继续补以前拉下的债~~~
一、相关性指标的研究意义
1.1相关系数(Correlation coefficient):
相关系数是变量间关联程度的最基本测度之一
1.2相关分析(Correlation analysis)
是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。
二、相关系数的基本特征
2.1方向:
正相关(positive correlation):两个变量变化方向相同
负相关(negative correlation):两个变量变化方向相反
2.2量级(magnitude):
低度相关:0≤| r | ≤ 0.3
中度相关:0.3≤| r | ≤ 0.8
高度相关:0.8≤| r | ≤ 1
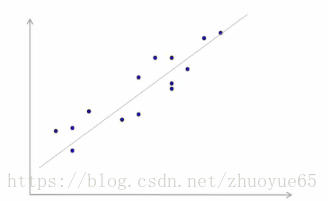
散点分部在一条直线周围==>变量存在线性相关关系。
三、相关系数的计算

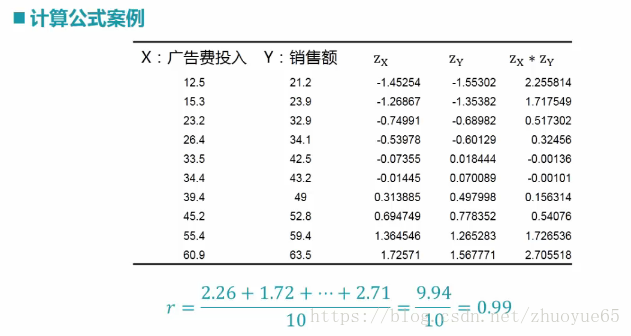
Zx = (每个变量中的值 - 该变量的均值) 除以(标准差)
3.2案例实战:
四、代码案例:
4.1numpy案例:
import numpy
X = [
12.5, 15.3, 23.2, 26.4, 33.5,
34.4, 39.4, 45.2, 55.4, 60.9
]
Y = [
21.2, 23.9, 32.9, 34.1, 42.5,
43.2, 49.0, 52.8, 59.4, 63.5
]
#均值
XMean = numpy.mean(X);
YMean = numpy.mean(Y);
#标准差
XSD = numpy.std(X);
YSD = numpy.std(Y);
#z分数
ZX = (X-XMean)/XSD;
ZY = (Y-YMean)/YSD;
#相关系数
r = numpy.sum(ZX*ZY)/(len(X));
#直接调用Python的内置的相关系数的计算方法
numpy.corrcoef(X, Y)
4.2Pandas案例
import pandas;
X = [
12.5, 15.3, 23.2, 26.4, 33.5,
34.4, 39.4, 45.2, 55.4, 60.9
]
Y = [
21.2, 23.9, 32.9, 34.1, 42.5,
43.2, 49.0, 52.8, 59.4, 63.5
]
data = pandas.DataFrame({
'X': X,
'Y': Y
})
data.corr()
?查看安斯库姆四重奏