注:cs224n
语言模型:一个用来预测下一个单词的系统模型
用公式可以表示为:
这里
是一个位于词汇表V={
}中的词。
一、最初用的语言模型被称为n-gram Langurage Models

n-gram model 引入HMM假设:
只依赖于前面的n-1个词
即:
用频率逼近概率得:
例:

n-gram langurage model 存在的问题


二、那么如何建立一个神经网络语言模型呢?
首先想到的当然是与n-gram langurage model类似的窗口模型。
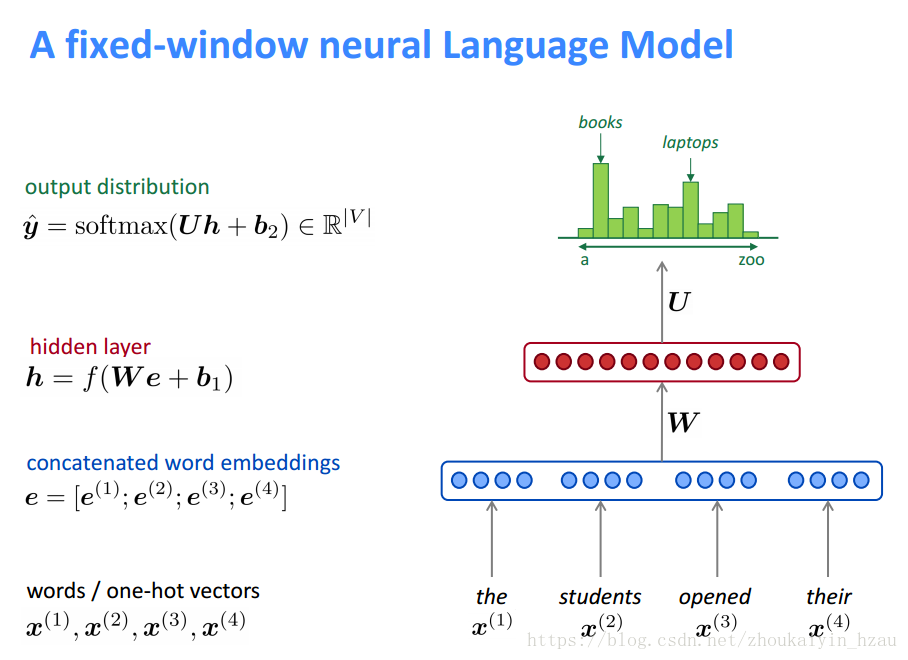
该模型是一个限定窗口长度的语言模型。相比于传统的n-gram langurage model 他的优势是:
一、不存在向量稀疏问题
二、模型复杂度为O(n)
而该模型得缺点在于
一、固定窗口往往太小
二、若增加窗口 W得维度将增加(w维度与窗口大小成正比)

三、引入循环神经网络
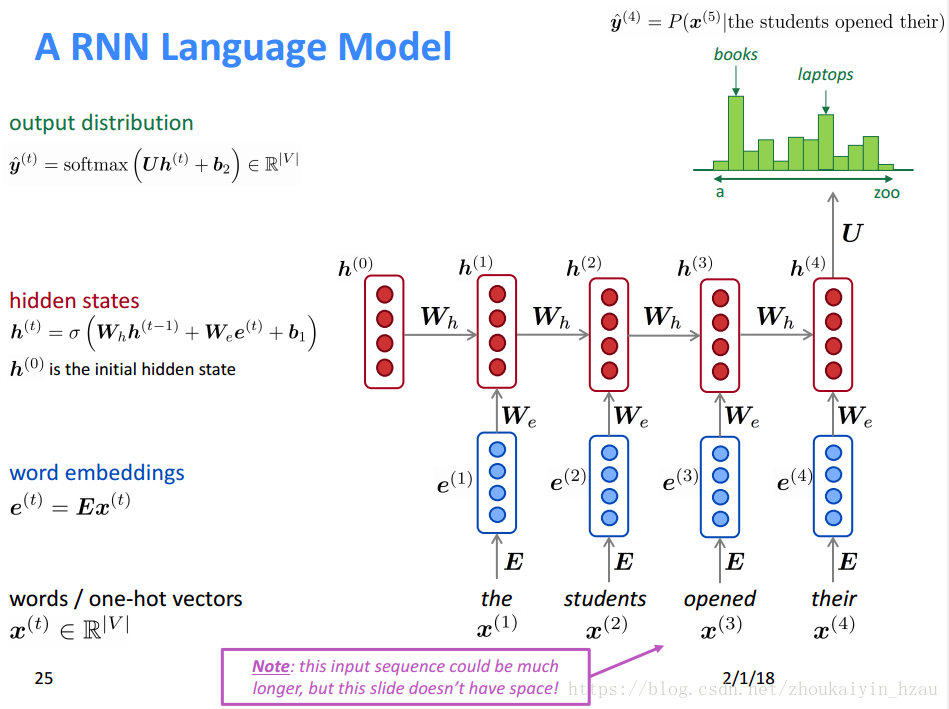
RNN的优缺点:

Training RNN langurage Model
1、将预料库中的序列输入RNN-LM计算每一个时刻输出结果的分布情况。
2、通常选用交叉熵来计算损失

对总的交叉熵去均值作为最终损失函数:

其模型表示为:

注:在整个corpus上计算交叉熵的复杂度太高,通常采用随机梯度下降来计算。即在一个batch上计算交叉熵。
Question: 对 的导数?
由链式法则:

因此:

这里原本是对 求导,但在求和的时候是对每一个时刻的w求导原因是:

六、评价语言模型
用perplexity评价语言模型

