首先,来进行异常值分析(注意异常值是查看各种单属性的各种数值后得出的结论),然后进行分组比较、切片比较、自定义比较。这些比较也是用来更好的观察数据的。
import pandas as pd
import scipy.stats as ss
import numpy as np
df=pd.read_csv("/Users/ren/PycharmProjects/untitled7/data/HR_comma_sep.csv")
#删除空值,注意有两种删除:行删除和列删除,axis=0为行,how有两个属性any和all,前者有一个空就删,后者都为空才删
df=df.dropna(axis=0,how="any")
#干掉其他异常值,具体规则是根据分析而定的!!
df=df[df["last_evaluation"]<=1][df["salary"]!="nme"][df["department"]!="sale"]
#以部门为单位进行分组对比
df.groupby("department").mean()
#切片对比
df.loc[:["last_evaluation","department"]]
#自定义函数,极差对比
df.loc[:["average_monthly_hours","department"]].groupby("department")["average_monthly_hours"].apply(lambda x:x.max()-x.min())相关代码以及函数都在代码中详细标注了,遇到不会可以直接官方查询或者百度查询,再次不做详细说明来了。
一、柱状图
如图所示: 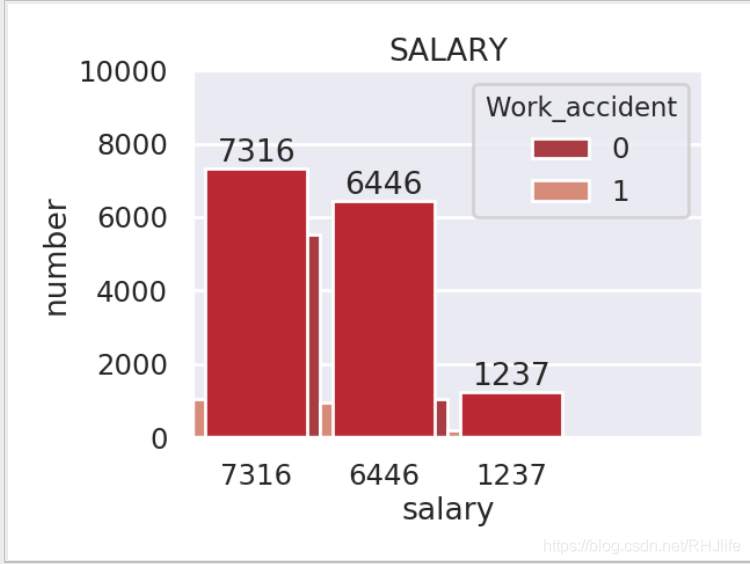
代码:(其中的+0.5是图像产生后有位移差,用来调整图像用的)
import pandas as pd
import scipy.stats as ss
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv("/Users/ren/PycharmProjects/untitled7/data/HR_comma_sep.csv")
#设置不同的样式
sns.set_style(style="darkgrid")
#sns.set_context(context="poster")
sns.set_context(context="poster",font_scale=0.8)
#调色板
#sns.set_palette("Reds")
sns.set_palette(sns.color_palette("RdBu",n_colors=7))
#不同颜色绘制
#sns.countplot(x="salary",data=df)
#多层绘制
sns.countplot(x="salary",hue="Work_accident",data=df)
#横坐标和纵坐标
plt.bar(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts())
#增加标题和横纵坐标名称以及标注
plt.title("SALARY")
plt.xlabel("salary")
plt.ylabel("number")
plt.xticks(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts())
#设置范.
plt.axis([0,4,0,10000])
#遍历
for x,y in zip(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts()):
plt.text(x,y,y,ha="center",va="bottom")
plt.show()二、直方图
如图所示: 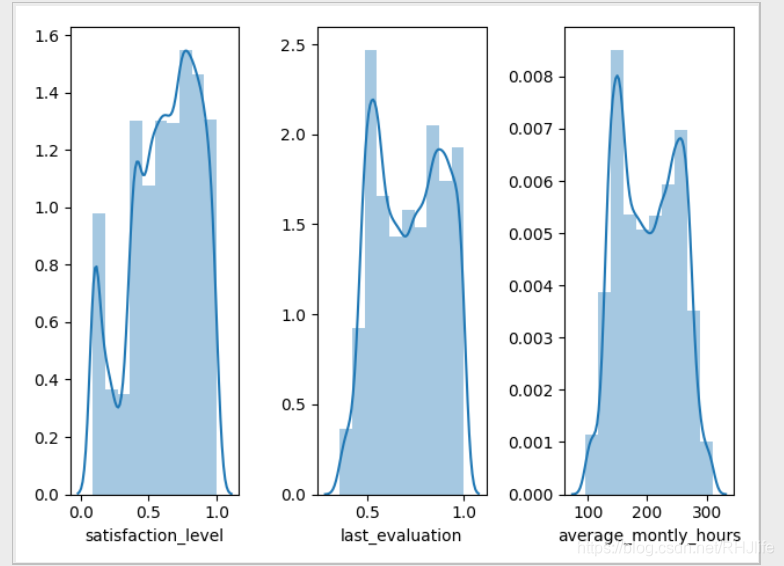
import pandas as pd
import scipy.stats as ss
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv("/Users/ren/PycharmProjects/untitled7/data/HR_comma_sep.csv")
