目录
1.哈夫曼树的概念
路径概念
路径长度概念
节点的带权路径长度
树的带权路径长度
2.构建哈夫曼树的步骤
3.构建哈夫曼树的完整代码
4.哈夫曼编码
1.哈夫曼树的概念
在正式接触我们的哈夫曼树之前,先了解以下几个概念
什么是路径?
在一棵树中,从一个结点到另一个结点所经过的所有结点,被我们称为两个结点之间的路径
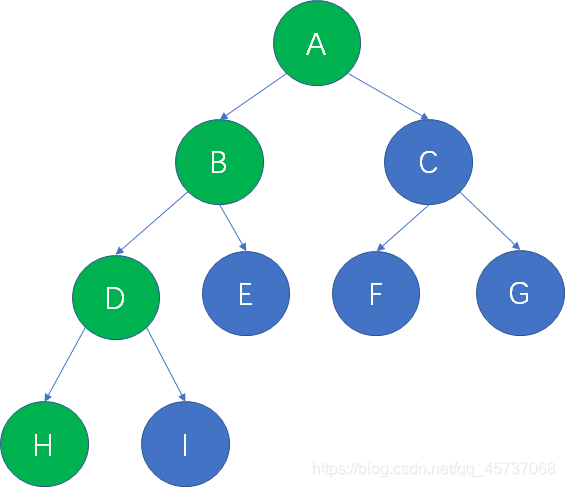
上面的二叉树当中,从根结点A到叶子结点H的路径,就是A,B,D,H
什么是路径长度?
在一棵树中,从一个结点到另一个结点所经过的“边”的数量,被我们称为两个结点之间的路径长度。
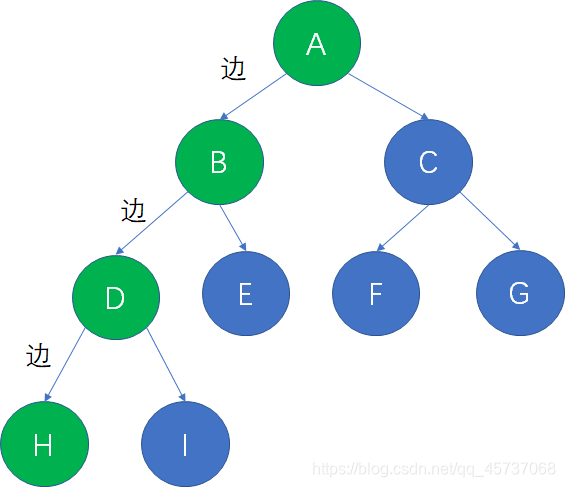
仍然用刚才的二叉树举例子,从根结点A到叶子结点H,共经过了3条边,因此路径长度是3
什么是 结点的带权路径长度?
树的每一个结点,都可以拥有自己的“权重”(Weight),权重在不同的算法当中可以起到不同的作用。结点的带权路径长度,是指树的根结点到该结点的路径长度,和该结点权重的乘积。
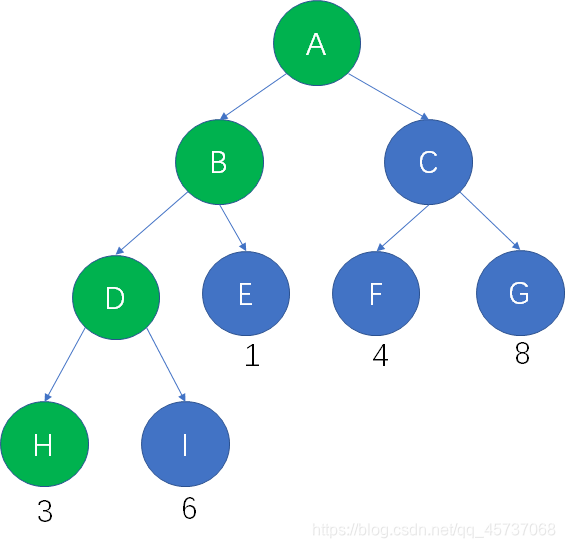
假设结点H的权重是3,从根结点到结点H的路径长度也是3,因此结点H的带权路径长度是 3 X 3 = 9
什么是 树的带权路径长度?
