版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_29027865/article/details/88902966
Python数据分析与挖掘实战
第三章 数据探索
3.1 数据质量分析
3.1.1 缺失值分析
缺失值的处理分为三种情况:
- 删除存在缺失值的记录;
- 对可能的数据进行插值:拉格朗日插值,牛顿插值法:
3.1.2 异常值分析
首先可以先使用describe()函数查看数据的基本情况:
import pandas as pd
# 餐饮数据
catering_sale = './data/catering_sale.xls'
# 读取数据,指定日期列为索引列
data = pd.read_excel(catering_sale,index_col=u'日期')
data.describe()
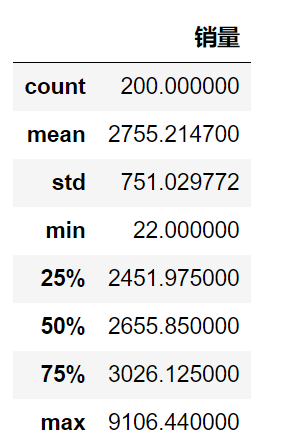
检测异常值的方法可以使用箱型图:
import pandas as pd
catering_sale = './data/catering_sale.xls'
data = pd.read_excel(catering_sale,index_col=u'日期')
import matplotlib.pyplot as plt
# 用来正常显示中文标签
# plt.rcParams['dont.sans-serif'] = ['SimHei']
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
# # 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
plt.figure()
'''
画箱型图,这里画箱型图有两种方法:
1. 一种是直接调用DataFrame的boxplot();
2. 另一种是调用Series或者DataFrame的plot()方法,并用kind参数指定箱型图(box);
'''
p = data.boxplot(return_type='dict')
# 'flies'即为异常值的标签
x = p['fliers'][0].get_xdata()
y = p['fliers'][0].get_ydata()
y.sort()
for i in range(len(x)):
if i > 0:
plt.annotate(y[i],xy = (x[i],y[i]), xytext = (x[i]+0.05-0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i],xy = (x[i],y[i]),xytext = (x[i]+0.08,y[i]))
plt.show()
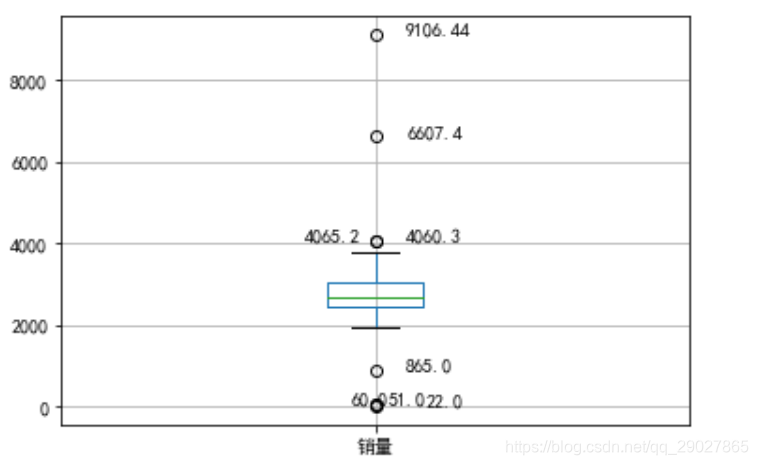
