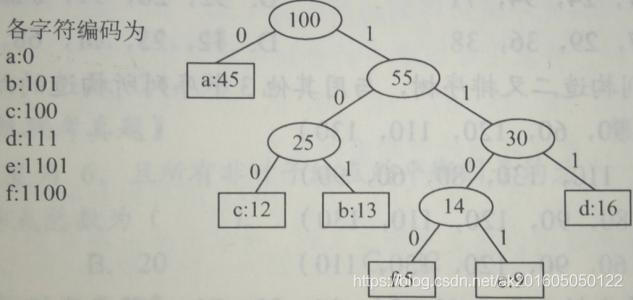
关于建树的关键点,都在下面代码的注释里了。
#include<iostream>
#include<algorithm>
#include<cstdio>
#include<cstring>
#include<cstdlib>
using namespace std;
const int inf=0x3f3f3f3f;
typedef struct
{
char data;
double weight;
int parent;
int lchild;
int rchild;
}HTNode;
typedef struct
{
char cd[101];
int start;
}HCode;
void CreatHT(HTNode ht[],int n0)
{
int lnode,rnode;
double min1,min2;
for(int i=0;i<2*n0-1;i++)
ht[i].parent=ht[i].lchild=ht[i].rchild=-1;
for(int i=n0;i<=2*n0-2;i++)//每一次大循环都是更新一个父节点
{
min1=min2=inf;
lnode=rnode=-1;
for(int k=0;k<=i-1;k++) //核心思想:一趟遍历,找出两个权值最小的点
if(ht[k].parent==-1) //在尚未构造二叉树的点中寻找
{
//根据下面的算法,必有min1<=min2。
if(ht[k].weight<min1) //如果当前点比已知最小的点还要小
{
min2=min1; rnode=lnode;//更新已知的第二小的点
min1=ht[k].weight; lnode=k;//更新已知的最小的点
}
else if(ht[k].weight<min2)//如果当前点大于等于已知最小的点但是小于已知的第二小的点
{
min2=ht[k].weight; rnode=k; //更新第二小的点
}
}
//更新父节点
ht[i].weight=ht[lnode].weight+ht[rnode].weight;
ht[i].rchild=rnode;ht[i].lchild=lnode;
ht[rnode].parent=i; ht[lnode].parent=i;
}
}
void CreatHCode(HTNode ht[],HCode hcd[],int n0)
{
HCode hc;
for(int i=0;i<n0;i++)
{
hc.start=n0;
int c=i;
int f=ht[i].parent;
while(f!=-1)
{
if(ht[f].lchild==c) //若当前点是父结点的左孩子,就添加0
hc.cd[hc.start--]='0';
else //若当前点是父结点的右孩子,就添加1
hc.cd[hc.start--]='1';
c=f;
f=ht[f].parent;
}
hc.start++;
hcd[i]=hc;
}
}
int main()
{
//想要学习的其他点:1怎么遍历这棵树?2 怎么对它进行编码?3 怎么对编码实现译码?
return 0;
}关于哈夫曼编码为什么得到的一定是前缀码:
- 同一层上的点,由于编码的长度相等且不同,所以任意两个同一层上的点(0001,0000)相互之间肯定不可能有前缀。
- 不同层上的点:由于我们建树得到的要编码的对象(a,b,c,d,e,f,g)都在叶子结点,所以编码的对象后面没有连着结点,所以对于同一分枝上的来说,没有前缀 码;对于其他分枝上的来说,由于路径不同,小层上的点(短的码)也不可能成为长的码的前缀。
- 结合图看: