前言
前不久,我用rvest包爬取了政府工作报告,通过jiebaR分词,并用wordcloud2进行了词云分析。点击查看 http://blog.csdn.net/wzgl__wh/article/details/72804687
今天,我们来用rvest包爬取猎聘网上的招聘信息。
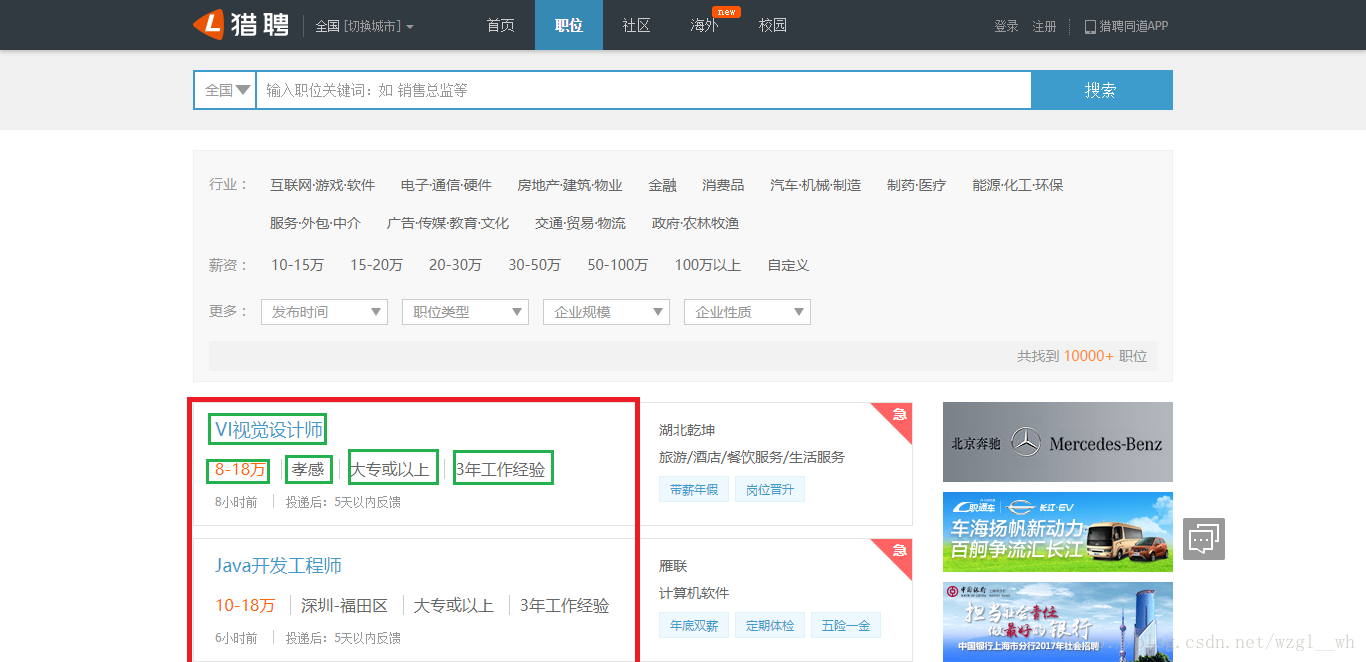
链接为 https://www.liepin.com/zhaopin/?init=1 。 打开的页面如上图,今天任务要爬取红色区域里面用绿色标记的那些信息,爬取完之后保存下来。
在开始之前,我先简单的介绍一下下面几个函数:
函数 |
作用 |
read_html() |
读取html文档 |
html_nodes() |
获得指定名称的网页元素、节点 |
html_text() |
获得指定名称的网页元素、节点文本 |
html_attrs() |
提取所有的属性名称及其内容 |
html_attr() |
提取指定的属性名称及其内容 |
html_tag() |
提取标签名称 |
html_table() |
解析网页数据表的数据到R的数据框中 |
html_session() |
利用cookie实现模拟登陆 |
guess_encoding() |
返回文档的详细编码 |
repair_encoding( |
用来修复html文档读入后的乱码问题 |
在写爬虫之前要对css和html有简单的了解才行,否侧就找不到节点。在这里给大家提供两个谷歌浏览器插件 SelectorGadget和 数据抓取分析工具,它们可以帮助我们很快分析出css。
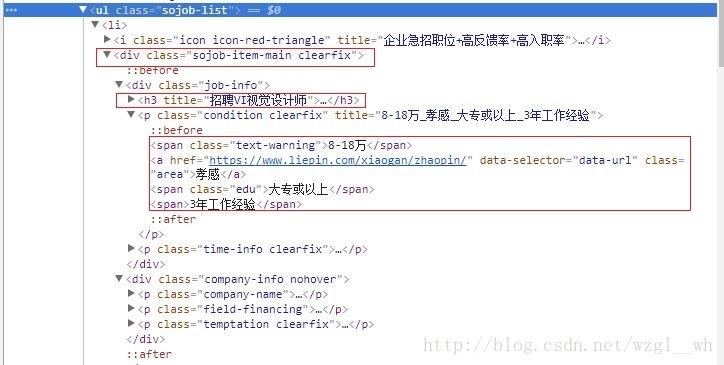
在这种图片中,我已经框出标签了。ul.sojob_list下的div.sojob-item-main clearfix下的div.job-info,里面h3的a里面,嵌套的比较多,我那张图中没有把h3打开,你们可以使一下。这需要注意几个点:
标签名称中间如何有空格可以把空格后面的单词忽略不计,如何 div.sojob-item-main clearfix就可以写成 div.sojob-item-main。 只要网页节点没有命名重复的其实节点也不用写这么具体,大家可以对比一下提取 职位 和 工作地点 代码中节点的区别。
html_nodes()函数中,先写父节点,再写子节点,中间用空格隔开,或者 > 隔开。如果节点是标题时,需要用“ , ”逗号与前面隔开。可以对比下面提取 职位 和 链接 的代码。
一. 爬取网页代码
library(rvest) url<-"https://www.liepin.com/zhaopin/?init=1" #我们都知道这些数据更新频率比较快,因此为防止网页数据变化造成后面数据不一致,可以先将网页数据保存在page变量中 page<-read_html(url)
二. 提取职位
position<-page%>%html_nodes('ul.sojob_list div.sojob-item-main div.job-info,h3 a')%>%html_text(trim =TRUE)
position #查看职位
position<- position[-41] #删除第41个
爬取的职位如下:

我们发些第41个不是一个有效职位,所以删掉。所以说这一页的职位有40个。
三.提取职位链接
我们都知道,每一个职位下面都有一个链接,打开这个链接就是这个职位的详细介绍。
link<- page %>% html_nodes('ul.sojob_list div.job-info,h3 a')%>%html_attrs()
#也可以写成'ul.sojob_list div.sojob-item-main div.job-info,h3 a
link[1] #读取数据,规定编码
position<-web %>% html_nodes("div.pages_content") %>% html_text()
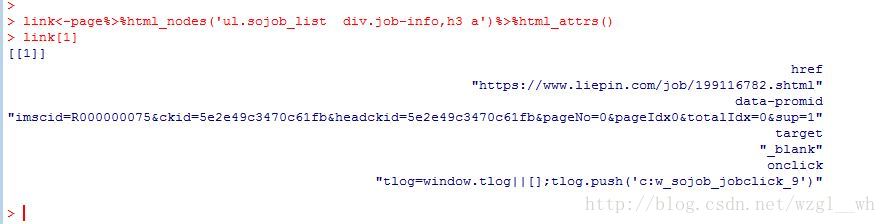
l ink其实就是一个list,查看link第一个时可以发现链接就是link的href。因此我用下面一个循环提取出来链接。
link1<-c(1:length(link)) #初始化一个和link长度相等的link1 for(i in 1:length(link)) link1[i]<-link[[i]][1] link1 #查看link1 link2<-link1[-41] #删除最后一行 link2 #查看link2 link<-link2 #将link2重新赋值给link

如上图,就是我们提取的链接。
四. 提取薪水
salary <- page %>% html_nodes('span.text-warning') %>% html_text()
salary

OK,薪资也提取出来了。
五. 提取工作地点
experience <- page %>% html_nodes('p.condition span') %>% html_text()
experience

六. 提取教育背景
edu<-page %>% html_nodes('span.edu') %>% html_text()
edu

七. 提取工作经验
experience <- page %>% html_nodes('p.condition span') %>% html_text()
experience

结果我们不但爬取了工作经验要求,也爬到了薪水,和学历。我们来看看下面这张截图,我只截取了前4个。
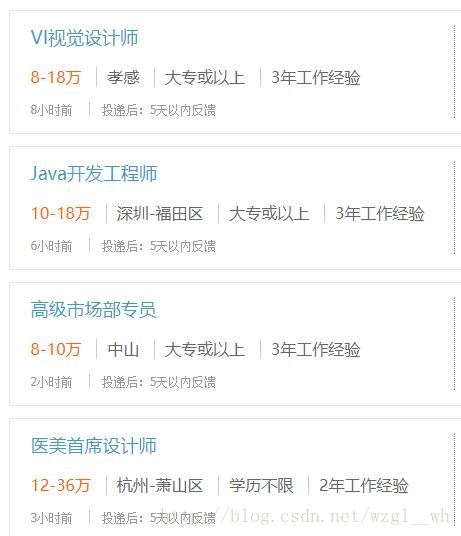
如果大家仔细观察的话,可以发现一个规律,experience的前三个是第一个职位的薪水,学历要求,和工作经验要求,第4个到6个是第二个职位的薪水,学历要求,和工作经验要求。依次可以类推。因此我们可以用一个双重循环来分别提取这三个内容。
dt<-matrix(,length(experience)/3,3) #定义一个数据框,报存数据,也是为了方便后面数据进行对比
colnames(dt)<-c("sal","ed","exp") #数据框列命名 第一个是薪水,第二个是学历,第三个是经验
for(n in 1:3) #n代表第n列
{
j<-1 #列数自加
i<-n #初值代表第一列的初值位置
while(i<=length(experience))
{
dt[j,n]=experience[i];
j<-j+1
i <- i+3
}
}

八. 数据合并
现在数据已经都获取完毕了,现在的任务就是把前面获取的全部信息汇总到一块。
Alldata<-matrix(,40,6) #定义一个40行,6列的矩阵
Alldata[,1]<-position
Alldata[,2]<-dt[,1]
Alldata[,3]<-dt[,2]
Alldata[,4]<-dt[,3]
Alldata[,5]<-place
Alldata[,6]<-link
colnames(Alldata)<-c("职位","薪水","学历","经验","工作地点","链接") #给列命名
head(Alldata) #查看Alldata数据前6行
write.csv(Alldata,file="Alldata.csv",quote=F,row.names = F) #保存csv文件中

保存到csv文件后为

总结
现在,职位链接我们也提取出来了,如何说想爬取职位的详细信息的话,那就不成问题了。如果你想爬取这个网页的数据,这些代码目前都还是可以用的,你可以去试试。 下次有时间了再来对这些数据进行可视化分析。
如果你想验证我爬取的数据对不对,或者想获取爬取的数据,请点击阅读原文,通过百度网盘分享下载获取的数据和网页截图。密码: fmt8

注:
原文链接:http://blog.csdn.net/wzgl__wh/article/details/74936761
作者:王亨
公众号:跟着菜鸟一起学R语言