在一棵树中,所有叶子结点的带权路径长度之和,被称为树的带权路径长度,也被简称为WPL。
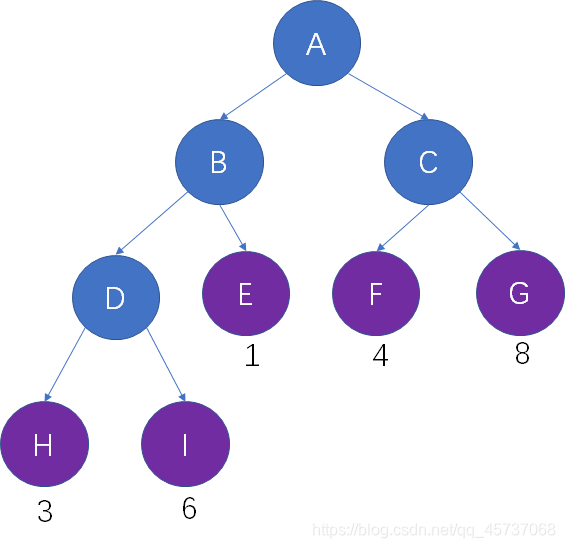
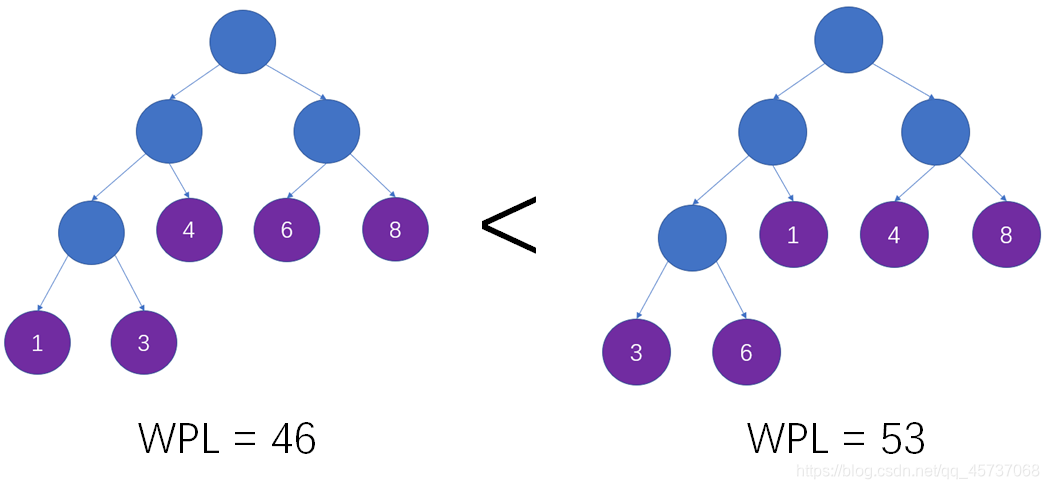
仍然以这颗二叉树为例,树的路径长度是 3X3 + 6X3 + 1X2 + 4X2 + 8X2 = 53
而哈夫曼树(Huffman Tree)是在叶子结点和权重确定的情况下,带权路径长度最小的二叉树,也被称为最优二叉树。
举个例子,给定权重分别为1,3,4,6,8的叶子结点,我们应当构建怎样的二叉树,才能保证其带权路径长度最小?
原则上,我们应该让权重小的叶子结点远离树根,权重大的叶子结点靠近树根。
下图左侧的这棵树就是一颗哈夫曼树,它的WPL是46,小于之前例子当中的53:
2.哈夫曼树的创建步骤
假设有6个叶子结点,权重依次是2,3,7,9,18,25,如何构建一颗哈夫曼树,也就是带权路径长度最小的树呢?

