根据观测、调查收集到初步的样本数据集后,接下来要考虑的的是:样本数据集的数量和质量是否满足模型构建的要求?有没有出现从未设想过的数据状态?其中有没有明显的规律和趋势?各因素之间有什么样的关联性?
通过检验数据集的数据质量、绘制图表、计算某些特征量等手段,对样本数据集的结构和规律进行分析的过程就是数据探索。数据探索有助于选择合适数据预处理和构建方法,甚至可以完成一些通常由数据挖掘解决的问题。
数据1读取:
import pandas as pd
import numpy as np
catering_sale = 'D:\\WeChat_Documents\\WeChat Files\\FileStorage\\File\\2023-02\\catering_fish_congee.xls' # 餐饮数据
data = pd.read_excel(catering_sale,names=['date','sale']) # 读取数据,指定“日期”列为索引
print(data)
print(data.describe()) #具体描述
一、异常值分析
箱型图提供了识别异常值的一个标准:异常值通常被定义为小于下四分位数-1.5*四分位数间距或大于上四分位数+1.5*四分位数间距,代码和图如下图:
#箱线图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure()
p = data.boxplot(return_type='dict')
x = p['fliers'][0].get_xdata()
y = p['fliers'][0].get_ydata()
y.sort()
for i in range(len(x)):
if i > 0:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.05-0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.08,y[i]))
plt.title('季度销售额频率分布直方图(3001)',fontsize=20)
plt.show()
如图可得3960归为异常值。
二、数据特征分析
分布分析能揭示数据的分布特征和分布类型。对于定量数据,要想了解其分布形式是对称还是非对称的、发现某些特大特或特小的可以指,可做出频率分布表、绘制频率分布直方图、绘制茎叶图进行直观分析;对于定性数据,可用饼图和条形图直观地显示其分布情况。
频率分布直方图,如下:
bins = [0,500,1000,1500,2000,2500,3000,3500,4000]
labels = ['[0,500)','[500,1000)','[1000,1500)','[1500,2000)',
'[2000,2500)','[2500,3000)','[3000,3500)','[3500,4000)']
data['sale分层'] = pd.cut(data.sale, bins, labels=labels)
aggResult = data.groupby(by=['sale分层'])['sale'].agg([("sale",np.size)])
pAggResult = round(aggResult/aggResult.sum(), 2, ) * 100
