数据预处理包含:数据盘点-数据可视化分析-空值填充-数据编码
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
import time
import pandas as pd
import numpy as np
1.获取数据
train_df = pd.read_csv(‘…/input/train.csv’)
2.数据概览
df.info()
df.describe()
df.head()
3.数据可视化
(1)df[‘label’].value_counts().plot.pie(autopct=’%1.1f%%’)
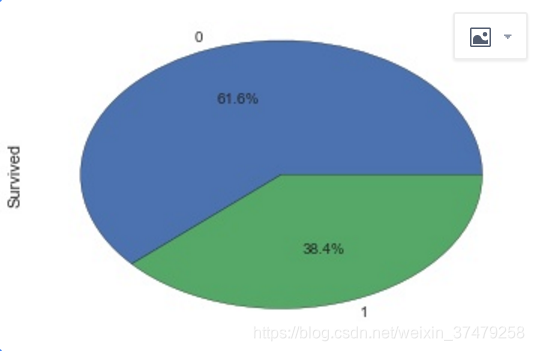
(2)df.groupby([‘X1’,‘Label’])[‘Label’].count()
X1 Y
female 0 81
1 233
male 0 468
1 109
(3)df[[‘X1’,‘Y’]].groupby([‘X1’]).mean().plot.bar()
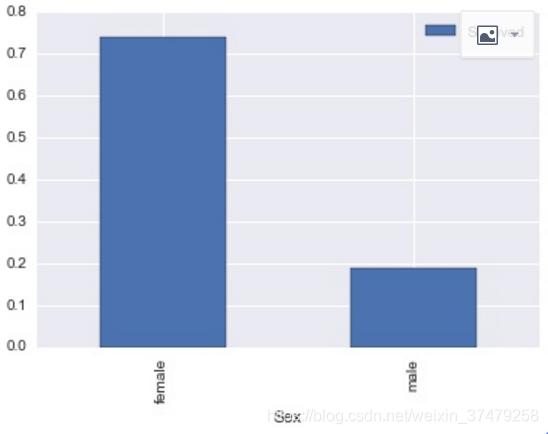
(4)df[[‘X1’,‘Y’]].groupby([‘X1’]).mean().plot.bar(color=[‘r’,‘g’,‘b’])

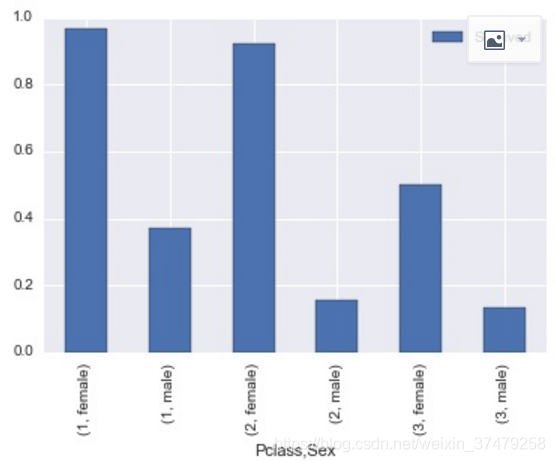
(5)df[[‘X1’,‘X2’,‘Y’]].groupby([‘X1’,‘X2’]).mean().plot.bar()
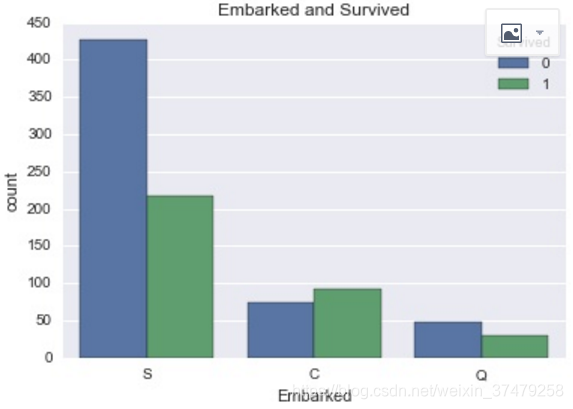
(6)sns.countplot(‘X1’,hue=‘Y’,data=train_data)
plt.title(‘Embarked and Survived’)
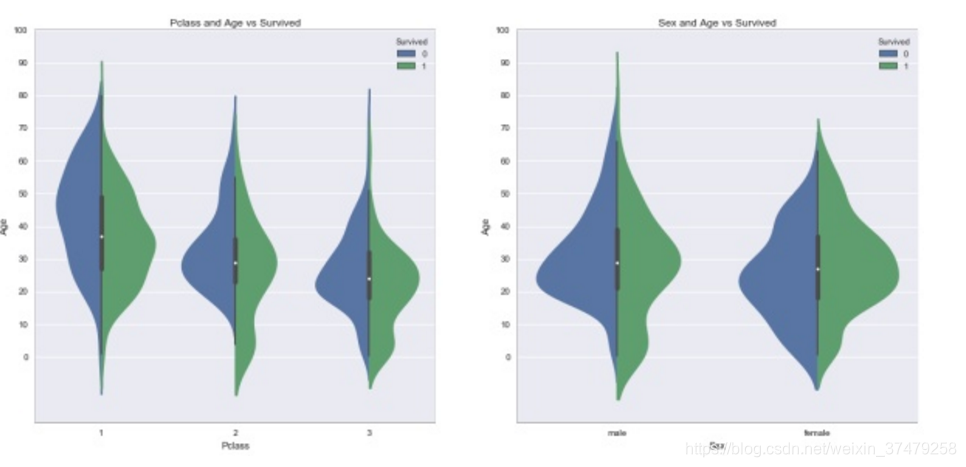
(7)
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot(“Pclass”,“Age”, hue=“Survived”, data=train_data,split=True,ax=ax[0])
ax[0].set_title(‘Pclass and Age vs Survived’)
ax[0].set_yticks(range(0,110,10))
sns.violinplot(“Sex”,“Age”, hue=“Survived”, data=train_data,split=True,ax=ax[1])
ax[1].set_title(‘Sex and Age vs Survived’)
ax[1].set_yticks(range(0,110,10))
plt.show()
4.空值填充
if df[‘X1’].isnull().sum() != 0:
df[‘X1’].fillna(df[‘X1’].mode().iloc[0], inplace=True)
除了众数填充外,还可以使用均值、前项后项填充
df[‘X1’]= df[‘X1’].fillna(df[‘X1’].mean())
df[‘X1’]= df[‘X1’].fillna(method=‘pad’)
df[‘X1’]= df[‘X1’].fillna(method=‘bfill’)
空值填充的其他方式:
1聚类按照类别均值填充空值
2模型预测,把已知数据作为train样本,空值列作为预测变量,其他列作为特征变量,构建模型,预测有待填充空值数据部分。
下面以age作为空值变量,运用GBDT算法预测填充空值部分
例:
#训练样本与测试处理
