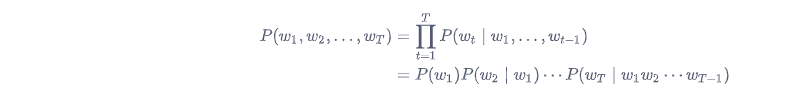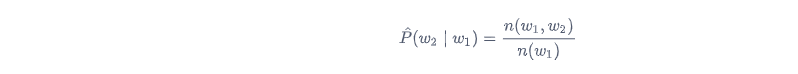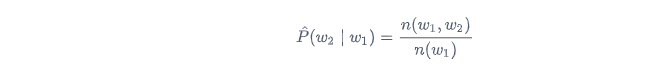一段自然语言文本可以看作是一个离散时间序列,给定一个长度为
T
T
T
w
1
,
w
2
,
…
,
w
T
w_1, w_2, \ldots, w_T
w 1 , w 2 , … , w T
P
(
w
1
,
w
2
,
…
,
w
T
)
.
P(w_1, w_2, \ldots, w_T).
P ( w 1 , w 2 , … , w T ) .
假设序列
w
1
,
w
2
,
…
,
w
T
w_1, w_2, \ldots, w_T
w 1 , w 2 , … , w T
例如,一段含有4个词的文本序列的概率
P
(
w
1
,
w
2
,
w
3
,
w
4
)
=
P
(
w
1
)
P
(
w
2
∣
w
1
)
P
(
w
3
∣
w
1
,
w
2
)
P
(
w
4
∣
w
1
,
w
2
,
w
3
)
.
P(w_1, w_2, w_3, w_4) = P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_1, w_2, w_3).
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 1 , w 2 , w 3 ) .
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如,
w
1
w_1
w 1
其中
n
(
w
1
)
n(w_1)
n ( w 1 )
w
1
w_1
w 1
n
n
n
类似的,给定
w
1
w_1
w 1
w
2
w_2
w 2
其中
n
(
w
1
,
w
2
)
n(w_1, w_2)
n ( w 1 , w 2 )
w
1
w_1
w 1
w
2
w_2
w 2
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。
n
n
n
n
n
n
n
n
n
n
n
n
n
=
1
n=1
n = 1
P
(
w
3
∣
w
1
,
w
2
)
=
P
(
w
3
∣
w
2
)
P(w_3 \mid w_1, w_2) = P(w_3 \mid w_2)
P ( w 3 ∣ w 1 , w 2 ) = P ( w 3 ∣ w 2 )
n
−
1
n-1
n − 1
P
(
w
1
,
w
2
,
…
,
w
T
)
=
∏
t
=
1
T
P
(
w
t
∣
w
t
−
(
n
−
1
)
,
…
,
w
t
−
1
)
.
P(w_1, w_2, \ldots, w_T) = \prod_{t=1}^T P(w_t \mid w_{t-(n-1)}, \ldots, w_{t-1}) .
P ( w 1 , w 2 , … , w T ) = t = 1 ∏ T P ( w t ∣ w t − ( n − 1 ) , … , w t − 1 ) .
以上也叫
n
n
n
n
n
n
n
−
1
n - 1
n − 1
n
=
2
n=2
n = 2
本节介绍循环神经网络,下图展示了如何基于循环神经网络实现语言模型。我们的目的是基于当前的输入与过去的输入序列,预测序列的下一个字符。循环神经网络引入一个隐藏变量
H
H
H
H
t
H_{t}
H t
H
H
H
t
t
t
H
t
H_{t}
H t
X
t
X_{t}
X t
H
t
−
1
H_{t-1}
H t − 1
H
t
H_{t}
H t
H
t
H_{t}
H t
我们先看循环神经网络的具体构造。假设
X
t
∈
R
n
×
d
\boldsymbol{X}_t \in \mathbb{R}^{n \times d}
X t ∈ R n × d
t
t
t
H
t
∈
R
n
×
h
\boldsymbol{H}_t \in \mathbb{R}^{n \times h}
H t ∈ R n × h
H
t
=
ϕ
(
X
t
W
x
h
+
H
t
−
1
W
h
h
+
b
h
)
.
\boldsymbol{H}_t = \phi(\boldsymbol{X}_t \boldsymbol{W}_{xh} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hh} + \boldsymbol{b}_h).
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) .
其中,
W
x
h
∈
R
d
×
h
\boldsymbol{W}_{xh} \in \mathbb{R}^{d \times h}
W x h ∈ R d × h
W
h
h
∈
R
h
×
h
\boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h}
W h h ∈ R h × h
b
h
∈
R
1
×
h
\boldsymbol{b}_{h} \in \mathbb{R}^{1 \times h}
b h ∈ R 1 × h
ϕ
\phi
ϕ
H
t
−
1
W
h
h
\boldsymbol{H}_{t-1} \boldsymbol{W}_{hh}
H t − 1 W h h
H
t
H_{t}
H t
H
t
H_{t}
H t
H
t
−
1
H_{t-1}
H t − 1
在时间步
t
t
t
O
t
=
H
t
W
h
q
+
b
q
.
\boldsymbol{O}_t = \boldsymbol{H}_t \boldsymbol{W}_{hq} + \boldsymbol{b}_q.
O t = H t W h q + b q .
其中
W
h
q
∈
R
h
×
q
\boldsymbol{W}_{hq} \in \mathbb{R}^{h \times q}
W h q ∈ R h × q
b
q
∈
R
1
×
q
\boldsymbol{b}_q \in \mathbb{R}^{1 \times q}
b q ∈ R 1 × q