# 绘制频率直方图
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6)) # 设置图框大小尺寸
pAggResult['sale'].plot(kind='bar',width=0.8,fontsize=10)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('季度销售额频率分布直方图(3001)',fontsize=20)
plt.show()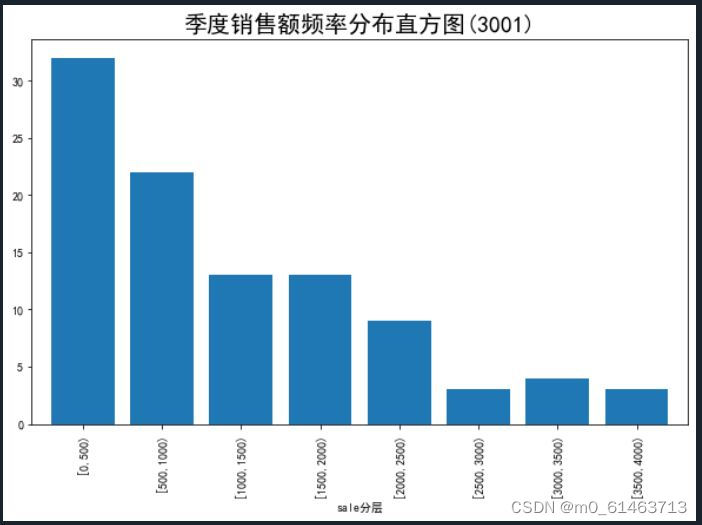
如图可得:销售量在[0,500)的日期占比相当高,而这3个月中销售量在2500以上的日期较少。
导入新的数据:
import pandas as pd
import matplotlib.pyplot as plt
catering_dish_profit = 'D:\\WeChat_Documents\\WeChat Files\\FileStorage\\File\\2023-02\\catering_dish_profit.xls' # 餐饮数据
data = pd.read_excel(catering_dish_profit)
饼图,如下:
#绘制饼图
x=data['盈利']
labels=data['菜品名']
plt.figure(figsize=(10,6))
plt.pie(x,labels=labels)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('菜品销售额分布(3001)')
plt.axis('equal')
plt.show()
条形图,如下:
#条形图
y=data['盈利']
x=data['菜品名']
plt.figure(figsize=(10,6))
plt.bar(x,y)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.xlabel('菜品')
plt.ylabel('销量')
plt.title('菜品销售额分布(3001)')
plt.show()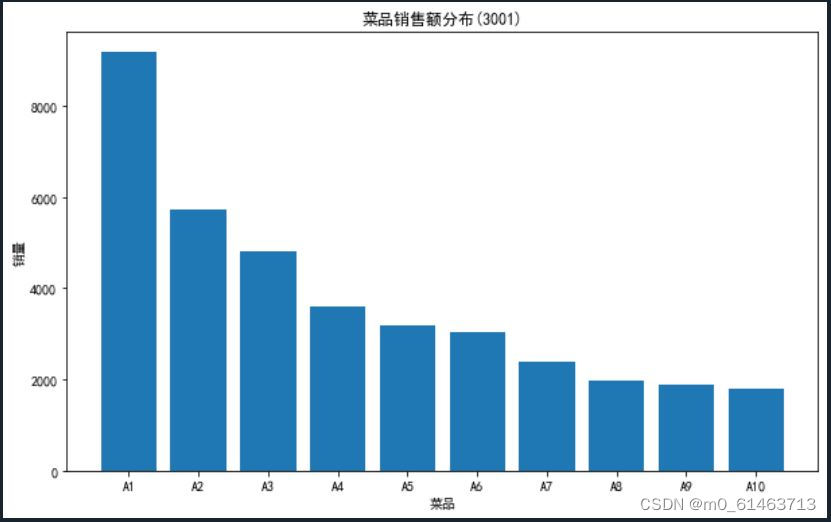
如上饼图和条形图,可以清晰看出每一种类型在整体中所占百分比或频数。
三、相关性分析
分析连续变量之间线性相关程度的强弱,并用适当的统计指标表示出来的过程称为相关分析。
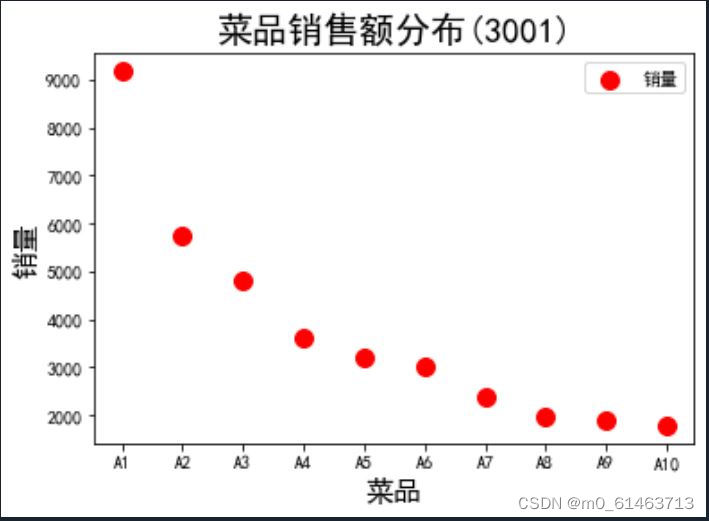
如散点图,如下:
#散点图
years = data['菜品名']
turnovers = data['盈利']
plt.figure()
plt.scatter(years, turnovers, c='red', s=100, label='销量')
plt.xlabel("菜品", fontdict={'size': 16})
plt.ylabel("销量", fontdict={'size': 16})
plt.title("菜品销售额分布(3001)", fontdict={'size': 20})
plt.legend(loc='best')
plt.show()