第一步:构建森林
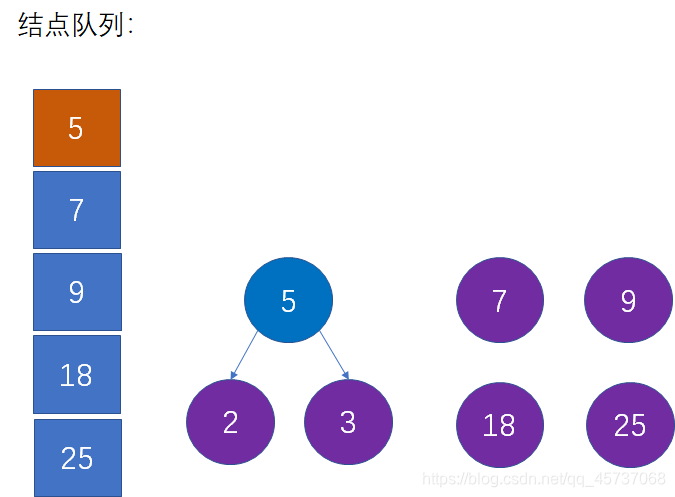
我们把每一个叶子结点,都当做树一颗独立的树(只有根结点的树),这样就形成了一个森林:

上图当中,右侧是叶子结点的森林,左侧是一个辅助队列,按照权值从小到大存储了所有叶子结点。至于辅助队列的作用,我们后续将会看到。
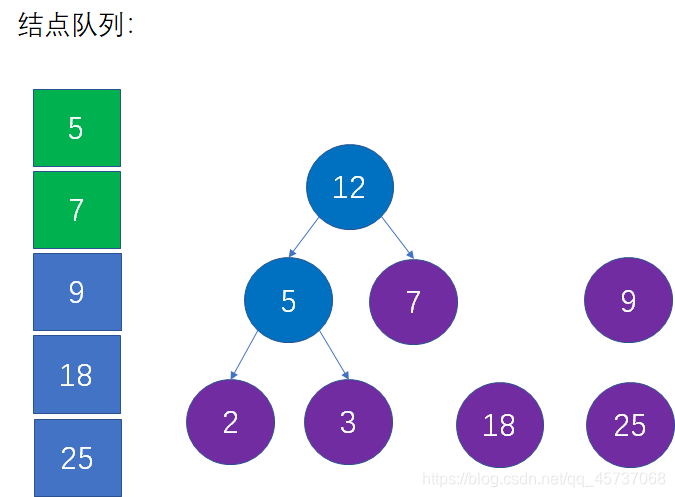
第二步:选择当前权值最小的两个结点,生成新的父结点
借助辅助队列,我们可以找到权值最小的结点2和3,并根据这两个结点生成一个新的父结点,父节点的权值是这两个结点权值之和:

第三步:从队列中移除上一步选择的两个最小结点,把新的父节点加入队列
也就是从队列中删除2和3,插入5,并且仍然保持队列的升序:
 然后重复第三步,直到所有结点组成一颗完整二叉树
然后重复第三步,直到所有结点组成一颗完整二叉树

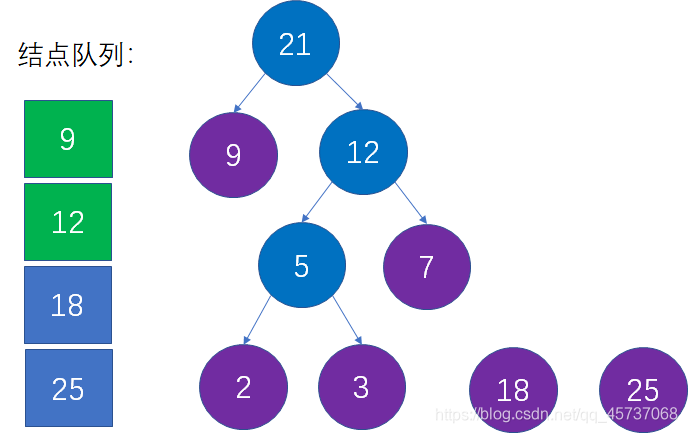


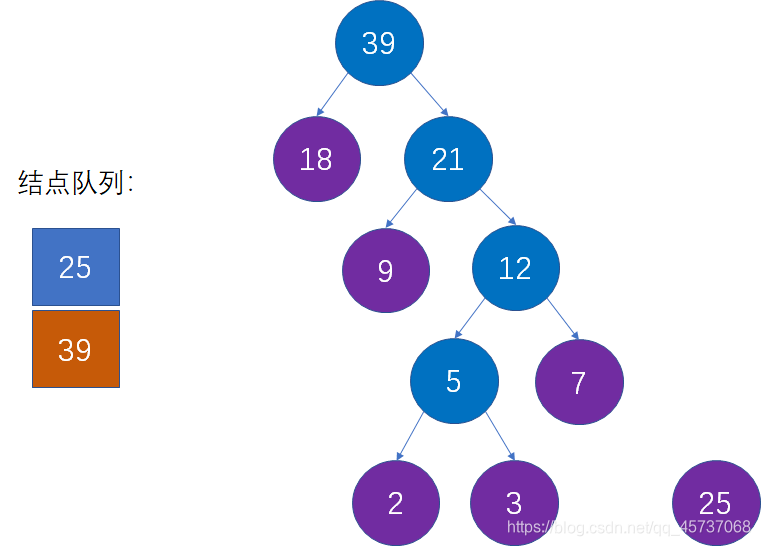
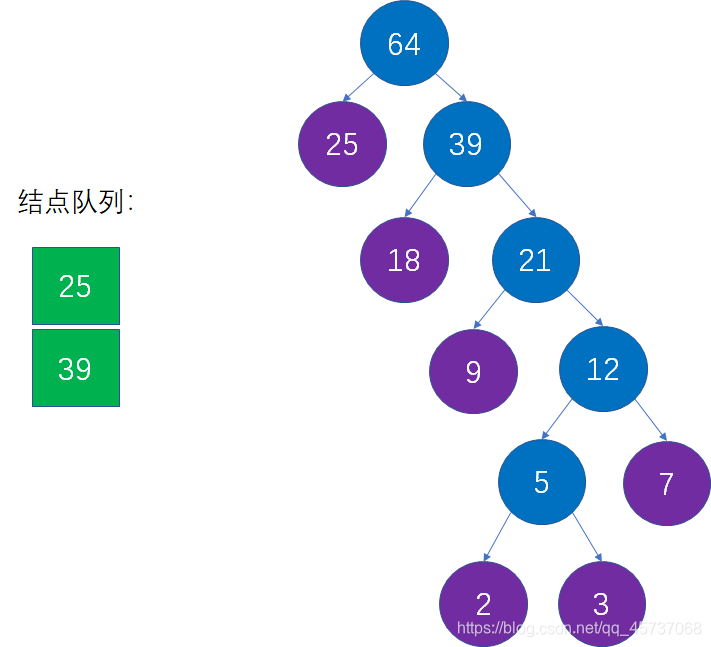
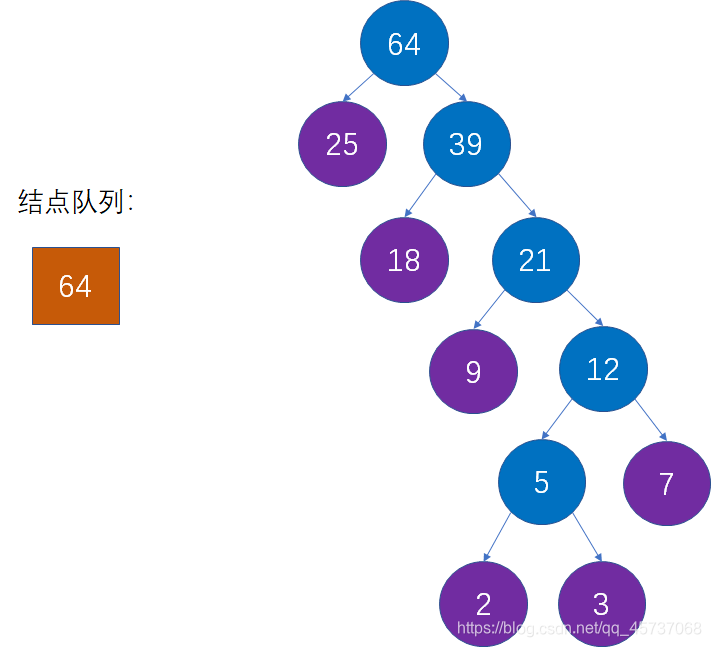
最后就得到了我们的哈夫曼树:
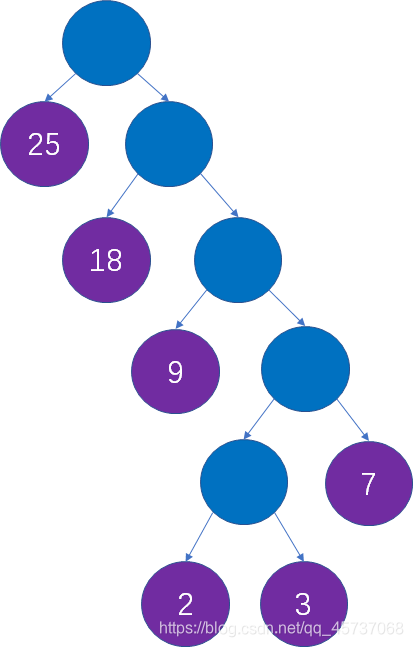
我们可以观察到哈夫曼树有一个特点,就是他没有度为1的结点,那么也就是说
一颗有n个叶子结点的的哈夫曼树共有2n-1个结点
下面给出推算过程:
设结点度为1的个数为n1
结点度为2的个数为n2
结点度为0的个数为n(叶子结点)