上下的两个标线表示的是上界和下界(四分位点),超过上下界的值就是异常,但是那其中几个散点离上下界比较近,所以可以把865,4060.3,4065.2归为正常值,将22,51,60,6607.4,9106.44归为异常值;
3.2 数据特征分析
对于定量数据可以通过绘制频率分布表,绘制频率分布直方图,茎叶图的方式进行直观的分析;
对于定性分类的数据,可以使用饼图和条形图的方式来查看显示分布情况;
3.2.1 统计量分析
极差反映了最大值和最小值的分布情况;
标准差用来度量数据偏离均值的程度;
变异系数度量标准差相对于均值的离中趋势;
四分位数间距表示上下四分位数之差,越大表示变异程度越大;
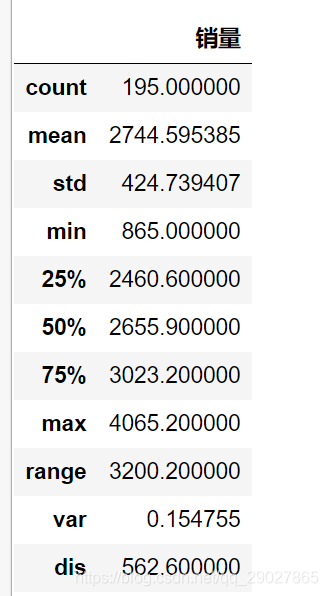
# 餐饮销量数据统计量分析
import pandas as pd
catering_sale = './data/catering_sale.xls'
data = pd.read_excel(catering_sale,index_col = u'日期')
# 过滤异常数据
data = data[(data[u'销量'] > 400)&(data[u'销量'] < 5000)]
statistics = data.describe()
# 极差
statistics.loc['range'] = statistics.loc['max'] - statistics.loc['min']
# 变异系数
statistics.loc['var'] = statistics.loc['std'] / statistics.loc['mean']
# 四分位数间距
statistics.loc['dis'] = statistics.loc['75%'] - statistics.loc['25%']
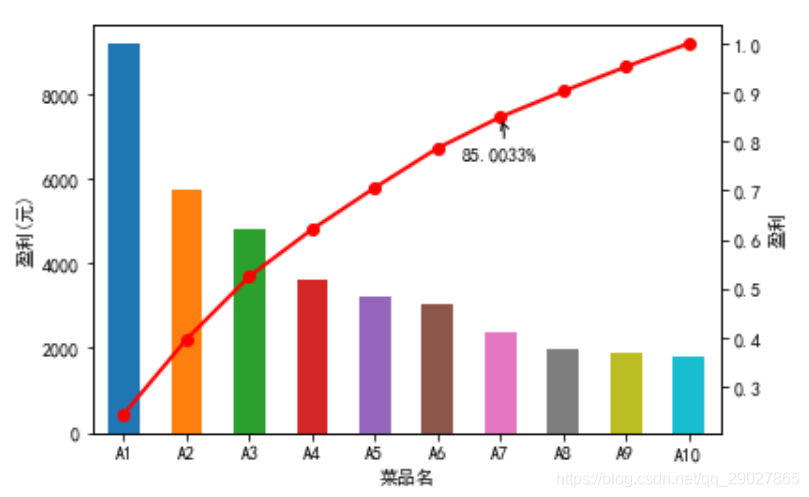
3.2.2 贡献度分析
# 菜品盈利帕累托图代码
import pandas as pd
# 初始化参数
dish_profit = './data/catering_dish_profit.xls'
data = pd.read_excel(dish_profit,index_col = u'菜品名')
data = data[u'盈利'].copy()
# 表示按降序排列
data.sort_values(ascending=False)
# 导入图像库
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False
plt.figure()
# 显示直方图
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')
p = 1.0 * data.cumsum()/data.sum()
p.plot(color = 'r',secondary_y=True,style='-o',linewidth=2)
# 添加注释,即85%处的标记,这里包括了指定箭头样式
plt.annotate(format(p[6],'.4%'),xy=(6,p[6]),xytext=(6*0.9,p[6]*0.9),
