Tensorflow2.0下载与环境配置请参考:TF2.0环境配置
程序清单
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential, metrics # 导入TF子库
# 1.数据集准备
(x, y), (x_val, y_val) = datasets.mnist.load_data() # 加载数据集,返回的是两个元组,分别表示训练集和测试集
x = tf.convert_to_tensor(x, dtype=tf.float32)/255. # 转换为张量,并缩放到0~1
y = tf.convert_to_tensor(y, dtype=tf.int32) # 转换为张量(标签)
print(x.shape, y.shape)
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)) # 构建数据集对象
train_dataset = train_dataset.batch(32).repeat(10) # 设置批量训练的batch为32,要将训练集重复训练10遍
# 2.网络搭建
network = Sequential([
layers.Dense(256, activation='relu'), # 第一层
layers.Dense(128, activation='relu'), # 第二层
layers.Dense(10) # 输出层
])
network.build(input_shape=(None, 28*28)) # 输入
# network.summary()
# 3.模型训练(计算梯度,迭代更新网络参数)
optimizer = optimizers.SGD(lr=0.01) # 声明采用批量随机梯度下降方法,学习率=0.01
acc_meter = metrics.Accuracy()
for step, (x, y) in enumerate(train_dataset): # 一次输入batch组数据进行训练
with tf.GradientTape() as tape: # 构建梯度记录环境
x = tf.reshape(x, (-1, 28*28)) # 将输入拉直,[b,28,28]->[b,784]
out = network(x) # 输出[b, 10]
y_onehot = tf.one_hot(y, depth=10) # one-hot编码
loss = tf.square(out - y_onehot)
loss = tf.reduce_sum(loss)/32 # 定义均方差损失函数,注意此处的32对应为batch的大小
grads = tape.gradient(loss, network.trainable_variables) # 计算网络中各个参数的梯度
optimizer.apply_gradients(zip(grads, network.trainable_variables)) # 更新网络参数
acc_meter.update_state(tf.argmax(out, axis=1), y) # 比较预测值与标签,并计算精确度
if step % 200 == 0: # 每200个step,打印一次结果
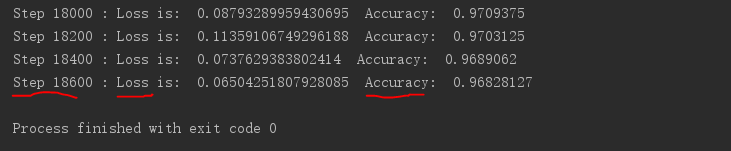
print('Step', step, ': Loss is: ', float(loss), ' Accuracy: ', acc_meter.result().numpy())
acc_meter.reset_states()
训练结果:
这里要注意的是:将mnist数据集中的标签y转换成one-hot编码