missing_age_df = pd.DataFrame(df[['Age', 'Parch', 'Sex', 'SibSp', 'Family_Size', 'Family_Size_Category', 'Title', 'Fare', 'Fare_Category', 'Pclass', 'Embarked']])
missing_age_df = pd.get_dummies(missing_age_df,columns=['Title', 'Family_Size_Category', 'Fare_Category', 'Sex', 'Pclass' ,'Embarked'])
missing_age_train = missing_age_df[missing_age_df['Age'].notnull()]
missing_age_test = missing_age_df[missing_age_df['Age'].isnull()]
missing_age_X_train = missing_age_train.drop(['Age'], axis=1)
missing_age_Y_train = missing_age_train['Age']
missing_age_X_test = missing_age_test.drop(['Age'], axis=1)
#调用模型
gbm_reg = ensemble.GradientBoostingRegressor(random_state=42)
gbm_reg_param_grid = {'n_estimators': [2000], 'max_depth': [3],'learning_rate': [0.01], 'max_features': [3]}
gbm_reg_grid = model_selection.GridSearchCV(gbm_reg, gbm_reg_param_grid, cv=10, n_jobs=25, verbose=1, scoring='neg_mean_squared_error')
gbm_reg_grid.fit(missing_age_X_train, missing_age_Y_train)
print('Age feature Best GB Params:' + str(gbm_reg_grid.best_params_))
print('Age feature Best GB Score:' + str(gbm_reg_grid.best_score_))
print('GB Train Error for "Age" Feature Regressor:'+ str(gbm_reg_grid.score(missing_age_X_train, missing_age_Y_train)))
missing_age_test['Age_GB'] = gbm_reg_grid.predict(missing_age_X_test)
print(missing_age_test['Age_GB'][:4])
5.哑变量编码
df=pd.get_dummies(df,colunms=[X1,X2,X3])
关注Python数据挖掘实战技术群,每周定期分享机器学习、数据挖掘、深度学习代码干货,get行业更新技能:
1机器学习数据挖掘代码实战技巧干货 pandas numpy sklearn
2数据可视化技巧
3.商业数据分析用户画像技术分享
4.机器学习算法原理与数据挖掘建模案例 SVM LR LSTM GBDT
5.用户标签体系与推荐算法分享
点链接或者扫描二维码,一起get Python数据挖掘实战技巧:
https://t.zsxq.com/yR76myZ