我们观察一颗二叉树的连接线数:可以得出是连接线的条数是结点数减一,还有一种求连接线多少的方法:由于一个结点的度有多少就会有多少条连接线即n2* 2+n1;
就有 n1+n2+n0-1=n2*2+n1;
就会有:n0=n2+1,由于没有度为1的结点所以n2+n0=总结点数,现在有n个叶子结点(n0=n)那么总结点=2n-1
3.构建哈夫曼树的完整代码
#include <cstdio>
#include <cstring>
using namespace std;
typedef struct {
int weight; // 结点权值?
int parent, lc, rc; // 双亲结点和左 右子节点
} HTNode, *HuffmanTree;
void Select(HuffmanTree &HT, int n, int &s1, int &s2)
{
int minum; // 定义一个临时变量保存最小值?
for(int i=1; i<=n; i++) // 以下是找到第一个最小值
{
if(HT[i].parent == 0)
{
minum = i;
break;
}
}
for(int i=1; i<=n; i++)
{
if(HT[i].parent == 0)
if(HT[i].weight < HT[minum].weight)
minum = i;
}
s1 = minum;
// 以下是找到第二个最小值,且与第一个不同
for(int i=1; i<=n; i++)
{
if(HT[i].parent == 0 && i != s1)
{
minum = i;
break;
}
}
for(int i=1; i<=n; i++)
{
if(HT[i].parent == 0 && i != s1)
if(HT[i].weight < HT[minum].weight)
minum = i;
}
s2 = minum;
}
void CreatHuff(HuffmanTree &HT, int *w, int n)
{
int m, s1, s2;
m = n * 2 - 1; // 总结点的个数
HT = new HTNode[m + 1]; // 分配空间
for(int i=1; i<=n; i++) // 1 - n 存放叶子结点,初始化
{
HT[i].weight = w[i];
HT[i].parent = 0;
HT[i].lc = 0;
HT[i].rc = 0;
}
for(int i=n+1; i<=m; i++) // 非叶子结点的初始化
{
HT[i].weight = 0;
HT[i].parent = 0;
HT[i].lc = 0;
HT[i].rc = 0;
}
printf("\nthe HuffmanTree is: \n");
for(int i = n+1; i<=m; i++) // 创建非叶子节点,建哈夫曼树
{ // 在HT[1]~HT[i-1]的范围内选择两个parent为0且weight最小的两个结点,其序号分别赋值给 s1 s2
Select(HT, i-1, s1, s2);
HT[s1].parent = i; // 删除这两个结点
HT[s2].parent = i;
HT[i].lc = s1; // 生成新的树,左右子节点是 s1和s2
HT[i].rc = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight; // 新树的权�?