f=plt.figure()
f.add_subplot(1,3,1)
sns.distplot(df["satisfaction_level"],bins=10)
f.add_subplot(1,3,2)
sns.distplot(df["last_evaluation"],bins=10)
f.add_subplot(1,3,3)
sns.distplot(df["average_montly_hours"],bins=10)
plt.show()三、箱线图(可以很容易看出异常值的范围)
如图所示: 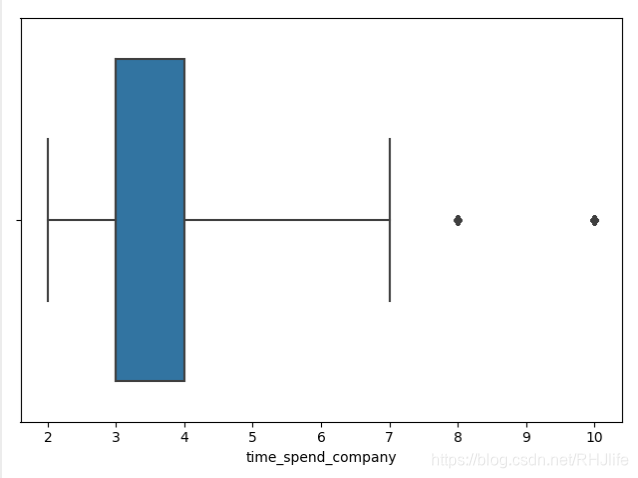
import pandas as pd
import scipy.stats as ss
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv("/Users/ren/PycharmProjects/untitled7/data/HR_comma_sep.csv")
#纵箱线图
#sns.boxplot(y=df["time_spend_company"])
#横箱线图,上界是上四分位数,变成之前的三倍
sns.boxplot(x=df["time_spend_company"],saturation=0.75,whis=3)
plt.show()四、折线图(表示数据变化的趋势、走势、范围)
观察随着工作时间增加,离职率是如何变化的。
如图所示: 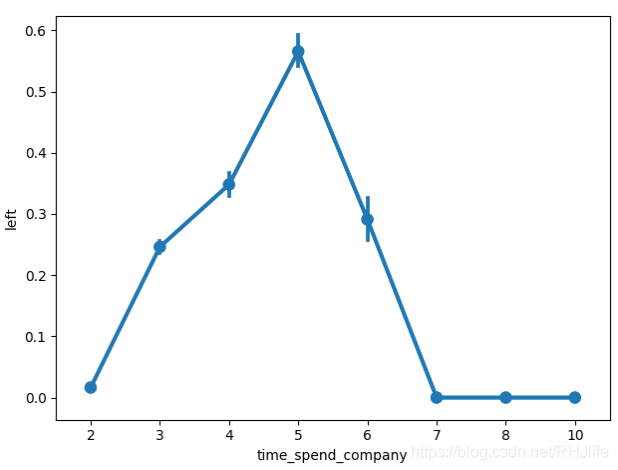
import pandas as pd
import scipy.stats as ss
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv("/Users/ren/PycharmProjects/untitled7/data/HR_comma_sep.csv")
sub_df=df.groupby("time_spend_company").mean()
sns.pointplot(sub_df.index,sub_df["left"])
#另一种画法
sns.pointplot(x="time_spend_company",y="left",data=df)
plt.show()五、饼图
(sub没饼图,用plt画)
如图所示: 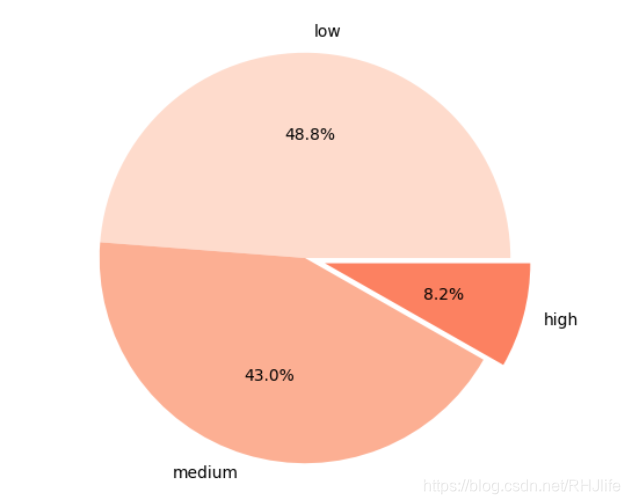
import pandas as pd
import scipy.stats as ss
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv("/Users/ren/PycharmProjects/untitled7/data/HR_comma_sep.csv")
lbs=df["salary"].value_counts().index
#强调某一块
explodes=[0.1 if i=="high" else 0 for i in lbs]
plt.pie(df["salary"].value_counts(normalize=True),explode=explodes,labels=lbs,autopct="%1.1f%%",colors=sns.color_palette("Reds"))
plt.show()六、其他
散点图、集轴图、雷达图、气泡图等,还有很多图,可以直接从官方函数中查看联系。
七、常见统计图的特点
1.条形统计图
(1)能够显示每组中的具体数据。
(2)易于比较数据之间的差别。
2.扇形统计图
(1)用扇形的面积表示部分在总体中所占的百分比。
(2)易于显示每组数据相对于总数的大小。
3、折线统计图
(1)不仅可以表示数量的多少,而且可以反映同一事物在不同时间里的发展变化的情况。
(2) 能够显示数据的变化趋势,反映事物的变化情况。
四、网状统计图
(1)网状统计图的特点是这类统计图中只有一些字母,字母所代表的意义都在题外,在答题前必弄清这些字母代表的意义,在具体的答题过程中就可以脱离字母,较简便地得出答案。