arrowprops=dict(arrowstyle="->",connectionstyle="arc3,rad=.2"))
plt.ylabel(u'盈利')
plt.show()
3.2.3 相关性分析
import pandas as pd
# 餐饮数据,含有其他属性
catering_sale = './data/catering_sale_all.xls'
# 读取数据,指定'日期'列为索引列
data = pd.read_excel(catering_sale,index_col = u'日期')
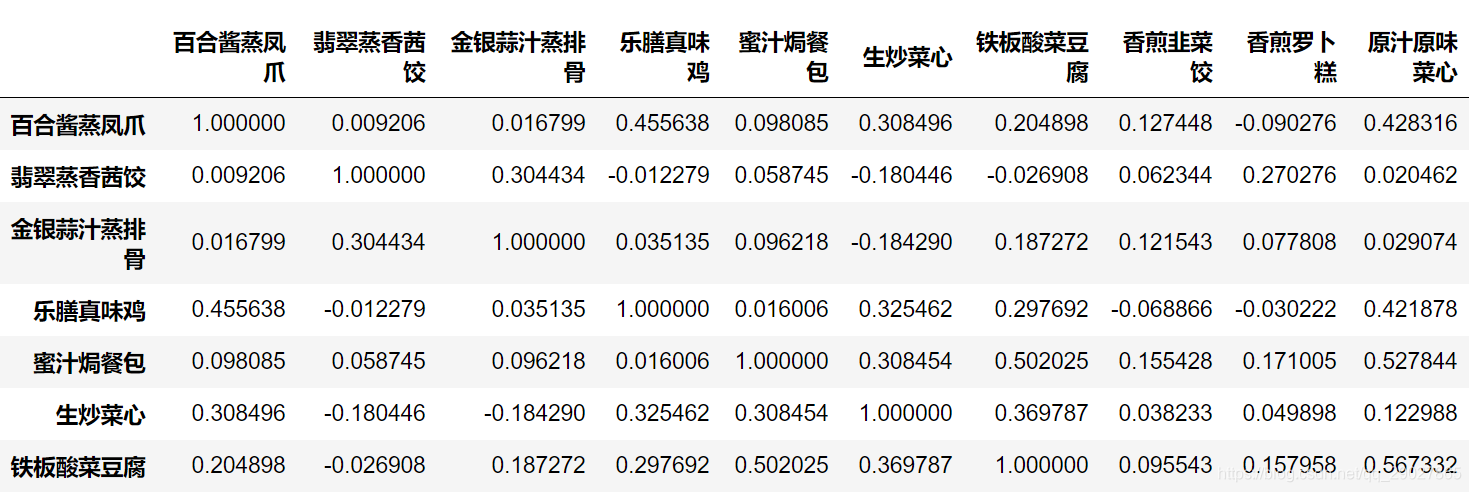
# 相关系数矩阵,即给出了任意两款菜式之间的相关系数
data.corr()
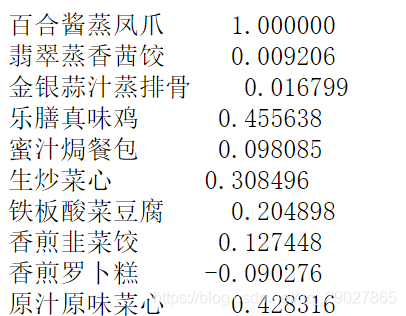
# 只显示"百合酱蒸风爪"与其他菜式的相关系数
data.corr()[u'百合酱蒸凤爪']
# 计算两者的相关系数
data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺'])
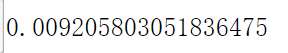
计算两个列向量的相关系数:
# 计算两个列的相关系数
# 生成样本D,一行为1-7,一行为2-8
D = pd.DataFrame([range(1,8),range(2,9)])
# 提取第一行
S1 = D.loc[0]
# 提取第二行
S2 = D.loc[1]
# 计算S1,S2的相关系数:有person(皮尔逊系数),kendall(肯德尔系数),spearman(斯皮尔曼系数)
S1.corr(S2,method='pearson')
计算协方差矩阵:
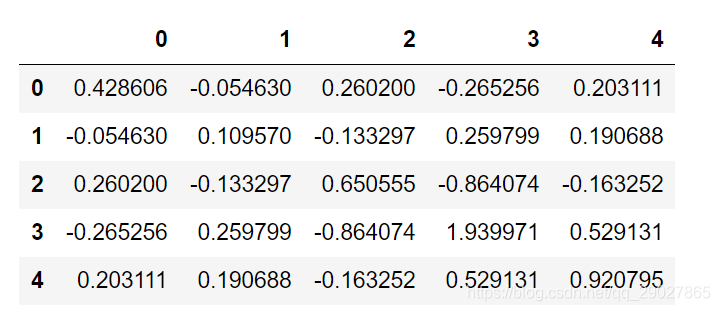
# 计算协方差矩阵
import numpy as np
D = pd.DataFrame(np.random.randn(6,5)) # 产生6*5的随机矩阵
D.cov() #计算协方差矩阵
D[0].cov(D[1]) # 计算第一列和第二列的协方差
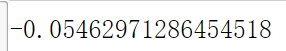
计算 6 * 5 随机矩阵的偏度(三阶矩)/峰度(四阶矩)
# 计算 6 * 5 随机矩阵的偏度(三阶矩)/峰度(四阶矩)
import pandas as pd
D = pd.DataFrame(np.random.randn(6,5)) # 产生6*5的随机矩阵
# 偏度:通过对偏度系数的测量,我们能够判定数据分布的不对称程度以及方向
D.skew()
# 峰度:是研究数据分布陡峭或平滑的统计量,通过对峰度系数的测量,我们能够判定数据分布相对于正态分布而言是更陡峭还是平缓。
D.kurt()
3.2.4 统计特征函数
使用cumsum来获取某一列的前n项和:
# 使用cumsum来获取某一列的前n项和
D = pd.Series(range(0,20)) # 构造Series,内容为0-19共20个整数
D.cumsum(0) # 给出前n项和
# 问题:当其大于列数时,表示什么意思呢?
3.2.5 绘图函数
直线:
import matplotlib.pyplot as plt # 导入作图库
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize = (7,5)) # 创建图像区域,指定比例
import numpy as np
#设置起点,终点和步长
x = np.linspace(0, 2*np.pi, 50) # x坐标输入
y = np.sin(x) # 计算对应x的正弦值
plt.plot(x, y, 'bp--') # 控制图形格式为蓝色带星虚线,显示正弦曲线
plt.show()
饼图:
import matplotlib.pyplot as plt
labels = 'Frogs','Hogs','Dogs','Logs' # 定义标签
sizes = [15, 30, 45, 10] #每一块的比例
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral'] #每一块的颜色
explode = (0,0.09,0,0) # 突出显示,这里仅仅突出第二块
plt.pie(sizes,explode=explode, labels=labels, colors=colors, autopct='%1.1f%%',
shadow=True, startangle=90)
plt.axis('equal') #显示为圆(避免比例压缩为椭圆)
plt.show()
直方图:
import matplotlib.pyplot as plt
import numpy as np
x = np.random.randn(1000) # 1000个服从正态分布的随机数
plt.hist(x, 10) # 分成10组进行绘制直方图
plt.show()
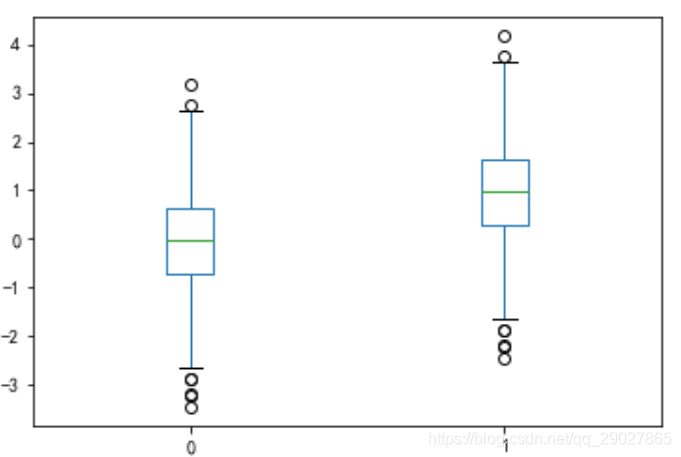
箱型图
'''
绘制箱型图的两种方法:
1. 直接调用DataFrame的boxplot()方法;
2. 调用Series或者DataFrame的plot()方法,并用kind参数指定箱型图(box);
'''
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
x = np.random.randn(1000) # 1000个服从正态分布的随机数
D = pd.DataFrame([x,x+1]).T # 构造两列的DataFrame
D.plot(kind = 'box') # 调用Series内置的作图方法画图,用kind参数指定箱型图box
plt.show()
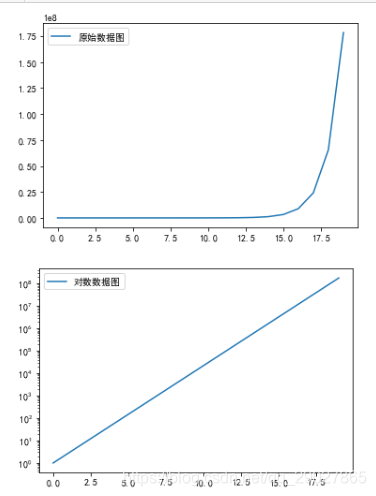
折线图:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import numpy as np
import pandas as pd
# np.arrange()返回一个ndarray而不是一个列表
x = pd.Series(np.exp(np.arange(20))) # 原始数据
# 对图像左上方做好标记
x.plot(label = u'原始数据图',legend = True)
plt.show()
x.plot(logy = True, label = u'对数数据图',legend = True)
plt.show()
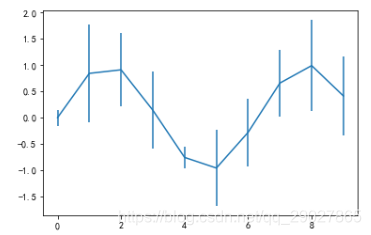
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import numpy as np
import pandas as pd
error = np.random.randn(10) # 定义误差列
y = pd.Series(np.sin(np.arange(10))) #均值数据列
y.plot(yerr = error) #绘制误差图
plt.show()
第四章 数据预处理
4.1 数据清洗
4.1.1 缺失值处理
缺失值处理一般采用:均值/中位数/众数插补,使用固定值,最近邻值插补,回归法,插值法
拉格朗日插值:
# 用拉格朗日法进行插补
import pandas as pd
from scipy.interpolate import lagrange # 导入拉格朗日函数
import xlwt
inputfile = './data/catering_sale.xls' # 销售数据路径
outputfile = './sales.xls' # 输出数据路径
data = pd.read_excel(inputfile) # 读入数据
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None # 过滤异常值,将其变为空值
# 自定义列向量插值函数
# s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k,n)) + list(range(n+1, n+1+k))] # 取数
y = y[y.notnull()] # 剔除空值
return lagrange(y.index, list(y))(n) # 插值并返回插值结果
