImage发送给namenode。
HDFS采用master/slave主从架构。一个HDFS集群由一个NameNode和一定数量的DataNode组成。

三、HDFS文件写入流程
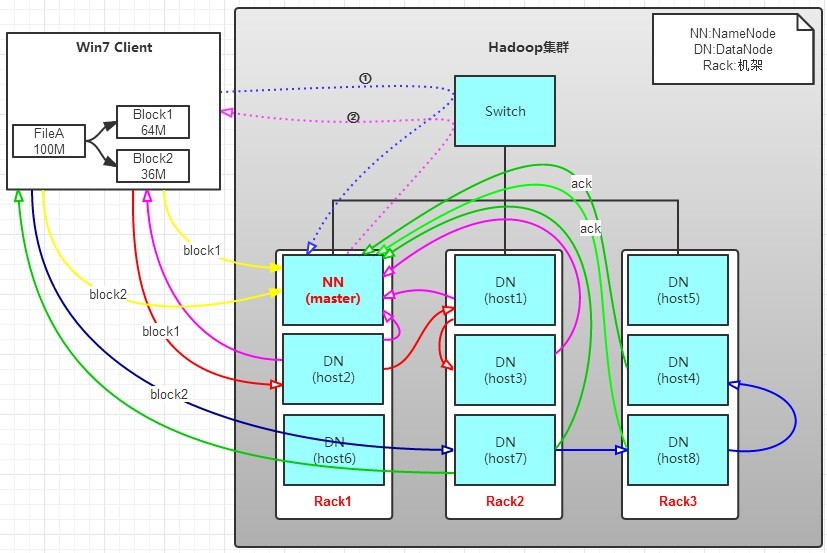
如上图所示,HDFS分布在三个机架上Rack1,Rack2,Rack3。
此时假设有一个文件FileA,大小为100MB,而HDFS的块大小为64MB。
a. Client向NameNode发送写数据请求,如上图蓝色虚线①
b. NameNode根据文件大小和文件块配置情况,将FileA按64MB分块成Block1和Block2;
c. NameNode节点根据DataNode的地址信息以及机架感知(rack-aware)策略返回可用的DataNode,如粉色虚线②。扩展:HDFS 机架感知

注:HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性、可用性和网络带宽的利用率。默认情况下,副本系数是3(可通过dfs.replication进行修改)。HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本存放在同一机架的另一个节点上,最后一个副本存放在不同机架的节点上。这种策略减少了机架间的数据传输,提高了写操作的效率。机架的错误远远比节点的错误少,所以这种策略并不会影响到数据的可靠性和可用性。与此同时,因为数据块只存放在两个(不是三个)不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。
因此,返回的DataNode信息如下:网络拓扑上的就近原则,如果都一样,则随机挑选一台DataNode
Block1: host2,host1,host3
Block2: host7,host8,host4
d. client向DataNode发送Block1;发送过程是以流式写入。 流式写入过程如下:
1>将64MB的Block1按64KB的package划分;
2>然后将第一个package发送给host2;
3>host2接收完后,将第一个package发送给host1,同时client向host2发送第二个package;
4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5>以此类推,如图红线实线所示,直到将block1发送完毕。
6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10>client向NameNode发送消息,说我写完了,如图黄色粗实线。这样就完毕了。
四、HDFS文件读取流程

读操作相对简单,如上图所示,FileA由block1和block2组成。此时client从DataNode读取FileA流程如下:
a. client向namenode发送读请求。
b. namenode查看Metadata元数据信息,返回FileA的block的位置。
Block1: host2,host1,host3
Block2: host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:优选读取本机架上的数据。
五、结语
HDFS的读写流程感觉这里写的还不是很透彻,在贴几个博客地址: