R语言的理论学习也已经有一段时间了,数据分析的基础就是要获取数据,在如今的互联网时代,获取网络数据成为了数据分析师必不可少的随身技能,本篇就模仿R语言爬虫利器:rvest包+SelectorGadget抓取链家杭州二手房数据用rvest包爬取链家南京二手房的信息。
先上此次爬虫的源代码:
library(xml2)
library(rvest)
library(stringr)
library(dplyr)
i <- 1:100
house_inf <- data.frame()
#此处新建house_inf数据框很重要,如若不建立此数据框以下代码则只会爬取1页的信息
for (i in 1:100){
webpage <- read_html(str_c("https://nj.lianjia.com/ershoufang/pg",i),encoding="UTF-8")
#链家的编码格式为"UTF-8",如若爬取其他网站,可能有所变更
house_name_html <- html_nodes(webpage,".houseInfo a")
#爬取房屋名称
house_name <- html_text(house_name_html)
#将房屋数据转化为文本
price_html <- html_nodes(webpage,".unitPrice span")
price <- html_text(price_html)
house_basic_html <- html_nodes(webpage,".houseInfo")
house_basic <- html_text(house_basic_html)
house_basic <- str_replace_all(house_basic," ","")
#消除房屋基础信息中的空格
total_price_html <- html_nodes(webpage,".totalPrice span")
total_price <- html_text(total_price_html)
total_price <- as.numeric(total_price)
#将总价转化为数字
house <- data.frame(house_name,price,total_price,position,house_basic)
house_inf <- rbind(house_inf,house)
#将每页爬取的house数据框进行合并,从而进行累积
}
write.csv(house_inf,file="nanjinershoufang.csv")
个人写爬虫代码的一个心得就是先爬取1页的信息,将每个字段的信息处理好,然后再进行推广。比如爬取房屋基础信息时,通过head(house_basic)可以发现房屋信息中有空格存在,应该进行消除:

爬取的初始信息如下:

鉴于目前我处理字段的能力还不熟练,故而转用Excel进行了进一步的数据处理,结果如下:
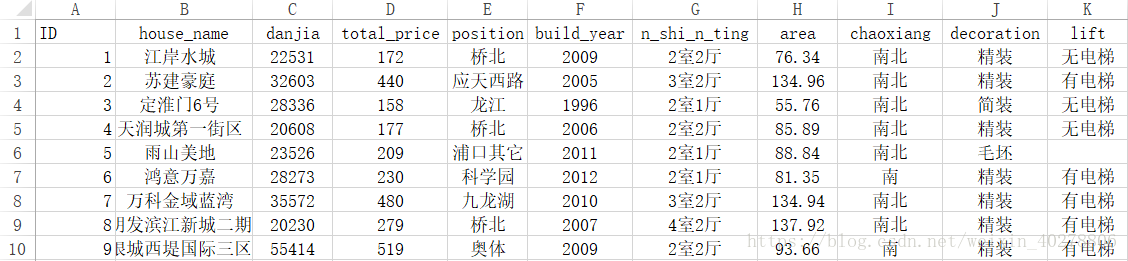
之后,利用Tableau软件进行了简单的可视化呈现,仪表板截图如下:
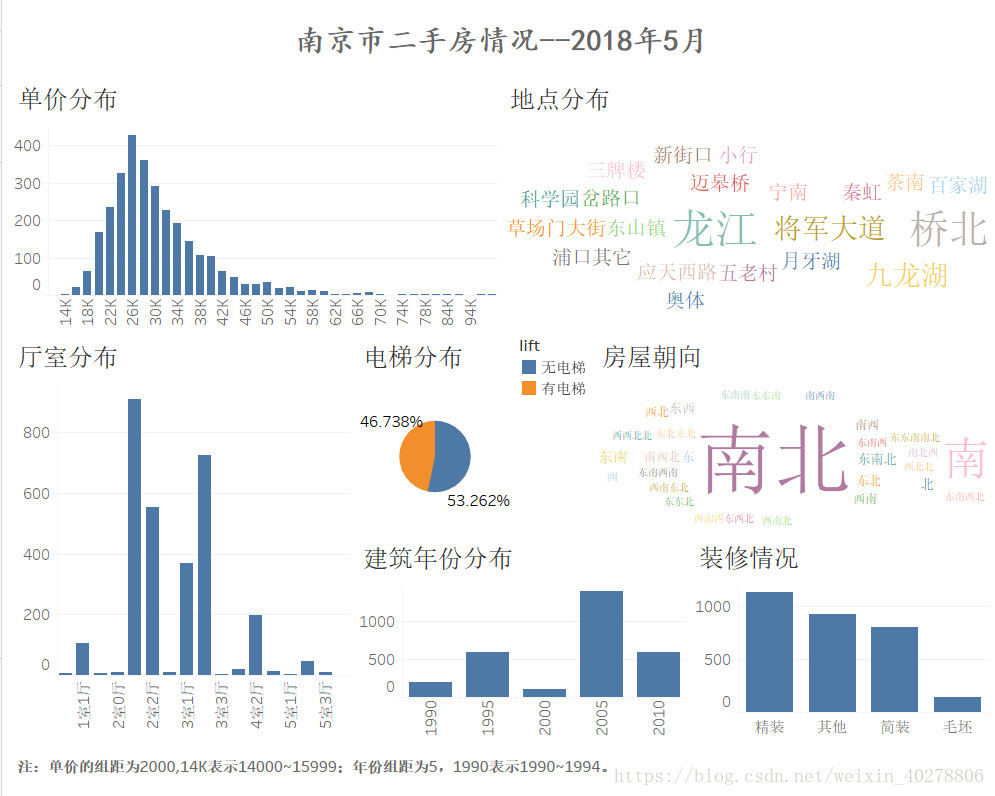
以上就是此次爬虫的始终,如有不当或改进之处,还请各位看官不吝赐教。
扫描二维码关注公众号,回复:
1129633 查看本文章

链接:源代码 密码:oqh4
链接:tableau文件 密码:s97k