printf("%d (%d, %d)\n", HT[i].weight, HT[s1].weight, HT[s2].weight);
}
printf("\n");
}
int main()
{
HuffmanTree HT;
int *w, n, wei;
printf("input the number of node\n");
scanf("%d", &n);
w = new int[n+1];
printf("\ninput the %dth node of value\n", n);
for(int i=1; i<=n; i++)
{
scanf("%d", &wei);
w[i] = wei;
}
CreatHuff(HT, w, n);
return 0;
}
4.哈夫曼编码
可能有朋友会问,那么构建哈夫曼树有啥用。接下来讲的哈夫曼编码就是他的应用
比如我们有一段电报,内容为“BADCADFEED”,那么我们计算机要用二进制表示,然后传递这些内容我们按照下表的标准表示这些字母:
| A | B | C | D | E | F |
|---|---|---|---|---|---|
| 000 | 001 | 010 | 011 | 100 | 101 |
那么我们的内容就被翻译成001000011010000011101100100011。接收方可以按照三位一分来编码,那么当我们的电报内容特别长的时候,那么计算机翻译的编码也会特别长,那么我们可以对其进行压缩吗,当然可以。
假设我们的一整段电报中各字母的频率如下
| 字母 | 出现次数 |
|---|---|
| A | 27 |
| B | 8 |
| C | 15 |
| D | 15 |
| E | 30 |
| F | 5 |
那么我们可以用他们的权重来构建哈夫曼树如下:
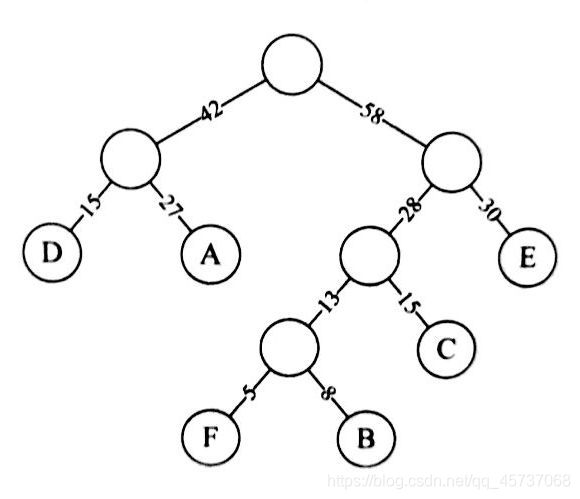
我们把左分支权值改为0,右分支权值改为1,那么该哈夫曼树就变成了
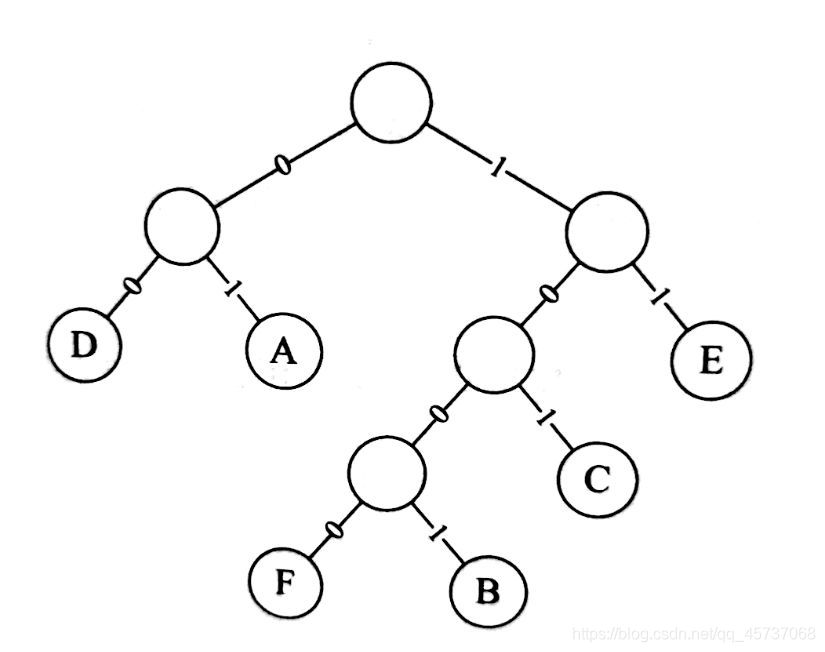
这样我们按照路径重新给每个字母分配编码
| A | B | C | D | E | F |
|---|---|---|---|---|---|
| 01 | 1001 | 101 | 00 | 11 | 1000 |
对于这一段“BADCADFEED”
新编码的二进制为:1001010010101001000111100
旧编码的二进制为:001000011010000011101100100011
压缩了17%左右,那么要是这一段电报非常长,那么传输数据节约的成本是很可观的
哈夫曼树的构建参考博客程序员小灰的哈夫曼树讲解