# 逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值
data[i][j] = ployinterp_column(data[i],j)
data.to_excel(outputfile) # 输出结果, 写入文件
4.2 数据变换
4.1.1 数据归一化
# 数据规范化
import pandas as pd
import numpy as np
datafile = './data/normalization_data.xls' #参数初始化
data = pd.read_excel(datafile,header = None) # 读取数据
(data - data.min())/(data.max() - data.min()) # 最小-最大规范化
(data - data.mean())/data.std() # 零-均值规范化
data/10**np.ceil(np.log10(data.abs().max())) # 小数定标规范化
4.1.2 数据离散化(聚类)
等宽法,等频法,基于聚类分析的方法;
def cluster_plot(d, k): # 自定义作图函数来显示聚类结果
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
# 数据离散化:根据某列的数值来进行分组
import pandas as pd
datafile = './data/discretization_data.xls' #参数初始化
data = pd.read_excel(datafile) # 读取数据
data = data[u'肝气郁结证型系数'].copy()
k = 4
# 1. 等宽离散化,各个类别依次命名为0,1,2,3
d1 = pd.cut(data, k, labels= range(k))
# 2. 等频率离散化
w = [1.0*i/k for i in range(k+1)]
w = data.describe(percentiles = w)[4:4+k+1] # 使用describe函数自动计算分位数
w[0] = w[0] * (1-1e-10)
d2 = pd.cut(data, w, labels = range(k))
# 3. 基于聚类分析的方法
from sklearn.cluster import KMeans # 引入KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 4) # 建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data.values.reshape((len(data), 1)))
c = pd.DataFrame(kmodel.cluster_centers_).sort_values(by=0) # 输出聚类中心,并且排序(默认随机排序)
# # python3中没有rolling_mean的方法,需要将其改为rolling.mean
w = c.rolling(2).mean().iloc[1:]
# w[0]
# .mean(2).iloc[1:] # 相邻两项求中点,作为边界点
w = [0] + list(w[0]) + [data.max()] # 把首末边界点加上
d3 = pd.cut(data, w, labels = range(k))
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()
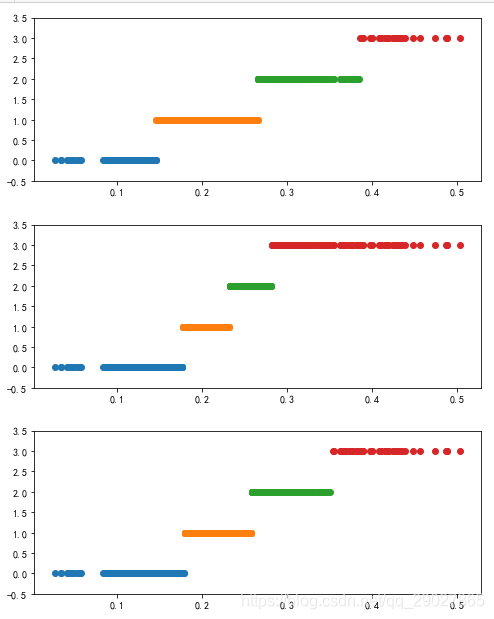
4.3 属性改造
# 线损率属性改造
import pandas as pd
# 参数初始化
inputfile = './data/electricity_data.xls' #供入供出电量数据
outputfile = './electricity_data.xls' # 属性改造后的电量数据
data = pd.read_excel(inputfile) # 读入数据
data[u'线损率'] = (data[u'供入电量'] - data[u'供出电量'])/data[u'供入电量']
data.to_excel(outputfile, index = False) # 保存结果
4.4 数据规约
# 主成分分析降维代码
inputfile = './data/principal_component.xls'
outputfile = './dimention_reducted.xls' # 降维后的数据
data = pd.read_excel(inputfile, header = None) # 读入数据
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
pca.components_ # 返回模型的各个特征向量
pca.explained_variance_ratio_ # 返回各个成分各自的方差百分比

# 使用pca的结果
pca = PCA(3)
pca.fit(data)
low_d = pca.transform(data) # 用它来降低维度
pd.DataFrame(low_d).to_excel(outputfile) # 保存结果
pca.inverse_transform(low_d) # 必要时可以用inverse_transform()函数来复原数据
4.5 常用预处理函数
D = pd.Series([1,1,2,3,5])
# 进行数据去重的两种方法
D.unique()
np.unique(D)